Master Thesis
The Databank Model
Author(s):
Hublet, François Publication Date:
2021
Permanent Link:
https://doi.org/10.3929/ethz-b-000477329
Rights / License:
In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use.
ETH Library
Databank The Model
François Hublet von
Masterarbeit
vorgelegt zur Erlangung des Grades Master of Science ETH in Informatik
an der Eidgenössischen Technischen Hochschule Zürich Institut für Informationssicherheit
Betreuer Prof. Dr. David Basin Dr. Srđan Krstić
Bearbeitungszeitraum Sep. 2020 – März 2021
Eingereicht am 21.3.2021
1 Introduction 9
2 Monitoring preliminaries 13
2.1 Information flow monitoring . . . 13
2.1.1 Information flows and information flow channels . . . 14
2.1.2 Label-based information flow monitoring . . . 15
2.2 Runtime verification . . . 18
2.2.1 General concepts . . . 18
2.2.2 Metric First-Order Temporal Logic (MFOTL) . . . 20
2.2.3 MonPoly . . . 31
3 The Databank architecture 35 3.1 General presentation . . . 35
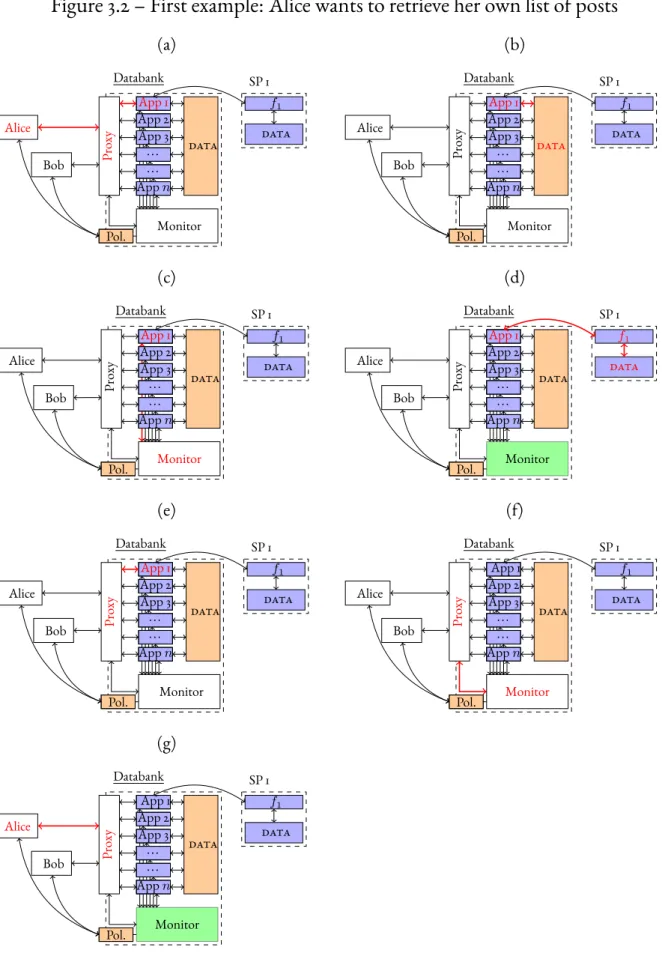
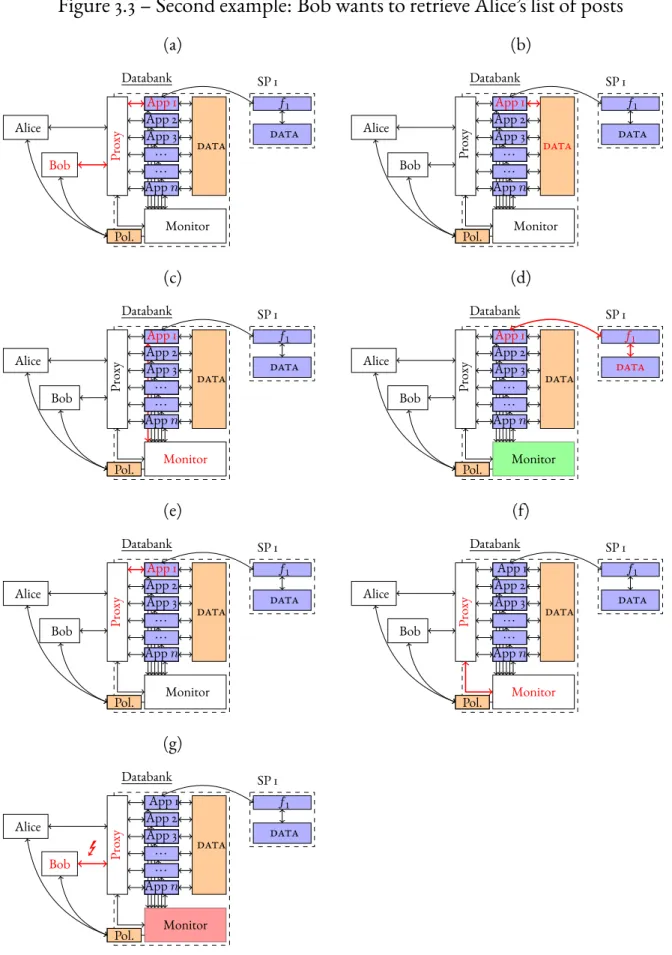
3.2 Two examples . . . 37
3.3 Threat model . . . 38
4 A model language for the Databank 43 4.1 Programming the Databank . . . 43
4.1.1 Introducing the Databank model language (Dmol) . . . . 43
4.1.2 Semantics of Dmol . . . 51
4.1.3 Finding memory locations affected by a statement: assigned 62 4.2 Running the Databank . . . 66
4.2.1 Program runs . . . 66
4.2.2 Memory equivalence . . . 69
4.2.3 Noninterference . . . 74
5 Adding monitoring support 89 5.1 Monitoring the Databank . . . 90
5.1.1 Modelling structured databases: depth-2 memory cells . . . 90
5.1.2 Monitoring signature . . . 90
5.1.3 Encoding traces, monitors and user knowledge . . . 92
5.2 Re-programming the Databank . . . 99
5.2.1 Definitions . . . 99
1
5.2.2 Semantics of Dmol’ . . . 102
5.3 Re-running the Databank . . . 109
5.3.1 Program runs . . . 109
5.3.2 Noninterference . . . 111
6 A monitoring backend for the Databank 123 6.1 Embedding traces and trace operations . . . 123
6.1.1 Traces . . . 124
6.1.2 Logging operations . . . 129
6.1.3 Requirements . . . 131
6.2 A labeled monitoring algorithm . . . 134
6.2.1 Global overview . . . 134
6.2.2 Table operations . . . 136
6.2.3 Correctness . . . 138
7 A Databank prototype 151 7.1 Choice of technologies and general structure . . . 151
7.1.1 Python, Flask, SQLite, OCaml, and more . . . 151
7.1.2 High-level overview . . . 153
7.2 Implementing Dmol’ . . . 164
7.2.1 Data structures . . . 164
7.2.2 Compiler . . . 166
7.3 Modifying MonPoly . . . 172
7.3.1 High-level overview . . . 172
7.3.2 Implementation . . . 174
8 Evaluating the Databank 177 8.1 Case study: an event management application . . . 177
8.1.1 Description of the application . . . 177
8.1.2 Implementation and design . . . 178
8.2 Performance evaluation . . . 181
8.2.1 Workloads and methodology . . . 181
8.2.2 Results . . . 183
8.3 Discussion . . . 185
9 Related works 189 9.1 Related architectures . . . 189
9.2 Information flow and runtime monitoring . . . 193
10 Conclusions and future work 197
Bibliography 199
In this thesis, we use the following notations:
• N = { 0, 1, . . . } denotes the set of natural numbers.
