4.4.2 Dynamisches perfektes Hashing
Sei U =
{0, . . . , p−1} f¨ ur eine Primzahl p. Zun¨ achst einige mathematische Grundlagen.
Definition 36
Hk,n
bezeichne in diesem Abschnitt die Klasse aller Polynome
∈Zp
[x] vom Grad < k, wobei mit ~a = (a
0, . . . , a
k−1)
∈U
kh
~a(x) =
k−1
X
j=0
a
jx
j
mod p
mod n f¨ ur alle x
∈U .
EADS 4.4 Perfektes Hashing 138/530
ľErnst W. Mayr
Definition 37
Eine Klasse
Hvon Hashfunktionen von U nach
{0, . . . , n−1}
heißt
(c, k)-universell, falls f¨ur alle paarweise verschiedenen x
0, x
1, . . . , x
k−1 ∈U und f¨ ur alle i
0, i
1, . . . , i
k−1 ∈ {0, . . . , n−1}
gilt, dass
Pr[h(x
0) = i
0∧ · · · ∧h(x
k−1) = i
k−1]
≤c
n
k,
wenn h
∈ Hgleichverteilt gew¨ ahlt wird.
Satz 38
Hk,n
ist (c, k)-universell mit c = (1 +
np)
k.
Beweis:
Da
Zpein K¨ orper ist, gibt es f¨ ur jedes Tupel (y
0, . . . , y
k−1)
∈U
kgenau ein Tupel (a
0, . . . , a
k−1)
∈Zkpmit
k−1
X
j=0
a
jx
jr= y
rmod p f¨ ur alle 0
≤r < k.
Damit folgt, dass
|{~a;
h
~a(x
r) = i
rf¨ ur alle 0
≤r < k}|
=
|{(y0, . . . , y
k−1)
∈U
k; y
r= i
rmod n f¨ ur alle 0
≤r < k}|
≤l
p n
mk
.
EADS 4.4 Perfektes Hashing 140/530
ľErnst W. Mayr
Beweis (Forts.):
Da es insgesamt p
kM¨ oglichkeiten f¨ ur ~a gibt, folgt Pr[h(x
r) = i
rf¨ ur alle 0
≤r < k]
≤lp
n
mk·
1 p
k=
lp
n
m·
n p
k
·
1 n
k<
1 + n
p
k·
1
n
k.
Kuckuck-Hashing f¨ ur dynamisches perfektes Hashing
Kuckuck-Hashing arbeitet mit zwei Hashtabellen, T
1und T
2, die je aus den Positionen
{0, . . . , n−1} bestehen. Weiterhin ben¨ otigt es zwei (1 + δ,
O(logn))-universelle Hashfunktionen h
1und h
2f¨ ur ein gen¨ ugend kleines δ > 0, die die Schl¨ usselmenge U auf
{0, . . . , n−
1} abbilden.
Jeder Schl¨ ussel x
∈S wird
entwederin Position h
1(x) in T
1 oderin Position h
2(x) in T
2gespeichert, aber nicht beiden. Die IsElement-Operation pr¨ uft einfach, ob x an einer der beiden Positionen gespeichert ist.
EADS 4.4 Perfektes Hashing 142/530
ľErnst W. Mayr
Die Insert-Operation verwendet nun das Kuckucksprinzip, um neue Schl¨ ussel einzuf¨ ugen. Gegeben ein einzuf¨ ugender Schl¨ ussel x, wird zun¨ achst versucht, x in T
1[h
1(x)] abzulegen. Ist das erfolgreich, sind wir fertig.
Falls aber T
1[h
1(x)] bereits durch einen anderen Schl¨ ussel y besetzt ist, nehmen wir y heraus und f¨ ugen stattdessen x in T
1[h
1(x)] ein.
