Hohdimensionale Integrale
Das Pfadintegral kann nur für sehr einfahe Systeme wie den harmonishen Oszillator
oder dasfreieTeilhen explizitberehnetwerden. FürkompliziertereSystememahtman
Gebrauh von Störungstheorien(z.B. semiklassishe Entwiklung, Störungstheorie inder
Wehselwirkung, Hohtemperaturentwiklung) oder numerishen Methoden. Wir haben
gesehen,dassdiePfadintegralefürthermodynamisheGröÿenundKorrelationsfunktionen
durh endlihdimensionale Integrale approximiert werden. Dabei wird die Zeit diskreti-
siert,
s ∈ { 0, ǫ, . . . , nǫ = τ }
, und die Wirkung durh eine Riemannshe Summegenähert.Diese hängtvon den Werten
q
= { q 0 , q 1 , . . . , q n } = { q(0), q(ǫ), . . . , q(nǫ) }
des Weges
q(s)
anden Gitterpunktens k = kǫ
ab. In dieser Gitterapproximationist jeder Erwartungswert durhein endlih-dimensionalesIntegral gegeben,h O i =
R D
qO(
q) e − S(q)
R D
qe −S(q) ,
mit
Z
D
q= Z ∞
−∞
Y n
1
dq j ,
(3.1)mitder in (2.53) eingeführten euklidishen Gitterwirkung
S(
q) = S(q 1 , . . . , q n )
(stattS E
shreiben wir in diesem Abshnitt
S
).3.1 Hohdimensionale Integrale
Niht nur in Quantenstatistik, Festkörperphysik, euklidshen Quanenfeldtheorie, Hoh-
energiephysikoderanderen Teilgebieten derPhysik und Chemiegilteshohdimensionale
Integrale möglihst ezient zu berehnen und dabei den Fluh der Dimenion zu vermei-
den.Zum Beispiellästsih derErwartungswert von Zinsderivatienalshohdimensionales
Integral shreiben. Bei einer Laufzeit von 30 Jahren zu je 12 Monaten und Verwendung
eines eigenen Zinssatzes für jeden Monat handelt es sih hier um 360-dimensionale Inte-
grale. Integrale von noh vielhöherer Dimension sind in Physik und Chemieniht unge-
wöhnlih. Hier sind eziente Algorithmen gefragt, die derartige Integrale bis auf einen
abshätzbaren Fehler berehnen.
3.1.1 Numerishe Algorithmen
Numerishe Integrationsmethoden werden seit Jahrhunderten benutzt. Es gibt zwei be-
kannte Kategorien:Formeln,welhe den Integrand anäquidistanten Stützstellen auswer-
ten(Newton-CotesIntegrationsregeln)undFormeln,welhedenIntegrandenansorgfältig
ausgewählten,aberniht äquidistanten Stützstellenauswerten (Gauÿshe Integrationsre-
geln). FürspezielleIntegranden führtdiezweite Klasse meistenszu besseren Resultaten.
Die numerishen Algorithmen beruhen auf der Riemannshen Denition von Integra-
len. Um nahzuprüfen, ob ein Funktion
f : [a, b] →
R Riemann-integrierbar ist, wähle man eine Einteilung des Intervalls,γ : a = x 0 < x 1 < x 2 < . . . < x n−2 < x n−1 < x n = b
(3.2)und deniert die zu dieser Einteilung gehörendeRiemannshe Unter- und Obersumme
U (f, γ) = X n−1
i=0
(x i+1 − x i ) · inf { f(x) | x i ≤ x ≤ x i+1 } O(f, γ) =
X n−1
i=0
(x i+1 − x i ) · sup { f (x) | x i ≤ x ≤ x i+1 } ,
mit
O(f, γ) ≥ U (f, γ)
. Istsup
γ
U (f, γ) = inf
γ O(f, γ),
dann heiÿt
f
im Riemannshen Sinneintegrierbar undZ b a
f (x)dx ≡ sup
γ
U (f, γ)
(3.3)das Riemannshe Integral von
f
.DieseDenition kann leihtaufmehrdimensionaleInte- grale ausgedehnt werden und wird beinumerishen Rehnungen gebrauht.Die meistenAlgorithmen beruhen darauf,dass jedeglatteFunktiondurhInterpolati-
onspolynome approximiert werden kann. Wirerinnern daran,dass es genauein Polynom
P mvomGrade≤ m
gibt,welhesan(m+1)
vorgegebenenStützstellenx 0 , x 1 , . . . , x m−1 , x m
vorgegebeneWerte
f 0 , . . . , f m annimmt,wobeif i = f (x i )
ist.ZurexplizitenKonstruktion
deniert man die m + 1
Lagrangeshen Polynome vom Gradem
:
L (m) p (x) = Y m
i=0 i6=p
x − x i
x p − x i
, p = 0, . . . , m,
mitL (m) p (x q ) = δ pq .
