Allgemeiner Beitrag
Frank Nickel*
„ Unbekannt “ heißt nicht „ Ich verstehe es nicht “
Von der Identifizierung deutsch-englisch-japanischer Kognaten und ähnlicher Wörter durch japanische Deutschlernende
DOI 10.1515/infodaf-2017-0002
Zusammenfassung: Die aktuellen Forschungsergebnisse zeigen, dass Sprache weder isoliert gelernt noch verarbeitet wird, daher scheint eine Berücksichtigung von bereits gelernten Sprachen beim Deutschlernen nur folgerichtig. Für einen künftigen Lernerwortschatz für Deutsch als Fremdsprache nach Englisch in Japan wurden zwei Umfragen durchgeführt, um die Fähigkeiten des Erkennens unbe- kannten Vokabulars von Studienanfängerinnen und -anfängern des Deutschen an japanischen Universitäten zu testen. Hierbei wurde gemeinsames deutsch- englisches Vokabular berücksichtigt sowie englische Lehnwörter, die es sowohl im Japanischen als auch im Deutschen gibt.
Schlüsselwörter:Deutsch als Fremdsprache, Mehrsprachigkeit, Lexik, Vokabular
Abstract: The latest research shows that Language can neither be learned in isolation to the language a learner knows already, nor can the brain handle the new language separately to already studied languages. Therefore, a consideration of languages already known and studied by the learners appears to be plausible.
Two studies were carried out in order to examine the students’ abilities to recognise unknown vocabulary for the purpose of a future learner’s vocabulary German as a Foreign Language after English (GFLE (German: DaFnE)). For this, the common English-German vocabulary as well as English loan words in Japane- se have been used. This article presents the results and analyses the outcome for future use of English loan words to study German as a third language
Keywords:German as a Foreign Language, Multilingualism, Vocabulary
*Kontaktperson: Frank Nickel,E-Mail: nickel.frank@aoni.waseda.jp
1 Bisherige Forschungsarbeit zum mentalen Verarbeiten von Vokabular
Die Wissenschaft hat bei der Erforschung der mentalen Lernprozesse in den letzten zwei Dekaden gute Fortschritte gemacht, angefangen von Levelt (1989) über Gass/Selinker (1992), Lutjeharms (1999), Marx (2004), Targonska (2004), Herdina/Jessner (2002) bis hin zu Szubko-Sitarek (2015), um nur einige zu nen- nen. Durch diese Forschung hat sich die Ansicht, Sprache sei getrennt lernbar und werde separat verarbeitet, gewandelt zu dem Verständnis, dass gelerntes Wissen und gelernte Sprache miteinander interagieren.
Ebenfalls großen Fortschritt gab es im Bereich der deutschen Mehrsprachig- keitsforschung. Bausch (1992), Neuner (1996), Bausch (2003), Marx (2004), Huf- eisen (2005), Bausch/Helbig (2007), Jessner (2006) u. v. m. haben dieses Feld weiterbearbeitet. Seit der ersten Arbeit Britta Hufeisens im Jahre 1991 sind 25 Jah- re vergangen. Hufeisen war eine der Ersten im deutschen Sprachraum, die sich mit dem Thema„Deutsch nach Englisch“beschäftigte. In der Zwischenzeit gab es eine steigende Zahl Publikationen und Untersuchungen zu diesem Thema. Die entsprechende Forschung geht inzwischen sogar so weit, von einem „schu- lischen Gesamtsprachencurriculum und Mehrsprachigkeit“ (Hufeisen 2012) zu sprechen.
Soweit steht es mit der Tertiärsprachenforschung in Deutschland. In Japan allerdings gibt es im Bereich der Tertiärsprachenforschung derzeit nur wenig Literatur, auch wurde in diese Richtung auch noch keine ausreichende Forschung unternommen, um festzustellen, welcher Art und Größe das Lexikwissen ist, das tatsächlich für einen Spracherwerb einer Fremdsprache nach Englisch–oder für den Deutscherwerb–genutzt werden kann. In Japan wurde Englisch in der Schule bisher sechs Jahre lang gelernt, nach Plänen des japanischen Bildungsministeri- ums (MEXT, 2003) soll fortan sogar schon ab der dritten Klasse der Grundschule Englisch gelernt werden (www.kairyudo.co.jp). Dies heißt im Detail, dass künftige Studierende und Lernende des Deutschen etwa ab dem Jahr 2021 hiervon beim Lernen einer zweiten Fremdsprache an einer Universität profitieren können. Es wird also vier Jahre länger Englisch gelernt, was dazu führen sollte, dass u. a. mehr Vokabular bekannt ist und im Sprachunterricht genutzt werden kann. Da es bisher nur wenige Daten über das Vorwissen von japanischen Deutschlernenden gibt, habe ich mich diesem Feld angenommen, um die SituationDeutsch nach Englisch in Japan im Hinblick auf die Lexik genauer zu beleuchten.
Am Ende meines Dissertations-Forschungsprojektes soll ein Vokabular ste- hen, das für den Anfängerunterricht Deutsch genutzt werden kann, um schneller Sprachwissen aufzubauen und um zu (re-)aktivieren, was bereits vorhanden ist.
Daher wurden Befragungen durchgeführt, um das grundlegend vorhandene Wis- sen zu eruieren, mit dem im Deutschunterricht gearbeitet werden kann.
In diesem Artikel möchte ich die Ergebnisse aus zwei Befragungsrunden präsentieren, die zeigen sollen, wie viel Deutschlernern auf Anfängerniveau an japanischen Universitäten bereits aus dem Englischen bekannt ist und inwiefern dieses Wissen für den Erwerb deutscher Lexik genutzt werden kann.
Zuerst möchte ich allerdings auf den aktuellen Forschungsstand zum Thema des mentalen Lexikons eingehen. Anschließend soll auf die Verbindung von mentalem Lexikon zur SituationDeutsch als Fremdsprache nach Englischeinge- gangen werden, um schließlich die Ergebnisse der Befragung präsentieren zu können, die den Wissensstand von Lernenden genauer beleuchten.
1.1 Zusammenhänge von mentalem Lexikon und Sprachenlernen
Abbildung 1:TIA Modell von Dijkstra
1989 hat Levelt dasSpeaking Modelentwickelt, dessen Aufgabe es ist, mentale Prozesse der Sprachverarbeitung zu erklären. In der Beschreibung des Modells spricht er von einzelnen Verarbeitungskomponenten, die als„relativ autonome Spezialeinheiten“(Ender 2007: 80) funktionieren. Darüber hinaus unterscheidet er zwischen kontrollierter und automatisierter Verarbeitung. Erstere verlange bewusste Kontrolle, während die zweite automatisiert funktioniere (ebd.). Später wurde dieses Modell durch De Bot (1992) adaptiert und für die Mehrsprachigkeit angepasst. Hierbei lauten zwei der Anpassungen, dass einerseits die Sprachen je nach Kontext sowohl voneinander getrennt als auch zusammen funktionieren können und dass andererseits „Formen der gegenseitigen Beeinflussung der Sprache[n] wie Transfer und Interferenz[en]“ (Ender 2007: 81) berücksichtigt werden, da sie die Sprachprozesse beeinflussen. Aktuell schreibt Szubko-Sitarek zum Thema der mentalen Verarbeitung von Kognaten, dass für die mentale Ver- arbeitung bei der Wortwahl ein integriertes Lexikon angenommen wird, das alle Sprachen des Individuums umfasst (2015: 96). Dies unterstützt die Aussage Her- dinas, dass Mehrsprachige im Vergleich zu Monolingualen die Fähigkeit besitzen,
„sich auf eine Sprache als Objekt zu konzentrieren und abstrakt über sie nach- zudenken“(Herdina Jessner 2002: 62). Die Reflexion über Sprache ist damit ein wichtiger Bestandteil, der erst durch Mehrsprachigkeit entwickelt wird und der es ermöglicht, Sprache nicht nur als Teil der Persönlichkeit, sondern auch als Medium–für das erfolgreiche Erreichen eines Kommunikationsziels–zu sehen.
Dijkstra (2005) geht in seinem „Trilingual Interactive Activation Model“ von einem integrierten Lexikon aus, das auf vier Ebenen repräsentiert ist: der Merk- malsebene (feature level), der Buchstabenebene (letter level), der Wortebene (word level) und der Sprachebene (language level). Diese Ebenen spielen eine entscheidende Rolle bei der visuellen Worterkennung, da immer zuerst allgemei- ne Merkmale aktiviert werden, die dann ihrerseits bestimmte Buchstaben oder Buchstabenkombinationen aktivieren, welche dann bestimmte Wörter aktivieren.