Danach versuchen wir, y in T
2[h
2(y)] unterzubringen. Gelingt das, sind wir wiederum fertig. Falls T
2[h
2(y)] bereits durch einen anderen Schl¨ ussel z besetzt ist, nehmen wir z heraus und f¨ ugen stattdessen y in T
2[h
2(y)] ein. Danach versuchen wir, z in
T
1[h
1(z)] unterzubringen, und so weiter, bis wir endlich den zuletzt
angefassten Schl¨ ussel untergebracht haben. Formal arbeitet die
Insert-Operation wie folgt:
if T
1[h
1(x)] = x then return fi repeat MaxLoop times
(a) exchange x und T
1[h
1(x)]
(b) if x = NIL then return fi (c) exchange x und T
2[h
2(x)]
(d) if x = NIL then return fi od
rehash(); Insert(x)
EADS 4.4 Perfektes Hashing 144/530
ľErnst W. Mayr
F¨ ur die Analyse der Zeitkomplexit¨ at nehmen wir an, dass die Schleife t-mal durchlaufen wird (wobei t
≤MaxLoop).
Es gilt, die folgenden zwei F¨ alle zu betrachten:
1
Die Insert-Operation ger¨ at w¨ ahrend der ersten t Runden in eine Endlosschleife
2
Dies ist nicht der Fall
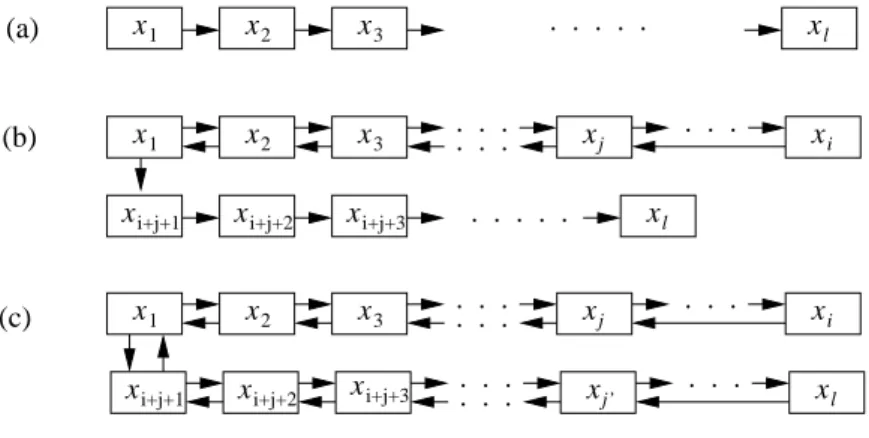
x1 x2 x3 xl
x1 x2 x3 . . . xj . . . xi
. . .
x1 x2 x3 . . . xj . . . xi
. . . xi+j+1 xi+j+2 xi+j+3
xi+j+2 xi+j+3 xi+j+1
(a)
(b)
(c)
. . . . .
. . . . . xl
x x
. . . .
. . . j’ l
Abbildung 3: Drei F¨alle f¨ur den Ausgang derInsertOperation. (a): Es wird keine Position zweimal besucht. (b):xibesucht die Position vonxj, was dazu f¨uhrt, dass alle Schl¨usselxj, . . . , x2wieder in ihre Ausgangspositionen zur¨uckgeschoben werden.x1versucht daraufhin die andere Alternativpositi- on, und hier terminiert die Kuckucksregel inxℓ. (c):xibesucht die Position vonxjundxℓbesucht die Position vonxj′, was zu einer Endlosschleife f¨uhrt.
2. DieInsertOperation formt keine Endlosschleife w¨arend der erstentRunden.
Wir untersuchen zun¨achst den ersten Fall. Seiv ≤ ℓ die Anzahl der verschiedenen angefassten Schl¨ussel. Dann ist die Anzahl der M¨oglichkeiten, eine Endlosscheife zu formen, h¨ochstens
v3·sv−1·nv−1
da es maximalv3 M¨oglichkeiten f¨ur die Werte i,j und ℓin Abb. 3 gibt, sv−1 viele M¨oglichkeiten f¨ur die Positionen der Schl¨ussel gibt, undnv−1 viele M¨oglichkeiten f¨ur die Schl¨ussel außerx1 gibt.