• N
∗= { 1, 2, . . . } denotes the set of positive natural numbers.
• For x ≤ y ∈ N, [[ x, y ]] denotes { x, x + 1, . . . , y } .
• For x ≤ y ∈ N, [[ x, y [[ denotes { x, x + 1, . . . , y − 1 }.
• I = {[[ x, y [[∣ x ∈ N , y ∈ N ∪ { ∞ } , y ≥ x } is the set of intervals over N.
• For I = [[ x, y ]] ∈ I and ∆ ∈ N, I − ∆ denotes
[[ max ( 0, x − ∆ ) , max ( 0, y − ∆ )]] .
• For n ∈ N and (possibly non-unique) elements a
1, . . . , a
n, the multiset con- taining a
1, . . . , a
nis denoted by { a
1, . . . , a
n}
#.
We refer to finite, partial maps A ⇀ B between two sets A and B as dictionaries.
For any sets A and B and dictionary d = { a
1↦ b
1, . . . , a
k↦ b
k} ∈ A ⇀ B , the set dom d = { a
1, . . . , a
k} is called domain or set of keys of d , while the set Im d = { b
1, . . . , b
k} is called image or set of values of d ; finally, ∣ d ∣ = k is the size of d . To state that dictionary d maps key k to value v , we write d [ k ] = v . The dictionary d
′obtained by adding a binding k ↦ v to a dictionary d (possibly overwriting a previous mapping k ↦ v
′in d ) is denoted by d
′= d [ k ↦ v ] . The dictionary d
′′obtained by removing a binding from k in d is denoted by d
′′= d \ { k }.
For any map f ∈ A ⇀ B between two sets A and B , for any C ⊆ A , f ∣
Cdenotes the restriction of f to C , i.e. f ∣
C∶ C ⇀ B, x ↦ f ( x ).
3
I am very grateful to Prof. Dr. David Basin for his giving me the unique opportunity to address this topic during the past six months. Coming with own ideas for a Mas- ter’s thesis proposal was probably something of a bold and unusual start. But Prof.
Basin believed in the potential of the idea, took the time to comment and discuss it with me, and eventually greatly contributed to transforming a very sketchy initial vision into a viable research project. Without his support, none of this would have been possible.
Ringrazio il dr. Srđan Krstić per la sua attenta supervisione durante gli ultimi sei mesi, tanto preziosa in questi tempi di telelavoro. Gli sono gratissimo per le nostre discussioni settimanali, i suoi utilissimi commenti su questo manoscritto, le innume- revoli e-mail sia in italiano che in inglese, nonché per la sua ormai leggendaria pazienza di fronte ai capricci del sistema operativo del mio portatile.
Many thanks also to all those who surrounded and supported me in the last six months: family, friends and colleagues from Zürich, Paris, Western France, Germany and all over Europe and beyond. Danke, merci, thank you, grazie, ¡gracias!, tack, and hope to see you all very soon in our good old analogous world!
5
Abstract
In this thesis, we design and implement the ‘Databank Model’, a new privacy- preserving web architecture for database-backed applications. The Databank Model aims at making the web more user-centric and safe by separating data storage from data processing functions. In this model, data storage and data policy enforcement are delegated to a trusted third party called the Databank, which serves as a proxy be- tween users and applications. Application developers deploy parts of their code which interact with user data directly to the Databank. This allows them to provide their service without retrieving user data. The Databank monitors code executed against its database and prevents violations of its users’ policies. The overall infrastructure pro- vides strong formal guarantees to users that their policies will be correctly enforced.
Through a novel combination of ideas from both information-flow monitor- ing and runtime verification, we design a realistic Python-like programming language called Dmol, tailored for the development of database-backed web applications. The Dmol’ language features both static and dynamic information flow propagation and uses an external monitoring backend to detect violations of users’ policies, specified in a fragment of Metric First-Order Temporal Logic (MFOTL), at runtime. Nonin- terference properties are proved for this language and user policies are shown to be correctly enforced in the resulting execution model. We implement a prototype of the Databank infrastructure in Python and OCaml with Dmol’ as a Databank-side programming language and assess the practicality of our approach in a case study.
Zusammenfassung
In dieser Arbeit wird das „Databank-Modell“, eine neue datenschutzorientier- te Webarchitektur für datenbankgestützte Anwendungen, entworfen und implemen- tiert. Mit dem Ziel, durch eine möglichst vollständige Trennung von Datenspeiche- rung und -verarbeitung das Web benutzerzentrierter und sicherer zu machen, wird in diesem Modell eine vertraute Drittorganisation, die Databank, mit Datenspeicherung und Datenschutzdurchsetzung betraut. Diese fungiert als Proxy zwischen Benutzern und Anwendungen. Entwickler stellen diejenigen Teile ihres Codes, die einen direk- ten Zugriff auf die Daten benötigen, auf den Servern der Databank bereit. Dadurch können Dienstleistungen angeboten werden, ohne dass die Daten die Databank ver- lassen. Die Databank überwacht diese Programme, um Vertöße gegen die von ihren Benutzern bestimmten Datenschutzregeln zu verhindern. Somit garantiert sie ihren Nutzern eine korrekte Umsetzung ihrer Datenschutzpräferenzen.