Erst am Ende wird die Zugehörigkeit zu einer bestimmten Sprache aktiviert (siehe Abbildung 1). Dies bedeutet zweierlei: Einerseits leisten Sprechende bereits eine kognitive Arbeit, bevor sie sich sicher sein können, dass ein entsprechendes Wort zu der Sprache gehört, andererseits werden bekannte Wörter aller Sprachen eines Individuums unwillkürlich mitaktiviert. Ein weiteres Charakteristikum dieses Modells ist die Berücksichtigung der Frequenz eines Wortes und dessen letzte Benutzung. Diese zwei Aspekte sind von entscheidender Bedeutung, da Wörter demnach schneller erkannt werden, wenn sie hochfrequent sind oder wenn sie häufig benutzt werden. Schließlich bewirkt der Nachbarschaftseffekt (neighbour- hood effect), dass ein Wort, das Personen präsentiert wird, im mentalen Lexikon nicht nur dieses, sondern auch andere Wörter (im Modell auf der Wortebene) mitaktiviert, so werden z. B. beim englischen wind auch bind, kind, wild, wink
aktiviert (Dijkstra 2005). Dies kann so ausgelegt werden, dass die Sprachprozesse eines multilingualen Individuums weder bewusst noch unbewusst ausschließlich monolingual ablaufen können, da die Aktivierung anderer Sprachen automatisch vonstattengeht.
Zur Arbeitsweise des mentalen Lexikons und dessen Auswirkungen auf den Sprachprozess sind nicht nur theoretische Modelle entwickelt, sondern auch einige Studien durchgeführt worden. Olah (2007) hat sich damit beschäftigt, ob und wie englische Lehnwörter im Japanischen genutzt werden können, um die Fertigkeiten der Lernenden im gesprochenen Englisch zu verbessern. Seiner Ansicht nach ist beim Benutzen der japanischen Lehnwortkenntnisse im Eng- lischunterricht die größte Gefahr, dass Japaner und Japanerinnen glauben, Lehn- wörter im Japanischen und die englischsprachigen Originale hätten identische Bedeutungen (Olah: 181). Diese Annahme der Lernenden unterstreicht die effi- ziente Arbeitsweise des Gehirns, also die Annahme, dass vermeintlich gleiche Wörter in verschiedenen Sprachen auch gleiche Bedeutungen haben. Daher, so Olah, sollte der Fokus im Fremdsprachenunterricht darauf liegen, sowohl Aus- sprache- als auch Bedeutungsunterschiede zu vermitteln (Olah: 185). Bezüglich der Ähnlichkeit von Vokabular haben Dijkstra et al. erforscht, wie zwischen- sprachliche Gleichartigkeit von Vokabular die Wahrnehmung der Kognaten be- einflusst. Die Ergebnisse einer Studie zeigten, dass die Reaktionszeit bei Auf- gaben zu lexikalischen Entscheidungen eines passenden Wortes kürzer wird, je ähnlicher sich Wörter –also Kognaten bzw. Fast-Kognaten–in zwei Sprachen sind (Dijkstra et al.: 298), obwohl hinzugefügt werden muss, dass dieser Effekt in der Studie stark aufgabenabhängig war.
1.2 Arbeitsweise des mentalen Lexikons und wie man dies nutzen kann
Jeder, der ein neues Wort lernt, lernt damit auch dessen denotative und konnota- tive Bedeutung, dessen Aussprache und Schreibung, welcher Sprache es angehört und welcher Wortart sich das neue Wort zuordnen lässt, wie es morphologisch und syntaktisch eingesetzt werden kann und welche Wörter es typischerweise begleiten (Kollokationen) (vgl. Lutjeharms 2004). Dies bedeutet, dass beim Vo- kabellernen nichtnur ein neues Wortgelernt werden muss, sondern viele relevante Zusatzinformationen hinzukommen, die von dem/der Lernenden bewältigt wer- den müssen. Werden Wörter das erste Mal gelernt, so sind die Verarbeitungspro- zesse in der Regel zentral, also energie- und aufmerksamkeitsaufwendig, da Lernende sich aktiv auf das Lernen konzentrieren müssen. Erst später im Lern- prozess werden diese Abläufe automatisiert und beanspruchen damit weniger
Energie. Dieser Aufwand kann minimiert werden, wenn anstatt unbekannten Vokabulars, das keinen Bezug zu bereits erworbenem Wissen hat, Kognaten gelernt und benutzt werden, also Wörter gleicher etymologischer Herkunft, die in mehreren Sprachen vorkommen. Bereits 1999 sprach Lutjeharms davon, dass die gemeinsame Speicherung von Kognaten im mentalen Lexikon sehr wahrschein- lich ist. Dies impliziert, dass deren Erlernen mit weniger Aufwand einhergeht, da eine Verknüpfung der Kognaten unkomplizierter geschieht als das Erstellen eines neuen Eintrages im mentalen Lexikon. Innerhalb der allgemeinen Gruppen der Kognaten lässt sich noch weiter unterscheiden zwischen Konkreta und Abstrakta (De Groot, Annette M.B. 1993). De Groot et al. gehen davon aus, dass sich bei den Kognaten die Konkreta in verschiedenen Kulturen sehr ähnlich sind, da die Objekte untereinander geteilt werden können. Hingegen können die Abstrakta je nach Sprache spezifischer ausgeprägt sein, insbesondere zwischen Sprachen, die sich weniger konzeptuelle Charakteristika miteinander teilen. Daraus kann abge- leitet werden, dass Konkreta generell schneller und mit weniger Erklärungen seitens der Lehrperson erlernt werden können und Abstrakta längere Erklärungen und eine Bedeutungsbestimmung und -abgrenzung– wie von Olah genannt – erfordern.
Weltweit gibt es viele Entlehnungen aus anderen Sprachen. Auf diese Weise entstehen viele neue Kognaten, heutzutage zumeist aus dem Englischen. Dies deutet darauf hin,„dass die zugrundeliegenden Strukturierungsprinzipien für die in den verschiedenen Sprachen vollzogenen Kategorisierungen universal sind und sich wohl auf die Gliederung und Organisation des semantischen und kon- zeptuellen Gedächtnisses im mentalen Lexikon beziehen“ (Neuner-Anfindsen 2005: 80). Diese Strukturierungsprinzipien sind genauer: (1) die Fähigkeit, auf- grund gemeinsamer perzeptiver Merkmale klassifizierend zu erfassen, (2) die Fähigkeit, die dadurch entstandenen Objektklassen hierarchisch zu strukturieren und sich diese mithilfe von Merkmalscharakteristiken zu merken, (3) die Fähig- keit, Objektstrukturen und -konstellationen systematisch bestimmte Bedeutun- gen zuzuweisen (vgl. ebd.).
Was die Organisation des Vokabulars im mentalen Lexikon angeht, so kann neues Vokabular nicht nur extrinsisch, durch natürliche Beziehungen zueinan- der, organisiert sein, sondern auch intrinsisch durch die Bedeutung in Form von Hyponymie, Co-Hyponymie, Fast-Synonymie und Antonymie (Szubko-Sitarek 2015: 41). Nach demParasitic Model of Vocabulary Developmentvon Hall (2002) werden neue Repräsentationen im mentalen Lexikon mittels bereits bestehenden in eine Art Netzwerk integriert. Dies geschieht dort, wo es orthografische, aus- sprachliche oder bedeutungsmäßige Ähnlichkeiten zwischen Wörtern gibt. Mit Halls Modell lässt sich somit angeben, wo Wörter in existierende lexikalische Netzwerke integriert werden. Nach den Regeln des Modells erfolgt die Integration
so schnell und so unkompliziert wie möglich. Ferner zeigt das Modell, dass die Integration von Wissen in bereits bestehendes essenziell für die Entwicklung von konzeptuellen Beziehungen und Netzwerken und für die Organisation und die Erweiterung des mentalen Lexikons ist (vgl. Hall et al., 2009). Hall vermutet darüber hinaus, dass es bei Lernenden, die mit neuen Spracheinheiten kon- frontiert werden, die Aufgabe des mentalen Lexikons ist, damit umzugehen.