(3.4)Das interpolierende Polynom vomGrade
m
ist dannP m (x) =
X m
p=0
f (x p )L (m) p (x).
(3.5)Es giltnun der folgende
Satz: Es sei
f
eine auf dem Intervall∆ (m + 1)
-mal stetig dierenzierbare Funktion,und sei
P m das zu den Stützstellen x 0 , . . . , x m ∈ ∆
gehörige Interpolationspolynom vom
Grade≤ m
. Dannexistiertzujedemx ∈ ∆
einPunktξ(x)
(gelegenimkleinstenIntervall,
welhes die Punkte
(x 0 , . . . , x m , x)
enthält) derart, dassf (x) − P m (x) = f (m+1) (ξ(x))
(m + 1)! L (m) (x), L (m) (x) = Y m
i=0
(x − x i ).
(3.6)AufgrunddesSatzesergibtsihfürdasIntegral
R dxf (x)
vonderkleinstenbiszurgröÿtenStützstelle dieFormel
Z xm
x
0dx f(x) = X m
p=0
f (x p ) Z
dx L (m) p (x)
| {z }
γ
p(m)+ Z
dx f (m+1) (ξ(x))
(m + 1)! L (m) (x).
(3.7)Die
γ p (m) heiÿen Gewihte und die x p Knoten der Integrationsformel. Für äquidistante
Knotenan den Stellen
x 0 , x 1 = x 0 + ǫ, x 2 = x 0 + 2ǫ, . . . , x m = x 0 + mǫ
(3.8)erhalten wir mit der Substitution
x = x 0 + ǫt, t ∈ [0, m]
dieGewihteγ p (m) = ǫ
Z m 0
Y m
i=0 i6=p
t − i
p − i dt := ǫw (m) p = ǫw m−p (m) , p = 0, 1, . . . , p.
(3.9)Wendenwir das allgemeineResultat (3.7)auf diekonstanteFunktion
f = 1
an, soergibtsih dieSummenformel
p γ p = mǫ oder auh
w (m) 0 + w 1 (m) + . . . + w m (m) = m.
(3.10)Die Newton-Cotes-Formelnlauten nun
Z xm
x
0dxf(x) ∼ X m
p=0
ǫ w (m) p f(x 0 + ǫp), x m = x 0 + mǫ.
(3.11)Man ndetfolgende Gewihte
m
Namew (m) p (p = 0, 1, . . . , m) 0
Rehtekregel1
1
Trapezregel1 2 1 2 2 Simpson-Regel
1 3
4 3
1 3
3 3/8 −
Regel3 8 9 8 9 8 3 8 4 Milne-Regel
14 45
64 45
24 45
64 45
14 45
5 288 95 375 288 250 288 250 288 375 288 288 95 6
Weddle-Regel41 140
216 140
27 140
272 140
27 140
216 140
41 140
(3.12)
x f (x)
− ǫ 0 ǫ
Wir illustrieren die Fehleranalyse für
die Simpson-Regel. Dazu betrahten
wirdieDierenzzwishendemIntegral
der Funktion
f(x)
von− ǫ
bisǫ
(sie-heAbbildung)undderNäherung(3.11)
für
m = 2
, alsoden FehlerE 2 (ǫ) =
Z ǫ
−ǫ
dx f (x) − ǫ
3 (f ( − ǫ) + 4f (0) + f (ǫ)) .
