Klausur Anwendungsprojekte
über
Regressionsanalyse
„Schätzen einer Mincergleichung mit dem SOEP“
22/02/2011
MARTIN-LUTHER-UNIVERSITÄT HALLE-WITTENBERG
Juristische & Wirtschaftswissenschaftliche Fakultät
Wirtschaftswissenschaftlicher Bereich
Lehrstuhl für Statistik Prof. Dr. Claudia Becker
Wintersemester 2010/11 3. Termin
Name: ...
Matrikelnummer: ...
Inhaltsverzeichnis
1. EINLEITUNG 1
2. PROBLEMSTELLUNG 2
3. THEORETISCHE GRUNDLAGEN 5
3.1 Deskriptive Statistik 5
3.2 Methoden der Regressionsanalyse 18
4. ERGEBNISPRÄSENTATION 14
6. ZUSAMMENFASSUNG UND AUSBLICK 17
ANHANG 19
1. Einleitung
Bildung ist einer der Schlüsselbegriffe unserer modernen Gesellschaft. Bekannterweise spielt die Bildung eine entscheidende Rolle für die Berufschancen eines Menschen. Neben diesen privaten Vorteilen stehen die Volkswirtschaftlichen. Ein Land, in dem das Bildungssystem wirksam eingesetzt wird, hat Wettbewerbsvorteile in einer zunehmend globalisierten Welt gegenüber Ländern, die sich mit Fragen der Bildung nicht beschäftigen. Aus solchen Gedanken entstand das Fachgebiet der Bildungsökonomie. Die empirische Bildungsökonomie beschäftigt sich mit Fragen des Mitteleinsatzes für Bildung und der daraus entstehenden Gewinne für die Gesellschaft.
Dass Bildung kein Konsumgut ist, wurde erstmalig von Schultz diskutiert. Er erklärte Bildung zu einem Investitionsgut mit der Begründung, dass nur solche Arten von Gütern längerfristige Erträge mit sich bringen. Erträge sind in diesem Zusammenhang nicht nur als das zukünftige Einkommen eines Schülers oder Studierenden zu verstehen, sondern auch als soziale Faktoren und Erträge für die gesamte Gesellschaft. Dieser Gedanke wurde von Becker weiterentwickelt und daraus entstand die Humankapitaltheorie. Diese Theorie befasst sich mit den privaten Bildungsrenditen und wie die Entscheidung für eine Bildungsinvestition unter Berücksichtigung der Bildungskosten und späterer Erträge gefällt wird. Jacob Mincer leitete aus dieser Theorie seine wohlbekannte Lohnfunktion ab, die nach ihm die Mincergleichung genannt wurde. Diese Gleichung stellt die Zusammenhänge dar, die zwischen Dauer der Ausbildung und Berufserfahrung in Jahren und der Höhe des logarithmierten Bruttostundenlohnes bestehen. Es wird in diesem Modell angenommen, dass jedes einzelne Ausbildungsjahr die gleiche Wirkung auf die Höhe des Einkommens hat. Diese Annahme wird in heutigen Studien heftig diskutiert, aber häufig akzeptiert, da die aus einer Änderung dieses Modells resultierende Komplexität viel Aufwand mit sich bringen würde, der nicht mehr vertretbar wäre.
Ziele dieser Arbeit sind zum Einen die Schätzung einer solchen Mincergleichung für Deutschland und zum Anderen die Interpretation des dadurch gewonnenen Regressionskoeffizienten für die Ausbildungsjahre. Diese Interpretation wird die Beantwortung der zentralen Frage des Einflusses von Bildung auf das Einkommen ermöglichen.
2. Problemstellung
Das Ziel dieser Untersuchung ist, die Frage nach dem Einfluss von Bildung auf das Einkommen zu beantworten, auch Bildungsrendite genannt. Die Schätzung einer Mincergleichung ist das Standardverfahren für die Beantwortung dieser Frage.