Dabei ist egal, welche der Sprachen (L1 oder der L2) dafür benutzt wird (ebd.). Die zentrale Aufgabe des Sprachenlernens im Gehirn ist es demzufolge, den Formen Bedeutungen zuzuweisen und Bedeutungen Formen. Hierfür werden beliebig viele und alle möglichen linguistischen Ressourcen verwendet (ebd.). Herwig argumentiert hierzu, dass die Entscheidung darüber, welche Sprache für die Ver- arbeitung des Inputs herangezogen wird, abhängig davon ist, wie diewahrgenom- mene – nicht die tatsächliche – linguistische Distanz zur Referenzsprache ist, welche Fertigkeiten der/die Lernende hat und welche Methode zum Erwerb benutzt wird (vgl. Herwig 2001). Hoshino und Kroll (2008) wollten in einer Studie die Frage beantworten, ob zwischensprachliche Aktivierung bei bilingualen Spre- chern stattfindet, wenn die Schriftsysteme beider Sprachen sich voneinander unterscheiden, das geschriebene Wort allerdings nicht präsent ist. Untersucht wurden zwei Gruppen bilingualer Sprecher/-innen, einerseits Spanisch/Englisch- und andererseits Japanisch/Englisch-Bilinguale. Die Ergebnisse der Studie zei- gen, dass in einer Sprechsituation, in der nur eine Sprache verwendet wird, bei bilingualen Sprechenden auch die Phonologie der Nicht-Zielsprache aktiviert wird, selbst dann, wenn beide Sprachen unterschiedliche Schriftsysteme verwen- den. Sie gehen daher davon aus, dass die Schreibung nicht als ein abstraktes Sprachsignal für eine bestimmte Sprache wirkt und deshalb beide Sprachen aktiviert werden (Hoshino/Kroll 2008: 507). Genauer: In der Untersuchung soll- ten Bilder auf Englisch benannt werden, wobei das Gesprochene aufgenommen wurde. Da die hier untersuchte Fremdsprache (Spanisch) eine Alphabetsprache ist, Japanisch aber Logografe und Silbenzeichen benutzt, wurde angenommen, dass dies eine Auswirkung auf die Leistung der Probanden hat, was allerdings widerlegt wurde. Nach Meinung der Autorinnen spricht das Ergebnis gegen eine Einflussnahme der Orthografie auf die Sprachplanung, wenn sie nicht präsent ist.
Die Orthografie nimmt daher wohl nur Einfluss in Situationen, in denen das geschriebene Wort präsent ist (ebd.: 509).
1.3 Anmerkung zum Entlehnungsprozess im Japanischen
Generell kann gesagt werden, dass Wörter, wenn sie aus anderen Sprachen in die heimische Sprache integriert werden, zwangsläufig an das eigene Sprachsystem
angepasst werden müssen. Im Deutschen geschieht die Anpassung, indem z. B.
alle Nomen einen Artikel bekommen und die Verben für gewöhnlich die Endung –enerhalten. Im Japanischen ist eine Anpassung notwendig, um im heimischen Silbenalphabet wiedergegeben werden zu können. Das heißt genauer, dass ent- weder nach der Schrift – in der Mitte des letzten Jahrhunderts noch häufig – entlehnt wird oder dass ein Wort nach der Lautung–wie es aktuell häufiger zu beobachten ist– entlehnt wird. Das entlehnte Wort wird dann im heimischen Silbenalphabet geschrieben, was das Wort in eine Konsonant-Vokal-Kombination zwingt, was bedeutet, dass aufeinanderfolgende Konsonanten durch neu einge- fügte Vokale getrennt werden. Dies führt nicht nur dazu, dass Wörter schwer mit dem englischsprachigen Original in Verbindung zu bringen sind, sondern auch, dass sie von Japanern und Japanerinnen auch nicht als englische Lehnwörter, sondern als sog.Neujapanischangesehen werden (vgl. Stanlaw 2004). Dies könn- te zusammen mit den Bedeutungsunterschieden, die Olah angesprochen hat, zu Schwierigkeiten bei der Form-Bedeutungs-Zuordnung von Lehnwörtern führen.
2 Studie
2.1 Probanden und Probandinnen
Die Daten aus der Studie stammen aus zwei Befragungsrunden, die im Sommer- semester 2015 – zum Studienbeginn in Japan – an zwei Universitäten in der Region Tokio und Umgebung ermittelt wurden. Die Daten wurden zu zwei unter- schiedlichen Zeitpunkten erhoben, einmal zu Semesterbeginn und einmal zum Semesterende in der vorletzten Woche desselben Semesters.
Die Reihenfolge der Gruppen in dieser Arbeit erfolgt nicht chronologisch, sondern nach zu erwartendem Vorwissen. Dazu kann Folgendes festgehalten werden:
Gruppe 1 (43 japanische Teilnehmende): Studienanfänger und -anfängerin- nen mit Vorwissen aus sechs Jahren Schulunterricht Englisch und ohne Vor- wissen im Deutschen.
Gruppe 2 (62 japanische Teilnehmende): Studienanfänger und -anfängerin- nen mit Vorwissen aus dem Schulenglischen (sechs Jahre) und Deutschkennt- nissen, die sie innerhalb eines kompletten Semesters an der Universität erworben haben. Die Gruppe hat mit dem Lehrwerk Schritte International 1 (A1/1) vom Hueber Verlag gelernt und den darin enthaltenen Lernstoff komplett durch- genommen.
Gruppe 3 (30 japanische Teilnehmende): Studenten mit Vorwissen im Schul- englischen und Deutschen. Das Deutschwissen wurde aber nicht an der Univer-
sität erworben. Zumeist haben diese Teilnehmenden eine Zeit lang in Deutsch- land gelebt und Deutsch gelernt. Die Ergebnisse dieser Gruppe beim Eignungstest der Universität waren allerdings nicht gut genug, um in die Fortgeschrittenen- gruppe eingestuft zu werden, sodass sie zusammen mit den Anfängern lernen.
Exkludiert wurden die Daten der Studierenden, die mehr Sprachen als nur Japa- nisch, Englisch und Deutsch gelernt haben. Aus Gründen der Vergleichbarkeit, insbesondere da Interferenzen aus anderen als den untersuchten Sprachen aus- geschlossen werden sollten, wurden die Ergebnisse dieser Probanden und Pro- bandinnen nicht ausgewertet.
Das Ziel der Durchführung war die Überprüfung, ob unterschiedliche Deutschkenntnisse und -erfahrungen einen Einfluss auf die Erkennung von neu- em Vokabular haben.
2.2 Wortschatz
In der Studie wird ein Wortschatz von vier Sets à 11 Elementen überprüft. Erst nach der ersten Durchführungsrunde ist aufgefallen, dass das Element Haus sowohl in Set 1 als auch in Set 2 vorkommt, sodass sich eine Gesamtanzahl von 43 Items ergibt. Aufgrund der Wortdopplung wäre es möglich, dass die Erkennungs- werte dieses Elements in beiden Aufgaben gleich sind. Allerdings muss dies nicht zwingend so sein, da die Aufgabenstellung und der jeweilige Input beider Auf- gaben unterschiedlich sind. In einzelnen Aufgaben wird außerdem zwischen Wörtern lateinischen (Set 2 und 3) und nichtlateinischen Ursprungs (Set 1 und 4) unterschieden.
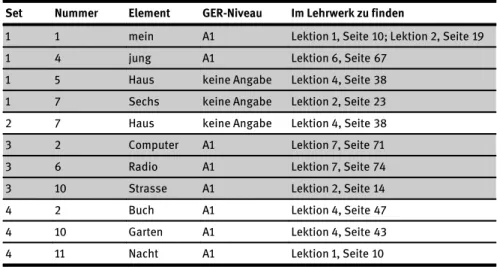
Des Weiteren wurden die in der Studie benutzten Elemente daraufhin unter- sucht, ob sie den Probanden und Probandinnen bekannt sein könnten. Da Gruppe 1 noch nicht Deutsch gelernt hat, wird angenommen–Gesetz der Arbeitsweise des mentalen Lexikons–, dass Teilnehmende dieser Gruppe die Wörter aus den Sprachen Japanisch bzw. Englisch herleiten. Bei Personen der Gruppe 2 kann aufgrund des unspezifischen Vorwissens nicht genau bestimmt werden, welches Vokabular bekannt ist, daher ist bei dieser Gruppe Vorwissen aus dem Deutschen tendenziell bei jedem Element möglich. Da Personen der Gruppe 2 den Wort- schatz des LehrwerkesSchritte International 1 (A1/1)gelernt hatten, wurde unter- sucht, ob die Elemente der Umfrage auf dem Referenzrahmen-Niveau A1 einge- ordnet werden und ob diese im Lehrwerk vorhanden sind. Nach der Überprüfung aller im Lehrwerk vorhandenen Elemente ergab sich folgende Übersicht:
Tabelle 1:Tendenziell bekanntes Vokabular für Gruppe 2
Set Nummer Element GER-Niveau Im Lehrwerk zu finden
1 1 mein A1 Lektion 1, Seite 10; Lektion 2, Seite 19
1 4 jung A1 Lektion 6, Seite 67
1 5 Haus keine Angabe Lektion 4, Seite 38
1 7 Sechs keine Angabe Lektion 2, Seite 23
2 7 Haus keine Angabe Lektion 4, Seite 38
3 2 Computer A1 Lektion 7, Seite 71
3 6 Radio A1 Lektion 7, Seite 74
3 10 Strasse A1 Lektion 2, Seite 14
4 2 Buch A1 Lektion 4, Seite 47
4 10 Garten A1 Lektion 4, Seite 43
4 11 Nacht A1 Lektion 1, Seite 10
Alle 43 Elemente wurden außerdem auf dieLevenshtein-Distanz(folgendEditier- distanzgenannt) hin untersucht. Die Editierdistanz ist die Anzahl von Schritten des Einfügens, Ersetzens oder Löschens von Zeichen eines Wortes, die man benötigt, um ein zweites Wort zu erhalten. Auf diese Art erhält man eine Methode, um die Nähe bzw. Distanz zweier Wörter zu berechnen. Für diese Arbeit wurde angenommen, dass die Distanz klein ist, wenn der Wert maximal die Anzahl der Hälfte aller Buchstaben des Wortes beträgt (z. B.: zwischen dt.
