MARTIN-LUTHER-UNIVERSITÄT HALLE-WITTENBERG
Juristische und Wirtschaftswissenschaftliche Fakultät Wirtschaftswissenschaftlicher Bereich
Lehrstuhl für Statistik Prof. Dr. Claudia Becker
Wintersemester 2007/08 1. Termin
Klausur Anwendungsprojekte
über Varianzanalyse
„Einflussgrößen auf die Pizza-Lieferzeit“
14.02.2008
Name: ...
Matrikelnummer: ...
Inhaltsverzeichnis
1. Einleitung ... 1
2. Problemstellung ... 2
3. Theoretische Grundlagen der statistischen Verfahren ... 4
3.1 Deskriptive Verfahren ... 4
3.2 Varianzanalyse ... 8
4. Statistische Auswertung ... 10
1. Einleitung
Im harten Wettbewerb der Pizza-Lieferservice-Unternehmen spielt - neben der Qualität und dem Preis der Pizza - vor Allem die Liefergeschwindigkeit eine große Rolle. Eine kurze Lieferzeit kann sich dabei unter Umständen als entscheidender Wettbewerbsvorteil herausstellen. So versprechen viele Piz- za-Lieferservice-Unternehmen eine Lieferung in einer eng begrenzten Zeit- spanne, um sich von Wettbewerbern zu differenzieren. Manche Unterneh- men garantieren sogar, dass der Kunde die Pizza kostenlos erhält, wenn die versprochene Lieferzeit nicht eingehalten wird.
Doch was sind die wesentlichen Einflussfaktoren auf die Lieferzeit? Neben unternehmensexternen Einflussfaktoren wie die Entfernung des Kunden zum Pizza-Lieferservice-Unternehmen, Witterungseinflüssen / höherer Gewalt oder Lieferverzögerungen durch Stoßzeiten (Zeiten mit hoher Bestell- und/oder Verkehrsdichte) haben ebenso unternehmensinterne Faktoren Auswirkungen auf die Lieferzeit. Denn sind die Prozesse bei der Bestellauf- nahme, beim Backen der Pizza und bei der Zusammenstellung der Lieferung nicht gut aufeinander abgestimmt, kommt es zu langen Lieferzeiten und un- zufriedenen Kunden. Daher werden im Rahmen dieser Arbeit die unterneh- mensinternen Faktoren analysiert. Das Ziel der Arbeit besteht darin, festzu- stellen, welche Faktoren einen Einfluss auf die Lieferzeit haben, um Hand- lungsempfehlungen für die Organisation der betriebsinternen Prozesse ablei- ten zu können. Als Auswertungsverfahren wird dabei die Varianzanalyse ge- nutzt.
Als Hauptergebnis lässt sich feststellen, dass v.a. die Art des Pizzarandes die Lieferzeit bestimmt.
Die weiteren Kapitel gliedern sich wie folgt:
2. Problemstellung
3. Theoretische Grundlagen der statistischen Verfahren 3.1 Deskriptive Verfahren
3.2 Varianzanalyse 4. Statistische Auswertung
2. Problemstellung
Viele Pizza-Lieferservice-Unternehmen versprechen die Lieferung innerhalb einer bestimmten Zeitspanne und garantieren u.U. sogar, dass der Kunde bei verspäteter Lieferung die Pizza kostenlos erhält. Dieses Service- Versprechen hat seinen Ursprung in den USA, wo in den 80’er und den frü- her 90’er Jahren ein Pizza-Lieferservice-Unternehmen in einer aggressiven Werbekampagne garantierte, dass die Lieferung innerhalb von 30 Minuten erfolgt, oder die Pizza ansonsten kostenlos sein würde („30 minutes or it’s free“).1 Allerdings wurde diese Praxis 1993 wegen einer Vielzahl von Ver- kehrsunfällen und Prozessen eingestellt, die von eiligen Pizzafahrern des Unternehmens verursacht wurden. Jedoch hat das Service-Versprechen da- zu beigetragen, dass das Pizza-Lieferservice-Unternehmen deutliche Markt- anteilsgewinne und später die Marktführerschaft verzeichnen konnte. Insge- samt zeigt sich, dass die Lieferzeit anscheinend eines der wichtigsten Krite- rien bei der Auswahl eines Pizza-Lieferservice-Unternehmens sein kann.