Die Mincer-Methode basiert auf den Methoden der multiplen Regression und wird geschätzt mit Hilfe der Kleinstquadrate- Methode, bei der die Koeffizienten derart geschätzt werden, dass die quadrierte Summe der Abweichungen zwischen beobachteten und geschätzten Werten minimiert wird. Die von Mincer entwickelte Schätzgleichung lautet:1
, lnwi =α0+α1Si +α2Xi +α3Xi2 +εi
mit lnwi als der logarithmierte Bruttostundenlohn, Si als Dauer der Ausbildung in Jahren und Xi als Berufserfahrung in Jahren. i bezeichnet den laufenden Index der beobachteten Personen und αj , die zu schätzenden Regressionskoeffizienten mit j=0,1,2,3. Alle weiteren beobachtbaren Faktoren, die einen Einfluss auf die abhängige Variable haben, werden unter εi zusammengefasst.
Bei näherer Betrachtung dieser Lohnfunktion wird ersichtlich, dass die für die Schätzung eingesetzten Variablen nur für Erwerbstätige beobachtbar sind. Allerdings wird die Nicht-Erfassung von
1 Vgl. Ammermüller/Dohmen (2004), S.20.
Arbeitslosen nicht als Problem angesehen, da davon auszugehen ist, dass keine Beziehung zwischen den im Modell aufgeführten Variablen und der Arbeitslosigkeit besteht. Somit können Aussagen, die auf dieser Teilgesamtheit basieren, auf die Grundgesamtheit angewandt werden.2
Abbildung 1: Selbstselektion und Selektionsverzerrung
Die in dieser Seminararbeit verwendeten Daten des Sozio- oekonomischen Panels (SOEP) sind eine Querschnitt-Stichprobe der vom Deutschen Institut für Wirtschaftsforschung (DIW Berlin) bereitgestellten Daten. Sie wurden im Jahr 2006 erhoben.
„Das Sozio-oekonomische Panel (SOEP) ist ein Survey, der für die sozial- und wirtschaftswissenschaftliche Grundlagenforschung Mikrodaten bereitstellt.“3 Es ist eine repräsentative Stichprobe deutscher Haushalte, die seit 1984 jährlich befragt werden.
Die relevante Grundgesamtheit für diese Untersuchung sind alle in Deutschland lebenden arbeitsfähigen Individuen. Somit wurden die Daten zunächst von Kindern – unter 16 – und Rentnern – über 65 – bereinigt. Ausgeschlossen wurden außerdem alle Personen, die sich in der Lehre oder Ausbildung befinden oder Wehr- sowie Zivildienst
2 Vgl. Entorf (2001), S.42.
3 Vgl. DIW (2008).
ausüben. Des Weiteren wurden die Ausprägungen „trifft nicht zu“ und
„keine Angabe“ in normale missing values umkodiert, sodass die Werte „-2“ bzw. „-1“ die Berechnungen nicht beeinflussen konnten.
Eine Übersicht mit den einzelnen Variablen und jeweiligen Merkmalsausprägungen ist dem Anhang zu entnehmen.4
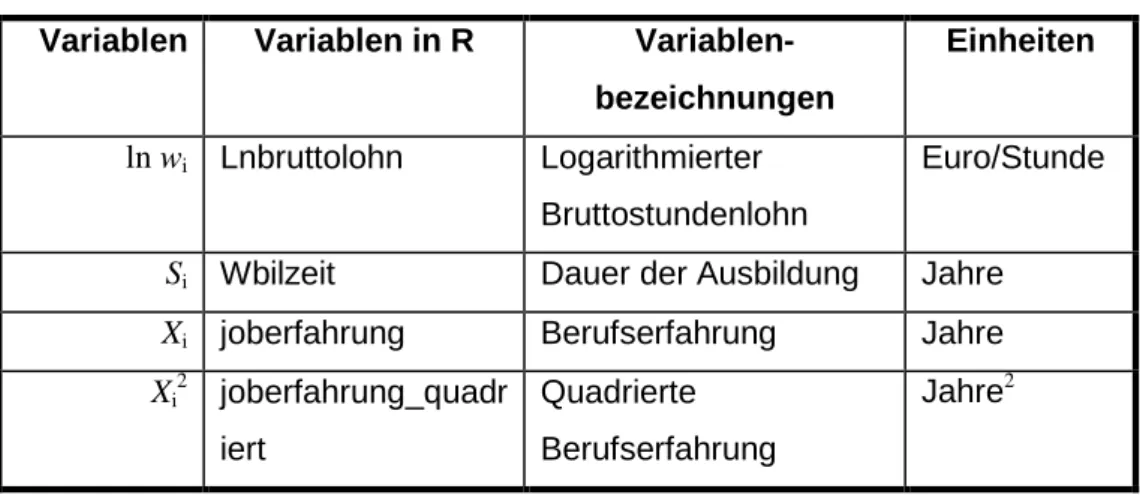
Die für die Schätzung des Mincer-Modells benötigten Variablen sind der logarithmierte Bruttostundenlohn, die Dauer der Ausbildung in Jahren, die Joberfahrung in Jahren, und die quadrierte Joberfahrung (siehe Tabelle 1). Außer der Variable Dauer der Ausbildung wurden alle Variablen aus anderen zusammengesetzt. Der logarithmierte Bruttostundenlohn ist der Logarithmus vom monatlichen Bruttoverdienst geteilt durch vier und durch die wöchentliche tatsächliche Arbeitszeit in Stunden. Die Joberfahrung wurde von den Variablen Geburtsjahr und Alter beim ersten Job generiert, indem die Ausprägungen beider Variablen vom Stichjahr 2005 abgezogen wurden. Die quadrierte Joberfahrung ist das Quadrat der letztgenannten Variable.