Durch eine neue Kombination von Ideen aus den Bereichen Informationsfluss- Monitoring und Runtime-Verifizierung entwerfen wir Dmol’, eine realistische, Py- thonähnliche, auf die Entwicklung datenbankgestützter Anwendungen zugeschnitte- ne Programmiersprache. Diese implementiert einen sowohl statistischen als auch dy- namischen Informationsflusspropagierungsmechanismus und verwendet zur Über- wachung von benutzerspezifischen Datenschutzvorschriften, die in metrischer Zeitlo- gik erster Stufe (MFOTL) spezifiziert werden, ein externes Monitoring-Backend. Wir beweisen Nichtinterferenz-Eigenschaften für diese Sprache sowie die Korrektheit der Datenschutzdurchsetzung im daraus resultierenden Ausführungsmodell. Ein Proto- typ der Databank-Infrastruktur mit Dmol’ als Databank-Sprache wird in Python und OCaml implementiert, und unser Ansatz anhand einer Fallstudie auf seine praktische Nutzbarkeit geprüft.
Résumé
Dans ce mémoire, on s’intéresse à la conception et à l’implémentation d’une nou- velle architecturewebgarantissant la protection des données personnelles, la «banque de données». Afin de remettre lewebau service des utilisateurs et de le rendre plus sûr, ce modèle sépare les fonctions de stockage et de traitement des données. La conserva- tion et la protection des données y sont déléguées à un tiers de confiance, la « banque de données», qui agit comme un proxy entre les utilisateurs et les applications. Les dé- veloppeurs déploient le code accédant aux données directement sur les serveurs de la banque, ce qui leur permet de fournir leur service sans extraire ces données. La banque surveille ensuite ce code pour empêcher toute violation des règles définies par les utili- sateurs. Le système fournit ainsi des garanties formelles aux utilisateurs en matière de protection des données.
Au travers une nouvelle combinaison de techniques de monitoring des flux d’in- formation et de vérification de trace, on décrit Dmol’, un langage de programma- tion réaliste proche de Python dont la sémantique intègre un mécanisme statique et dynamique de propagation des flux d’information. Dmol’ utilise un moniteur ex- terne pour détecter les violations des règles de protection des données spécifiées par ses utilisateurs dans un fragment de la logique métrique temporelle du premier ordre (MFOTL). On prouve des propriétés de non-interférence pour ce langage et on montre que le modèle d’exécution obtenu garantit l’application des règles formulées par les uti- lisateurs. Un prototype de l’infrastructure globale, utilisant Dmol’ comme langage des applications déployées dans la banque de données, est implémenté en Python et OCaml, et la practicité de l’approche adoptée est évaluée à l’aide d’une étude de cas.
Sommario
In questa tesi, disegniamo e implementiamo il “modello Databank”, una nuova infrastrutturawebper applicazioni basate su banche dati che garantisce la riservatezza dei dati. Attraverso l’implementazione di una rigorosa separazione funzionale tra sto- rage e trattamento dei dati, il modello Databank rende la rete più incentrata sull’utente e più sicura. In questo modello, il storage e l’applicazione delle privacy policies degli utenti vengono delegate a una terza parte fidata, la Databank, che funge da proxy tra utenti e applicazioni. Gli sviluppatori distribuiscono la parte del codice che interagi- sce con i dati direttamente sulla Databank. Così possono offrire il loro servizio senza estrarre i dati. Monitorando l’esecuzione di questo codice, la Databank garantisce che vengano rispettate le preferenze definite dagli utenti.
Combinando idee proveniente sia dal campo del information-flow monitoring che da quello della runtime verification, disegniamo Dmol’, un linguaggio di pro- grammazione realistico specialmente concepito per lo sviluppo di applicazioniwebba- sate su banche dati. Questo comporta un mecanismo di propagazione statica e dinami- ca dei flussi d’informazione e ricorre a un monitore esterno per controllare al runtime l’applicazione delle data policies degli utenti, specificate in un frammento della logica metrica temporale del primo ordine (MFOTL). Si dimostrano proprietà di noninter- ferenza per questo linguaggio, e si verifica che il modello di esecuzione applica corret- tamente le policies. Implementiamo un prototipo di questa infrastruttura in Python e OCaml con Dmol’ come linguaggio di programmazione delle applicazioni distribuite sulla Databank, e valutiamo la praticità dell’approccio adottato in uno studio di caso.
Recapitulaziun
En quella tesa concepin ed implementein nus il “model da Databank”, ina nova ar- chitectura per applicaziuns-web basadas sin bancas da datas che garantescha la protec- ziun dallas datas. Entras l’implementaziun dad ina separaziun stricta denter funcziuns dad arcunar e dad elavurar datas, effectuescha il model da Databank in web pli segir e pli drizzau ora sin utilisaders. L’arcunaziun da datas e l’execuziun dalla protecziun da datas davart ils utilisaders vegnan cun quella mira delegadas ad ina tiarza organisaziun fidada, la Databank. Ella agescha sco proxy denter utilisaders ed applicaziuns. Ils svi- luppaders distribueschan sin ils servers dalla Databank la part da lur code che tracta las datas dils utilisaders. Quei lubescha ad els da porscher lur survetsch senza stuer retrer las datas. La Databank survigilescha lu l’execuziun dil code e garantescha aschia che las preferenzas dils utilisaders vegnien respectadas.
Cumbinond ideas che provegnan schibein dil intschess dil monitoring dils curren- ts d’informaziun sco era da quel dalla verificaziun da runtime, concepin nus Dmol’, un lungatg da programmaziun realistic, concepiu specialmein per il svilup dad appli- caziuns-web basadas sin bancas da datas. Quel cumpeglia in mecanissem da propaga- ziun statica e dinamica dils currents d’informaziun e fa diever d’in monitur extern per constatar abus eventuals dallas reglas davart l’utilisaziun dallas datas. Quellas reglas vegnan fixadas dils utilisaders en in fragment dalla logica metrica temporala d’emprem grad (MFOTL). Ei vegn cumprovau proprietads da noninterferenza per quei lungatg e verificau che il model dad execuziun applicheschi correctamein las reglas. Nus imple- mentein in prototip dall’infrastructura da Databank en Python e OCaml cun Dmol’
sco lungatg dallas applicaziuns distribuidas silla Databank e valetein la praticabladad da nossa metoda entras il studi dad in cass concret.1
1Engraziel a Not Soliva per siu prezius sustegn linguistic!