Dabei werden in diesem Bericht ausschließlich die unternehmensinternen Einflussfaktoren auf die Lieferzeit analysiert.
Der Arbeit liegt dabei ein Datensatz einer Erhebung in einer Filiale eines Piz- za-Lieferservice-Unternehmens zu Grunde. Im Vorfeld der Erhebung wurden als mögliche Einflussfaktoren auf die Lieferzeit die Art der zu backenden Piz- za, das Geschlecht des Fahrers und eventuelle Zusatzwünsche bei der Kun- denbestellung identifiziert. Für die Durchführung der Erhebung wurden 16 Freiwillige von einem Filialleiter eines Pizza-Lieferservice-Unternehmens be- auftragt, Bestellungen bei derselben Filiale des Pizza-Lieferservice- Unternehmens aufzugeben und die Zeit von der Bestellung bis zur Lieferung zu messen.
Um vergleichbare Bedingungen bei den 16 Bestellungen zu gewährleisten, wurden die Freiwilligen so ausgewählt, dass sie in benachbarten Häusern einer Straße leben und somit eine vergleichbare Wegstrecke für den jeweili- gen Pizza-Fahrers zurückzulegen ist. Ebenso wurde die Variante der zu be- stellenden Pizza vorgegeben (Durchmesser 26 cm, Pizza Supreme). Die Be- stellungen mussten an vorgegebenen, vergleichbaren Tagen zu ungefähr
1 Vgl. http://www.chopchop.ch/blog/index.php?entry=entry070110-125249
derselben Uhrzeit per Telefon erfolgen. Da durch dieses Vorgehen nahezu identische Bedingungen erzeugt wurden und dadurch eine Vielzahl möglicher unternehmensexterner Einflussfaktoren ausgeschaltet werden, kann von Re- präsentativität des Datensatzes ausgegangen werden.
Im Rahmen der Studie wurde die Lieferzeit (in Minuten) erfasst, die sich als Zeitspanne vom Auflegen des Telefons bei der Bestellung bis zur Pizza- Lieferung an die Haustür (Klingeln des Pizza-Fahrers) berechnen lässt. Ne- ben der Lieferzeit wurden weiterhin der genaue Bestellzeitpunkt (Uhrzeit), das Geschlecht des Pizza-Fahrers, Zusatzwünsche bei der Bestellung (Piz- zabrot, Cola) und die Randstärke der Pizza erhoben. Die Merkmale des Da- tensatzes und deren Eigenschaften können Tabelle 1 entnommen werden.
Der Datensatz umfasst 16 Beobachtungen. Bei allen Beobachtungen sind Angaben zu allen erhobenen Merkmalen verfügbar, so dass keine fehlenden Werte auftreten.
Tabelle 1: Merkmale des Datensatzes
Merkmal Ausprägungen/Einheit Skalenniveau
Rand Dünn = 0
Dick = 1
metrisch diskret
Cola Ja = 1
Nein = 0
metrisch diskret
Brot Ja = 1
Nein = 0
metrisch diskret
Fahrer Frau = F
Mann = M
ordinal
Bestellzeitpunkt Uhrzeit nominal
Lieferzeit Minuten nominal
Der Datensatz lag in Form einer txt-Datei vor und konnte daher ohne Anpas- sungen und ohne Probleme über den R-Commander in R eingelesen wer- den. Dazu ist im Menü des R-Commander zu wählen: Data\Import Data\from text file und den Anweisungen im sich nun öffnenden Fenster zu folgen.
3. Theoretische Grundlagen der statistischen Verfahren 3.1 Deskriptive Verfahren
Bevor die eigentliche Auswertung der Daten mit Hilfe der Varianzanalyse erfolgt, ist es empfehlenswert, den Datensatz deskriptiv zu analysieren. Da- bei wird das Ziel verfolgt, durch die Angabe einiger weniger Kennzahlen die gesamten Verteilungen der einzelnen Merkmale zu charakterisieren und so- mit die zu analysierende statistische Masse zusammenfassend beurteilen zu können. Solche Kennzahlen werden auch Parameter einer Verteilung ge- nannt. Die unterschiedlichen Kennzahlen geben u.a. Auskunft zur Lage, Streuung oder Schiefe der Verteilung einer Variablen.