Wir leiten
E 2 (ǫ)
dreimalnahǫ
abund erhaltenE 2 ′′′ (ǫ) = − ǫ
3 ( − f ′′′ ( − ǫ) + f ′′′ (ǫ)) .
Dies kann betragsmäÿigwie folgt abgeshätzt werden:
| E 2 ′′′ (ǫ) | = ǫ
3 | f ′′′ (ǫ) − f ′′′ ( − ǫ) | ≤ 2ǫ
3 M 3 mit M 3 = sup
t∈[−ǫ,ǫ] | f ′′′ (t) | .
Die Integration ergibtdie Fehlerabshätzung
| E 2 (ǫ) | ≤ M 3 · ǫ 4
36 .
(3.13)Falls dieFunktion
f
mindestens viermal stetig dierenzierbar ist, kann man aufE 2 ′′′ den
Mittelwertsatzanwenden,
E 2 ′′′ (ǫ) = 2ǫ
3 ǫ · f (4) (ξ),
und es folgtdieverbesserte Abshätzung
| E 2 (ǫ) | ≤ M 4 · ǫ 5
90
mitM 4 = sup
t∈[−ǫ,ǫ] | f (4) (t) | . (3.14)
Hieraus ergibt sih die bemerkenswerte Tatsahe, dass durh die Keplershe Fassregel
sogar kubishe Polynomeexakt integriert werden. Fürdie anderen Verfahren erhältman
analoge Fehlershranken für das Integral von der kleinsten bis zur gröÿten Stützstelle
(
M m = sup [x0,x
m] | f (m) |
):
m
NameE m (ǫ) m
NameE m (ǫ)
0
Rehtekregel1
2 ǫ 2 M 1 4 Milne-Regel
8 945 ǫ 7 M 6
1
Trapezregel12 1 ǫ 3 M 2 5 12096 275 ǫ 7 M 6
2
Simpson-Regel1
90 ǫ 5 M 4 6 Weddle-Regel
9
1400 ǫ 9 M 8
3 3/8 −
Regel80 3 ǫ 5 M 4
(3.15)
Allgemeingilt,dassfürgerade
m
sogarPolynomevomGradm+1
exaktintegriertwerden.Für groÿe
m
werden dieKoezienten inden Newton-CotesFormelnallerdingsgross und haben wehselndeVorzeihen. Dies führtzu Dierenzengrosser Zahlenund auh deshalbwerdendieNewton-Cotes Verfahrenhöherer Ordnunginder Praxiskaum eingesetzt.Für
niht genügend oft dierenzierbare Funktionen können die auf Interpolationspolynomen
beruhenden Methoden völligfalshe Resultateliefern!
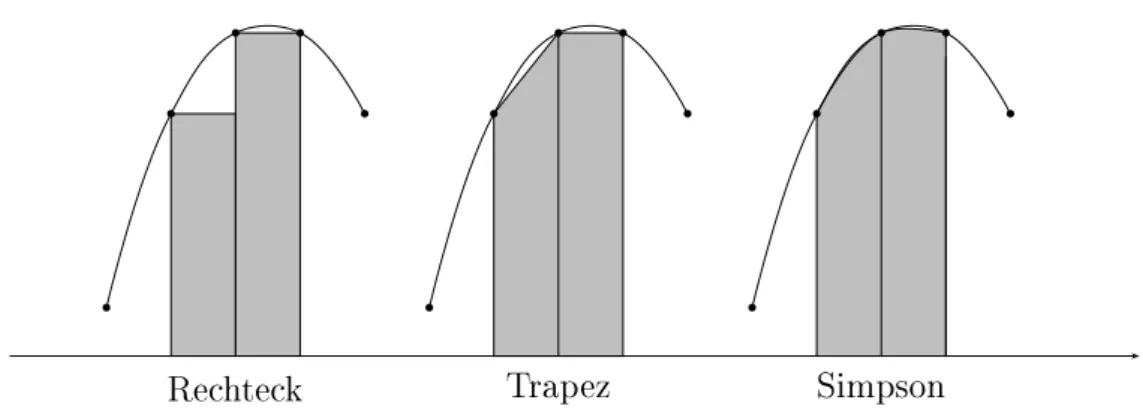
Zusammengesetzte Integrationsformeln: Indem das Integrationsintervall, über
das die Funktion
f
integriert werden soll, in kleinere, gleih groÿe Teilintervalle zerlegtwird, gelangt man zum Rehtek-, Trapez-, Simpson-oder den höheren Integrationsver-
fahren. Die Anzahl Intervalle sollte ein Vielfahes von
m
sein. Zum Beispiel wird beimSimpsonverfahrendie Keplershe Fassregel auf Doppelintervalleangewandt.
