Den Einfluss der Suchmaschinenoptimierung messbar machen
26
0
0
Volltext
(2)
(3)
(4)
(5)
(6)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
Abbildung
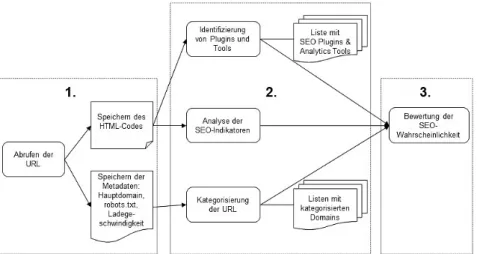
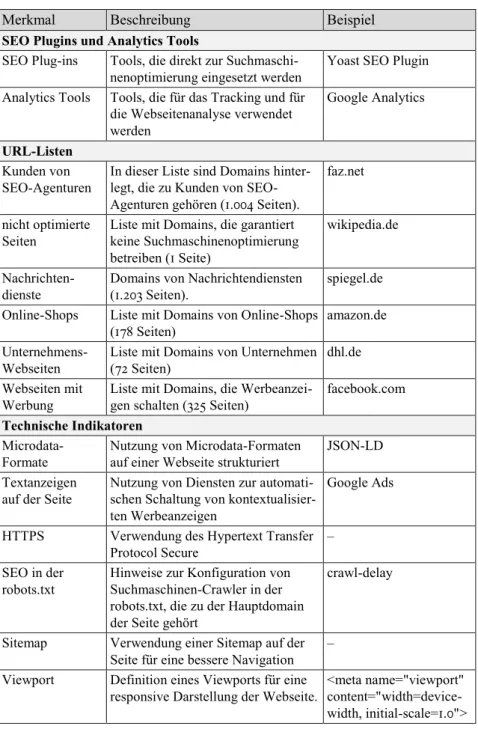
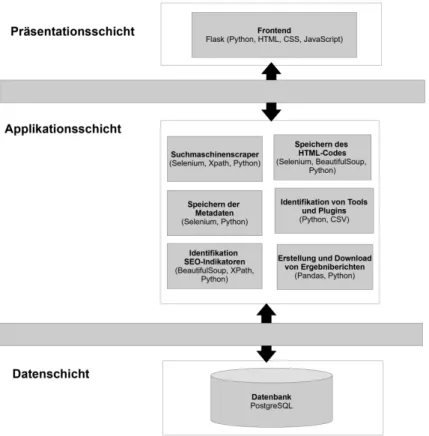

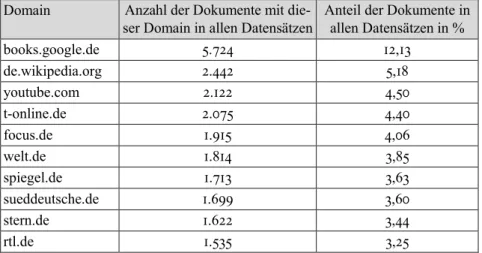
+3
ÄHNLICHE DOKUMENTE
Quality control of LNS cores through automatic digital photo processing In order to maintain a consistently high qua- lity of LNS material control and selection of the core
Dafür wurde von der KVB extra ein neunköpfiges Tutoren- Team geschult, das sich zunächst um die Fortbildung der angehenden Moderatoren und später auch um deren komplette Ausbil-
Der finanzielle Aufwand für derartige Kontrollen lohnt sich auch für mittlere und kleinere Gebäude, wie ein kürzlich abgeschlossenes Forschungsprojekt im Auftrag des Bundesamts
Zusätzlich garantiert Energho, dass der Wärme- und Strombedarf des Gebäudes durch die Optimie- rungsmassnahmen innerhalb von fünf Jahren um mindestens 10 % sinkt.. Hilfe
Mannheimer Straße: Geplanter Baubeginn März; Kosten: 90.000 Euro; Bauzeit: 3 Wochen; Länge circa 300 Meter; Art der Bautätigkeit: Deckensanierung im Bereich der Fahrbahn
Die Abläufe in der Zulassungsstelle wurden in Zusammenarbeit mit den Mitarbeiter*innen so umstrukturiert und optimiert, dass den Kunden*innen in der Woche die Dienstleitungen
Das Heft kann außerdem über die Webseite des Vereins „Flüchtlingshilfe München e.V.“.. unter www.�luechtlingshilfe-muenchen.de als PDF kostenlos
"Wesentliche Elemente des Konzeptes sind unter anderem, dass der zentrale Veranstaltungsort, der Berliner Platz, von Donnerstag bis Sonntag weiträumig für den Verkehr gesperrt