Introduction
Today’s data economy is characterized by significant political and economic imbal- ances. In our digital world where a small number of oligopolies serve billions of semi-captive consumers, the dominant paradigm is to exchange user data for “free”
services. This makes many tech companies unwilling to consistently enforce more stringent data protection policies. Despite the awareness raised in recent years by the passing of important new legislation, among which the European Union’s Gen- eral Data Protection Regulation—GDPR, data ownership is still not properly and rigourously enforced. Instead, we are stuck in a state of “digital feudalism” [11] which we can hardly hope to escape without a thorough rethinking of our data ecosystem.
In fact, the current model of the data economy is both too open and too closed to provide actual data ownership. It is too open in that it makes it technically possible for firms collecting user data to use this data for whatever purposes they want, with only limited capacity for audit and control on the part of users and regulators. Some uses may, of course, be prohibited by law, but such infringements are in many cases hard to detect, let alone prevent. Other uses may be legal but happen de facto “behind the back” of users, who are not aware, or (given the average length and complexity of common terms of use) not even cognitively able to have consented to them. In general, duplication of data is not limited by purpose, and transfers to third parties, especially to the most powerful monopolies, are difficult to prevent.
At the same time, the current model is too closed, as it prevents users from man- aging (i.e. accessing, retrieving, migrating or deleting) data across different platforms in a covenient and uniform way. Data collected by third-party applications are stored on their own servers, far from the eyes and hands of the ‘data subjects’ to whom they should belong. Users, although empowered by GDPR to request information about what applications know about them, have only limited technical capacity to do so, and the commercial purposes for which this knowledge has been used is generally impossible to determine precisely as soon as third parties are involved. Even when they have this capacity, users get to see only raw data, never secundary data combin- ing this raw data with that of others, e.g. statistical consumer models or personalized advertisement profiles.
9
At least since the mid-2000s, alternative models for the web have been suggested as a solution to the imbalances in the current data economy [60, 73, 68, 69, 84]. Most of these models introduce a clear functional separation between data storage and data processing roles. While data storage remains under the control of users, either via a de- centralized architecture in which these keep their own servers at home, or by delegat- ing storage functions to a trusted third party, data processing is performed by external service providers who can deploy their code inside and/or outside of the data contain- ers. If generalized to the entire data economy, this strict separation of data storage and data processing would amount to a kind of “digital Glass-Steagall act”, in which de- posits (storage) and investment (processing and value-making) would be required to be operated by distinct firms with different business models. Data storage firms, en- trusted with the management of users’ digital assets (their data) against the payment of a fee and accountable only to them, would defend their users’ data ownership in the digital ecosystem. These firms—limited companies, cooperatives, non-profits or even ‘data unions’ [74]—would compete with each other in a regulated market as do internet providers, web hosting services or commercial banks. They would rely on open, standardized and formally verified technologies which would allow them to enforce their users’ policies in a reliable way. Data processors, on the other hand, would need to contract with data storage firms or individual users to be granted access to the data on a by-purpose basis. With such an infrastructure in place, regulations such as the GDPR would be considerably easier to enforce, and would provide much stronger guarantees to users than in the current web ecosystem.
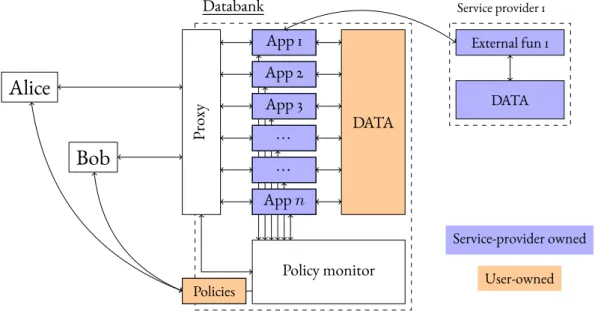
This new vision for the data economy requires novel software architectures. The trusted data storage system which plays a key part in the above description—and which we will henceforth call the Databank
1—must let users formulate their own data policies, efficiently and correctly enforce them, and provide service providers a way to access user data in the least intrusive and most purposed-based way possible.
In this thesis, we present the theory and implementation of this “Databank mo- del”, a new privacy-preserving web architectures organized around the Databank con- cept. In particular, we focus on the design of an execution environment for the Databank in which users specify policies, service providers provide programs, and the Databank monitors the execution of programs to prevent violations of the users’
policies. This infrastructure provides users with formal guarantees about the enforce- ment of their policies, which they specify in an expressive fragment of past-only Met- ric First-Order Temporal Logic (MFOTL).
1The word ‘databank’ was a widely used synonym of ‘database’ in the early years of computing, and is still the most common word for ‘database’ in German today (Datenbank); we chose this wording because it emphasizes the analogy between the data storage organization’s role and that of traditional banks, which are essentially ‘money storage’ organizations.
Contributions
The main contribution of this thesis is the design of the Databank model, a new web architecture for database-backed applications which enforces users’ privacy policies
“by design”. In the following, we list the concrete contributions of this thesis.
We design (1) Dmol’, a realistic model of an imperative language with method calls, dictionaries and web-oriented I-O, which features native label propagation and monitoring mechanisms. Assuming a blackbox monitoring backend, we show (2) that this language provides formal guarantees as regards both information flow prop- agation (non-interference) and correct enforcement of user policies (i.e. programs are always interrupted before a violation occurs). This language model is more com- prehensive than those generally considered in information flow tracking. We also (3) extend an existing past MFOTL monitoring algorithm with a label-propagation mechanism and (4) show its correctness. The combination of Dmol’ with this new monitoring backend constitutes a powerful and flexible framework for the develop- ment and deployment of Databank-side applications.
By developing (5) a working prototype of the full infrastructure with Dmol’
as the programming language of Databank-side code, we demonstrate that this ap- proach is practical and pave the way for further concrete developments in the field.
We compile Dmol’, which we view as a fragment of Python with special semantics, into standard Python, and extend MonPoly [15], which we use as the monitoring backend of our implementation, to implement our modified algorithm. Finally, (6) we evaluate our prototype through a case study of an event management application.
Structure of this thesis
This thesis consists of ten chapters, including this introduction. In Chapter 2, we re-
view the basic theory of two subfields of information security which address the issue
of ‘monitoring’ from very different perspectives, namely information flow monitor-
ing (Section 2.1) and runtime verification (Section 2.2). Ideas drawn from these two
hitherto largely independent fields will be combined in a novel way in the rest of
this thesis. In Chapter 3, we describe the architecture of the Databank model. The
next three chapters introduce the theory of the programming language Dmol’ (for
Databank model language) which is at the heart of the Databank architecture. Chap-
ter 4 describes the basic language model Dmol and how it propagates information
flows, and proves non-interference properties on this lanugage. Chapter 5 extends
Dmol with support for an (abstractly specified) monitor to obtain the monitored
language Dmol’ which is proven correct in terms of both non-interference and en-
forcement of user policies. Finally, Chapter 6 presents a concrete MFOTL monitor
derived from MonPoly [22] which complies with the specification assumed in the
previous chapter. The next chapters show the implementation of the Databank pro-
totype (Chapter 7) and its evaluation (Chapter 8). Finally, Chapter 9 discusses related
works, and Chapter 10 concludes this thesis with a brief summary of both achieve-
ments and open questions.