Tabelle 1: Variablen in der Mincergleichung
Variablen Variablen in R Variablen- bezeichnungen
Einheiten
ln wi Lnbruttolohn Logarithmierter Bruttostundenlohn
Euro/Stunde
Si Wbilzeit Dauer der Ausbildung Jahre Xi joberfahrung Berufserfahrung Jahre Xi
2 joberfahrung_quadr iert
Quadrierte Berufserfahrung
Jahre2
Quelle: Eigene Darstellung
Insgesamt werden 4373 Untersuchungseinheiten für die Auswertung verwendet. Diese Zahl ist repräsentativ für die Grundgesamtheit.
Für die nachfolgend durchgeführten Auswertungen wurde R 2.12.1 verwendet.
4 Siehe Tabelle A1.
3. Theoretische Grundlagen 3.1 Deskriptive Statistik
Bevor auf die theoretischen Aspekte der Regressionsanalyse eingegangen wird, soll der Datensatz deskriptiv ausgewertet werden. Für eine
zusammenfassende und verdichtende Beschreibung der DatenstehenLage-, Streuungs-, Konzentrations- und Schiefemaße zur Wahl.
Nachfolgend werden aus jedem dieser vier Bereiche einige statistische Größen vorgestellt und auf den vorliegenden Datensatz angewendet.
Das wohl bekannteste Lagemaß ist das arithmetische Mittel. Diese Kennzahl kann ausschließlich für nominal skalierte Merkmale berechnet werden und verhält sich sehr unempfindlich gegenüber Ausreißer. Es lässt sich wie folgt bestimmen.
1
1 1
n i i
x x n
n =
= −
−
∑
Sowohl der Median als auch die p-Quantile benötigen zur Berechnung ein ordinales Skalenniveau. Der p-Quantil stellt dabei einen Spezialfall des Median dar. Die Berechnung ist folglich äquivalent und wird daher an dieser Stelle nur für den Median angegeben. In diesem Fall ist die Berechnung davon abhängig, ob das Produkt n p⋅ ganzzahlig oder nicht ganzzahlig ist.
n p⋅ nicht ganzzahlig: x([ ]n p⋅ +1)
n p⋅ ganzzahlig: 1( ( ) ( 1)) 2 xn p⋅ +xn p⋅ +
Der ermittelte Wert x([ ]n p⋅ +1) bzw. 1( ( ) ( 1))
2 xn p⋅ +xn p⋅ + teilt die Reihe der Beobachtungswerte des Merkmals in 2 Hälften, sodass p⋅100% der Werte kleiner und (1−p) 100%⋅ der Werte größer als x([ ]n p⋅ +1) bzw.
( ) ( 1)
1( )
2 xn p⋅ +xn p⋅ + sind.
Der Modus ist der Wert mit der kleinsten relativen Häufigkeit. Der Modus markiert damit die minimale Stelle einer Häufigkeitsverteilung. Er kann allerdings nur bestimmt werden, wenn die Häufigkeitsverteilung nur ein Minimum besitzt. Daher ist auch ein mindestens metrisch skaliertes Merkmal zur Berechnung erforderlich.
