MARTIN-LUTHER-UNIVERSITÄT HALLE-WITTENBERG
Juristische & Wirtschaftswissenschaftliche Fakultät
Wirtschaftswissenschaftlicher Bereich Lehrstuhl für Statistik
Prof. Dr. Claudia Becker
Wintersemester 2006/07 3. Termin
Klausur Anwendungsprojekte
über Varianzanalyse
„Arbeitsperformance im ersten Arbeitsjahr bei Hochschulabsolventen“
19.02.2007
Name: ...
Matrikelnummer: ...
Inhaltsverzeichnis
1. Einleitung ... 1
2. Problemstellung ... 2
3. Theoretische Grundlagen der statistischen Verfahren ... 4
3.1 Deskriptive Verfahren ... 4
3.2 Varianzanalyse ... 7
4. Statistische Auswertung ... 12
4.1 Deskriptive Analyse ... 12
4.2 Varianzanalyse ... 15
Abkürzungsverzeichnis ... 19
Anhang ... 20
1. Einleitung
Nach vielen Jahren des Zögerns und nach heftigen Diskussionen hat sich die Bundesregierung entschlossen, Spitzenleistungen in der Forschung durch die Einrichtung sogenannter Elite-Unis zu fördern. Dies ist mit der Zielset- zung verbunden, die langfristige Wettbewerbsfähigkeit Deutschlands zu si- chern und den „Brain Drain“ (also die Abwanderung) von Nachwuchswissen- schaftlern wegen schlechterer Arbeitsbedingungen und Entwicklungsper- spektiven zu stoppen.
Die staatliche Förderung konzentriert sich jedoch oft nur auf technische bzw.
naturwissenschaftliche Fachgebiete. Auch ist fragwürdig, ob mit der Förde- rung von Spitzenforschung eine herausragende Ausbildung in der Breite ge- sichert ist. Somit besteht für einen Arbeitgeber, der Nachwuchskräfte mit ex- zellenter ökonomischer Ausbildung sucht, weiterhin die Unsicherheit, von welcher Universität er bevorzugt die Absolventen rekrutieren soll.
Insbesondere die Beratungsbranche ist von dieser Rekrutierungs- Problematik betroffen, da die gesamte Wertschöpfung dort auf den „Produk- tionsfaktor“ Humankapital zurückzuführen ist. Daher stellen der Zugang zu geeigneten neuen Mitarbeitern und eine gute und effektive Rekrutierungspoli- tik essenzielle Wettbewerbsvorteile für das jeweilige Unternehmen dar.
Eine bedeutende und international tätige Unternehmensberatung entschließt sich vor diesem Hintergrund eine interne Studie durchzuführen. Diese Unter- suchung soll überprüfen, ob zwischen der Arbeitsleistung von Hochschulab- solventen im ersten Arbeitsjahr und ihrem Ausbildungsort, d.h. ihrer Universi- tät, ein Zusammenhang besteht. Das Ziel ist es, herauszufinden, ob und in- wieweit die in den Hochschulrankings „suggerierten“ Qualitätsunterschiede in der Ausbildung und in den Studienbedingungen der Universitäten einen Ein- fluss auf die Arbeitsleistung der Absolventen im späteren Arbeitsleben ha- ben. Die Ergebnisse der Studie sollen als Entscheidungsgrundlage für rekru- tierungspolitische Maßnahmen dienen. Im Speziellen geht es darum, die Campuspräsenz des Unternehmens an den besten Universitäten zu verstär- ken bzw. an wenigen guten zu konzentrieren, um so einen direkten Zugang zu guten Mitarbeitern zu bekommen. Weiterhin soll mit diesem Studiendesign analysiert werden, ob Unterschiede in der Arbeitsleistung zwischen den Ge- schlechtern bestehen.
Für die Auswertung der Studie wurde die Varianzanalyse eingesetzt, welche die Wirkung des Ausbildungsortes auf die Arbeitsleistung untersucht und mögliche Unterschiede zwischen den Geschlechtern aufdeckt. Als Haupter- gebnis lässt sich feststellen, dass die Arbeitsleistung der Hochschulabsolven- ten scheinbar nicht vom Ausbildungsort abhängt.
Der Aufbau der Untersuchung stellt sich wie folgt dar: Im zweiten Kapitel wird nach der Beschreibung der Problemstellung ein Überblick über die betrachte- ten Variablen des Modells gegeben.
Abschnitt 3 beschäftigt sich mit den theoretischen Grundlagen der statisti- schen Verfahren, im speziellen mit den deskriptiven Verfahren und der Vari- anzanalyse. Im 4. Kapitel erfolgt die statistische Auswertung der Daten an- hand von Tabellen und Abbildungen und deren Interpretation.
Im letzten Abschnitt werden die gewonnenen Ergebnisse im Bezug auf die interessierende Fragestellung zusammengefasst.
2. Problemstellung
Anlass dieser Studie eines Beratungsunternehmens ist die bereits in der Ein- leitung erwähnte Notwendigkeit, neue Erkenntnisse über den Einfluss unter- schiedlicher Ausbildungsorte und des Geschlechts auf die Arbeitsleistung der Absolventen im ersten Arbeitsjahr zu gewinnen. Die Ergebnisse der Untersu- chung sollen zur effektiveren Steuerung und Organisation des Rekrutie- rungsprozesses eingesetzt werden. Insbesondere soll eine Entscheidung über die Aufstellung und Verteilung der Unternehmenspräsenz an den unter- suchten deutschen Hochschulen getroffen werden.