Monitoring: information flows and runtime verification
In this chapter, composed of two largely independent sections, we introduce the pre- liminary concepts on which the rest of this thesis relies. We first introduce informa- tion flow monitoring, giving a high-level overview of notions such as information flows, noninterference and label lattices. Then, we present runtime verification, in- cluding a more in-depth account of the theory of past-only Metric First-Order Tem- poral Logic [20] and its monitoring.
2.1 Information flow monitoring
Since the seminal works of Bell, Fenton and Denning’s in the 1970s [28, 45, 40], the study of information flows within programs has given rise to abundant research in software and system security, leading to significant spillovers in the technological realm.
The standard framework for information flow monitoring is provided by Den- ning’s 1976 and 1977 papers [40, 41], which mostly summarize ideas laid down in her PhD thesis [42]. The question she asks is the following: given a set of objects in mem- ory (files, variables etc.) and their confidentiality levels, a set of processes with differ- ent clearances accessing and manipulating memory, and rules of the form A → B allowing information to flow only between objects of specific security classes, how to enforce these rules in a given computer system? This and similar questions are cen- tral to all systems that manipulate confidential data. The variations are endless: dif- ferent system and security models may be considered, allowing to specify authorized flows much more complex than simple A → B rules; one or more programs, pro- cesses or users may need to collaborate, etc. Although information flow monitoring as described above generally focusses on confidentiality, i.e. on preventing unautho- rized disclosure of data, the issue of integrity, or preventing unauthorized alteration of data, can be handled in a similar way [82].
13
Enforcement methods may vary in a number of ways. Among other aspects, code describing the system (e.g. source code) may be checked statically for compliance with security policies before being deployed; or the information flows may be monitored at runtime, dynamically, blocking flows which are not compatible with the specifi- cations. While, in the early years of information flow monitoring, research efforts had mainly focussed on dynamic techniques, Denning and Denning’s groundbreak- ing 1977 paper shifted the focus to static analysis. This tendency was progressively re- versed from the 1990s onwards to the benefit of purely dyamic and mixed approaches [83].
2.1.1 Information flows and information flow channels
At this point, we need to clarify what we mean by ‘information flow’. For instance, consider two variables x and y in memory. Intuitively, information flows from x to y if and only if, during the execution of the program, the value of x has an effect on the value of y . This most naturally occurs when the value in x is assigned to y , as in the following Python code:
1 y = x
But some information also flows from x into y when x is only part of a computation whose final result is assigned to y . This is the case in each of the following three instructions:
1 y = x + 1
2 y = x % 2
3 y = x * x
There, we see that the presence of an information flow x → y does not necessarily imply that we are able to reconstruct the value of x from that of y . In line 2 above, reading the content of y only informs us about the parity of x , not about its actual value, while in the third example the value of y has two ‘preimages’ in x (namely √
y and − √
y ). In general, the existence of an information flow does not tell us how much information has flowed, but only that some information has or may have flowed from the old variable into the new one.
The key notion here is noninterference [47]. Informally, noninterference be- tween x and y means that the value of x does not in any way affect the value of y . What ‘not affecting’ means can be made more concrete by considering the following Gedankenexperiment: in a contrafactual scenario where the value of x would have been different (and chosen arbitrarily), the value of y would still have ended up be- ing the same as it currently is. Considering the following three instructions
1 y = 1
2 y = x + 1
3 y = x % 2
we see that the first line provides noninterference between x and y , since after exe- cuting it the value of y is 1 , irrespective of the value of x ; in the two other cases, we can always find an alternative value of x (for example x + 1 ) that leads to a different value of y after executing the instruction; hence noninterference does not hold.
Now, consider the following code snippet:
1 if x % 2 == 0:
2 y = 1
3 e l s e:
4 y = 0
With this code, do we have noninterference between x and y ? At a purely syntactical level, we may first think that it is the case: x and y do not occur together in any in- struction, and y can only be assigned a constant by lines 2 or 4. Semantically, however, we quickly realize that this code is equivalent to
1 y = 1 - ( x % 2)
which clearly shows that x and y interfere. What we have here is an instance of a so- called implicit information flow [40], as opposed to explicit information flows of the former type. In this example, information flows from x to y because of the presence of an if block guarded by a test ( x % 2 == 0 ) in which x occurs. As the value of x can affect the choice of the branch to be executed, all variables that are modified in either of the branches can be influenced by the value of x . This example shows that in any language that contains control flow statements, chasing explicit flows in assignements is insufficient to ensure noninterference.
Beyond implicit and explicit information flows, various covert channels capable of leaking information about the system may also arise. Sabelfeld and Myers distinguish termination channels, which result from an attacker’s ability to observe whether the program terminates or not; timing channels, when she can learn information about the content of memory based on the amount of time elapsed between two observable events triggered by the program; and probabilistic, resource and power channels arising from the observation of stochastic properties of the program and of resource and power consumption respectively [82].
2.1.2 Label-based information flow monitoring
The use of labels for monitoring information flows at runtime can be traced back
to Fenton’s 1974 Data Mark Machine [45, 40]. In this work, Fenton extends a regis-
ter machine with tags which associate a security class to each memory object. Some
registers might have a fixed security class—for example those representing input or
output channels from/to users with predefined clearances—while other tags are dy-
namically updated depending on the data they contain. Tags are propagated dynam-
ically throughout the code. Before each input or output operation, the tags of the in-
or output is checked for compliance with the policy, ensuring that no data is leaked in an unauthorized way.
A set of tags L , encoding security labels, typically forms a semilattice ( L, ⊔ , ⊑ ).
The join operation ⊔ is used to compute the tag of a piece of data which combines information from two (potentially different) sources, while the restriction relation
⊑ checks that a security level is subsumed by another. For example, a basic three- level security model can be modelized by the semilattice L
3= ({ 0, 1, 2 } , max, ≤ ).