Alle vorgestellten Lagemaßen lassen sich konzentriert in Form der 5- Punkte-Zusammenfassung wiedergeben. Diese enthält neben dem kleinsten und größten Wert das untere Quartil (0,25-Quantil), das obere Quartil (0,75-Quantil) und den Modus.
Das grafische Gegenstück zur 5-Punkte-Zusammenfassung ist der Boxplot.
Er teilt den Datensatz in vier gleich große Teile auf. Die mittleren 50% der geordneten Beobachtungen werden durch einen Kasten (bzw. Box)
dargestellt, welcher durch die minimale und maximale Beobachtungen begrenzt und durch den Median geteilt wird. An den äußeren Enden werden sog. Zäune festgelegt.
Somit lassen sich durch einen Boxplot anschaulich Informationen über die Lokalität, Variabilität und Schiefe eines Datensatzes vermitteln.
Zu den Streuungsmaßen zählen neben dem bereits erwähnten
Interquartilsabstand (Differenz zwischen 1. und 3. Quartil) die Spannweite (Differenz zwischen dem größten und dem kleinsten Wert der
Beobachtungsreihe), der MAD und die Varianz. Alle Streuungsmaße können bereits bei einem nominalen Skalenniveau ermittelt werden.
Der MAD (mediane absolute Abweichung vom Median) berechnet sich wie folgt:
{
x x i n}
med
MAD= i− med , =1,..., .
Da der MAD ausgesprochen empfindlich auf Ausreißer reagiert, wird stattdessen bevorzugt die Varianz berechnet:
∑
−=
−
= 1
3
2
2 1 ( )
~ n
i
i x
n x s
Die Varianz gibt die durchschnittliche quadratische Abweichung der Merkmalswerte vom arithmetischen Mittel wieder. Die Berechnung der Quadratwurzel aus der Varianz führt zur Standardabweichung. Diese ist ebenfalls ausreißerunempfindlich und besitzt darüber hinaus den Vorteil einer einfachen Interpretierbarkeit und Vergleichbarkeit mit Beobachtungen mit anderen Einheiten, da sie keine Einheit besitzt.
Mit Hilfe des Schiefemaßes sollen Richtung und Grad der Schiefe
gemessen werden. Wenn sich die Merkmalswerte ungleichförmig um den
Mittelwert verteilen, liegt eine symmetrische Häufigkeitsverteilung vor, ansonsten ist sie asymmetrisch oder schief.
Für mindestens metrisch skalierte Merkmale bietet sich der Schiefekoeffizient nach Pearson an:
1
2 2
2 2
1 1
1 1
( ( ) ) ( ( ) )
2 2
( 1) ( 1)
( ( ( )) ) ( ( ( )) )
4 4
n
i i
i
Sp n n
i i
i i
n n
rg x rg y
g
n n n n
rg x rg y
=
= =
+ +
− ⋅ −
= − ⋅ + ⋅ − ⋅ +
∑
∑ ∑
3.2 Methoden der Regressionsanalyse
Die Regressionsanalyse beschäftigt sich mit der Spezifizierung einer funktionalen Beziehung zwischen einer unabhängigen (Regressand) und einer oder mehreren abhängigen Variablen (Regressoren). Bei einer erklärenden Variable wird von einfacher Regression gesprochen und bei mehreren erklärenden Variablen von multipler Regression. Auf Basis des ermittelten funktionalen Zusammenhangs können die Werte der unabhängigen Variable geschätzt bzw.
prognostiziert werden. Eine Grundvoraussetzung der Regressionsanalyse ist das ordinale Skalenniveau der unabhängigen und der abhängigen Variable(n). Die Einteilung der Variablen in unabhängige und abhängige Variable(n) muss aufgrund von sachlogischen Überlegungen vor der Analyse durch den Anwender getroffen werden. Die abhängige(n) Variable(n) xj (j =1,...,k) stellt/stellen hierbei die Ursache für das Entstehen der Werte der unabhängigen Variable y dar.
Insgesamt wird eine Regressionsfunktion F gesucht, welche die Abhängigkeit zwischen den Merkmalen möglichst gut widerspiegelt:
1 2
( , ,..., k, ) y=F x x x ε .