Im vorliegenden Bericht wird die Auswertung einer solchen internen Studie über die Arbeitsleistung von Hochschulabsolventen verschiedener Universi- täten im ersten Arbeitsjahr vorgenommen. Die Untersuchung umfasst die vollständig anonymisierten Daten von allen 100 Absolventen, die deutsch- landweit nach dem Studium im Jahre 2005 bei der Beratungsfirma als Junior- Consultants eingestellt wurden. Also liegt eine mehrstufige Zufallsauswahl vor. Die Beratungsfirma beschränkt sich allerdings nur auf eine interne Stu-
die und erfasst ausschließlich Hochschulabsolventen. Mit einem deutsch- landweiten Netz von Beratungsbüros in allen wichtigen Wirtschaftsstandorten verspricht man sich dennoch repräsentative Ergebnisse, die gegebenenfalls auch für andere Beratungsunternehmen und Zeiträume Gültigkeit haben.
Insgesamt kann festgestellt werden, dass im Datenmaterial keine fehlenden Werte auftreten.
Von den neueingestellten Junior-Consultants werden im Rahmen der Studie folgende Merkmale erfasst: Arbeitsleistung im ersten Jahr (Performance), Ausbildungsort (Universität) und Geschlecht.
• Für die Bewertung der Arbeitsleistung der Hochschulabsolventen wurde ein Scoring-Modell erarbeitet, welches neben den „hard skills“1 auch so genannte „soft skills“2 berücksichtigt. Gewissermaßen als ag- gregierte Kennzahl resultiert ein Wert, der sich auf einer Skala von Null (schlechte Arbeitsleistung) bis 100 (überragende Arbeitsleistung) Punkten bewegt. Da es in der Beratungsbranche üblich ist, einem Be- rufanfänger einen Mentor zur Seite zu stellen, werden diese gebeten, aufgrund ihrer persönlichen Nähe und der in der Regel guten Kenntnis ihrer „Schützlinge“, die Bewertung aller Teilaspekte des Scoring- Modells nach einem Jahr Unternehmenszugehörigkeit zu überneh- men.
• Als Ausbildungsort wird diejenige Universität angegeben, an welcher der Absolvent den größten Teil seiner Ausbildung absolviert hat. Bei der Durchsicht der Daten der 100 Junior-Consultants wurde festge- stellt, dass das Beratungsunternehmen neue Mitarbeiter von bisher nur 5 verschiedenen Universitäten eingestellt hat. Dazu zählen 3 pri- vate und 2 staatliche Universitäten.
Tabelle 1 fasst die erhobenen Variablen und ihre Ausprägungen noch einmal zusammen.
1 Technische Anforderungen an den Job (Computerkenntnisse, Methodenwissen u.a.)
2 Menschliche Eigenschaften, Fähigkeiten und Persönlichkeitszüge (Disziplin, Freundlichkeit, Ver- antwortung u.a.)
Tabelle 1: Merkmale und Ausprägungen
Variablen Ausprägungen Skalenniveau
Arbeitsleistung (Performance)
Punkte auf einer Skala von 0 bis 100 metrisch
Ausbildungsort (Universität)
- Evangelische Universität Eichstätt-Ingolstadt - Globalisierungshochschule Leipzig
- Leo X-Universität Halle - Quitten-Herdecke - WHU Kalender
nominal
Geschlecht - männlich
- weiblich
metrisch
Mit Hilfe der Varianzanalyse wird nun der Einfluss der Faktoren „Universität“
und „Geschlecht“ auf die Arbeitsleistung untersucht. Es sollen dabei folgende Fragestellungen beantwortet werden:
• Wirkt sich der der Faktor „Ausbildungsort“ isoliert betrachtet auf die Arbeitsleistung der Absolventen aus, oder hat er keinen Einfluss?
• Wirkt sich der Faktor „Geschlecht“ isoliert betrachtet auf die Arbeits- leistung aus, oder hat er keinen Einfluss?
• Wirken die Einflussfaktoren vielleicht nicht isoliert, dafür aber gemein- sam auf die Arbeitsleistung ein?
• Wirken sich die Einflussfaktoren sowohl isoliert, also auch gemein- sam auf das interessierende Merkmal aus?
Die Auswertungen wurden mit dem Programm SPSS 14.0 für Windows durchgeführt.
3. Theoretische Grundlagen der statistischen Verfahren 3.1 Deskriptive Verfahren
Bevor die eigentliche Auswertung der Daten mit Hilfe der Varianzanalyse erfolgt, ist es empfehlenswert, den Datensatz deskriptiv zu analysieren. Da- bei wird das Ziel verfolgt, mit Hilfe von graphischen Darstellungen der Häu- figkeitsverteilung (wie etwa die Lorenzkurve) oder der Berechnung von Kenn- größen (Lage-, Streuungs- und Schiefeparameter) die Verteilungen der ein-
zelnen Merkmale zu charakterisieren und somit die zu analysierende statisti- sche Masse zusammenfassend beurteilen zu können.
Lageparameter geben Auskunft über die Größenordnung der Merkmalswerte und somit über die Lage des Zentrums einer Verteilung. Sie sollen die Ge- samtheit der Beobachtungswerte möglichst gut repräsentieren. Als Lagepa- rameter werden in der Regel der Median, der Modus und das arithmetische Mittel berechnet. Als Median xmed wird jede Merkmalsausprägung eines min- destens metrisch skalierten Merkmals bezeichnet, welche die geordnete Rei- he der Beobachtungswerte in vier gleiche Teile teilt. Er repräsentiert die Mitte der Verteilung und ist durch seine Berechnung extrem unempfindlich gegen außergewöhnlich hohe/niedrige und somit untypische Beobachtungen (Aus- reißer).
Der Modus stellt die Verallgemeinerung des Median dar. Als Modus xmod wird diejenige Merkmalsausprägung eines mindestens metrisch skalierten Merkmals bezeichnet, welche die Reihe der Beobachtungswerte in 2 beliebig wählbare Anteile p*100% und (1-p)*100% zerlegt: Unterhalb von xmod befin- den sich höchstens p*100% der Werte und oberhalb von xmod höchstens (1-p)*100% der Werte.
Das arithmetische Mittel x ist das am häufigsten verwendete Lagemaß.