Lageparameter geben Auskunft über die durchschnittliche Größenordnung der Merkmalswerte einer Beobachtungsreihe und somit über die Lage des Zentrums einer Verteilung. Sie sollen die Gesamtheit der Beobachtungswerte möglichst gut repräsentieren. Der für qualitative Merkmale am häufigsten verwendete Lageparameter ist das arithmetische Mittel x. Es beschreibt jenen Wert, der sich ergibt, wenn die gesamte Merkmalssumme auf alle n Merkmalsträger zu gleichen Teilen aufgeteilt wird:
n i i 1
x 1 x
n 1 =
= −
∑
.Die Aussagefähigkeit von x wird dadurch eingeschränkt, dass es von Aus- reißern beeinflusst wird.
Daher wird für quantitative Merkmale als Lageparameter bevorzugt der Mo- dus berechnet. Als Modus xmod wird jede Merkmalsausprägung eines min- destens metrisch skalierten Merkmals bezeichnet, welche die Reihe der ge- ordneten Beobachtungswerte x1≤x2 ≤ ≤... xn in zwei Hälften teilt. Er reprä- sentiert die Mitte der Verteilung und ist durch seine Berechnung extrem un- empfindlich gegen außergewöhnlich hohe/niedrige und somit untypische Be- obachtungen (Ausreißer).
Die Lageparameter reichen zur Charakterisierung einer Häufigkeitsverteilung oft nicht aus. In vielen Fällen ist es auch wichtig zu wissen, wie eng die Beo- bachtungswerte beieinander liegen oder wie weit sie um einen Lageparame- ter streuen. Je größer die Abweichungen vom Lageparameter sind, desto
besser repräsentiert dieser den Datensatz. Das am häufigsten verwendete Streuungsmaß sind die p-Quantile. Als p-Quantil xp wird eine Merk- malsausprägung eines mindestens ordinal skalierten Merkmals bezeichnet, wenn dieser Wert die Reihe der Beobachtungswerte so aufteilt, dass höchs- tens p% der Beobachtungswerte größer als xp sind und gleichzeitig höchs- tens (1-p)% der Beobachtungswerte kleiner als xp sind. Je größer der Wert (1-p) ausfällt, desto größer ist die Streuung des Merkmals. Die großen Vortei- le dieses Streuungsmaßes liegen zum Einen in der einfachen Berechenbar- keit und zum Anderen darin, dass auf eine Sortierung der Merkmalswerte verzichtet werden kann.
Durch Lage- und Streuungsparameter kann eine Häufigkeitsverteilung oft ausreichend charakterisiert werden. Es gibt aber Fälle, in denen Verteilungen sowohl in Lageparametern als auch in Streuungsmaßen übereinstimmen, aber eine völlig unterschiedliche Gestalt aufweisen. So ist es in diesen Fällen erforderlich, weitere Kennzahlen wie z.B. die Schiefe zur Charakterisierung der Verteilung heranzuziehen. Die Schiefe beschreibt dabei, inwieweit bei der Verteilung eine Symmetrie bzw. Asymmetrie (Schiefe) vorliegt. Verteilen sich die Beobachtungswerte eines mindestens nominal skalierten Merkmals gleichförmig zu beiden Seiten um den Mittelwert x, liegt eine symmetrische Häufigkeitsverteilung vor. Anderenfalls ist die Häufigkeitsverteilung asymmet- risch bzw. schief.
Um die Ausgeprägtheit der Schiefe der Verteilung mit einer Maßzahl zu mes- sen, wird in der Regel auf die Standardabweichung zurückgegriffen. Als Standardabweichung s wird die durchschnittliche quadratische Abweichung der Merkmalswerte von xmod bezeichnet:
n
2 mod i 1
s 1 (x x )
n =
=
∑
− .Sobald s positiv wird (s>0), handelt es sich um eine rechtsschiefe (rechts- steile) Verteilung, bei s<0 um eine linksschiefe (linkssteile) Verteilung. Soll- te s=0 sein, liegt eine symmetrische Verteilung vor.