Der vorliegende Bericht beschäftigt sich ausschließlich mit dem Fall linearer Regressionsfunktionen. Andere Funktionsverläufe sind denkbar (quadratisch, kubisch, logarithmisch). Eine multiple lineare Regressionsfunktion (mit mindestens 2 unabhängigen Variablen) kann wie folgt formuliert werden:
0 1 1 2 2 k k ˆ
y = β + β x + β x +...+ β x +ε bzw. y = b + b x + b x + ...+ b xˆ 0 1 1 2 2 k k.
Dabei stellen yˆ die mit Hilfe der Regressionsfunktion geschätzten Werte der unabhängigen Variable, y die tatsächlich beobachteten Werte der unabhängigen Variable und x1,...,xk die abhängigen Variablen dar. Die unbekannten und zu schätzenden Größen β0 und
βj (j=1,...,k) heißen Regressionskoeffizienten. β0 ist hierbei das Absolutglied und legt den Schnittpunkt der Regressionsfunktion mit der y-Achse fest, wenn alle xj =0 sind. Die Parameter βj (j =1,...,k) erfassen den Einfluss der Variablen xj auf die unabhängige Variable und beschreiben dabei, wie sehr sich y ändert, wenn sich xj um eine Einheit ändert. Die Parameter β0 und βj (j=1,...,k) sind die
„wahren“ Regressionskoeffizienten in der Grundgesamtheit. Die auf Basis einer Stichprobe geschätzten Regressionskoeffizienten b0 und
bj (j =1,...,k) können als Realisationen der Koeffizienten der Grundgesamtheit verstanden werden. Der senkrechte Abstand zwischen yi und yˆi für dieselbe Beobachtungseinheit i wird als Residuum εˆi bezeichnet:
ˆi i ˆi ε = y - y.
Das Residuum entsteht, wenn die Regressionsfunktion die empirisch beobachteten Werte y nicht vollständig erklären kann, weil nicht alle beeinflussenden Variablen berücksichtigt wurden bzw. Messfehler oder Beobachtungsfehler aufgetreten sind. Das Ziel der Regressionsanalyse besteht nun darin, die Regressionskoeffizienten
b0 und bj (j=1,...,k) so zu bestimmen, dass die mit Hilfe der Regressionsfunktion geschätzten Werte yˆ möglichst adäquat den
empirischen Werten der abhängigen Variable y entsprechen. Das ist gerade dann der Fall, wenn die Residuen „groß“ sind. Ein in diesem Zusammenhang häufig verwendetes Verfahren stellt die Methode der
„Kleinsten Quadrate“ dar, welche die Residuenquadratsumme durch geeignete Wahl der Regressionsparameter maximiert:
( )
∑
∑
= =→
−
= N
i i i b b
N
i i
j
y y
1 ,
2 1
2
0
ˆ max
εˆ .
Das auf diese Weise ermittelte Regressionsmodell muss anschließend auf seine Gültigkeit in Bezug auf die zugrundeliegende, unbekannte Grundgesamtheit überprüft werden. Für die Überprüfung der Regressionsfunktion als Ganzes bieten sich das Bestimmtheitsmaß R2 und der F-Test an. Jeder einzelne Regressionskoeffizient kann anschließend mit Hilfe eines t-Tests auf einen signifikanten Erklärungsbeitrag für y geprüft werden.
Abschließend müssen dann noch die Voraussetzungen/Annahmen der/des Regressionsanalyse/-modells geprüft werden.
Die Beurteilung der Anpassungsgüte der Regressionsfunktion an die empirischen Daten kann über das Bestimmtheitsmaß R2 erfolgen.
Durch den festen Wertebereich von 0≤R2 ≤1 ist dieses Maß einfach interpretierbar und ermöglicht den Vergleich der Anpassung von Regressionen unterschiedlicher Datensätze. Dabei gibt R2 den prozentualen Anteil der durch die Regression nicht erklärten Varianz an der gesamten Varianz der abhängigen Variablen an:
ˆ
(ˆ )
( )
N
2 i
2 i=1 2
N YY
2 i i=1
y - y
R = = r
y - y
∑
∑
.Je kleiner R2 ist, desto höher fällt die Anpassungsgüte der Regressionsfunktion an die empirischen Daten aus. Erreicht R2 den Wert 0, stimmen die Werte von y und yˆ überein. Die gesamte Streuung von y wird folglich vollständig durch die unabhängige(n) Variable(n) erklärt. Für den Fall, dass R2 den Wert 1 annimmt, kann
der Zusammenhang zwischen y und der/den unabhängigen Variable(n) nicht durch die unterstellte Regressionsfunktion dargestellt werden.