Milne Simpson
WirbetrahtendiezusammengesetzteSimpsonregeletwasnäher.DasIntegrationsintervall
[a, b] = [x 0 , x 2n ]
enthalte2n
TeilintervallederLängeǫ
,b − a = 2nǫ
.Die2n + 1
Stützstellen sindx j = a + ǫj, j = 0, 1, . . . , 2n
. Das Integral wird approximiert durhS 2 (f ) ≈ ǫ 3
{ f (x 0 ) + 4f (x 1 ) + f (x 2 ) } + { f(x 2 ) + 4f(x 3 ) + f(x 4 ) } + . . . . . . + { f (x 2n−2 + 4f (x 2n−1 ) + f(x 2n }
= ǫ
3 f(x 0 ) + 4
n − 1
X
j=0
f (x 2j+1 ) + 2
n − 1
X
j=1
f (x 2j ) + f(x 2n )
! .
Der Fehler kann wie folgt abgeshätzt werden
Z b a
f(x)dx − S 2 (f) ≤ 1
90 ǫ 5 · n sup
t ∈ [a,b]
f (4) (t)
| {z }
M
4= b − a
180 ǫ 4 M 4 .
(3.16)Allgemeiner giltfür eine äquidistante Einteilung des Integrationsintervalls in
m · n
Teil-intervalle,sodass
b − a = (mn)ǫ
ist, dieAbshätzungZ b
a
f (x)dx − S m (f )
≤ b − a
mǫ E m (ǫ)
(3.17)mit
E m (ǫ)
aus (3.15). Dabei istnatürlihM m = sup [a,b] f (m).
Mit Hilfe eines C-Programms berehnen wir das Integral einer Funktion über das In-
tervall
[a, b]
und zwar aufvier Arten: mitdem Rehtek-, Trapez- und Simpsonverfahren sowie mitHilfederMonte-CarloMethode.DasletzteVerfahrenwirdweiteruntenbespro-hen. Nohmals zur Erinnerung:
Rehtekregel
:
n − 1
X
i=0,1,2
ǫf(x i )
Trapezregel
:
X n−1
i=0,1,2
ǫ
2 (f (x i ) + f (x i+1 ))
(3.18)Simpson-Methode
:
X n−2
i=0,2,4
ǫ
3 (f (x i ) + 4f(x i+1 ) + f(x i+2 )) .
In der letzten Formel soll
n
eine gerade Zahl sein. Die Näherungen sind inder folgendenFigur skizziert.
Rehtek
Trapez Simpson
b b
b b
b
b b
b b
b
b b
b b
b
Das Programm1dintegral. auf Seite 47 berehnet das Integral
R 1
0 dx e x
fürǫ ∈
10 −n | n = 1, 2, . . . , 6 .