Die Bestimmung von x ist nur sinnvoll für Merkmale, die auf einer metri- schen Skala gemessen werden können. Es beschreibt jenen Wert, der sich ergibt, wenn die gesamte Merkmalssumme auf alle n Merkmalsträger zu gleichen Teilen aufgeteilt wird:
k i i j 1
x 1 x y
n =
=
∑
i .Die Aussagefähigkeit von x wird dadurch eingeschränkt, dass es von Aus- reißern beeinflusst wird. Es ist deshalb für die konkreten Daten jeweils zu prüfen, welches Lagemaß eine sinnvolle Aussage über die Verteilung liefern kann.
Die Lageparameter reichen zur Charakterisierung einer Häufigkeitsverteilung oft nicht aus. In vielen Fällen ist es auch wichtig zu wissen, ob die Beobach-
tungswerte weit auseinander liegen, d.h. stark streuen oder ob sie sehr nahe um einen Mittelwert angeordnet sind. Je geringer die Abweichungen vom Mittelwert sind, desto besser repräsentiert dieser den Datensatz. Das am häufigsten verwendete Streuungsmaß ist der Gini-Koeffizient G. Er misst die durchschnittliche quadratische Abweichung der Merkmalswerte von x:
n n
i i i 1 i
i 1 i 1
G u v u− v 1
= =
=
∑
i +∑
i − .Der Gini-Koeffizient ist ein normiertes Maß, welches die Ungleichheit der auf die einzelnen Untersuchungsobjekte i entfallenden relativen Merkmalsanteile beschreibt. Dabei nimmt der Koeffizient bei einer egalitären Verteilung (Ein- punktverteilung) den Wert 0 an und strebt mit zunehmender Ungleichheit der Verteilung gegen den Wert 1. Jedoch besitzt der Gini-Koeffizient als Maßein- heit das Quadrat der Einheit des Merkmals, für das er berechnet wurde, und ist daher kaum zu interpretieren. Wichtig für die Interpretation der Ergebnisse ist vor allem die Varianz s= G, die durch einen festen Wertebereich von
−∞ ≤ ≤ +∞s anschaulich interpretiert werden kann. Je größer s ist, desto weiter liegen die Merkmalswerte auseinander. Je kleiner s ist, desto kleiner ist die Abweichung der Merkmalswerte von x. Ist s < 0, konzentrieren sich die Merkmalswerte auf der linken Seite der Häufigkeitsverteilung.
Insbesondere für Vergleichszwecke von Streuungen verschiedener Merkma- le sind Gini-Koeffizient und Varianz ungeeignet. Hierzu müssen so genannte relative Streuungsmaße wie der Variationskoeffizient genutzt werden. Die- ser setzt G und x in Beziehung und erlaubt als dimensionslose Maßzahl eine merkmalsübergreifende Vergleichbarkeit der Streuungen:
v G
= x .
Durch Lage- und Streuungsparameter kann eine Häufigkeitsverteilung im Allgemeinen ausreichend charakterisiert werden. Es gibt aber Fälle, in denen unterschiedliche Verteilungen sowohl in Lageparametern als auch in Streu- ungsmaßen übereinstimmen. So ist es in diesen Fällen erforderlich, weitere Kennzahlen wie die Schiefe zur Charakterisierung der Verteilung heranzu- ziehen. Die Schiefe beschreibt dabei, inwieweit bei der Verteilung eine Symmetrie bzw. Asymmetrie (Schiefe) vorliegt. Verteilen sich die Beobach-
tungswerte eines mindestens nominal skalierten Merkmals gleichförmig zu beiden Seiten um den Mittelwert x und gilt G=xmed, liegt eine symmetrische Häufigkeitsverteilung vor. Anderenfalls ist die Häufigkeitsverteilung asymmet- risch bzw. schief. Ist G>xmed, wird von einer rechtsschiefen (rechtssteilen) Verteilung gesprochen, bei G<xmed von einer linksschiefen (linkssteilen) Ver- teilung. In der Regel ist es nützlich, die Ausgeprägtheit der Schiefe der Ver- teilung mit einer Maßzahl zu messen. Das in der deskriptiven Statistik übli- cherweise eingesetzte Schiefemaße ist der Korrelationskoeffizient nach Spearman und ist kann wie folgt interpretiert werden:
• linkssteile Verteilung: Schiefemaß positiv,
• symmetrische Verteilung: Schiefemaß 0,
• rechtsschiefe Verteilung: Schiefemaß negativ.
3.2 Varianzanalyse
Die Varianzanalyse ist ein Verfahren, das die Wirkung einer/mehrerer min- destens nominal skalierter unabhängiger Variablen auf eine/mehrere met- risch skalierte abhängige Variable untersucht. Im vorliegenden Bericht wird jedoch nur der Fall einer abhängigen Variable untersucht. Die Varianzanaly- se unterstellt eine Vermutung über die Wirkungsrichtung der Variablen in der Art, dass die unabhängigen Variablen xj (j=1,…,k) als ursächlich für das Entstehen der Werte der abhängigen Variable y angesehen werden:
) , ,..., ,..., ,
(x1 x2 xj xk ε f
y= .
Die erklärenden (unabhängigen) Variablen werden in der Varianzanalyse allgemein als Faktoren bezeichnet, die Ausprägungen der unabhängigen Va- riablen als Faktorstufen. Die Faktoren müssen sich inhaltlich eindeutig von- einander unterscheiden und die Faktorstufen müssen stets alternative Zu- stände beschreiben. Der Modellparameter ε erfasst alle Einflussgrößen au- ßerhalb des vermuteten Modells, welche die Werte von y mitbestimmen (wie unberücksichtigte Faktoren, Mess- oder Beobachtungsfehler). Für ε werden dabei für alle Faktorstufen g die üblichen Annahmen unterstellt: E(εig)=0, Varianzhomogenität, Normalverteilung und Unkorreliertheit.