Die Standardabweichung besitzt als Maßeinheit die Einheit des Merkmals, für das sie berechnet wurde, und ist daher kaum zu interpretieren. Daher wird für solche Zwecke vor allem die Varianz s2 herangezogen, die durch
> table(Pizza$label.Rand) dünn dick
8 8
> table(Pizza$label.Cola) nein ja
8 8
> table(Pizza$label.Brot) nein ja
8 8
> table(Pizza$label.Fahrer) Frau Mann
4 12
einen festen Wertebereich von − ≤1 s2 ≤ +1 anschaulich interpretiert werden kann.
Neben der Berechnung der Parameter einer Verteilung empfiehlt es sich, auch die graphische Darstellung einer Häufigkeitsverteilung zu analysieren.
Zur graphischen Darstellung eignen sich Kreisdiagramme für diskrete Merk- male, Boxplots für nominale Merkmale und Stab- bzw. Balkendiagramme für stetige Merkmale. In allen Graphiken werden die Verteilungsparameter mit ihren relativen bzw. absoluten Häufigkeiten abgetragen.
Im Folgenden erfolgt die Darstellung der deskriptiven Analysen für alle beo- bachteten Variablen. Zuerst werden die Häufigkeitsverteilungen der Merkma- le Rand, Cola und Fahrer dargestellt (vgl. Tabelle 2 und Abbildung 1). Die Häufigkeitsverteilungen können in R mit dem Befehl table(...) erzeugt wer- den.
Tabelle 2: Häufigkeitsverteilung
In Tabelle 2 ist ein klarer Trend zu erkennen: Frauen ernähren sich gesünder als Männer. Ebenso ist zu sehen, dass die Kunden bei ihrer Bestellung 8mal öfter einen dicken anstatt eines dünnen Randes bestellen und ebenso 8mal öfter Cola und Brot mitbestellen, als auf Brot und Cola zu verzichten.
Abbildung 1: Häufigkeitsverteilung von Cola, Brot und Rand
dünn
dick
nein
ja
Bei der Analyse des Histogramms der Variable Bestellzeitpunkt lässt sich feststellen, dass es sich hierbei um eine zweigipflige, weitgehend symmetri- sche Verteilung handelt, da die Werte gleichmäßig um den Mittelwert ange- ordnet sind (vgl. Abb. 2).
Abbildung 2: Histogramm der Häufigkeitsverteilung von Bestellzeitpunkt
20.37 20.52 20.6 20.62 20.68 20.7 20.75 20.78 20.87 20.9 20.95 20.97 20.98 21.08
0.00.51.01.52.0
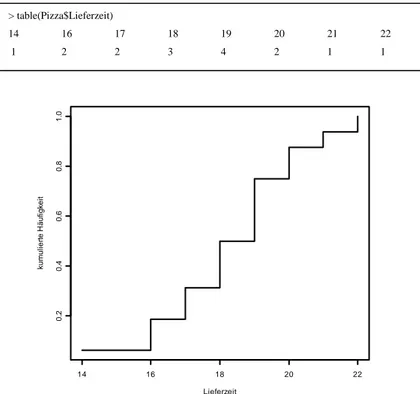
In Abbildung 3 ist die Häufigkeitsverteilung der Lieferzeit graphisch darge- stellt. Wie zu erkennen ist, verzerrt der deutliche Ausreißer am unteren Ende des Beobachtungsbereiches den Gesamtmittelwert.
> table(Pizza$Bestellzeitpunkt)
20.37 20.52 20.6 20.62 20.68 20.7 20.75 20.78 20.87 20.9 20.95 20.97 20.98 21.08
1 1 1 1 1 2 1 2 1 1 1 1 1 1
Abbildung 3: Häufigkeitsverteilung von Lieferzeit
14 16 18 20 22
0.20.40.60.81.0
Lieferzeit
kumulierte Häufigkeit
3.2 Varianzanalyse
Mit Hilfe der Varianzanalyse kann die Abhängigkeit einer nominal skalierten abhängigen Variable von einer metrisch skalierten unabhängigen Variablen untersucht werden. Die unabhängige Variable wird als Faktor bezeichnet, die Ausprägungen des Faktors als Faktorstufen.