Angenommen, wir haben(1, v)-universelle Hashfunktionen, dann passiert jede M¨oglichkeit nur mit einer Wahrscheinlichkeit vons−2v. Falls nuns ≥ (1 +ǫ)nf¨ur eine Konstanteǫ > 0, dann ist die Wahrscheinlichkeit f¨ur den Fall 1 h¨ochstens
Xℓ v=3
v3sv−1nv−1s−2v≤ 1 sn
X∞ v=3
v3(n/s)v=O(1/n2)
F¨ur den zweiten Fall ben¨otigen wir das folgende Lemma.
Lemma 1.7 Angenommen, dieInsertOperation formt keine Endlosschleife nachℓbesuchten Schl¨usseln.
Dann gibt es eine Schl¨usselfolge in der L¨ange mindestensℓ/3inx1, . . . , xℓ, in der alle Schl¨ussel ver- schieden sind.
Beweis. Falls dieInsert Operation niemals zu einer bereits besuchten Position zur¨uckkehrt, die das Lemma wahr. Nehmen wir also an, dass die Operation zu einer bereits besuchten Position zur¨uckkehrt, und seieniundjso definiert wie in Abb. 3. Fallsℓ < i+j, dann bilden die erstenj−1≥(i+j−1)/2≥ ℓ/2Schl¨ussel die gesuchte Folge. F¨urℓ≥i+j muss eine der Folgenx1, . . . xj−1undxi+j−1, . . . , xℓ
die L¨ange mindestensℓ/3haben. ⊓⊔
7
Insert bei Kuckuck-Hashing; Endlosschleife im Fall (c)
EADS 4.4 Perfektes Hashing 146/530
ľErnst W. Mayr
Erster Fall:
Sei v
≤l die Anzahl der verschiedenen angefassten Schl¨ ussel. Dann ist die Anzahl der M¨ oglichkeiten, eine
Endlosscheife zu formen, h¨ ochstens v
3·n
v−1·m
v−1,
da es maximal v
3M¨ oglichkeiten f¨ ur die Werte i, j und l gibt, n
v−1viele M¨ oglichkeiten f¨ ur die Positionen der Schl¨ ussel, und m
v−1viele M¨ ooglichkeiten f¨ ur die Schl¨ ussel außer x
1.
Angenommen, wir haben (1, v)-universelle Hashfunktionen, dann passiert jede M¨ oglichkeit nur mit einer Wahrscheinlichkeit von n
−2v. Falls n
≥(1 + δ)m f¨ ur eine Konstante δ > 0, dann ist die Wahrscheinlichkeit f¨ ur den Fall 1 h¨ ochstens
l
X
v=3
v
3n
v−1m
v−1n
−2v≤1 nm
∞
X
v=3
v
3(m/n)
v=
O(1
m
2) .
Zweiter Fall:
Lemma 39
Im zweiten Fall gibt es eine Schl¨ usselfolge der L¨ ange mindestens l/3 in x
1, . . . , x
l, in der alle Schl¨ ussel paarweise verschieden sind.
Beweis:
Nehmen wir an, dass die Operation zu einer bereits besuchten Position zur¨ uckkehrt, und seien i und j so definiert wie in der Abbildung. Falls l
≤i + j, dann bilden die ersten
j
−1
≥(i + j
−1)/2
≥l/2 Schl¨ ussel die gesuchte Folge.
F¨ ur l
≥i + j muss eine der Folgen x
1, . . . , x
j−1und x
i+j−1, . . . , x
ldie L¨ ange mindestens l/3 haben.
EADS 4.4 Perfektes Hashing 148/530
ľErnst W. Mayr
Beweis (Forts.):
Sei also x
01, . . . , x
0veine solche Folge verschiedener Schl¨ ussel in x
1, . . . , x
2tder L¨ ange v =
d(2t−1)/3e. Dann muss entweder f¨ ur (i
1, i
2) = (1, 2) oder f¨ ur (i
1, i
2) = (2, 1) gelten, dass
h
i1(x
01) = h
i1(x
02), h
i2(x
02) = h
i2(x
03), h
i1(x
03) = h
i1(x
04), . . . Gegeben x
01, so gibt es m
v−1m¨ ogliche Folgen von Schl¨ usseln x
02, . . . , x
0v. F¨ ur jede solche Folge gibt es zwei M¨ oglichkeiten f¨ ur (i
1, i
2). Weiterhin ist die Wahrscheinlichkeit, dass die obigen Positions¨ ubereinstimmungen gelten, h¨ ochstens n
−(v−1), wenn die Hashfunktionen aus einer (1, v)-universellen Familie stammen. Also ist die Wahrscheinlichkeit, dass es irgendeine Folge der L¨ ange v gibt, so dass Fall 2 eintritt, h¨ ochstens
2(m/n)
v−1 ≤2(1 + δ)
−(2t−1)/3+1.