meinund engl.mind;die Distanz beträgt hier 2 (von 4 Buchstaben)), die Distanz wird als groß angenommen, wenn der Wert mindestens einen Buchstaben über die Hälfte aller Buchstaben eines Wortes beträgt (z. B.: zwischen dt. mein und engl.mild; die Distanz beträgt hier 3 (von 4 Buchstaben)). Die Großschreibung von Nomen im Deutschen wurde bei diesen Analysen nicht berücksichtigt, da dies die Ergebnisse verfälscht hätte, bedingt durch die Großschreibung im Deutschen und die Kleinschreibung im Englischen bzw. die im lateinischen Alphabet wiedergegebenen nichtkapitalisierten Transkriptionen des Japani- schen. Hierin unterscheidet sich diese Studie von der von Chen (Chen: 369) darin, dass Chen den Probanden. Vorinformationen gegeben hat, die ihnen etwa die Kapitalgroßschreibung u.a. erklären. Da die Probanden in dieser Studie möglichst ohne jegliches Vorwissen getestet werden sollten, ist hier anders vorgegangen worden
Bei den Aufgaben ist auch immer die Möglichkeit gegeben,ich weiß es nicht (jap.分かりません) anzukreuzen, da kein Entscheidungszwang zwischen Items vorgegeben werden sollte, sondern auch die Option, sich für keines der Items zu
entscheiden. Dazu gibt es eine weitere Seite, die die Einstellung der Teilnehmen- den zum Fragebogen erfragt.
Obwohl Testläufe durchgeführt wurden und es hierbei keine Verständnispro- bleme gab, wurden Aufgaben teilweise nicht korrekt ausgefüllt. Dies betraf al- lerdings nur einzelne Aufgaben, niemand hatte den Fragebogen komplett falsch ausgefüllt. Da dies nur in Einzelfällen vorkam und aus Gründen der Vergleich- barkeit wurde das Aufgabendesign nicht verändert.
Zu den Aufgaben im Einzelnen:
Die Aufgabe im Set 1 war, das korrekte englische Äquivalent zu einem gehörten und gelesenen deutschen Wort zu finden (Abbildung 2). Die deutschen Wörter sind orthografisch und/oder phonetisch manchmal ähnlicher zum englischen Kognat, manchmal weniger ähnlich. Da die Initialgroßschreibung im Deutschen keine Hin- weise liefern sollte, wurde alle Nomen in den Sets 1 und 2 klein geschrieben.
Abbildung 2:Aufgabenbeispiel Set 1
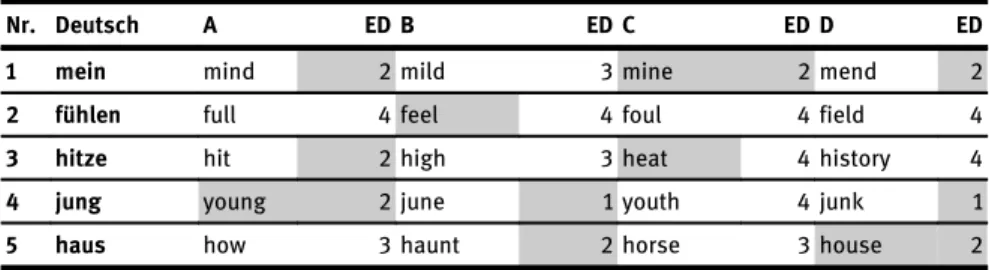
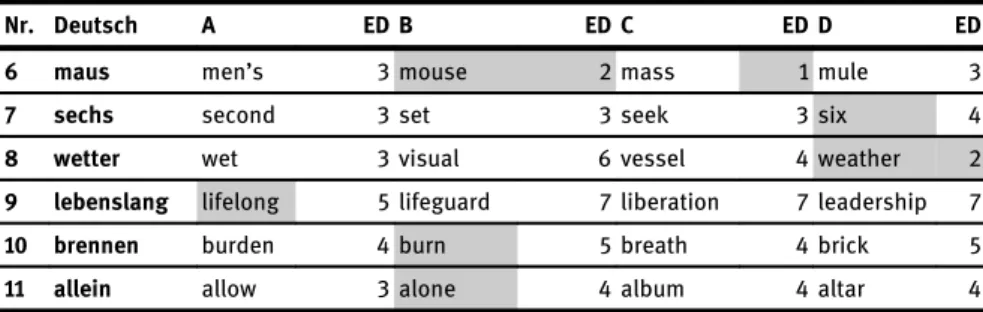
Im Folgenden werden die Einheiten der Aufgabe 1 angegeben. Die korrekten Lösungswörter sind in der Darstellung grau hinterlegt, die niedrigsten Werte der jeweiligen Editierdistanzen (ED) zu einem Zielwort sind ebenfalls grau hinterlegt.
Die Editierdistanzen der Antwortmöglichkeiten (A–D) lassen sich der Tabelle 2 entnehmen. Wie zu erkennen ist, treten verschiedene Kombinationen von nied- riger Distanz und Lösungswort bzw. Distraktoren auf, was bedeutet, dass nicht immer das Lösungswort auch das Wort mit der geringsten Distanz ist. Nun könnte angenommen werden, dass von den Teilnehmenden jene Wörter mit geringster Distanz ausgewählt werden. Da die Wörter von den Teilnehmenden aber auch gehört wurden, erscheint die Editierdistanz bei dieser Aufgabe nicht als alleinig ausschlaggebendes Kriterium.
Tabelle 2:Editierdistanzen von Set 1
Nr. Deutsch A ED B ED C ED D ED
1 mein mind 2 mild 3 mine 2 mend 2
2 fühlen full 4 feel 4 foul 4 field 4
3 hitze hit 2 high 3 heat 4 history 4
4 jung young 2 june 1 youth 4 junk 1
5 haus how 3 haunt 2 horse 3 house 2
Nr. Deutsch A ED B ED C ED D ED
6 maus men’s 3 mouse 2 mass 1 mule 3
7 sechs second 3 set 3 seek 3 six 4
8 wetter wet 3 visual 6 vessel 4 weather 2
9 lebenslang lifelong 5 lifeguard 7 liberation 7 leadership 7
10 brennen burden 4 burn 5 breath 4 brick 5
11 allein allow 3 alone 4 album 4 altar 4
Da die Wörter dieser Aufgabe vorgelesen wurden, hat einerseits die Aussprache des deutschen Wortes, andererseits das von den Teilnehmenden gespeicherte Klangbild der englischen Wörter ebenfalls einen Einfluss auf die Wahrnehmung und Lösungsauswahl. Die Berücksichtigung der Perzeption würde allerdings den Rahmen dieser Arbeit sprengen.
Bezüglich der Erkennungsergebnisse (Tabelle 2) kann gesagt werden, dass generell die ähnlichen Wörter besser erkannt wurden als die, deren deutsche Schreibung und Lautung von der englischen abweicht. Oft erkannt (Erkennungs- rate über einem Wert von 0,8) wurden von allen Gruppen die Wörtermein,jung, haus, mausund sechs. Weniger oft erkannt (Erkennungsrate unter einem Wert von 0,5) wurden von allen Gruppen die Wörterhitze, lebenslang, brennen. In dieser Aufgabe war, bis auf die Ausnahme mein, allgemein die Erkennung in Gruppe 3 am größten, was auch durch das arithmetische Mittel bestätigt werden kann. Die Elemente mit den geringsten arithmetischen Mitteln waren 2, 3, 9 und 10. Für die Elemente 3 und 10 gilt, dass die Editierdistanz im Vergleich zu den anderen Auswahlmöglichkeiten relativ hoch ist. Bei Element 2 ist sie bei allen Elementen gleich hoch, bei Element 9 ist sie im Vergleich zu den anderen Aus- wahlmöglichkeiten sogar am niedrigsten.
Tabelle 3:Auswertung Set 1
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
1 mein 0,91 0,98 0,93 0,94
2 fühlen 0,44 0,42 0,57 0,48
3 hitze 0,07 0,08 0,20 0,12
4 jung 0,88 0,81 0,97 0,89
5 haus 0,93 0,95 1,00 0,96
6 maus 0,93 0,94 0,97 0,94
Tabelle 2:(fortgesetzt)
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
7 sechs 0,88 0,91 1,00 0,93
8 wetter 0,60 0,72 0,73 0,69
9 lebenslang 0,47 0,27 0,50 0,41
10 brennen 0,21 0,06 0,27 0,18
11 allein 0,63 0,45 0,87 0,65
arithmetisches Mittel 0,63 0,60 0,73
Beim Set 2 war die Aufgabe, zu einem vorgegebenen englischen Wort das deut- sche Äquivalent in einem vorgelesenen deutschen Text herauszufinden und zu markieren (Beispiel siehe Abbildung 3). Der Text wurde zum Mitlesen ebenfalls dargestellt, allerdings war dessen Schwierigkeit so gewählt, dass zwar einzelne Wörter erkannt werden konnten, nicht aber der Satzinhalt. Die Texte sind authen- tisch und wurden aus dem DWDS entnommen (das digitale Wörterbuch der deutschen Sprache: http://www.dwds.de/).