Das Ziel des gesamten Verfahrens besteht in der Analyse, ob die unter- schiedlichen Werte der abhängigen Variable auf die Variation der Faktorstu- fen eines Faktors zurückzuführen sind und somit der Faktor einen statistisch gesicherten Einfluss auf y ausübt oder nicht.
Die analytische Idee der Varianzanalyse wird zunächst am Beispiel einer ein- faktoriellen Varianzanalyse erläutert (1 unabhängige Variable y, 1 Faktor A mit g=1,...,G Faktorstufen). Für jede Faktorstufe g des Faktors A werden
1,..., g
i= n Beobachtungen yig der abhängigen Variable y erhoben (vereinfa- chend sei unterstellt, dass ng =n mit
1 G
g g
n N
=
∑
= ). Danach erfolgt die Berech- nung des Gesamtmittelwertes y über alle Faktorstufen und des Mittelwertes je Faktorstufe yg aus den Beobachtungswerten yig. Die Aufgabe ist nun, zu untersuchen, ob Faktor A die Variable y beeinflusst oder nicht. Dazu werden die Mittelwertunterschiede zwischen y und yg analysiert. Bestehen solche Mittelwertunterschiede, haben die Faktorstufen einen Einfluss auf y. Können keine Unterschiede festgestellt werden, dann haben die Faktorstufen keinen Einfluss. Die Abweichungen der einzelnen Beobachtungswerte yig zum Mit- telwert der Faktorstufe yg werden durch die zuvor bereits erwähnten zufälli- gen äußeren Einflüsse (z.B. andere, bisher unberücksichtigte Faktoren oder Messfehler) bewirkt und können durch das Modell nicht erklärt werden und werden somit dem Modellparameter ε zugeordnet:ε =ig (yig−y )g .
Um die mit dem Modell erklärbaren Einflüsse von den im Modell nicht erfass- ten trennen zu können, wird also eine Streuungszerlegung der abhängigen Variablen vorgenommen. Dabei wird die Gesamtabweichung SSt in eine durch das Modell erklärte Abweichung SSb und eine vom Modell nicht erklär- te Abweichung SSw zerlegt:
n G G n G
2 2 2
ig g ig g
i 1 g 1 g 1 i 1 g 1
(y y) n(y y) (y y )
= = = = =
− = − + −
∑∑ ∑ ∑∑
Gesamtab- = erklärte Ab- + nicht erklärte weichung SSt weichung SSb Abweichung SSw.
Die nicht erklärte Abweichung SSw erfasst die Summe der quadrierten Ab- weichungen innerhalb der Faktorstufen. Denn streuen die Beobachtungswer- te yig um yg, ist diese Streuung allein auf unberücksichtigte Einflussgrößen zurückzuführen und kann somit nicht durch das Modell erklärt werden. Die erklärte Abweichung SSb erfasst die Summe der quadrierten Abweichungen zwischen den Faktorstufen. Wirkt sich die nicht erklärte Abweichung in allen Faktorstufen gleich aus, so drückt die Abweichung (yg − y) den Einfluss der Faktorstufe g des Faktors A aus.
In einem weiteren Rechenschritt werden die 3 verschiedenen quadrierten Abweichungen SS durch ihre Freiheitsgrade dividiert und dadurch so ge- nannte mittlere quadratische Abweichungen MS ermittelt. Eine Gegenüber- stellung der Größen MSw und MSb ermöglicht es, die Bedeutung des Faktors A im Vergleich zu den nicht erfassten Einflussgrößen abschätzen zu können.
Ist MSw= 0, so wird SSt alleine durch den Faktor A erklärt. Je größer MSb im Vergleich zu MSw ist, desto geringer ist der Erklärungsanteil und somit die Wirkung des Faktors A auf y und desto größer ist der Erklärungsanteil der im Modell nicht erfassten Einflussgrößen. Je kleiner also der Quotient (MSb/MSw) ausfällt, desto eher ist eine Wirkung des Faktors A anzunehmen.
Die statistische Signifikanzprüfung des Einflusses der Faktorstufen erfolgt schließlich durch den F-Test. Hier werden nun folgende Hypothesen über die Parameter der Stichprobe überprüft:
H0: In der Stichprobe haben die Faktorstufen des Faktors A keinen Einfluss auf y bzw. die Faktorstufenmittelwerte entsprechen dem Ge- samtmittelwert
vs.
H0: mindestens eine Faktorstufe des Faktors A hat einen Einfluss bzw.
mindestens 1 Faktorstufenmittelwert ist ungleich dem Gesamtmittelwert.
Gilt H0, so unterscheiden sich die Faktorstufen des Faktors A bezüglich ihrer durchschnittlichen Ausprägung yg nicht und die Mittelwertunterschiede
(yg −y) sind nur zufällig zustande gekommen. Daher kann ein Einfluss des Faktors angenommen werden. Würde H0 gelten, unterscheidet sich mindes- tens eine Faktorstufe hinsichtlich yg signifikant von y. Es kann daher kein Einfluss des Faktors vermutet werden.
Um über die Annahme bzw. Ablehnung von H0 und H1 entscheiden zu kön- nen, wird eine Prüfgröße Femp berechnet, für welche die aus der Stichprobe ermittelten MS Ausgangspunkt sind:
b emp
w
F MS
= MS .
Für eine Testentscheidung muss Femp mit einem kritischen Wert Fkrit vergli- chen werden, der u.a. von der Irrtumswahrscheinlichkeit α abhängig ist. Die Irrtumswahrscheinlichkeit α (auch Fehler höherer Art genannt) stellt den vom Anwender maximal tolerierbaren Irrtum dar, dass H0 angenommen wird, obwohl H0 korrekt ist. Es wird - wie allgemein üblich - im Bericht α = 0.05 gesetzt. Durch die Wahl von α = 0.05 wird ebenso der Fehler 2. Art (auch Signifikanzniveau genannt) auf 95% festgelegt. Dies bedeutet, dass in 95%
aller Fälle die Annahme von H1 erfolgt, wenn H0 korrekt ist, und nur in 5% der Fälle H0 angenommen wird.