Combining data tagged with security level 2 with data tagged with security level 1 leads to the result having security level max ( 1, 2 ) = 2 , which is consistent with our intuition that combining top-secret ( 2 ) with secret ( 1 ) data in an arbitrary way (e.g.
by concatenation) cannot lead to a security level less thann top-secret. The ordering relation ≤ then simply checks that a security level is less stringent than another; for instance 1 ≤ 2 expresses the fact that ‘secret’ is less restrictive than ‘top-secret’.
In the very well-known Bell-LaPadula model [28], the following read-down–
write-up approach is used to ensure that confidentiality of data is preserved: Every input or output channel is labeled with a fixed tag, corresponding e.g. to the security clearance of the user that sends and receives on this channel. To read from an input channel c
Iwith tag `
I, the receiver object should have security level `
R⊒ `
I(read- down): only data with a security level which is lower or equal to one’s clearance can be read. To write to an output channel c
Owith tag `
O, the sender object should have security level `
S⊑ `
O(write-up): one’s data can only be passed to people with higher clearances, in order to avoid disclosing sensitive information to unauthorized agents.
This enforces noninterference between every pair of levels ( `, `
′) with ` ⊒ `
′: “con- fidential (high) input does not cause a variation of public (low) output” (Sabelfeld and Myers).
Bell’s approach has been revisited countless times since its publication. Tag-based approaches have been widely studied and implemented in both static and dynamic contexts, with most authors adopting the lattice view pioneered by Denning.
An example of this is security type systems, introduced by Volpano, Irvine, and Smith [95]. In a security type system, the instructions of a language are labeled with elements from a semilattice to check whether they preserve confidentiality. Consider for example the simple imperative language MiniIMP (a slightly simplified version of Nipkow and Klein’s IMP language [75]) whose syntax is given in Figure 2.1a. Assume straightforward semantics for this language. Given a context Γ assigning a security level in ( L, ⊔ , ⊑ ) to each variable of a MiniIMP program p , it is easy to prove that p is typable with respect to the rules in Figure 2.1b iff it enforces noninterference with respect to L .
Besides these static approaches, a number of both imperative [90, 57], functional
[7] and assembly-like [3] language models featuring purely- or semi-dynamic label
propagation have been developed since the mid-2005. The principles of (semi-) dy-
Figure 2.1 – The MiniIMP language
(a) Syntax of the MiniIMP language
p ∶∶ = x = c ∣ x = y + z ∣ p; p ∣ while x ∶ p ∣ if x ∶ p else ∶ p
x, y, zdenote variable identifiers whilecdenotes a constant
(b) Bottom-up security type system for the MiniIMP language
Γ ⊢ x = c ∶ Γ ( x )
Γ ( x ) ⊒ Γ ( y ) ⊔ Γ ( z ) Γ ⊢ x = y + z ∶ Γ ( x )
Γ ⊢ c
1∶ `
1Γ ⊢ c
2∶ `
2Γ ⊢ c
1; c
2∶ `
1⊔ `
2Γ ( x ) ⊑ ` Γ ⊢ p ∶ `
Γ ⊢ while x ∶ p ∶ `
Γ ( x ) ⊑ `
1⊔ `
2Γ ⊢ p
1∶ `
1Γ ⊢ p
2∶ `
2Γ ⊢ if x ∶ p
1else ∶ p
2∶ `
1⊔ `
2namic label propagation will be presented in more detail in Chapter 4, where we will discuss the semantics of our own Dmol language.
Refinements of Bell’s approach can also be obtained by considering more com- plex semilattices. In 1997, Myers and Liskov suggested the following method to prop- agate information through complex systems in a decentralized way. Given a set of users U , the semilattice contains labels in U ⇀ 2
U, which are partial maps associat- ing a (finite) number of owners of a piece of data to a (finite) number of readers. The owners of a piece of data are those users whose inputs to the system affected the value of the data; the readers are those users that the corresponding owner authorized to access this data [70]. The corresponding join operation is
`
1⊔ `
2≡ ⎧⎪⎪⎪
⎨⎪⎪⎪ ⎩
x ↦ `
1( x ) if x ∈ dom `
1\ dom `
2x ↦ `
2( x ) if x ∈ dom `
2\ dom `
1x ↦ `
1( x ) ∩ `
2( x ) if x ∈ dom `
1∩ dom `
2.
For example, consider a variable x labeled with `
x= { u
1↦ { u
2, u
3}} and a variable y labelled with `
y= { u
1↦ { u
2} , u
2↦ { u
4}} . Combining the contents of these two variables, e.g. by concatenation into a new variable z , yields a value which is owned by both u
1and u
2. The ‘part’ of the new value owned by u
1can be read by u
2, since the content of both x and y could, but not by u
3, since u
1did not allow u
2to read y . We obtain
`
z= `
x⊔ `
y= { u
1↦ { u
2} , u
2↦ { u
1}} ,
and as owners always have the right to access their own data, z would then be readable
by users u
1and u
2only.
Additionally, Myers and Liskov describe a declassification mechanism through which users can alter the labels of pieces of data they own to make them visible to users with lower clearances. A comprehensive theoretical account of declassification and other extensions of standard information-flow labels has been given by Montagu, Pierce, and Pollack [67]. The interested reader can refer to this paper for a more thorough discussion of the theory of label algebras.
2.2 Runtime verification
Runtime verification (RV) is a fairly recent and actively researched branch of for- mal methods which is primarily concerned with the monitoring of the behavior of (complex) systems [63, 13]. In runtime verification, the system’s internal structure and mode of operation are abstracted away, focussing instead on specific high-level events. During the execution of the system, these events are logged to traces, which are then checked, either online or offline, for compliance with some predefined policies written in an appropriate logical formalism, called the specification language. This approach is generally considered to have entered history through the homonymous workshop held in 2001 [13], and, with its considerable potential as a “lightweight, yet rigorous” method (Bartocci et al.), has since then become part of the mainstream in both industry and research.
In this section, we review the main concepts of RV that will be used in the fol- lowing chapters. We first present the main concepts of RV. Then, we describe Metric First-Order Temporal Logic (MFOTL) [14] and its applications to RV. In particu- lar, we provide an algorithm for online monitoring of past-only MFOTL formulae which we will revisit in a later chapter. Finally, we give a brief overview of the Mon- Poly tool for MFOTL monitoring [22, 15].
2.2.1 General concepts
The smallest unit of RV is the event. An event is “any kind of observation about the
system” [13], which might or might not be associated to a specific system state. For ex-
ample, a user retrieving a web page, clicking on a button or shutting down the server
may be considered an event. Events may have none, one or more parameters, which
are relevant pieces of information that tell us more about the event. In the previous
examples, the identity of the user who retrieved the page, clicked the button or shut
down the server is such a piece of information; for the button click, other parame-
ters might be, for instance, the ID of the button and the duration of the click. These
events may be logged by the same software that triggered them (the user’s browser)
or received them (the server), or they might be registered by some external third party
in a purely observational way (a browser add-on or a hacker behind her keylogger).