Abbildung 3:Aufgabenbeispiel Set 2
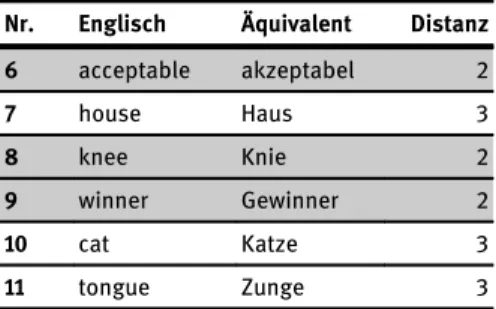
Im Hinblick auf die Editierdistanz der korrekten Elemente dieser Aufgabe ergeben sich sechs Elemente mit niedriger Distanz und fünf mit hoher Distanz. Beachtet man die Editierdistanzen, so sollten 1, 2, 3, 6, 8 und 9 gut erkannt werden, wohin- gegen die anderen Elemente weniger oft erkannt werden sollten (siehe Tabelle 4).
Tabelle 4:Editierdistanzen von Set 2
Nr. Englisch Äquivalent Distanz
1 abstract abstrakten 1
2 creative kreativ 2
3 result Resultat 3
4 clinic Kliniken 4
5 complicated kompliziert 6
Tabelle 3:(fortgesetzt)
Nr. Englisch Äquivalent Distanz
6 acceptable akzeptabel 2
7 house Haus 3
8 knee Knie 2
9 winner Gewinner 2
10 cat Katze 3
11 tongue Zunge 3
Hohe Erkennungsraten gab es bei 9 von 11 Wörtern, allerdings nicht bei allen Gruppen gleichmäßig. Gruppe 2 erkanntecreativewesentlich seltener (etwa um 0,12 Punkte) als die anderen zwei Gruppen. Hingegen wurde in dieser Gruppecat öfter erkannt als in den Vergleichsgruppen (ebenfalls um 0,12 Punkte).Tongue wurde als englisches Äquivalent zu Zunge generell weniger oft erkannt, bei Gruppe 1 kommt es sogar nur zu einem Wert von 0,18 Punkten korrekter Erken- nung. Alle Elemente mit geringer Editierdistanz hingegen wurden auch von den Teilnehmenden oft erkannt. Das Element mit der höchsten Distanz (complica- ted : kompliziert)wurde mit einem arithmetischen Mittel von 0,91 Punkten den- noch durchgehend sehr oft erkannt. Die Gruppe mit den meisten korrekten Ant- worten war Gruppe 3 mit einem arithmetischen Mittel von 0,88 Punkten.
Tabelle 5:Auswertung Set 2
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
1 abstract 0,91 0,89 0,93 0,91
2 creative 0,91 0,78 0,93 0,87
3 result 0,84 0,88 0,97 0,89
4 clinic 0,86 0,84 0,93 0,88
5 complicated 0,91 0,88 1,00 0,93
6 acceptable 0,91 0,89 0,93 0,91
7 house 0,95 0,94 0,93 0,94
8 knee 0,91 0,89 0,97 0,92
9 winner 0,72 0,81 0,93 0,82
10 cat 0,70 0,92 0,70 0,77
11 tongue 0,19 0,36 0,43 0,33
arithmetisches Mittel 0,80 0,83 0,88
Tabelle 4:(fortgesetzt)
Beim Set 3 sollten die Teilnehmenden deutsche Wörter einem japanischen Äqui- valent zuordnen (Abbildung 4). Diese Wörter sind Lehnwörter, bei denen davon ausgegangen werden kann, dass sie über das Englische ins Japanische gekom- men sind. Die deutschen Wörter wurden in einem Extrakasten angegeben, soll- ten passend ausgewählt und in Spalte 1 geschrieben werden, danach sollte das passende englische Wort–soweit bekannt–in Spalte 2 geschrieben werden. Zu jedem deutschen Wort wurde je ein Distraktor hinzugefügt.
Abbildung 4:Aufgabenbeispiel Set 3
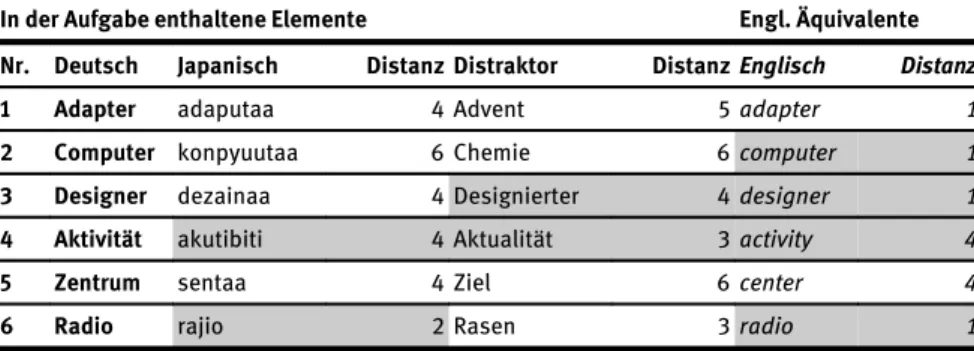
Bei diesem Set habe ich zur Bestimmung der Editierdistanzen das im Beispielsatz vorgegebene japanische Wort in lateinische Buchstaben transkribiert, um sie mit den Editierdistanzen der anderen Wörter vergleichen zu können. Die Transkripti- on folgt nach dem Hepburn-System. Lange Vokale wurden doppelt wiederge- geben. Danach wurden die Distanzen der Distraktoren berechnet. Da Interferen- zen aus dem Englischen möglich sind, wurden die englischen Äquivalente in der Auswertung ebenfalls angegeben und deren Editierdistanzen berechnet. Die An- zahl von Elementen mit geringer Distanz im Japanischen beläuft sich auf fünf, die Anzahl bei den Distraktoren liegt sogar nur bei vier, die Anzahl bei den eng- lischen Äquivalenten– die in der Aufgabe zwar nicht vorhanden waren, aller- dings durch Interferenzen die Entscheidungen beeinflussen könnten–beträgt 10.
Auffällig ist, dass die japanischen Lehnwörter höhere Editierdistanzen aufweisen als die englischen Äquivalente. Von den Distraktoren haben Aktualität, Taktik undStrategieeine geringe Distanz, was dazu führen könnte, dass diese öfter als passend gewählt wurden als die korrekten deutschen Äquivalente.
Tabelle 6:Editierdistanzen Set 3
In der Aufgabe enthaltene Elemente Engl. Äquivalente
Nr. Deutsch Japanisch Distanz Distraktor DistanzEnglisch Distanz
1 Adapter adaputaa 4 Advent 5adapter 1
2 Computer konpyuutaa 6 Chemie 6computer 1
3 Designer dezainaa 4 Designierter 4designer 1
4 Aktivität akutibiti 4 Aktualität 3activity 4
5 Zentrum sentaa 4 Ziel 6center 4
6 Radio rajio 2 Rasen 3radio 1
In der Aufgabe enthaltene Elemente Engl. Äquivalente Nr. Deutsch Japanisch Distanz Distraktor DistanzEnglisch Distanz
1 Adapter adaputaa 4 Advent 5adapter 1
7 Taxi takushii 6 Taktik 3taxi 1
8 negativ negatibu 2 negieren 5negative 1
9 magisch majikku 4 mager 4magic 2
10 Strasse sutoriito 7 Strategie 4street 3
11 Identität aidentitii 4 Idealismus 6identity 3
Oft erkannt wurden die Elemente 1, 2, 4, 9, 10 und 11. Relativ selten erkannt wurde Designer; bei dieser Aufgabe ist das Ergebnis der Gruppe 3 am besten, fällt aller- dings nur etwas geringer aus als das der Gruppe 2. Diese Teilnehmenden, also die Lernenden am Ende des ersten Semesters ohne Deutschkenntnisse, zeigten sich bei der Erkennung einiger Wörter als schwächste Gruppe (Adapter,Designer,negativ, Strasse, Identität), bei anderen Wörtern allerdings auch wiederum als stärkste Gruppe: BeiTaxiwar die Erkennung um bis zu 0,16 Punkte besser. Bei diesem Set lassen sich keine eindeutigen Zusammenhänge zwischen Editierdistanz und gewählten Antworten ziehen. Sicher scheinen jedoch zwei Fakten zu sein: Erstens scheinen die geringen Distanzen zwischen dem englischen Original und dem ja- panischen Lehnwort keinen Einfluss auf die Entscheidungen gehabt zu haben.