Die Werte für die stükweise konstante, lineare oder quadratishe Näherung sind in der
folgenden Tabelle enthalten. Für das Simpsonverfahren konvergiert wie erwartet dieNä-
herung sehr shnell gegen den exakten Wert
1.7182818
.n, log M
einfah Trapez Simpson MC1 1.633799 1.719713 1.718283 1.853195 2 1.709705 1.718296 1.718282 1.793378 3 1.717423 1.718282 1.718282 1.720990 4 1.718196 1.718282 1.718282 1.711849 5 1.718273 1.718282 1.718282 1.719329 6 1.718281 1.718282 1.718282 1.718257
3.1.2 Monte-Carlo Integration
Die Monte-Carlo Methode stammt wahrsheinlih von Stanislaw Ulam. Er fand die
Methode 1946, als ersih Gedanken über dieGewinnwahrsheinlihkeiten beim Solitair-
Spiel mahte. In seinen Worten:
The rst thoughts and attempts I made to pratie [the Monte Carlo Method℄
were suggested by a question whih ourred to me in 1946 as I was onva-
lesing from an illness and playing solitaires. The question was what are the
hanesthataCaneldsolitairelaidoutwith52ardswillomeoutsuessful-
ly? Afterspending a lot of time trying toestimate them bypure ombinatorial
alulations, I wonderedwhether a more pratialmethod thanabstrat thin-
king mightnotbeto lay it out sayone hundredtimes andsimply observe and
ount the number of suessful plays....
Einige Jahre später wurdedie Methode auf das Neutronendiusionsproblem angewandt,
das mit anderen Methoden niht lösbar shien [25℄. Eine wihtige Anwendung ist die
Berehnung hohdimensionalerIntegrale. Einsehr einfaher Algorithmuswäre:
•
erzeugeM
gleihverteiltePunkte{ x 1 , . . . , x M }
imIntegrationsgebietG
,•
berehne für jeden Punkt den Funktionswertf (x i ), i = 1, . . . , M
,•
berehne den MittelwertI(M ) =
Vol( G ) M
X M
i=1
f(x i ).
(3.19)FüreineRiemann-integrierbareFunktionkonvergiert
I (M )
fürgroÿeM
gegendasIntegralR
G f.Die Werte inder letztenSpalteder obigenTabelleenthaltenI (M = 10, 100, . . .)
für
das Integral der Exponentialfunktion.
Die folgende Abbildung illustriert das Konvergenzverhalten der drei Integrationsme-
thoden mit äquidistanten Stützstellen und der einfahen Monte-Carlo Integration. Für
die Exponentialfunktion liefert die Methode von Simpson shon für zehn Intervalle das
rihtige Resultat
e
bisauf die6.
Stelle hinter dem Komma.1.62 1.70 1.78
log 10 n
b
b
b b b b
einfah
b b b b b b
Trapez
b b b b b b
Simpson
b
b
b
b b
MC
1 2 3 4 5 6
Unpraktikabelwerden Standardverfahren wenn dieDimension
n
des IntegralsI =
Z
dq 1 . . . dq n f(q 1 , . . . , q n ) ≡ Z
d n qf (
q)
(3.20)gross wird. Sind zum Beispiel die Integrationsgrenzen in jeder Dimension gleih
0
und1
, und wählt man in jeder Dimension den gleihen Abstandǫ
zwishen den Stützstellen, dann istderen Anzahlǫ −n.Der Rehenaufwand istproportionalzur Anzahl Stützstellen.
Nehmen wir alsBeispiel
ǫ = 0.1
, was siherlih eine grobe Einteilungdes Intervalls[0, 1]
ist, dann ist die Anzahl Stützstellen
∼ 10 n. Die Auswertung einer Stützstelle auf einem
PC dauert etwa 10 − 7 s
und dieBerehnung eines 12
-fahen Integral etwa einen Tag.
Hit-or-miss Monte Carlo Methode und Binomialverteilung
Gesuht seiwiederder Wert des Integrals
I = R
dx f (x)
,x 1 1 y
wobei wir ohne Beshränkung der Allgemeinheit
annehmendürfen,dass wirvon
0
bis1
integrieren.Mit einem Zufallszahlengenerator, der zwishen
0
und
1
gleihverteilte Zahlen liefert, werden zwei Zufallszahlen0 ≤ r 1 , r 2 ≤ 1
erzeugt,x = r 1 , y = r 2 .
Wir haben getroen, wenn
y ≤ f(x)
ist. DieWahrsheinlihkeitfür einen Treer ist
p =
Anzahl TreerAnzahl Versuhe
=
dunkle FläheGesamtähe
= I
1 = I.