Thus, events conveniently abstract away the internal state of the system do focus on aspects relevant for program safety, correctness, compliance with regulation etc. The set of events to be considered as well as the number and the number of their parame- ters is generally known in advance. In logic, this set of possible events naturally trans- lates into a monitoring signature, which defines a set of constant symbols from which the parameters can be chosen, a set of relational symbols encoding the different types of events, and an arity function which maps each relation/event to the number of their parameters.
The next definition, as well as the following ones, is adapted from Basin, Klaedtke, and Müller [14] and Basin et al. [20].
Definition 2.1 (Signature). A signature σ is a triple ( C, R, α ) where C is a set of constant symbols, R is a finite set of relational symbols or predicates, and α ∶ R → N defines the arity of each relational symbol.
Once we have specified the universe of all event names and arities within a mon- itoring signature, the specific events that actually occur in the system can be seen as a logical structure over this signature. In this structure, each constant symbol is inter- preted as a concrete element of a domain ∣ D ∣, while each predicate r is associated to a set of tuples of arity α ( r ) containing elements of ∣ D ∣ . This set of tuples stores all those events of type r that actually occurred, as well as the corresponding parameters.
For example, a predicate ClickButton of arity α ( ClickButton ) = 2 , where the first parameter contains the name of the user that clicked the button and the second parameter contains the DOM name of the button, can be interpreted as the relation
ClickButton
D= {( Alice, button1 ) , ( Bob, button2 )}
which states that exactly two such events, namely ClickButton ( Alice, button1 ) and ClickButton ( Bob, button2 ), have taken place.
Given a signature which specifies all admissible events, structures over this sig- nature fit our henceforth informal intuition of a trace or log as encoding the set of all events occurred in the system. However, structures of this kind are still non- temporal, allowing us to consider only an unordered batch of all events that oc- curred, rather than those that occurred at each specific point in time.
Definition 2.2 (Structure). Let σ = ( C , R, α ) be a signature. A (relational) structure D over σ consists of a domain ∣ D ∣ and interpretations c
D∈ ∣ D ∣ and r
D⊆ ∣ D ∣
α(r)for each c ∈ C and r ∈ R respectively.
As our notion of time is discrete, a simple way to recover the missing temporal
dimension is to consider a sequence of structures over the same domain. Each struc-
ture in this sequence shall store those events that were logged at each time point,
along with a sequence of timestamps, under the additional requirement that the in- terpretation of constants should be the same in every structure. The evolution of the system over time is thus viewed as a succession of snapshots, with the system itself being characterized by its domain and the interpretation of constants, which do not change in the course of the execution. The resulting timed temporal structure consti- tutes a formal encoding of traces. Both words will be used interchangeably from this point onwards.
Definition 2.3 (Trace). Let σ = ( C , R, α ) be a signature. A timed temporal structure or trace over σ is a pair ( D, τ ) where D = ( D
0, . . . , D
N−1) and τ = ( τ
0, . . . , τ
N−1) are sequences
1of structures over σ and timestamps in N respectively, such that:
1. There exists a nonempty, totally ordered domain (∣ D ∣ , < ) such that for every i ∈ [[ 0, N [[, ∣ D
i∣ = ∣ D ∣;
2. For each c ∈ C , there exists an interpretation c
D∈ ∣ D ∣ of c such that for all i ∈ [[ 0, N [[, c
Di= c
D;
3. For each r ∈ R and i ∈ [[ 0, N [[, r
Diis finite;
4. The sequence τ is monotonically increasing.
Note that, since the trace we consider are always finite, we have required that every relation defined within a trace be finite as well.
2.2.2 Metric First-Order Temporal Logic (MFOTL)
2.2.2.1 Definitions and semantics
Having now formally introduced signatures and traces, we can proceed with defining the security policies which we will want to check and/or enforce with respect to traces.
Policies are formulae which partition the set of traces in two subsets: those which satisfy the policy and those which do not. Those not satisfying the policy are said to violate it, while traces of the second kind are said to comply with it. The objective of the monitoring process is to detect violations, or, equivalently, to check that the provided traces comply with the policy.
A security policy may state, for example, that a certain piece of information m cannot be learnt by any user u
1unless this has been previously authorised by some other user u
2with administrator permissions within the last two days. Or it could demand that some global attribute of the system must not change after an admin- istrator has defined it ‘frozen’. We will see in the next paragraphs how this can be encoded formally.
1Basin et al. originally considered infinite traces. In thesis, since we are only going to consider a past-only fragment of MFOTL, we consider finite traces to allow ourselves to treat traces as finite objects in memory.
In order to describe the set of policies that we will monitor, we need an appro- priate logical formalism. Common specific languages in runtime verification include dialects of temporal logic, among which (T)LTL [26, 27] and MFOTL [14, 20], but also regular expressions and state machines [13]. In this chapter, we will focus on past-only Metric First-Order Temporal Logic (MFOTL) as a specification language.
In MFOTL, in addition to the standard operators of first-order logic, we can use four types of basic temporal operators. First, we have a unary operator “previous”
(⬤), indexed by a (temporal) interval I ∈ I. Applied to a formula φ , “previous”
produces a formula ⬤
Iφ that is true iff φ was true at the previous time point and the difference between the current and the previous timestamps is in I . Similarly, a unary operator “next” (◯) allows us to specify formulae ◯
Iφ which hold iff φ holds in the next time point and the difference of the timestamps is in I . A binary operator “since” ( S
I) can be used to write formulae of the form φ
1S
Iφ
2, which hold true iff there exists some past time point with timestamp τ
jsuch that: (i) τ
jis within I from the current timestamp (ii) φ
1holds at τ
j(iii) φ
2holds at all time points between j and the present. Finally, a binary operator “until” ( U
I) allows us to form formulae φ
1U
Iφ
2twhich are true whenever there is a future time point with timestamp τ
jat which φ
2holds, and such that between the current time point and j formula φ
1always holds. When the interval considered is [[ 0, ∞[[ = N, we may omit the corresponding index.
Using these four operators, we can for convenience define further operators “his- torically”, “once” etc. as syntactic sugar. For instance, operator “once” (⧫), express- ing the fact that a formula has been true some time in the past, can be straightfor- wardly defined using “since” and the constant predicate “true” ( ⊤ ) as
⧫
Iφ ≡ ⊤ S
Iφ.