Beim Vergleich von Femp mit dem kritischen Wert Fkrit können nun folgende Testentscheidungen getroffen werden:
• Ist Femp> Fkrit, muss H0 verworfen werden und dafür H1 abgelehnt wer- den. Dies bedeutet, dass für Faktor A kein Einfluss auf y nachgewie- sen werden konnte.
• Ist Femp< α, ist der Test zu verwerfen. Hier kann folglich ein signifikan- ter Einfluss des Faktors A auf y berechnet werden.
Statt eines kritischen Wertes berechnet SPSS für die Testentscheidung ei- nen so genannten p-Wert. Der realisierte p-Wert kann als das kleinste Signi- fikanzniveau interpretiert werden, zu dem H0 gerade noch abgelehnt werden kann. Die Entscheidung über eine Annahme bzw. Ablehnung von H0 wird durch einen Vergleich zwischen Femp und dem p-Wert getroffen. Die Testent-
scheidungen sind dabei identisch wie beim Vergleich zwischen Femp und dem kritischen Wert Fkrit.
Lehnt man mittels F-Test die Hypothese des mangelnden Einflusses des Faktors A auf y ab, stellt sich zwangsläufig die Frage, welche Faktorstufen für den signifikanten Einfluss des Faktors verantwortlich sind. Denn befindet sich unter den G Faktorstufenmittelwerten yg z.B. ein Ausreißer, ist es mög- lich, dass dieser zu einem signifikanten F-Wert führt, obwohl sich die übrigen Mittelwerte yg nicht signifikant unterscheiden. Durch Einzelvergleiche (so genannte Kontraste) muss herausgefunden werden, zwischen welchen ein- zelnen Faktorstufen signifikante Unterschiede bestehen. Jedoch sind für die- se Problematik noch keine Testverfahren entwickelt worden.
Die mehrfaktorielle Varianzanalyse untersucht den Einfluss mehrerer Fak- toren auf y (z.B. 1 abhängige Variable y; 1 Faktor A mit g=1,...,G Faktorstu- fen; 1 Faktor B mit h=1,...,H Faktorstufen). Das Grundprinzip der Streuungs- zerlegung bleibt auch hier erhalten, allerdings umfasst die erklärte Abwei- chung SSb nun den Einfluss der einzelnen Faktoren (Haupteffekte) und zu- sätzlich so genannte Wechselwirkungen der Faktoren. Diese Wechselwir- kungen kennzeichnen einen über die Haupteffekte hinausgehenden Interak- tionseffekt, der dadurch entsteht, dass das gleichzeitige Wirksamwerden zweier oder mehrerer Faktoren eine eigenständige Wirkung auf y haben kann. Die Wechselwirkungen können im Plot der Faktorstufenmittelwerte ygh erkannt werden: Wechselwirkungen liegen vermutlich vor, wenn die Verbin- dungslinien der Mittelwerte nichtparallel verlaufen. Keine Wechselwirkungen werden vorliegen, wenn ein paralleler Verlauf dieser Linien zu beobachten ist, denn dann verändert sich der Wirkungsunterschied zweier Faktorstufen.
Die statistische Prüfung erfolgt wiederum durch den F-Test, wobei jetzt für jeden Faktor und für jede mögliche Wechselwirkung getrennt ein F-Test durchzuführen ist.
Geschlecht
50 50,0 50,0 50,0
50 50,0 50,0 100,0
100 100,0 100,0
männlich weiblich Gesamt Gültig
Häufigkeit Prozent Gültige Prozente
Kumulierte Prozente
4. Statistische Auswertung 4.1 Deskriptive Analyse
Den Ausgangspunkt der statistischen Analyse stellt die Ermittlung von de- skriptiven Kennzahlen für jedes der 3 Merkmale dar (vgl. Tabelle 3). Die
„Performance“ stellt in Kapitel 4.2 die abhängige Variable dar, die restlichen 2 Merkmale die so genannten Faktoren.
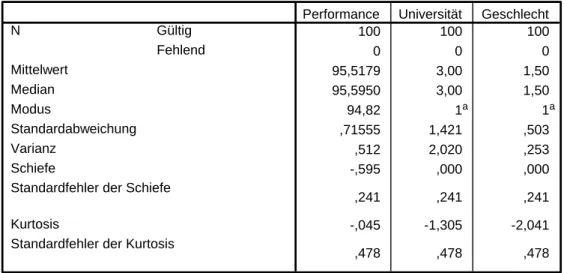
Tabelle 2: Deskriptive Analyse der 3 Merkmale
Deskriptive Statistik
100 100 100
0 0 0
95,5179 3,00 1,50
95,5950 3,00 1,50
94,82 1a 1a
,71555 1,421 ,503
,512 2,020 ,253
-,595 ,000 ,000
,241 ,241 ,241
-,045 -1,305 -2,041
,478 ,478 ,478
Gültig Fehlend N
Mittelwert Median Modus
Standardabweichung Varianz
Schiefe
Standardfehler der Schiefe Kurtosis
Standardfehler der Kurtosis
Performance Universität Geschlecht
Mehrere Modi vorhanden. Der kleinste Wert wird angezeigt.
a.
Universität
20 20,0 20,0 20,0
20 20,0 20,0 40,0
20 20,0 20,0 60,0
20 20,0 20,0 80,0
20 20,0 20,0 100,0
100 100,0 100,0
Quitten-Herdecke Leo X-Uni Halle Globalisierungs HS Leipzig WHU Kalender evang. Uni Eichstätt Gesamt Gültig
Häufigkeit Prozent
Gültige Prozente
Kumulierte Prozente
Im Durchschnitt über alle 5 Universitäten und Geschlechter beträgt die Ar- beitsleistung rund 95.52 Punkte. Am schlechtesten schneiden die männli- chen Absolventen ab (Mittelwert = 1.5) und auch die Universitäten werden im Durchschnitt schlecht bewertet (Mittelwert =3).