Wäre dem so, so hätten die Antworten bei den Elementen 3, 6, 7 und 8 in größerem Umfang korrekt sein müssen. Zweitens können die japanischen Lehnwörter hier in einigen Fällen für die Antworten ausschlaggebend gewesen sein. Die Editierdistan- zen der Distraktoren sind bei den Elementen 3 und 7 geringer als die der japanischen Wörter zum deutschen Wort. Hingegen lässt sich dieser Rückschluss nicht ziehen, was die Elemente 5, 6 und 8 betrifft, wo das Verhältnis umgekehrt ist, die Erkennun- gen mit 0,6, 0,72 und 0,70 Punkten jedoch nicht außerordentlich hoch waren.
Das höchste arithmetische Mittel bei dieser Aufgabe ergibt sich bei Gruppe 3.
Tabelle 7:Auswertung Set 3
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
1 Adapter 0,81 0,78 0,83 0,81
2 Computer 0,81 0,84 0,80 0,82
3 Designer 0,44 0,41 0,57 0,47
4 Aktivität 0,81 0,84 0,90 0,85
Tabelle 6:(fortgesetzt)
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
5 Zentrum 0,53 0,61 0,67 0,60
6 Radio 0,72 0,78 0,67 0,72
7 Taxi 0,51 0,69 0,53 0,58
8 negativ 0,70 0,66 0,73 0,70
9 magisch 0,77 0,84 0,90 0,84
10 Strasse 0,86 0,84 0,90 0,87
11 Identität 0,86 0,80 0,83 0,83
arithmetisches Mittel 0,71 0,74 0,76
Im folgenden Set war die Aufgabenstellung identisch zu der in Set 3, der Unter- schied lag lediglich in der Herkunft der Wörter–wobei ich aufgrund meiner Lehr- und persönlichen Erfahrung davon ausgehe, dass die Lernenden sich dessen nicht bewusst sind. In Set 4 wurden Wörter abgefragt, die keinen lateinischen Ursprung haben.
Abbildung 5:Aufgabenbeispiel Set 4
Die Editierdistanzen bei Set 4 sind im Japanischen dreimal geringer, bei den deutschen Distraktoren fünfmal und bei den englischen Äquivalenten achtmal.
Insgesamt sind die Distanzen also bei den japanischen Elementen am größten, gefolgt von den Elementen der Distraktoren und schließlich von den englischen Äquivalenten. Schaut man auf die Distraktoren, so könnten die geringen Editier- distanzen oft zu falschen Antworten führen. Wird ein Einfluss des Englischen berücksichtigt, so können diese Daten in acht von elf Fällen zu einer korrekten Antwort führen.
Tabelle 8:Editierdistanzen von Set 4
In der Aufgabe enthaltene Elemente Engl. Äquivalente
Nr. Deutsch Japanisch Distanz Distraktor DistanzEnglisch Distanz
1 Party paatii 3 Partikel 4party 1
Tabelle 7:(fortgesetzt)
In der Aufgabe enthaltene Elemente Engl. Äquivalente Nr. Deutsch Japanisch Distanz Distraktor DistanzEnglisch Distanz
2 Blaubeere buruuberii 6 Blaukraut 5blueberry 5
3 Kuss kisu 2 Kiste 3kiss 2
4 Herz haato 4 Haut 3heart 3
5 Partner paatonaa 5 Partizip 3partner 1
6 Leiter riidaa 4 Liter 1leader 3
7 Zirkus saakasu 5 Zirkel 2circus 2
8 Eis aisu 2 Eisen 2ice 3
9 Buch bukku 4 Bauer 3book 4
10 Garten gaaden 2 Gärtner 3garden 2
11 Nacht naito 3 Name 3night 3
Eine durchweg gute Erkennung gab es bei dieser Aufgabe bei den Elementen 2, 7, 8, 9, 10 und 11.Leiterwurde durchschnittlich nur selten erkannt. Selten korrekt erkannt wurden die Elemente 1, 4 und insbesondere 6 mit nur 0,39 Punkten. Ein Zusammenhang mit den Editierdistanzen lässt sich jedoch nur bei den Elemen- ten 4 und 6 erschließen, da die Distraktoren hier eine niedrigere Distanz haben.
Auffällig ist, dass die Editierdistanz des Distraktors beim Element 6 im Vergleich zum japanischen und englischen Äquivalent sehr gering ist, was ein Grund dafür sein kann, dass hier oft der Distraktor als korrekt gewählt wurde. Die Gruppen 2 und 3 waren bei dieser Aufgabe gleich stark mit 0,76 Punkten.
Tabelle 9:Auswertung Set 4
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
1 Party 0,51 0,78 0,60 0,63
2 Blaubeere 0,86 0,78 0,83 0,83
3 Kuss 0,60 0,78 0,70 0,70
4 Herz 0,40 0,53 0,60 0,51
5 Partner 0,53 0,77 0,83 0,71
6 Leiter 0,42 0,42 0,33 0,39
7 Zirkus 0,77 0,77 0,90 0,81
8 Eis 0,84 0,84 0,87 0,85
9 Buch 0,88 0,92 0,90 0,90
Tabelle 8:(fortgesetzt)
Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
10 Garten 0,81 0,88 0,87 0,85
11 Nacht 0,86 0,89 0,90 0,88
arithmetisches Mittel 0,68 0,76 0,76
Im letzten Teil des Fragebogens wurden u. a. noch vier Fragen zum Umgang mit deutsch-englisch-japanisch-ähnlichem Vokabular gestellt. Frage 1 war:Wie emp- finden Sie die Schwierigkeit der Aufgaben im Fragebogen?Die Antwortmöglichkeit war auf einer Skala von 1 bis 10 wählbar (1 = keine Schwierigkeit bis 10 = große Schwierigkeit). Durchschnittlich liegt die Mehrheit bei 7, wobei die Verteilung in den Gruppen leicht unterschiedlich ist. Die Mehrheit bei Gruppe 1 liegt bei 7, bei Gruppe 2, der Gruppe mit einem Semester Lernerfahrung in Deutsch, bei 8 und in der Gruppe 3, der Gruppe mit Deutsch-Vorerfahrung bei 6. Hier lässt sich kein Trend ablesen. Es lässt sich also nicht sagen, dass die empfundene Schwierig- keit beim Arbeiten mit ähnlichen Wörtern, bzw. mit Kognaten mit mehr Lern- erfahrung zu- oder abnimmt. Die Schwierigkeit wird von allen Gruppen als groß eingestuft.
Tabelle 10:Empfundene Schwierigkeit der Aufgaben
Item Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
ungültig 0,00 0,02 0,00 0,01
1 0,00 0,00 0,00 0,00
2 0,00 0,02 0,10 0,04
3 0,02 0,05 0,10 0,06
4 0,02 0,05 0,00 0,02
5 0,09 0,08 0,20 0,12
6 0,07 0,17 0,23 0,16
7 0,30 0,25 0,17 0,24
8 0,21 0,27 0,03 0,17
9 0,16 0,09 0,07 0,11
10 0,12 0,02 0,10 0,08
Die zweite Frage war:Was denken Sie, wie würde Ihnen die Berücksichtigung von ähnlichem deutsch-englisch-japanischen Vokabular beim Deutschlernen helfen?Bei
Tabelle 9:(fortgesetzt)
dieser Frage war die Antwortmöglichkeit auf einer Skala von 1 bis 10 wählbar (1
= große Hilfe bis 10 = keine Hilfe). Mehrheitlich wird die Hilfe von Kognaten beim Lernen im Fremdsprachenunterricht als sehr groß empfunden. Lediglich bei den Teilnehmenden ohne Deutschlernerfahrung liegt die Mehrheit auf dem Wert 2, bei den anderen beiden Gruppen auf dem Wert 1.
Tabelle 11:Empfundene Hilfe der Aufgaben
Hilfegrad Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
1 0,16 0,36 0,47 0,33
2 0,26 0,27 0,03 0,18
3 0,21 0,19 0,23 0,21
4 0,12 0,03 0,10 0,08
5 0,12 0,05 0,07 0,08
6 0,07 0,05 0,03 0,05
7 0,02 0,00 0,07 0,03
8 0,05 0,02 0,00 0,02
9 0,00 0,00 0,00 0,00
10 0,00 0,02 0,00 0,01
ungültig 0,00 0,03 0,00 0,01
Schließlich wurde noch gefragt, ob die Teilnehmenden einen Wortschatz ba- sierend auf deutsch-englisch-japanisch-ähnlichen Wörtern benutzen würden. In allen drei Gruppen lag der Ja-Wert bei 70 oder höher, am geringsten war er bei Gruppe 3.