Diese Wahrscheinlichkeit ist polynomiell klein in m, falls
t = Ω(log m) ist.
Beweis (Forts.):
Zusammen ergibt sich f¨ ur die Laufzeit von Insert :
1 +
MaxLoop
X
t=2
(2(1 + δ)
−(2t−1)/3+1+
O(1/m2))
≤
1 +
OMaxLoop m
2
+
O∞
X
t=0
((1 + δ)
−2/3)
t!
=
O1 + 1
1
−(1 + δ)
−2/3=
O(1 + 1/δ).
EADS 4.4 Perfektes Hashing 150/530
ľErnst W. Mayr
Beweis (Forts.):
Uberschreitet ¨ m irgendwann einmal die Schranke n/(1 + δ), so
wird n hochgesetzt auf (1 + δ)n und neu gehasht. Unterschreitet
auf der anderen Seite m die Schranke n/(1 + δ)
3, so wird n
verringert auf n/(1 + δ) und neu gehasht. Auf diese Weise wird die
Tabellengr¨ oße linear zur Anzahl momentan existierender Schl¨ ussel
gehalten. Der Aufwand f¨ ur ein komplettes Rehashing ist
O(n), sodass amortisiert ¨ uber Θ(n) Einf¨ ugungen und L¨ oschungen der
Aufwand nur eine Konstante ist.
Originalarbeiten zu Hashverfahren:
J. Lawrence Carter, Mark N. Wegman:
Universal Classes of Hash Functions, Proc. STOC 1977, pp. 106–112 (1977) Gaston H. Gonnet:
Expected Length of the Longest Probe Sequence in Hash Code Searching,
Journal of the ACM
28(2), pp. 289–304 (1981)Martin Dietzfelbinger et al.:
Dynamic Perfect Hashing: Upper and Lower Bounds, SIAM J. Comput.
23(4), pp. 738–761 (1994)EADS 4.4 Perfektes Hashing 152/530
ľErnst W. Mayr
Und weiter:
Rasmus Pagh, Flemming Friche Rodler:
Cuckoo Hashing,
Proc. ESA 2001, LNCS
2161, pp. 121–133 (2001)Luc Devroye, Pat Morin, Alfredo Viola:
On Worst Case Robin-Hood Hasing,
McGill Univ., TR
0212(2002)
5. Vorrangwarteschlangen - Priority Queues Priority Queues unterst¨ utzen die Operationen
Insert(), Delete(), ExtractMin(), FindMin(), DecreaseKey(), Merge().
Priority Queues per se sind
nichtf¨ ur IsElement()-Anfragen, also zum
Suchengeeignet. Falls ben¨ otigt, muss daf¨ ur eine passende W¨ orterbuch-Datenstruktur parallel mitgef¨ uhrt werden.
EADS 5 Vorrangwarteschlangen - Priority Queues 154/530
ľErnst W. Mayr
5.1 Binomial Queues (binomial heaps)
Binomialwarteschlangen (Binomial Queues/Binomial Heaps) werden mit Hilfe von
Binomialb¨aumenkonstruiert.
Definition 40
Die Binomialb¨ aume B
n, n
≥0, sind rekursiv wie folgt definiert:
sm sm s
sm s s
s
A A
sm
@
@
@ s @
Bn−1
Bn−1
B
0B
1B
2B
nAchtung:
Binomialb¨ aume sind offensichtlich
keineBin¨ arb¨ aume!