Die analytische Idee der Varianzanalyse besteht darin, eine beliebige Anzahl von Erwartungswerten normalverteilter Grundgesamtheiten auf Basis von Stichprobendaten zu vergleichen. Die verschiedenen Grundgesamtheiten und daraus resultierenden Stichprobengruppen werden dabei durch die Fak- torstufen j=1,..,k abgegrenzt. Die Zielstellung der Varianzanalyse ist festzu- stellen, ob sich die durch den Faktor gebildeten Faktorstufen hinsichtlich der Erwartungswerte der abhängigen Variable unterscheiden.
Beobachtet werden in einer Stichprobe einer jeden Faktorstufe die Ausprä- gungen der abhängigen Variable Y. Somit sind j=1,…,k Stichprobengruppen mit je nj Untersuchungseinheiten gegeben, für die gilt:
n n
k
j j =
∑
=1.
Die beobachteten Werte der abhängigen Variable yij werden mit einem Doppelindex versehen: yij ist der i-te Wert (i=1,…,nj) in der j-ten Faktorstufe des Faktors.
Die Aufgabe des Verfahrens ist es nun, zu untersuchen, ob der Faktor die abhängige Variable Y beeinflusst oder nicht. Hätte der Faktor einen Einfluss auf Y, dann müssten die k gebildeten Gruppen im Durchschnitt die gleichen Ausprägungen von Y aufweisen.
> table(Pizza$Lieferzeit)
14 16 17 18 19 20 21 22
1 2 2 3 4 2 1 1
Die Hypothesen der Varianzanalyse lauten somit:
H0: Die Erwartungswerte in den Faktorstufen sind gleich vs.
H1: Die Erwartungswerte in den Faktorstufen sind gleich.
Erst wenn H1 abgelehnt werden kann, ist sichergestellt, dass sich die Erwar- tungswerte der abhängigen Variable für die durch den Faktor gebildeten Gruppen unterscheiden und es kann von einem Einfluss des Faktors auf Y ausgegangen werden.
Wesentlich für die Varianzanalyse ist, dass sich die Abweichung der Beo- bachtungswerte vom Gesamtmittelwert der abhängigen Variable in 2 Anteile zerlegen lässt:
• die Abweichung der Einzelwerte vom Faktorstufenmittelwert (Streuung innerhalb der Gruppen; nicht erklärte Abweichungen) und
• die Abweichung der Faktorstufenmittelwerte vom Gesamtmittelwert (Streuung zwischen den Gruppen, erklärte Abweichung).
Es wird die Gesamtvariation der abhängigen Variable über alle Untersu- chungseinheiten (SAQ) betrachtet:
SAQTotal = SAQinnerhalb + SAQzwischen
∑ ∑ ∑
∑∑
− = − + −i j
j j j
j ij
i j
ij y) (y y ) n (y y)
y
( 2 2 2
mit den dazugehörigen Freiheitsgraden:
(n – 1) = (n – k) + (k – 1) mit
SAQTotal = totale zu erklärende Abweichungsquadratsumme von Y,
SAQinnerhalb = durch den Faktor nicht erklärte Abweichungsquadratsumme von Y,
SAQzwischen = durch den Faktor erklärte Abweichungsquadratsumme von Y.
Die Abweichung (yj −y) drückt den Einfluss der Faktorstufe j auf Y aus. Die Abweichung (yij − yj ) ist alleine auf unberücksichtigte Einflussfaktoren zu- rückzuführen und manifestiert sich im Modell der Varianzanalyse als Resi- duum bzw. Störgröße. Für die Residuen gelten die üblichen Annahmen:
• zufälliges Auftreten,
• Varianzhomogenität,
• Normalverteilung,
• Unkorreliertheit.
Der Quotient aus den SAQ und den dazugehörigen Freiheitsgraden wird als Mittlere Quadratsumme MQ bezeichnet. Diese Mittleren Quadratsummen sind Ausgangspunkt, um den Einfluss des Faktors auf Y zu überprüfen. Ist nämlich MQinnerhalb = 0, so wird SAQTotal ausschließlich durch den Faktor er- klärt. Je kleiner MQinnerhalb im Vergleich zu MQzwischen ist, desto kleiner ist der Erklärungsanteil und somit die Wirkung des Faktors auf Y und desto größer ist der Erklärungsanteil der im Modell nicht erfassten Einflussgrößen. Je grö- ßer folglich der Quotient MQzwischen / MQinnerhalb ausfällt, desto eher ist eine Wirkung des Faktors auf Y anzunehmen.