Der Vergleich der Standardabweichungen zwischen den Merkmalen zeigt, dass die Variable „Universität“ die größte Streuung hat. Hier schwanken die Werte im Durchschnitt um 1.421 Punkte um den Mittelwert. Bei der Auswer-
6 5 4 3 2 1 0
Universität
30
25
20
15
10
5
0
Häufigkeit
Mittelwert =3 Std.-Abw. =1,421
N =100
Universität
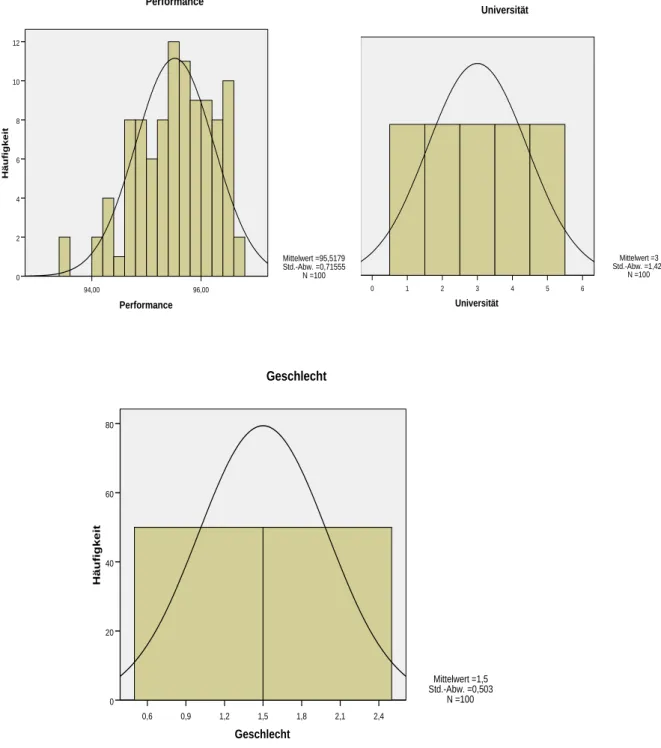
tung der Werte des Schiefemaßes kann festgestellt werden, dass das Merk- mal „Performance“ linksschief verteilt ist, das Merkmal Geschlecht bzw. Uni- versität mit einem Wert von 0.241 jedoch leicht linkssteil. Dies ist auch gut aus den graphischen Darstellungen der Häufigkeitsverteilungen der 3 Merk- male ersichtlich (vgl. Abbildung 1).
Abbildung 1: Häufigkeitsverteilung der 3 Merkmale
96,00 94,00
Performance
12
10
8
6
4
2
0
Häufigkeit
Mittelwert =95,5179 Std.-Abw. =0,71555
N =100
Performance
2,4 2,1 1,8 1,5 1,2 0,9 0,6
Geschlecht
80
60
40
20
0
Häufigkeit
Mittelwert =1,5 Std.-Abw. =0,503
N =100
Geschlecht
Zusammenfassung von Fällen
Performance
20 95,9400 20 95,5615 20 95,0500 20 96,3305 20 94,7075 100 95,5179 Universität
Quitten-Herdecke Leo X-Uni Halle Globalisierungs HS Leipzig
WHU Kalender evang. Uni Eichstätt Insgesamt
N Mittelwert Zusammenfassung von Fällen
Performance
50 95,5702 50 95,4656 100 95,5179 Geschlecht
männlich weiblich Insgesamt
N Mittelwert
In Tabelle 3 wird die durchschnittliche Performance in Abhängigkeit der je- weiligen Faktorstufen eines Faktors dargestellt.
Tabelle 3: Performance in Abhängigkeit der Faktoren
Die beste Arbeitsperformance haben Absolventen der Universität Quitten- Herdecke und der WHU Kalender (95.94 bzw. 96.3305). Eine ebenso über- durchschnittliche Performance kann bei den Absolventen der Uni Halle fest- gestellt werden. Im Vergleich dazu eine geringere Arbeitsleistung zeigen die Absolventen aus Leipzig und Eichstädt.
Auch der Einfluss des Geschlechts auf die Arbeitsleistung kann schon in Ta- belle 3 grob beurteilt werden. So scheint die Performance männlicher Be- rufseinsteiger geringfügig höher zu sein als bei den Frauen.
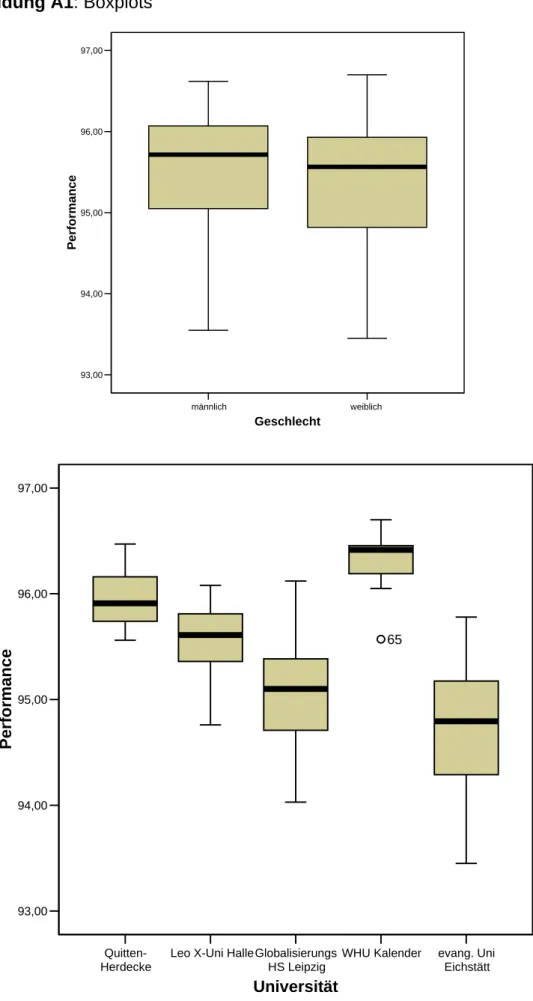
Mit Hilfe der Analyse der Boxplots der Performance in den jeweiligen Faktor- stufen eines Faktors können keine Anzeichen auf Ausreißer oder Asymmet- rie der Häufigkeitsverteilungen gewonnen werden (vgl. Abbildung A1 im An- hang). In allen Boxplots wird die geforderte Normalverteilung der abhängigen Variablen deutlich.