Lemma 41
Ein B
nl¨ asst sich wie folgt zerlegen:
s
@
B
n−1@s
@
B
n−2@s
@
B
n−3@s
@
B
1@s
@
B
0@ s#
#
#
#
#
c c c c c
q q q q
Erste Zerlegung von B
n:
der Breite nachEADS 156/530
ľErnst W. Mayr
Lemma 41
Ein B
nl¨ asst sich wie folgt zerlegen:
s
B
0s
B
0s
@
B
1@s
@
B
n−3@s
@
B
n−2@s
@
B
n−1@
p p p pp p p pp p
R¨ uckgrat
XX XXzZweite Zerlegung von B
n:
der Tiefe nachSatz 42
F¨ ur den Binomialbaum B
ngilt:
1
B
nhat 2
nKnoten.
2
Die Wurzel von B
nhat Grad n.
3
B
nhat H¨ ohe/Tiefe n.
4
B
nhat
niKnoten in Tiefe i.
EADS 5.1 Binomial Queues (binomial heaps) 157/530
ľErnst W. Mayr
Beweis:
zu 1: Induktion unter Verwendung der Definition zu 2: Siehe erste Zerlegung von Binomialb¨ aumen zu 3: Siehe zweite Zerlegung von Binomialb¨ aumen zu 4: Induktion ¨ uber n:
(I) n= 0:B0hat 1 Knoten in Tiefei= 0und0Knoten in Tiefe i >0, also 0i
Knoten in Tiefei.
(II) IstNin die Anzahl der Knoten in Tiefeiim Bn, so gilt unter der entsprechenden Induktionsannahme f¨urBn, dass
Nin+1=Nin+Ni−1n =
n
i
+
n
i−1
= n+ 1
i
, woraus wiederum per Induktion die Behauptung folgt.
Bemerkung:
Eine m¨ ogliche Implementierung von Binomialb¨ aumen ist das Schema
” Pointer zum
erstenKind und Pointer zum
n¨achstenGeschwister“.
EADS 5.1 Binomial Queues (binomial heaps) 159/530
ľErnst W. Mayr
Definition 43
Eine
Binomial Queuemit n Elementen wird wie folgt aufgebaut:
1
Betrachte die Bin¨ ardarstellung von n.
2
F¨ ur jede Position i mit einem 1-Bit wird ein Binomialbaum B
iben¨ otigt (der 2
iKnoten hat).
3
Verbinde die (Wurzeln der) Binomialb¨ aume in einer doppelt verketteten zirkul¨ aren Liste.
4
Beachte, dass innerhalb jedes Binomialbaums die
Heap-Bedingung erf¨ ullt sein muss. Dadurch enth¨ alt die Wurzel eines jeden Binomialbaums gleichzeitig sein minimales
Element.
5
Richte einen
Min-Pointerauf das Element in der Wurzel-Liste
mit minimalem Schl¨ ussel ein.
Beispiel 44
Beispiel: n = 11 = (1011)
2: B
32
mQ Q m Q
3
A m A
4
8
m A AB
11
m7
m11
m9
m10
m6
mB
07
mY
j -
@
@ I
min
EADS 5.1 Binomial Queues (binomial heaps) 161/530
ľErnst W. Mayr
Operationen f¨ ur Binomial Queues:
IsElement : Die Heap-Bedingung wirkt sich nur auf die Anordnung der Datenelemente innerhalb jedes einzelnen Binomialbaums aus, regelt aber nicht, in welchem Binomialbaum ein gegebenes Element gespeichert ist.
Tats¨ achlich kann ein Element in jedem der vorhandenen Binomialb¨ aume stehen. Das Suchen ist hier nicht effizient implementierbar, denn im worst-case m¨ usste jedes Element der Binomialb¨ aume angeschaut werden.
Also w¨ aren zum Suchen eines Elements schlimmstenfalls 2
0+ 2
1+
· · ·+ 2
blognc−1= Θ(n) Elemente zu betrachten.
Daher wird eine gesonderte Datenstruktur, etwa ein
Suchbaum, f¨ ur die IsElement-Operation verwendet. Damit ist
Suchen mit Zeitaufwand
O(logn) m¨ oglich.