Tabelle 12:Auswertung der empfundenen Hilfe von deutsch-englisch-japanischem Vokabular Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
ja 0,79 0,81 0,70 0,77
nein 0,05 0,16 0,03 0,08
egal 0,16 0,02 0,23 0,14
ungültig 0,00 0,02 0,03 0,02
Zuletzt wurde gefragt, wie die Lernenden einen Wortschatz dieser Art benut- zen wollen würden. Bei Gruppe 1 und 3 gaben jeweils mehr als die Hälfte der Teilnehmenden an, den Wortschatz im Unterricht benutzen zu wollen. Bei Grup-
pe 2 ist der Wert, den Wortschatz allein benutzen zu wollen, sehr hoch, da- durch liegt das höchste arithmetische Mittel aller Einheiten ebenfalls bei dieser Gruppe.
Tabelle 13:Auswertung nach gewünschtem Lernort für einen Wortschatz basierend auf Kognaten bzw. ähnliche Wörter
Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
im Unterricht 0,49 0,30 0,47 0,42
allein 0,42 0,66 0,37 0,48
beides 0,09 0,03 0,17 0,10
ungültig 0,00 0,02 0,00 0,01
Trotz der teilweise großen Unterschiede bei der Beantwortung einzelner Fragen unterscheiden sich die Daten der durchschnittlichen korrekten Antwort nicht sehr voneinander. Das arithmetische Mittel liegt bei 32,51 Punkten, hierbei liegt Grup- pe 3 im Vergleich zu den anderen Gruppen leicht vorn. Auffällig ist, dass Grup- pe 3 sich seltener dazu entschied, mitich weiß es nichtzu antworten.
Tabelle 14:Auswertung aller Antworten nach Korrektheit
Gruppe 1 Gruppe 2 Gruppe 3 arithmetisches Mittel
richtig 31,07 32,13 34,33 32,51
falsch 7,74 8,44 7,20 7,79
ich weiß es nicht 2,86 2,95 1,47 2,43
ungültig 4,77 2,84 4,20 3,94
2.3 Diskussion der Ergebnisse
2.3.1 Konkreta und Abstrakta
Eingangs, als die Arbeitsweise des mentalen Lexikons dargestellt wurde, ist erwähnt worden, dass De Groot et al. (1993) davon ausgehen, dass Konkreta schneller erlernt werden können als Abstrakta. Da diese Studie nicht untersucht, wie der Lernprozess von Wörtern verläuft, kann nur auf die Ergebnisse der Erkennungsraten eingegangen werden, nicht aber darauf, wie (schnell) diese erworben wurden.
In der Untersuchung wurden 30 Nomen verwendet, von diesen sind zwölf Abstrakta und 18 Konkreta. Gut erkannt (Erkennungsraten von über 0,79) wurden fünf Abstrakta und zwölf Konkreta, weniger gut bis schlecht erkannt (Erken- nungsraten von unter 0,80) wurden sieben Abstrakta und sechs Konkreta. Aus diesen Daten ergeben sich die folgenden arithmetischen Mittel: Abstrakta: 0,67 und Konkreta: 0,79 Punkte. Dies bedeutet, dass Konkreta mit 0,12 Punkten vor den Abstrakta liegen, und könnte ein Indikator dafür sein, dass Abstrakta nicht nur leichter erlernt, sondern–im Falle von Kognaten und ähnlichen Wörtern– auch leichter erkannt werden können.
2.3.2 Unterschiede zwischen Personen- und Wortgruppen
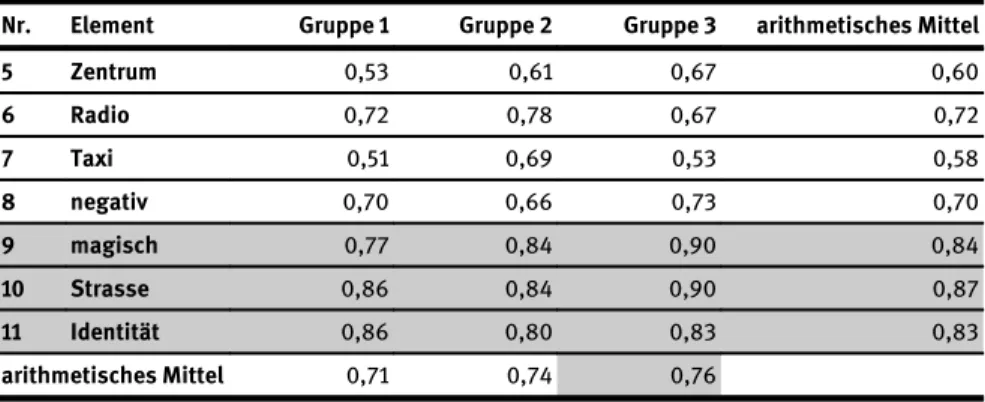
Die Gruppen wurden, wie eingangs erwähnt, nach ihren Deutschkenntnissen gereiht, Gruppe 1 hat keine Deutschkenntnisse, Gruppe 2 hat ein Semester lang Deutsch gelernt und Probanden und Probandinnen der Gruppe 3 haben bereits unbestimmte Deutscherfahrungen und teilweise Aufenthalte in deutschsprachi- gen Ländern hinter sich. Durchgängig haben die besten Ergebnisse die Teilneh- menden der Gruppe 3 erreicht. Im letzten Set allerdings haben Gruppe 2 und Gruppe 3 gleich viele Elemente korrekt zugeordnet (Tabelle 15).
Die Sets mit Wörtern nichtlateinischen Ursprungs (1 und 4) wurden zusam- mengenommen nicht so oft korrekt erkannt wie die Elemente lateinischen Ur- sprungs (1,49 zu 1,64 Punkten). Dieses Ergebnis kann als Indikator für das Trilingual Interative Anctivation Modelgelten und somit für die Aktivierung von Wortmerkmalen im mentalen Lexikon, da Kognaten lateinischen Ursprungs im Deutschen und Englischen generell geringere Editierdistanzen aufweisen als jene nichtlateinischer Herkunft. Die Ergebnisse sprechen dafür, dass Mehrsprachigkeit und Sprachwissen die Entscheidungen über Wörter und deren Erkennen beein- flussen. Insbesondere der Fakt, dass die Ergebnisse von Gruppe 1 und Gruppe 3– also den Gruppen mit keinem und mit Vorwissen im Deutschen–am weitesten auseinanderliegen, stützt diese These. Wie der Tabelle 15 entnommen werden kann, ist, wenn man das arithmetische Mittel aller Aufgaben nimmt, der Unter- schied zwischen den Gruppen nicht mehr allzu groß. Dies kann darauf hindeuten, dass bei den untersuchten Personen das Vorwissen nicht groß genug war, um einen größeren Unterschied auszumachen. Andererseits bedeutet dieses Ergebnis aber auch, dass durch Verknüpfungen von Wörtern des Japanischen, Englischen und Deutschen zur korrekten Lösungsfindung ein Minimum von 0,71 Punkten erreicht werden kann.
Tabelle 15:Arithmetische Mittel im Vergleich
Set Gruppe 1 Gruppe 2 Gruppe 3
1 0,63 0,60 0,73
2 0,80 0,83 0,88
3 0,71 0,74 0,76
4 0,68 0,76 0,76
Arithmet. Mittel Gesamt
0,71 0,73 0,78
Bei einzelnen Elementen kam es zu relativ hohen Schwankungen zwischen den Vergleichsgruppen, die im Folgenden kurz besprochen und zu denen Erklärungs- versuche gegeben werden sollen.
Im ersten Set wurdehitzerelativ selten erkannt mit Ausnahme von Gruppe 3.
In diesem Fall kann man annehmen, dass das Wort einigen der Probanden und Probandinnen dieser Gruppe bekannt gewesen sein muss und daher häufiger korrekt geantwortet wurde als in den anderen zwei Gruppen. Gruppe 2 hat dieses Wort noch nicht gelernt, und bei der ersten Gruppe lag die Verbindunghitze>heat nicht so nah wie zu dem Distraktor hitze>hit. Durch den Wortakzent auf dem ersten Vokal wäre auch denkbar, dass die im Deutschen unerfahrenen Lernenden das Wortende nicht mehr gehört haben. Ähnliche Beispiele, bei denen schlicht die fehlende Erfahrung mit dem Deutschen ausschlaggebend gewesen sein könn- te, sindwinner,tongueundHerz. Die Editierdistanz dieser drei Wörter ist lediglich beiHerzhoch, sodass diese nicht als hauptsächlicher Einflussfaktor gelten kann.
Gruppe 2 hatte bei den Elementenlebenslang,brennenundalleindie niedrigsten Erkennungswerte, aber beicatundTaxidie höchsten. Erklärungen hierfür kann ich nur im Bereich der natürlichen Schwankungen sehen, da keine Daten zur Verfügung stehen, die eine andere Erklärung dieser Phänomene liefern könnten.