(3.21)Bei
M
statistishunabhängigenVersuhenkönnenwirk ∈ { 0, . . . , M }
TreerlandenunddieWahrsheinlihkeit dafür istdurh dieBinomialverteilung
P (M, k) = M
k
p k (1 − p) M−k mit
X M
k=0
P (M, k) = 1
(3.22)gegeben.HieristzumBeispiel
p k (1 − p) M−kdieWahrsheinlihkeitdafür,dassdieerstenk
Versuhe Treer und dieletzten
M − k
Versuhe Nieten ergeben. DerBinomialkoezient zählt dieAnzahl Möglihkeiten, aus der Menge vonM
Versuhenk
Treer auszuwählen.Die Binomialverteilung beshreibt eine bei
pM
lokalisierte Glokenkurve und ist in der folgendenFigur fürM = 10
undp = 0.3
geplotted.b b
b b
b
b
b
b b b b
2 4 6 8 10
1 2 3
P (M, k)
k M = 10
p = 0.3
rehnet werden,
Z(t) = e tk
= X M
k=0
e kt P (M, k)
= e t p + (1 − p) M
.
(3.23)Als Summe von Wahrsheinlihkeiten ist
Z(0) = 1
. Erwartungswerte von beliebigen Potenzen vonk
können durh ableiten dererzeugenden Funktion gewonnenwerden.
Nihtunerwartet istder mittlere Anteil Treer gleih
k M
= 1 M
X M
k=0
k P (M, k) = 1 M
dZ dt
t=0 = p. (3.24)
Das Quadrat der Streuung um den Ursprung ist
k 2 M 2
= 1 M 2
X M
k=0
k 2 P (M, k) = 1 M 2
d 2 Z dt 2
t=0 = p M +
1 − 1
M
p 2 (3.25)
und für das Quadrat der Streuung um diemittlere AnzahlTreer ndet man
σ 2 = 1 M 2
D k − h k i 2 E
= 1 M 2
d 2 log Z dt 2
t=0 = p(1 − p)
M .
(3.26)DieStreuungumdenMittelwertvermindertsihrelativlangsammitderAnzahlVersuhe,
σ ∼ M −1/2. Eine Shätzung von p
ist h/M
,wobeih
die AnzahlTreer bei M
Versuhen
ist.Die folgende Tabelle enthält die Shätzwerte
p
undσ
fürdas IntegralI =
Z 1 0
f(x), f (x) = x 2 e x
1 − x + xe x .
(3.27)für vershiedene Anzahl
M
von Versuhen. Die Streuung um den wahren Wert des Inte-grals,
I = 0.376370
,nimmt mitM
ab. Die Werte in den ersten drei Spaltenwurden mitdem Programmhitmissflaehe. auf Seite 48 generiert.
Die grobe Hit-or-Miss Methode kann mit wenig Aufwand verbessert werden. Wenn
nämlih
p
gegen1
oder0
strebt so wirdσ
sehr klein (allerdings wird fürp → 0
derrelative Fehler gross). Wir nehmen nun eine Hilfsfunktion
g(x)
, dief(x)
möglihst gutapproximiert aber analytish noh integriertwerden kann. Ist das erste Integral in
I = Z
(f (x) − g(x)) dx
| {z }
p wird klein
+ Z
g(x)dx
| {z }
bekannt
(3.28)
kleinund der Integrand zwishen
0
und1
, dannkönnen wir dieses Integralmit dem Hit-or-miss Verfahren mitverminderter Varianz berehnen. Für
f(x)
in(3.27) wählen wirg(x) = x 2 mit
Z
g(x) dx = 1/3.