Operationen f¨ ur Binomial Queues:
Merge: Das Vorgehen f¨ ur das Merge (disjunkte Vereinigung) zweier Binomial Queues entspricht genau der
Addition zweier Bin¨arzahlen: Ein einzelnesB
iwird ¨ ubernommen, aus zwei B
i’s wird ein B
i+1konstruiert. Damit die Heap-Bedingung erhalten bleibt, wird als Wurzel des entstehenden B
i+1die Wurzel der beiden B
imit dem kleineren Schl¨ ussel genommen.
Allerdings kann ein solcher
” Ubertrag“ dazu f¨ ¨ uhren, dass im n¨ achsten Verschmelzungsschritt drei B
i+1zu verschmelzen sind. Dann wird unter Beachtung obiger Regel ein B
i+2gebildet und einer der B
i+1unver¨ andert ¨ ubernommen.
EADS 5.1 Binomial Queues (binomial heaps) 163/530
ľErnst W. Mayr
Algorithmus:
for i := 0, 1, 2, 3, . . . do if (∃ genau 3 B
is) then
verbinde zwei der B
i’s zu einem B
i+1und behalte das dritte B
ielif (∃ genau 2 B
is) then verbinde sie zu einem B
i+1elif (∃ genau ein B
i) then
¨ ubernimm es fi
od
Zeitkomplexit¨ at:
O(log
n) =
O(log(n1+ n
2))
Operationen f¨ ur Binomial Queues:
Insert: Die Insert-Operation wird einfach durch eine Merge-Operation mit einem B
0implementiert.
Beispiel 45
1 0 0 1 0 1 1 1
(B
7) (B
4) (B
2) (B
1) (B
0) 1
1 0 0 1 1 0 0 0
Zeitkomplexit¨ at:
O(logn)
EADS 5.1 Binomial Queues (binomial heaps) 165/530
ľErnst W. Mayr
Operationen f¨ ur Binomial Queues:
Initialisierung einer BQ durch n sukzessive Insert-Operationen:
Hier erg¨ abe die obige Absch¨ atzung einen Gesamtaufwand von
O(nlog n), was allerdings schlecht abgesch¨ atzt ist.
Wir sind an den Kosten zum sukzessiven Aufbau einer Binomial Queue mit n Elementen interessiert, die ¨ ubrigens identisch sind zum Aufwand f¨ ur das bin¨ are z¨ ahlen von 0 bis n, wenn jeder Z¨ ahlschritt und jeder ¨ Ubertrag jeweils eine Zeiteinheit kosten:
0 + 1
| {z }
1
+1
| {z }
2Schritte
+1
| {z }
1
+1
| {z }
3
+1
| {z }
1
Sei a
ndie Anzahl der Schritte (Einf¨ ugen des neuen Elements und anschließende Verschmelzungen) beim Mergen eines Knotens zu einer Queue mit n
−1 Elementen. Dann gilt f¨ ur a
n:
n a
n1 1 2 2 . . . 4 1 3 . . . 8 1 2 1 4
. . . 16 1 2 1 3 1 2 1 5
. . . 32 1 2 1 3 1 2 1 4 1 2 1 3 1 2 1 6 Man erkennt sofort, dass jede Zeile (außer den beiden ersten) doppelt so lange ist wie die vorhergehende und dabei die Folge aller vorhergehenden Zeilen enth¨ alt, wobei das letzte Element noch um eins erh¨ oht ist.
EADS 5.1 Binomial Queues (binomial heaps) 167/530
ľErnst W. Mayr
Damit ergibt sich f¨ ur den Gesamtaufwand der sukzessiven Erzeugung einer Binomial Queue mit n Elementen
T
n=
n
X
i=1
a
i= n +
jn 2
k+
jn 4
k+
jn 8
k+
· · ·≤
![h ( x )= a x mod p mod n f¨uralle x ∈ U. X Sei U = { 0 ,...,p − 1 } f¨ureinePrimzahl p .Zun¨achsteinigemathematischeGrundlagen. ∈ Z [ x ] vomGrad](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)