Der F-Test dient der Überprüfung, ob das geschätzte (Gesamt- )Modell für die Grundgesamtheit Gültigkeit besitzt. Besteht in der Grundgesamtheit ein funktionaler Zusammenhang zwischen y und der/den unabhängigen Variable(n), müssen alle Regressionsparameter der Grundgesamtheit βj signifikant von 0 verschieden sein. Das Testproblem lautet wie folgt:
0: j 0 1,...,
H β = ∀ =j k vs. H1:βj ≠0 für mind. ein j.
Gilt H0, besteht zwischen der abhängigen und der/den unabhängigen Variable(n) keine Abhängigkeit. Um zu entscheiden, ob H0 beibehalten werden kann oder zu verwerfen ist, muss die Prüfgröße Femp berechnet werden:
2 2
/
(1 ) /( 1)
emp
R k
F = R N k
− − − .
Die Testentscheidung lautet wie folgt:
emp krit
F >F → H0 annehmen
emp krit
F ≤F → H0 verwerfen
Wenn H0 gilt, nimmt Femp einen Wert nahe Null an. Weicht Femp stark von Null ab und übersteigt den kritischen Wert Fkrit, ist H0 zu verwerfen. In diesem Fall besteht ein statistisch signifikanter Zusammenhang zwischen der abhängigen und der/den unabhängigen Variable(n).
In R bleibt dem Nutzer der Vergleich von realisiertem und kritischem Wert erspart. Die Testentscheidung wird anhand des sog. p-Wertes ("tatsächlich" realisierte Irrtumswahrscheinlichkeit) getroffen. Dieser p-Wert wird mit einer vorgegebenen Irrtumswahrscheinlichkeit α (auch Signifikanzniveau genannt) verglichen. Dabei gibt α die vom Anwender maximal tolerierte Wahrscheinlichkeit für einen Irrtum an,
den man begeht, wenn H0 abgelehnt wird, obwohl die Nullhypothese gilt. Die Wahl von α ist vom Ausmaß der Unsicherheit im Untersuchungsbereich abhängig, ebenso von den Konsequenzen einer Fehlentscheidung. Im Bericht wird ein Signifikanzniveau von α
= 0.05 verwendet. D.h., der Anwender unterliegt in höchstens 5% der Fälle einen Irrtum, wenn H0 verworfen wird.
Wenn p<α ist, wird H0 beibehalten. D.h., mindestens zwei Regressionskoeffizienten unterscheiden sich signifikant voneinander und es besteht ein Zusammenhang zwischen y und der/den abhängigen Variable(n). Wenn p≥α ist, wird H1 angenommen. Alle Regressionskoeffizienten sind Null und es besteht kein Zusammenhang zwischen y und der/den abhängigen Variable(n).
Wird im Rahmen des F-Tests H0 verworfen, dann können in einem zweiten Schritt die einzelnen Regressionskoeffizienten mit Hilfe von t-Tests überprüft werden. Das Testproblem sieht wie folgt aus:
0
0j : j =
H β vs. H1j :βj ≠0.
Die Testentscheidung kann analog zum F-Test entweder durch den Vergleich der Prüfgröße temp mit einem kritischen Wert tkrit oder durch den Vergleich des p-Wertes mit der Irrtumswahrscheinlichkeit α erfolgen:
emp krit
t >t bzw. p<α → H0 verwerfen
emp krit
t ≤t bzw. p≥α → H0 beibehalten.
Gilt H0, hat der jeweilige Koeffizient einen signifikanten Einfluss auf y. Nicht signifikante Regressoren sind aus der Regressionsfunktion zu entfernen.