As an example, consider a few predicates
Learns ( user, message ) Authorizes ( admin, user ) IsAdmin( user ) Changes( attribute )
Freezes ( user, attribute )
The first security policy informally described above as “ m cannot be learnt by any user u
1unless some administrator u
2has previously authorized u
1to do so within the last two days” can be expressed as
∀ u
1.Learns ( u
1, m ) ⇒ ( ⊤ S
[[0,2]](∃ u
2.Authorizes ( u
2, u
1) ∧ IsAdmin ( u
2))) or, with “once”,
∀ u
1.Learns( u
1, m ) ⇒ ⧫
[[0,2]](∃ u
2.Authorizes( u
2, u
1) ∧ IsAdmin( u
2)) .
Similarly, the policy “no attribute should change if it has be defined frozen by an administrator” is encoded as
∀ a.Changes( a ) ⇒ ¬⧫ (∃ u.IsAdmin( u ) ∧ Freezes( u, a )) . This is formalized in the following definition:
Definition 2.4 (MFOTL formulae). Let σ = ( C , R, α ) be a signature, and V be a set of variables disjoint from C ∪ R . The set of MFOTL formulae over σ and V is defined inductively as follows:
φ ∶∶ = t
1≺ t
2( t
1, t
2) ∈ ( V ∪ C )
2∣ t
1≈ t
2( t
1, t
2) ∈ ( V ∪ C )
2∣ r ( t
1, . . . , t
α(r)) r ∈ R, ( t
1, . . . , t
α(r)) ∈ V
α(r)∣¬ φ
′“not”
∣ φ
1∧ φ
2“and”
∣∃ x.φ
′x ∈ V “exists”
∣⬤
Iφ
′I ∈ I “previous”
∣ ◯
Iφ
′I ∈ I “next”
∣ φ
1S
Iφ
2I ∈ I “since”
∣ φ
1U
Iφ
2I ∈ I “until”
Given x ∈ V , we define the following notations as syntactic sugar:
⊤ ≡ ∃ x.x ≈ x
⊥ ≡ ¬ ⊤
φ
1∨ φ
2≡ ¬ (¬ φ
1∧ ¬ φ
2) “or”
φ
1⇒ φ
2≡ ¬ φ
1∨ φ
2“entails”
⧫
Iφ ≡ ⊤ S
Iφ “once”
◊
Iφ ≡ ⊤ U
Iφ “eventually”
⬛
Iφ ≡ ¬⧫
I¬ φ “historically”
⬜
Iφ ≡ ¬◊
I¬ φ “always”
When I = [[ 0, ∞[[, the indices of temporal connectives may be omitted.
A specific case of MFOTL formulae are past-only MFOTL formulae, which are MFOTL formulae without future (“next” or “until”) operators:
Definition 2.5 (Past-only MFOTL formulae). For σ and V as above, the set of past-
only MFOTL formulae over σ and V contains all MFOTL formulae over σ and V
that use no “next” or “until” (and no “forever” or “eventually”) connectives.
In the rest of this thesis, we will consider only past-only MFOTL formulae. Hence, in the following pages, semantics as well as the monitoring algorithm will only be provided for the past-only fragment.
Finally, we introduce valuations, which map variables and constants to their re- spective values within a structure. The notation fv φ denotes the free variables of a formula φ .
Definition 2.6 (Valuation). Let σ = ( C , R, α ) be a signature, V a set of variables distinct from C ∪ R , and φ an MFOTL formula over σ and V . Let D be a structure over σ . A valuation v for φ is a mapping v ∶ C ⊔ fv φ → ∣ D ∣ such that for all c ∈ C , v ( c ) = c
D.
Given a valuation v , a variable x ∈ V and a value w ∈ ∣ D ∣, the mapping obtained by setting x to w in v is denoted by v [ x / w ] .
We are now ready to define the semantics of past-only MFOTL:
Definition 2.7 (Semantics of past-only MFOTL, [20]). Let σ = ( C, R, α ) be a sig- nature, V a set of variables distinct from C ∪ R . The satisfiability of past-only MFOTL formulae is encoded in sequents of the form ( D, τ, v, i ) ⊨ φ , where ( D, τ ) is a trace over σ of length N , φ is a past-only MFOTL formula over σ and V , v is a valuation for φ , and i ∈ [[ 0, N [[ is a time point. The semantics of past-only MFOTL is defined by the following derivation rules:
v(t)=v(t′) (D, τ, v, i)⊨t ≈t′
v(t)<v(t′) (D, τ, v, i)⊨t ≺t′
(v(t1), . . . , v(tα(r)))∈rDi (D, τ, v, i)⊨r(t1, . . . , tα(r)) (D, τ, v, i) /⊨φ
(D, τ, v, i)⊨¬φ
(D, τ, v, i)⊨φ1 (D, τ, v, i)⊨ φ2 (D, τ, v, i)⊨φ1∧φ2
w∈∣D∣ (D, τ, v[x/w], i)⊨φ (D, τ, v, i)⊨∃x.φ
i>0 τi−τi−1 ∈I (D, τ, v, i−1)⊨φ (D, τ, v, i)⊨⬤Iφ
j ≤i τi−τj ∈I (D, τ, v, j)⊨φ2 ∀k ∈[[j+1, i]],(D, τ, v, k)⊨φ1 (D, τ, v, i)⊨φ1 SIφ2
![Figure 4.1 – Syntax of programs prog ∶∶ = »»»» »»»» »»»» f un. . .f un (4.1) f un ∶∶ = »»»»»»»» »»»» »»»» [ @entrypoint ( r )]deff(h1,](https://thumb-eu.123doks.com/thumbv2/1library_info/3908843.1525989/48.892.117.793.136.1122/figure-syntax-programs-prog-f-f-entrypoint-deff.webp)


![Figure 4.10 – Evaluation of Dmol expressions c ∈ V ε ( c, u, m ) = ⟨ c, ∅⟩ (4.35) i ∈ dom m ε ( i, u, m ) = m [ i ] i ∈ G ⊔ H \ dom mε(i, u, m)=⟨⊥, ∅⟩ (4.36) ε ( e 1 , u, m ) = ⟨ v 1 , i 1 ⟩ ε ( ω e 1 , u, m ) = ⟨ ω ( v 1 ) , i 1 ⟩ (4.37) ε ( e 1 , u, m )](https://thumb-eu.123doks.com/thumbv2/1library_info/3908843.1525989/64.892.192.816.114.1104/figure-evaluation-dmol-expressions-v-dom-dom-mε.webp)