4.2 Varianzanalyse
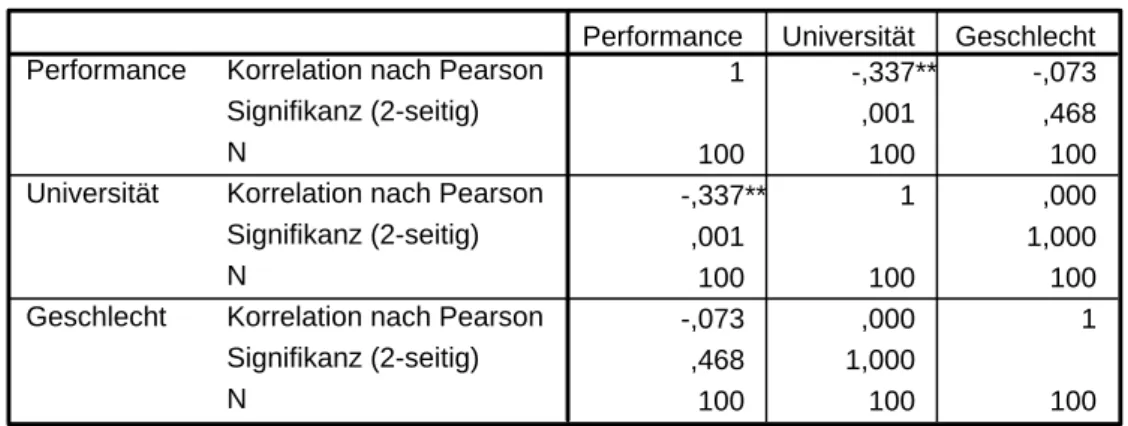
Bevor die Varianzanalyse überhaupt durchgeführt werden darf, ist zu über- prüfen, ob zwischen den Merkmalen überhaupt gesicherte lineare Zusam- menhänge unterstellt werden können. Ist dies nicht der Fall, muss von der Durchführung der Varianzanalyse abgesehen werden. Eine solche Überprü- fung kann mittels des Korrelationskoeffizienten nach Bravais/Pearson ge- schehen:
Tabelle 4: Korrelation nach Bravais/Pearson
Korrelationen
1 -,337** -,073
,001 ,468
100 100 100
-,337** 1 ,000
,001 1,000
100 100 100
-,073 ,000 1
,468 1,000
100 100 100
Korrelation nach Pearson Signifikanz (2-seitig) N
Korrelation nach Pearson Signifikanz (2-seitig) N
Korrelation nach Pearson Signifikanz (2-seitig) N
Performance
Universität
Geschlecht
Performance Universität Geschlecht
Die Korrelation ist auf dem Niveau von 0,01 (2-seitig) signifikant.
**.
Aus Tabelle 4 kann abgelesen werden, dass zwischen der abhängigen Vari- able und den Faktoren deutliche bis starke lineare Zusammenhänge beste- hen. Insbesondere die Korrelation zwischen Geschlecht und Performance ist mit einem Wert des Korrelationskoeffizienten von 0.468 stark signifikant. Da- her kann die Varianzanalyse durchgeführt werden.
Das Ziel des Berichtes besteht darin, zu ermitteln, welche Faktoren Einfluss auf die Performance haben. Die Analyse wird dazu in folgende Schritte unter- teilt: Zuerst werden 2 einfaktorielle Varianzanalysen durchgeführt, um zu be- urteilen, ob die einzelnen Faktoren Ausbildungsort und Geschlecht isoliert eine Wirkung auf die Performance ausüben. Anschließend wird überprüft, ob mögliche Wechselwirkungen der Faktoren die abhängige Variable y signifi- kant beeinflussen oder nicht.
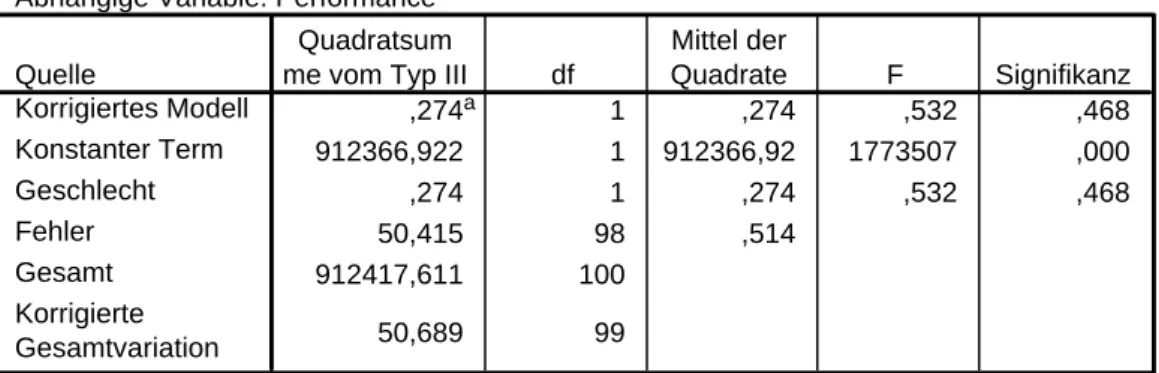
Tabelle 5: Einfaktorielle Varianzanalyse (Universität)
Tests der Zwischensubjekteffekte Abhängige Variable: Performance
,274a 1 ,274 ,532 ,468
912366,922 1 912366,92 1773507 ,000
,274 1 ,274 ,532 ,468
50,415 98 ,514
912417,611 100
50,689 99
Quelle
Korrigiertes Modell Konstanter Term Geschlecht Fehler Gesamt Korrigierte Gesamtvariation
Quadratsum
me vom Typ III df
Mittel der
Quadrate F Signifikanz
R-Quadrat = ,005 (korrigiertes R-Quadrat = -,005) a.