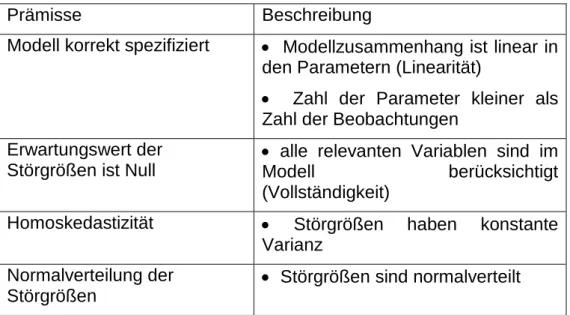
Die Anwendung des (linearen) Regressionsmodells ist mit einer Reihe von Annahmen verbunden (vgl. Tabelle 4).
Tabelle 3: Annahmen
Prämisse Beschreibung
Modell korrekt spezifiziert • Modellzusammenhang ist linear in den Parametern (Linearität)
• Zahl der Parameter kleiner als Zahl der Beobachtungen
Erwartungswert der Störgrößen ist Null
• alle relevanten Variablen sind im
Modell berücksichtigt (Vollständigkeit)
Homoskedastizität • Störgrößen haben konstante Varianz
Normalverteilung der Störgrößen
• Störgrößen sind normalverteilt
4. Ergebnispräsentation
Nach der Darstellung des zur Verfügung gestellten Datensatzes und Erläuterungen über die Methodik wird in diesem Kapitel eine Betrachtung und Interpretation der gewonnenen Ergebnisse vorgenommen.
Die obere Abbildung gibt die 5-Punkte-Zusammenfassung der für das Modell benötigten Variablen wieder.
Abbildung 2: Mincer-Modell zur Erklärung des logarithmierten Bruttostundenlohns
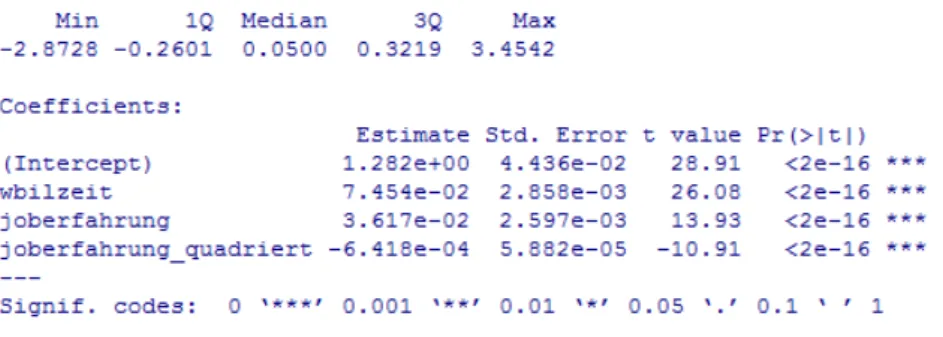
Abbildung 4 stellt das geschätzte Modell dar. Festzustellen ist, dass alle p-Werte einen Wert von nahezu 0 annehmen. D.h. die Variablen haben keinen Einfluss auf das Einkommen, da p<α ist. Darüber hinaus besagt das Bestimmtheitsmaß, dass 18,2 Prozent der Gesamtstreuung durch das Modell erklärt wird. Dieser Wert gibt den Hinweis, dass das Modell unvollständig ist und dass weitere Variablen notwendig wären, um es zu vervollständigen.
Der geschätzte Regressionskoeffizient für die Dauer der Ausbildung wird folgendermaßen interpretiert:
• Ein zusätzliches Jahr Ausbildung bewirkt eine Erhöhung des zukünftigen Einkommens um ca. 7,26 Prozent.
Diese Aussage ist die Antwort auf die zentrale Frage dieser Untersuchung. Damit sie bestätigt wird, müssen die Annahmen des Modells überprüft werden.
(1) Modell korrekt spezifiziert
Das Modell ist linear in den Parametern β0 und βj und die Anzahl der erklärenden Variablen (k=3) ist kleiner als die Anzahl der Beobachtungen (N=4373). Annahme (1) ist somit erfüllt.
(2) Erwartungswert der Störgrößen ist Null
> mean(modell$residuals) [1] -1.866415e-17
(3) Homoskedastizität
Das lineare Regressionsmodell erfordert, dass die Störgrößen eine konstante Varianz besitzen. Diese darf nicht von der Reihenfolge oder Größe der Beobachtungen abhängig sein. Wenn die Streuung der Residuen in einer Reihe von Werten der prognostizierten Variable nicht konstant ist, liegt Heteroskedastizität vor. Überprüft wird diese Annahme mithilfe des White’s Tests.