Die statistische Prüfung des Einflusses des Faktors auf Y erfolgt durch den F-Test, basierend auf dem Quotienten MQzwischen / MQinnerhalb.
Die Teststatistik
innerhalb zwischen
emp MQ
F = MQ
ist F-verteilt. Die nach dieser Vorschrift an Hand der Stichprobendaten be- rechnete Prüfgröße wird mit dem kritischen Wert der F-Verteilung Fk−1;n k− ;1−α verglichen. Hierbei beschreibt α das Signifikanzniveau des Tests. H0 wird abgelehnt, wenn Femp ≤Fk−1;n k− ;1−α und H1 verworfen, wenn Femp >Fk−1;n k− ;1−α. Wird H1 abgelehnt, unterscheiden sich mindestens 2 der durch den Faktor gebildeten k Gruppen bzgl. ihrer durchschnittlichen Ausprägung der abhän- gigen Variable. In diesem Fall sagt man, dass der Faktor zum Niveau α ei- nen signifikanten Einfluss auf Y hat. Gilt H1, so unterscheiden sich die Fak- torstufen des Faktors bezüglich ihrer durchschnittlichen Ausprägung nicht.
Daher kann kein Einfluss des Faktors angenommen werden.
Die Testentscheidung kann auch über einen Vergleich des Signifikanzni- veaus α mit dem Fehler 2. Art (auch p-Wert genannt) erfolgen. Das Signifi- kanzniveau stellt dabei eine Wahrscheinlichkeitsschranke für die unberech- tigte Ablehnung der Alternativhypothese H1 dar. Der Fehler 2. Art gibt an, mit welcher Wahrscheinlichkeit eine ebenso große oder größere Prüfgröße – im Vergleich zu der aus den Daten berechneten Prüfgröße – erwartet werden kann, wenn H0 richtig ist. Damit beschreibt der Fehler 2. Art die „realisierte“
Wahrscheinlichkeit, mit der man sich irrt, wenn man H0 verwirft. Sollte der Fehler 2. Art ≥ α sein, wird H0 beibehalten. Gilt aber, dass der Fehler 2. Art < α ist, muss H0 verworfen werden.
Im Bericht wird einheitlich ein Signifikanzniveau von α = 0.05 unterstellt.
4. Statistische Auswertung
Bevor die Einflüsse der Faktoren auf die Lieferzeit mit Hilfe der Varianzana- lyse untersucht werden, wird eine deskriptive Analyse aller beobachteten Merkmale durchgeführt. Hierzu wurde die 5-Punkte-Zusammenfassung aller Variablen erstellt (vgl. Tabelle 3).
Tabelle 3: 5-Punkte-Zusammenfassung aller Variablen
Min. 1st Qu. Median Mean 3rd Qu. Max. Spannweite SD Schiefe Rand 0.0 0.0 0.5 0.5 1.0 1.0 1 0.5163978 0,0000 Cola 0.0 0.0 0.5 0.5 1.0 1.0 1 0.5163978 0,0000 Brot 0.0 0.0 0.5 0.5 1.0 1.0 1 0.5163978 0,0000 Fahrer 0.0 0.25 1.00 0.75 1.0 1.0 1 0.44721359 -1,2778 Bestellzeitpunkt 20.37 20.6350 20.7650 20.77 20.9375 21.08 0.71 0.1882540 -0,3001 Lieferzeit 14.00 17.00 18.50 18.31 19.75 22.00 8 2.023817 -0,2673
Wie Tabelle 3 zu entnehmen ist, beträgt die durchschnittliche Lieferzeit 19.75 Minuten. Die schnellste Lieferung dauerte nur 14 Minuten, die längste Lieferung ganze 22 Minuten. Der durchschnittliche Bestellzeitpunkt war 20.9375, was der Uhrzeit 20:56 Uhr entspricht. Die Mittelwerte und Kenngrö- ßen der anderen Variablen sind der Tabelle 3 zu entnehmen. Überraschend ist, dass die Standardabweichungen der Variablen Rand, Cola und Brot iden- tisch sind. Insgesamt kann aus der Betrachtung der Standardabweichungen geschlossen werden, dass alle Variablen leicht linkssteil verteilt sind.