Test der Homogenität der Varianzen Performance
3,766 4 95 ,007
Levene-
Statistik df1 df2 Signifikanz
Die erste einfaktorielle Varianzanalyse untersucht den Einfluss des Ausbil- dungsortes auf die abhängige Variable (vgl. Tabelle 5). Es zeigt sich, dass der Faktor Ausbildungsort eine signifikante Wirkung auf die Performance hat, denn Femp > −p Wert. Dies bedeutet, dass nicht davon ausgegangen werden kann, dass die Absolventen der 5 Universitäten eine unterschiedliche Ar- beitsperformance aufweisen. Die Unterschiede der Faktorstufenmittelwerte sind also als zufällig anzusehen und nicht statistisch gesichert. Dies bedeutet für die Unternehmensberatungsgesellschaft, dass die Absolventen der 5 Uni- versitäten ungefähr gleich gut einzuschätzen sind. Das Unternehmen kann folglich keine Hinweise für die effizientere Gestaltung des Rekrutierungspro- zesses aus dieser ersten Analyse gewinnen.
Mit der zweiten einfaktoriellen Varianzanalyse wird überprüft, ob das Ge- schlecht die Arbeitsleistung im ersten Jahr beeinflussen kann (vgl. Tabelle 6).
Hier wird ersichtlich, dass nicht von einem signifikanten Einfluss des Ge- schlechts auf die Performance ausgegangen werden muss, da
Femp < −p Wert. Dies bedeutet, dass zwischen den weiblichen und männli- chen Absolventen deutliche Unterschiede hinsichtlich der Arbeitsleistung be- stehen müssen.
Tabelle 6: Einfaktorielle Varianzanalyse (Geschlecht)
Tests der Zwischensubjekteffekte Abhängige Variable: Performance
34,321a 4 8,580 49,802 ,000
912366,922 1 912366,92 5295538 ,000
34,321 4 8,580 49,802 ,000
16,368 95 ,172
912417,611 100
50,689 99
Quelle
Korrigiertes Modell Konstanter Term Universität Fehler Gesamt Korrigierte Gesamtvariation
Quadratsum
me vom Typ III df
Mittel der
Quadrate F Signifikanz
R-Quadrat = ,677 (korrigiertes R-Quadrat = ,664) a.
Test der Homogenität der Varianzen Performance
,041 1 98 ,840
Levene-
Statistik df1 df2 Signifikanz
Tabelle 7: Zweifaktorielle Varianzanalyse mit Wechselwirkungen
Tests der Zwischensubjekteffekte Abhängige Variable: Performance
35,109a 9 3,901 22,534 ,000
912366,922 1 912366,92 5270368 ,000
34,321 4 8,580 49,565 ,000
,274 1 ,274 1,580 ,212
,514 4 ,128 ,742 ,566
15,580 90 ,173
912417,611 100
50,689 99
Quelle
Korrigiertes Modell Konstanter Term Universität Geschlecht
Universität * Geschlecht Fehler
Gesamt Korrigierte Gesamtvariation
Quadratsum
me vom Typ III df
Mittel der
Quadrate F Signifikanz
R-Quadrat = ,693 (korrigiertes R-Quadrat = ,662) a.
In einem letzten Analyseschritt wird überprüft, ob auch die Wechselwirkun- gen der Faktoren eine eigenständige Wirkung auf y haben. Daher ist in Ta- belle 7 eine Varianzanalyse mit allen 2 Faktoren und den möglichen Wech- selwirkungen berechnet worden. Es ist zu erkennen, dass der Einfluss des Interaktionseffekts wegen Signifikanz verworfen werden muss (F-Wert 0.742). Die Plots der Faktorstufenmittelwerte (vgl. Abbildung A2 im Anhang) bestätigen insgesamt diesen Eindruck. Für die Faktoren selbst (Haupteffekte)
ist in dieser zweifaktoriellen Varianzanalyse dieselbe Testentscheidung wie bei den einfaktoriellen Varianzanalysen zu treffen.
Abschließend muss festgestellt werden, dass die Überprüfung der in Kapitel 3.2 geforderten Annahmen zur Varianzanalyse mit SPSS nicht durchgeführt werden kann.
Abkürzungsverzeichnis
Anhang
Abbildung A1: Boxplots
männlich weiblich
Geschlecht
93,00 94,00 95,00 96,00 97,00
Performance
Quitten- Herdecke
Leo X-Uni HalleGlobalisierungs HS Leipzig
WHU Kalender evang. Uni Eichstätt
Universität
93,00 94,00 95,00 96,00 97,00
Performance
65
Abbildung A2: Plot der Faktorstufenmittelwerte
evang. Uni Eichstätt WHU Kalender Globalisierungs
HS Leipzig Leo X-Uni Halle Quitten-
Herdecke
Universität
96,50
96,00
95,50
95,00
94,50
Geschätztes Randmittel
weilich männlich Geschlecht Geschätztes Randmittel von Performance
Abbildung A3: Histogramm der Residuen bei zweifaktorieller Varianzanaly- se
1,50 1,00 0,50 0,00 -0,50 -1,00 -1,50
Residuen für Performance
20
15
10
5
0
Häufigkeit
Mittelwert =-1,0592E-14 Std.-Abw. =0,39671
N =100