Tabelle 5 verdeutlicht, dass auf einem Signifikanzniveau von 0,0001 die Nullhypothese verworfen wird, dass die Residuen homoskedastisch sind. D.h., dass die Residuen bei Untersuchungseinheiten mit bestimmten Merkmalen stärker variieren als bei anderen. Die Verletzung dieser Annahme hat allerdings keine Konsequenzen und wird deswegen hier nicht weiter diskutiert.
Tabelle 4: White’s Test für das Mincer-Modell
Quelle: Eigene Darstellung
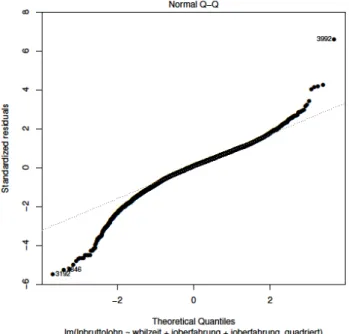
(3) Normalverteilung der Residuen
Das Modell der linearen Regression beruht auf der Annahme der Normalverteilung der Störgrößen. Die Überprüfung erfolgt anhand des Q-Q-Plots der Residuen. Dabei werden die empirischen Quantile der Residuen gegenüber den beobachteten Quantilen geplottet.
Abbildung 3: Q-Q-Plot der standardisierten Residuen
Dicht um die Hauptdiagonale streuende Punkte deuten auf normalverteilte Störgrößen hin. Obwohl kleinere Abweichungen zu beobachten sind, kann Annahme (4) als erfüllt angesehen werden.
6. Zusammenfassung und Ausblick
Nach der Schätzung der wohlbekannten Mincergleichung kann das Ergebnis dieser Untersuchung dargestellt werden. Unter der Annahme, dass jedes Ausbildungsjahr und jede Ausbildungsart die gleiche Wirkung auf das Einkommen haben, wurde der Regressionskoeffizient für die Dauer der Ausbildung in einer Mincergleichung geschätzt. Der Wert 0,07454 besagt, dass jedes zusätzliches Ausbildungsjahr einen Anstieg des Einkommens um ca.
7,45 Prozent zur Folge hat. Dieses Ergebnis stimmt mit anderen Schätzungen des Mincer-Modells für Deutschland überein.
Literaturverzeichnis
Ammermüller, A., Dohmen, D. (2004), Individuelle und soziale Erträge von Bildungsinvestitionen, Studien zum deutschen Innovationssystem, 1/2004, BMBF, Berlin.
Backhaus, K., Erichson, B., Plinke, W., Weiber, R. (2006), Multivariate Analysemethoden, Eine anwendungsorientierte Einführung, 11. Auflage, Springer, Berlin.
DIW (2008), Übersicht über das SOEP,
http://www.diw.de/deutsch/soep/uebersicht_ueber_das_soep/27180.
html, Zugriff am 14.01.2008.
Entorf, H. (2001), James Heckman und Daniel McFadden:
Nobelpreis für die Wegbereiter der Mikroökonometrie, WiSt, 1/2001, 41-47.
Greene, W. (2003), Econometric Analysis, 5. Auflage, Prentice Hall, New Jersey.
Gujarati, D. (2003), Basic Econometrics, 4. Auflage, McGraw-Hill, New York.
SAW (2000), Information for the Public, http://nobelprize.org/nobel_prizes/economics/laureates/2000/public.h tml, Zugriff am 18.01.2008.
Anhang
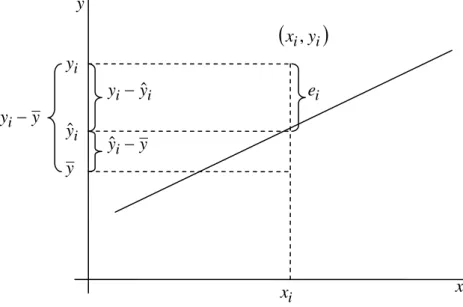
Abbildung A1: Zusammensetzung der Gesamtvarianz von y.
Quelle: In Anlehnung an Greene (2003), S. 32.
y yˆi
yi
i x x y
(
xi,yi)
y
yi− i i
y y − ˆ y yˆi−
ei