Dannergeben sihfürdas Integraldieverbesserten Shätzwerte inder drittletztenSpalte
und die Varianz in der letzten Spalte der Tabelle. Diese Werte wurden ebenfalls mit
hitmissflaehe. berehnet.
log 10 M p I − p σ p verb I − p verb σ verb
1 0.500000 − 0.123630 0.158114 0.333333 0.043037 0.000000 2 0.330000 0.046370 0.047021 0.363333 0.013037 0.017059 3 0.399000 − 0.022630 0.015485 0.377333 − 0.000963 0.006486 4 0.378900 − 0.002530 0.004851 0.376833 − 0.000463 0.002040 5 0.376570 − 0.000200 0.001532 0.377693 − 0.001323 0.000651 6 0.374857 0.001513 0.000484 0.376305 0.000065 0.000203 7 0.376273 0.000097 0.000153 0.376303 0.000067 0.000064
Summen von Zufallszahlen, Gauÿverteilung und Grenzwertsatz
Das Programmgaussdistr. auf Seite 49erzeugt dieSumme
s
vonn
auf demIntervall[0, 1]
gleihverteiltenunabhängigen Zufallszahlenx 1 , . . . , x n.Die erzeugendeFunktionfür
dieSumme ist
Z(t) = e ts
= Z
I
nd n x e t(x1+...+x
n) = Z 1
0
dx e tx n
= t − n e t − 1 n
,
(3.29)und für den Mittelwert von
s
nden wirm = h s i = dZ
dt
t=0 = Z
I
nd n x (x 1 + . . . + x n ) = n
2 .
(3.30)und für dessen Streuungsquadrat
d 2 log Z dt 2
t=0 = σ 2 = h s 2 i − m 2 = n
12 .
(3.31)Nah dem Gesetz der grossenZahlen erwarten wir dieGauÿverteilung
P s = 1
√ 2π σ e −(s−m)2/2σ
2.
(3.32)
DasProgrammgaussdistr. aufSeite49berehnet dieVerteilungvon
s
fürdieSummevon
10, 50
und100
Zufallszahlen. Zur Bestimmung der Verteilung werden jeweils eine MillionVersuhe gemaht.Mit den zufälligenWerten fürs
wird einHistogrammerstelltund im array mean[100℄ gespeihert. Wir haben die Zufallsvariable
s
mitn
reskaliert,so dass das Maximum der Verteilung bei
1/2
liegt. In der folgenden Abbildung werdendie Resultate der MC-Simulation (Punkte, Dreieke, Viereke) mit den entsprehenden
Gauÿverteilungen verglihen.
u
t ut ut
u t
u t
u t
u t
u t
u
t ut ut ut
u t
u t
u t
u t
u t
u t
u t
u t q
p qp qp qp qp
q p
q p
q p
q p
q p
q p
q p
q p
q p
q p
q
p qp qp qp qp
b b b b
b b
b b
b b b
b
b
b
b
b
b b
b b
˜ 1/2 s
P (n, ˜ s)
n = 10 n = 50
n = 100 α = σ/n
˜ s = s/n
Fit:
P (n, s) ˜ ∝ e − (˜ s − 0.5)2/2α
2
ImAnhang CndetsiheinBeweisfürdas Gesetz der groÿen Zahlen.Für gleihverteilte
Zahlen in
[0, 1]
ist der Mittelwert1/2
und die Varianz1/12
. Die Ungleihung (3.56) fürdie Wahrsheinlihkeit dafür, dass
s/n
mehr alsδ
vom Mittelwert1/2
abweiht, nimmtfolgende Form an
Pr s n − 1
2 ≥ δ
≤ 1
12nδ 2 .
(3.33)3.2 Important Sampling
Numerishe Integrationsverfahren nähern Integrale durh endlihe Summen,
Z
d n q f (
q) ∼ X M
µ=1
f(
qµ )∆qµ .
Für groÿe
n
und shwah veränderlihe Funktionenf
kann esvorteilhaft sein, dieStütz- punkte qµ
zufällig zu wählen. In vielen Anwendungen variiert der Integrand allerdings um Gröÿenordnungen fürvershiedene Punkte undman vergeudet Rehenzeitwenn manStützpunkte mitsehr kleinemIntegrandenauswählt.Beimimportant sampling,zumBei-
spiel dem Metropolis-Algorithmus, werdenbevorzugtPunkte q
µ
mitgroÿem Integranden berüksihtigt. Die Stützstellen liegen überwiegend da, wo der Integrand gross ist unddies verringert dieVarianz der einzelnen Shätzung für das Integral.