Tabelle 4: Durchschnittliche Lieferzeit in den Faktorstufen der Faktoren Rand, Cola, Brot und Geschlecht des Fahrers
Rand Cola Brot Fahrer dünn 17.25 nein 18.5 nein 19.375 Frau 17.00
dick 19.375 ja 18.125 ja 17.25 Mann 18.75
Um den Einfluss der Faktoren auf die Lieferzeit abschätzen zu können, wer- den in einem ersten Schritt die durchschnittlichen Lieferzeiten für alle Aus- prägungen eines Faktors errechnet (vgl. Tabelle 4). Dabei stellt sich heraus, dass mit Frauen als Fahrer eine kürzere Lieferzeit erreicht werden kann als bei Männern (17 Minuten zu 18.75 Minuten). Ebenso scheint der Randtyp der Pizza einen Einfluss auf die Lieferzeit zu haben: Die Lieferung einer Pizza mit dünnem Boden benötigt im Durchschnitt etwa 2 Minuten weniger als bei einem dicken Boden. Bei beiden Faktoren ist ein also deutlich positiver Zu- sammenhang festzustellen. Für die Faktoren Cola und Brot lassen sich keine großen Unterschiede bei der durchschnittlichen Lieferzeit in den einzelnen Faktorstufen feststellen.
Somit werden im Verlauf der Varianzanalyse ausschließlich der Einfluss der Faktoren Geschlecht des Fahrers und Randtyp der Pizza untersucht.
Tabelle 5: Mittelwerte in den einzelnen Faktorstufen von Rand und Ge- schlecht
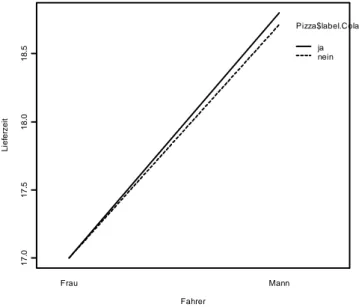
In Tabelle 6 sind die Ergebnisse der Varianzanalyse mit den Faktoren Rand und Geschlecht des Fahrers dargestellt. Ebenso sind im Modell Wechselwir- kungen der beiden Faktoren berücksichtigt.
Tabelle 6: Ergebnisse der Varianzanalyse
Wie aus Tabelle 6 ersichtlich wird, kann davon ausgegangen werden, dass sowohl der Faktor Rand als auch das Geschlecht des Fahrers einen signifi- kanten Einfluss auf die Lieferzeit ausüben, da alle p-Werte kleiner als 5%
sind. Sogar bei der Wechselwirkung konnte R mit einem p-Wert von 0.78%
einen signifikanten Einfluss ermitteln. Dies bedeutet, dass nicht nur das Ge- schlecht und der Rand getrennt einen Einfluss auf die Lieferzeit haben, son- dern auch das Zusammenwirken der beiden Faktoren die abhängige Variable beeinflusst. Dies wird auch aus dem Interaktionsplot der beiden Faktoren deutlich (vgl. Abb. 4). In dieser Abbildung sind die durchschnittlichen Liefer- zeiten für männliche und weibliche Fahrer ausgewiesen, getrennt nach den beiden Randtypen der Pizza. Da beide Linien nahezu parallel verlaufen, kann von vorneherein auf eine große Bedeutung der Wechselwirkung für die Lie- ferzeit geschlossen werden.