Tabelle 16:Übersicht von Elementen mit relativ hohen Schwankungen
Set Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 Arithmet. Mittel
1 3hitze 0,07 0,08 0,20 0,12
1 9lebenslang 0,47 0,27 0,50 0,41
1 10brennen 0,21 0,06 0,27 0,18
1 11allein 0,63 0,45 0,87 0,65
2 9winner 0,72 0,81 0,93 0,77
2 10cat 0,70 0,92 0,70 0,77
Set Nr. Element Gruppe 1 Gruppe 2 Gruppe 3 Arithmet. Mittel
2 11tongue 0,19 0,36 0,43 0,33
3 7Taxi 0,51 0,69 0,53 0,58
4 4Herz 0,40 0,53 0,60 0,51
4 6Leiter 0,42 0,42 0,33 0,39
2.3.3 Bekanntheit und Unbekanntheit
Die Analysen aller Sets haben ergeben, dass nicht nur Elemente mit geringer Editierdistanz erkannt wurden–dies konnte Chen (2015: 375 ff.) in ihrer Studie mit taiwanesischen Studierenden auch belegen–sondern auch solche mit hoher Edi- tierdistanz gut erkannt werden konnten. In der Verarbeitung der Daten stellte sich also heraus, dass ein Einfluss der Editierdistanz von deutschen, englischen und japanischen Wörtern auf die Lösungsentscheidung nicht nachgewiesen werden konnte. Dies kann damit zusammenhängen, dass es sich um mehrsprachige Teil- nehmende handelt, sodass ein Zusammenwirken der Sprachen möglich ist, welche durch diese Untersuchung allerdings nicht nachgewiesen werden kann. Erschwe- rend kommt hinzu, dass die Editierdistanz von Wörtern aus Sprachen mit unter- schiedlichen Schriftzeichen nicht problemlos bestimmt werden kann, sodass sich unterschiedliche Distanzen ergeben, je nach benutzter Transkriptionsmethode.
Eingangs wurde erwähnt, dass Gruppe 2 zum Analysezeitpunkt ein Semester Deutsch gelernt hat, also schon über einen bestimmten Wortschatz verfügte und angenommen werden könnte, dass sie diesen besser erkennen könnten. Nach den Analysen der Umfrageelemente kann dies allerdings nicht bestätigt werden. Von den zehn bekannten Elementen weisen nur fünf einen höheren Antwortwert aus, dennoch sind generell bei allen drei Gruppen die korrekten Antworten bei allen diesen Elementen bis aufRadiorecht hoch (über 0,80).
Tabelle 17:Ergebnisse tendenziell bekannter Elemente der Gruppe 2 im Vergleich
Set Nummer Element Gruppe 1 Gruppe 2 Gruppe 3
1 1 mein 0,91 0,98 0,93
1 4 jung 0,88 0,81 0,97
1 5 haus 0,93 0,95 1,00
1 7 sechs 0,88 0,91 1,00
Tabelle 16:(fortgesetzt)
Set Nummer Element Gruppe 1 Gruppe 2 Gruppe 3
2 7 Haus 0,95 0,94 0,93
3 2 Computer 0,81 0,84 0,80
3 6 Radio 0,72 0,78 0,67
3 10 Strasse 0,86 0,84 0,90
4 2 Buch 0,88 0,92 0,90
4 10 Garten 0,81 0,88 0,87
4 11 Nacht 0,86 0,89 0,90
Trotz der Schwierigkeit der Aufgaben, also des Herstellens von Zusammenhängen von bekanntem und unbekanntem Vokabular, wird diese Art der Einführung neuer Lexik bzw. des Lernens neuer Wörter von den Probandinnen und Pro- banden als sehr hilfreich eingestuft.
2.3.4 Signifikanz der Ergebnisse
In dieser Untersuchung wurden die Fertigkeiten der japanischen Studienanfänger erforscht, im Hinblick auf bereits vorhandenes Wissen im Englischen und auf ihre Kombinationsfertigkeit im Umgang mit unbekanntem deutschem Vokabular. Die gewonnenen Daten zeigen, in welchem Umfang es den Befragten möglich ist, unbekanntes Vokabular selbständig zu erschließen. Sie haben lexikalisches und semantisches Wissen erworben, das sie im Fremdsprachenunterricht anwenden können und wollen. Auch wenn die Arbeit mit Kognaten als nicht einfach angege- ben wurde, wird von vielen dennoch ein Nutzen darin gesehen. Die gesamten arithmetischen Mittel aller Aufgaben liegen über einem Wert von 0,7 Punkten, was zeigt, dass etwa drei von vier Wörtern korrekt erkannt wurden. Dies wiede- rum zeigt ein großes Potenzial, dass Lernende Wörter, die ähnlich zu bereits bekanntem Vokabular sind, selbständig erarbeiten und verstehen können.
Darüber hinaus lassen sich die Ergebnisse auch auf Lehrende und den Deutschunterricht allgemein beziehen. Da die Lernenden sich eine Berücksichti- gung von Kognaten wünschen, scheint nach den Ergebnissen dieser Studie eine explizite Anwendung von Strategien zur Verbindung von Kognaten verschiedener Sprachen als folgerichtig und lernerorientiert. Insbesondere da die Lernenden das Arbeiten mit Kognaten als schwierig einstufen, können die Lehrenden ihnen bei diesem Prozess das Lernen erleichtern und unterstützend wirken, indem sie Strategien vermitteln und einen auf Kognaten basierenden Wortschatz in ihren
Tabelle 17:(fortgesetzt)
Unterricht einfließen lassen. Da das Material in dieser Umfrage nur aus ähn- lichem Vokabular bestand, im normalen Alltag der Lernenden aber auch völlig unbekannte Wörter vorkommen, ist eine Wortschatzarbeit durch die Lehrenden nötig, sodass die Lernenden erst angeleitet werden und schließlich mehr und mehr selbst Vokabular entdecken und erarbeiten können. In Gesprächen mit Deutschlehrer-Kollegen in Japan ist mir berichtet worden, dass Kognaten bzw.
Lehnwörter im Japanischen im Unterricht einbezogen werden und als Erklärungs- hilfe genutzt werden, insofern sie bekannt sind. Das Problem hierbei ist, dass den deutschsprachigen Lehrenden oft nicht bekannt ist, welches japanische Lehnwort es auch im Deutschen gibt, und die japanischen Lehrpersonen nicht wissen, welche Wörter es in welcher Form im Englischen gibt. Hier fehlt ein verbindendes Medium. Wie die Untersuchung gezeigt hat, haben die Studierenden durchaus Interesse an einem Material, das ihr Vorwissen aus dem Englischen und Japa- nischen berücksichtigt. Mehrfach wurde in der Kommentarzeile des Fragebogens z. B. angegeben, dass die Lernenden solch ein Material gern benutzen würden, weil sie meinten, es helfe ihnen beim Wortschatzlernen. Dass laut Umfrage der Umgang mit ähnlichem Vokabular bzw. mit Kognaten als schwierig angesehen wurde, liegt wohl auch entscheidend daran, dass die Probanden und Probandin- nen auf sich allein gestellt waren. Es ist davon auszugehen, dass unter Anleitung durch die Lehrkräfte der Umgang mit solchen Vokabeln als weniger schwierig empfunden werden würde.
Deutschlehrwerke, die in Japan eingesetzt werden, kommen entweder aus Deutschland oder aus Japan. Zu Ersteren gibt es Zusatzmaterial auf Japanisch, welches das deutsche Vokabular und die japanischen Übersetzungen sowie eini- ge Übungen dazu beinhaltet. Japanische Lehrwerke sind oft nicht so umfangreich wie deutsche, und explizite Erklärungen zur Wortschatzvermittlung und Gemein- samkeiten im Wortschatz gibt es meines Wissens nach derzeit nicht.
Diese Untersuchung wurde im Zusammenhang mit meinem Forschungspro- jekt zum Doktorat durchgeführt. Das Ziel des Doktorates ist es, einen Lernerwort- schatz von Deutsch als Fremd- oder Zweitsprache für japanische Lernanfänger zu entwickeln. Die Quellen des Wortschatzes liegen im englischen Vokabular, das japanische Studenten bereits in der Schulbildung erworben haben, und in Lehn- wörtern im Japanischen, die zumeist aus dem Englischen kommen. Die Daten dieser beiden Vokabulare werden verglichen und mit Entsprechungen im Deut- schen abgeglichen, sodass ein Wortschatz aus Kognaten und ähnlichen Wörtern entsteht, mit dem neue Wörter schneller erlernt werden können.
Die Untersuchungen, die in diesem Artikel präsentiert wurden, sollten ermit- teln, inwiefern die Lernenden in der Lage sind, ein solches Vokabular effektiv zu nutzen. Speziell war es die Absicht zu eruieren, wie gut es den Teilnehmenden möglich ist, Wortzusammenhänge eigenständig zu erschließen. Da es generell zu