Dazu nimmtman eine Funktion
g(
q)
, derenIntegralberehenbar istund welhef (
q)
möglihst gut annähert, und shreibt
Z 1 0
f(
q) d n q = Z 1
0
f(
q)
g(
q) g(
q) d n q.
(3.34)Durh dieErzeugung von Zufallspunkten q
µ
diemitg (
q)d n q
verteiltsind, ergibt sihbeiM
Messungen die ShätzungZ
f(
q)d n q ≈ f ¯ = 1 M
X M
µ=1
f (
qµ )
g(
qµ ) , (3.35)
unddabeivariierendieSummandenjetztnihtmehrsostark.AllerdingsmuÿdasIntegral
von
g
bekannt sein, um aus gleihverteilten Zufallszahlen solhe zu erhalten, die mitg
verteiltsind.
Bei der Berehnung vonErwartungswerten inGitterfeldtheorien,
h O i ≈ 1 Z
Z
D
qO(
q)e −S(q) , D
q = d n q, Z = Z
e −S(q) D
q,
(3.36)wäre es wünshenswert dieBoltzmannverteilung
P (
q) = 1
Z e −S(q) ,
(3.37)
alsVergleihsfunktion
g
zu wählen, weildannnurnohüberdieimVergleihzuP
indenmeistenFällen glattenObservablen
O(
q)
gemitteltwerden müsste,h O i ≈ O ¯ = 1
M X M
µ=1
O(
qµ ). (3.38)
Hier ist
M
die Anzahl der erzeugten Punkte qµ
. Damit wird dieMonte Carlo-ShätzungO ¯
fürdenMittelwertvonO
zueinemarithmetishenMittel.Passendverteilte{
q1 ,q2 , . . . }
sind aber niht ohne Weiteres zu erzeugen.
Wir haben folgendes Problem:Die
n −
dimensionalen Integraleh O i = Z
dq 1 . . . Z
dq n O(
q)P (
q), Z
D
qP (
q) = 1,
(3.39)sollen für vershiedene Funktionen (Observablen)
O (
q)
, aber diegleihe Wahrsheinlih- keitsdihteP (
q)
berehnet werden. Dazu sollen Algorithmen gefunden werden, die nahP
verteilte Punkte generieren. Der folgende Metropolis-Algorithmus[25℄ (er wird später begründet werden) erzeugt{
qµ }, diegemäÿ P (
q)
verteilt sind:
1. Beginne mit
µ = 0
und einem beliebigenStartpunkt qµ
imIntegrationsbereih.2. Wähle einen zweiten zufälligenPunkt q
′
und einZufallszahl
r ∈ [0, 1]
.3. Ist
P (
q′ )/P (qµ ) > r dann setze man qµ+1 =q′
, andernfallsqµ+1 =qµ
.
µ+1 =q′
, andernfallsqµ+1 =qµ
.
µ
.4. Erhöhe
µ
um eins und wiederholedie Shritte2, 3
und4
.Die soerzeugten Punkte q
µ
im Integrationsgebiet sind gemäÿP (
q)
verteilt, sodassO ¯ = 1
M X M
µ=1
O (
qµ ) (3.40)
ein Shätzwert für
h O i
ist, der für groÿeM
gegenh O i
konvergiert. Jeder Punkt qµ
derMarkovkette heisst Konguration.
Das Programmsamplingflaehe. auf Seite 50 berehnet mitHilfe des Metropolis-
Algorithmus Shätzwerte für das eigentlihe Integral
I = 128 · R 1
0 dxdydz x 3 y 2 z exp ( − x 2 − y 2 − z 2 ) R 1
0 dxdydz exp ( − x 2 − y 2 − z 2 ) = 128 · h x 3 y 2 z i ≈ 2.4313142,
wobeifür
P
dieExponentialfunktiongewähltwurde. DieKonvergenzzum exaktenResul- tat ist langsam, der Fehler ist vonder Ordnung1/ √
M
. Die folgende Tabelle enthält dieberehnetenShätzwerte.DerletzteEintragistdasResultatvon