Rand dünn dick Cola 0.50000 0.5000 Brot 0.50000 0.5000 Bestellzeitpunkt 20.71875 20.8125 Lieferzeit 17.25000 19.3750
Geschlecht Frau Mann Rand 0.0000 0.6666667 Cola 0.7500 0.4166667 Brot 0.5000 0.5000000 Bestellzeitpunkt 20.6675 20.7983333 Lieferzeit 17.0000 18.7500000
> anova(lm(Pizza$Lieferzeit~Pizza$Rand+Pizza$Fahrer+Pizza$Cola)) Analysis of Variance Table
Response: Pizza$Lieferzeit
Df Sum Sq Mean Sq F value Pr(>F) Pizza$Rand 1 18.063 18.063 5.0893 0.04353 * Pizza$Fahrer 1 0.500 0.500 0.1409 0.71396 Pizza$Cola 1 0.286 0.286 0.0805 0.78145 Residuals 12 42.589 3.549
Abbildung 4: Interaktionsplot zwischen den Faktoren Geschlecht und Rand- typ
17.017.518.018.5
Fahrer
Lieferzeit
Frau Mann
Pizza$label.Cola ja nein
Im einem letzten Schritt des Modells sind die Annahmen der Varianzanalyse über das Verhalten der Residuen und der Faktoren zu überprüfen.
(1) Zufälliges Auftreten
Hierbei ist zu prüfen, ob der Erwartungswert der Residuen = 0 ist. Denn nur so ist gewährleistet, dass die Residuen keinen signifikanten Einfluss auf Y ausüben. Nach Tabelle 7 ist gewährleistet, dass diese Bedingung eingehal- ten wird.
Tabelle 7: Erwartungswert der Residuen
(2) Varianzhomogenität
Das Kriterium der Varianzhomogenität verlangt, dass die Varianz der Resi- duen in allen Faktorstufen vergleichbar groß ist. Allerdings sind keine Test- verfahren oder graphische Darstellungsmöglichkeiten bekannt, welche die Überprüfung der Einhaltung dieses Aspektes ermöglichen.
> mean(resid(output)) -1.387779e-17
(3) Normalverteilung der Residuen
Mit diesem Kriterium wird verlangt, dass die Residuen in den einzelnen Fak- torstufen normalverteilt sind. Die Überprüfung kann an Hand eines QQ-Plots erfolgen (vgl. Abb. 5). In Abb. 5 sind die Residuen gegen den um eine Beo- bachtungseinheit verzögerten Vorgängerwert geplottet. Würden die einzel- nen Punkte in Abb. 5 deutlich von der Winkelhalbierenden abweichen, wäre das Kriterium der Normalverteilung nicht erfüllt. Da in Abb. 5 nur die beiden letzten Werte von der Winkelhalbierenden abweichen, kann von einer Nor- malverteilung der Residuen ausgegangen werden. Allerdings wird der Prog- nosebereich durch diese 2 Abweichungen eingeschränkt.
Abbildung 5: QQ-Plot
-3 -2 -1 0 1 2 3
-3-2-1012
Normal Q-Q Plot
Theoretical Quantiles
Sample Quantiles
(4) Keine Autokorrelation der Residuen
Bei Voraussetzung der Abwesenheit von Autokorrelation wird verlangt, dass die Faktorstufen nicht zeitlich voneinander abhängen. Die Überprüfung er- folgt durch Inspektion der Residuen im Histogramm (vgl. Abb. 6).
Abbildung 6: Histogramm der Residuen
Histogram of standresid
standardisierte Residuen
Frequency
-3 -2 -1 0 1 2
01234567
Wie zu erkennen ist, liegt kein Zusammenhang der Residuen vor und die Werte sind relativ symmetrisch um den Mittelwert angeordnet.
(5) Keine Multikollinearität der Faktoren
Hierbei wird vorausgesetzt, dass die in der Varianzanalyse einbezogenen Faktoren nicht linear voneinander abhängen. Als Prüfkriterium dafür kann der Korrelationskoeffizient nach Bravais-Pearson für die beiden Faktoren be- rechnet werden (vgl. Tabelle 8).
Tabelle 8: Korrelation der Faktoren
Wie Tabelle 8 zu entnehmen ist, liegt ein sehr geringer, positiver, linearer Zusammenhang zwischen den beiden Faktoren vor (Korrelationskoeffizient = 0.01919). Dies bedeutet, dass auch das Kriterium (5) durch das Modell erfüllt wird und damit die Ergebnisse der Varianzanalyse uneingeschränkt interpre- tiert werden können.
> cor.test(Pizza$Rand,Pizza$Fahrer,method=c("pearson"))
Pearson's product-moment correlation data: Pizza$Rand and Pizza$Fahrer t = 2.6458, df = 14, p-value = 0.01919
alternative hypothesis: true correlation is not equal to 0 cor
0.5773503