Statistische Analyseverfahren Abschnitt 3: Diskriminanzanalyse
Dr. Andreas W¨ unsche
TU Bergakademie Freiberg Institut f¨ur Stochastik
Oktober/November 2019
3 Diskriminanzanalyse 3.1 Einf¨ uhrung
I
Zielstellung einer Diskriminanzanalyse ist es, einen Merkmalstr¨ ager (ein Objekt) mit Hilfe der beobachteten Messwerte zu einer von mehreren Klassen (Gruppen, Populationen, . . . ) zuzuordnen, wobei in der Regel keine eindeutige deterministische Zuordnung mittels einfacher Entscheidungsregeln m¨ oglich ist.
I
Zuerst soll der Fall behandelt werden, dass die unterschiedlichen Klassen durch jeweils bekannte Wahrscheinlichkeitsverteilungen der Merkmalszufallsvektoren charakterisiert werden.
I
Danach wird auf den praktisch relevanteren Fall eingegangen, dass die unterschiedlichen Wahrscheinlichkeitsverteilungen der Merkmalszufallsvektoren nicht vollst¨ andig bekannt sind.
I
Außerdem soll die lineare Diskriminanzanalyse von
Fishervorgestellt werden, bei der keine speziellen Verteilungen der
Merkmalszufallsvektoren genutzt werden.
Beispiele
I
Kredit-Scoring: Beurteilung der Kreditw¨ urdigkeit f¨ ur (z.B.) Neukunden, wobei ein Kunde anhand von bestimmten erhobenen Daten, wie z.B. Familienstand, Alter, Verm¨ ogen, Status als Arbeitsnehmer, Besch¨ aftigungsdauer, etc. in die Klasse der kreditw¨ urdigen oder kreditunw¨ urdigen Kunden eingestuft werden soll.
I
Im Zusammenhang mit dem R-Beispieldatensatz
” Iris“ kann man das Problem betrachten, eine Schwertlilienpflanze anhand der gemessenen Gr¨ oßen L¨ ange des Kelchblattes, Breite des Kelchblattes, L¨ ange des Bl¨ utenblattes und Breite des Bl¨ utenblattes zu einer der drei Blumenarten
” Iris setosa“ (Borsten-Schwertlilie),
” Iris versicolor“ (Verschiedenfarbige Schwertlilie) und
” Iris virginica“
(Virginische Schwertlilie) zuzuordnen.
Formales Vorgehen
I
Aufgabenstellung: Klassifikation (Klassierung), Zuordnung eines Merkmalstr¨ agers zu einer von g
≥2 Klassen Π
1, . . . , Π
gauf der Grundlage von
” Messwerten“ x als Realisierungen von zuf¨ alligen p−dimensionalen Merkmalsvektoren X
j.
I
Ziel: Die Zuordnung soll zu m¨ oglichst wenigen Fehlklassifikationen f¨ uhren.
I
Formales Vorgehen: Der Merkmalsraum (oft
Rd) wird in g disjunkte Regionen R
1, . . . , R
geingeteilt (zerlegt).
I
Diskriminanzregel: Der Merkmalstr¨ ager mit Merkmalsvektor x ( ” der Merkmalsvektor x“) wird der Population Π
i(i
∈ {1, . . . ,g
})genau dann zugeordnet, wenn x
∈R
igilt.
I
H¨ aufige Annahme: Die Verteilung des Merkmalsvektors f¨ ur jede
Klasse besitze eine Dichtefunktion f
j, j = 1, . . . , g , bzgl. eines
Maßes auf dem Merkmalsraum (oft die ¨ ubliche Verteilungsdichte).
Beispiel f¨ ur die Maximum-Likelihood-Diskriminanzregel
I
1 Merkmal, 2 Klassen, Normalverteilungen.
I
Geg. p = 1 , g = 2 , Π
1=
N(µ1, σ
2) , Π
2=
N(µ2, σ
2) , µ
1< µ
2; µ
1, µ
2, σ
2bekannt.
I
Maximum-Likelihood-Diskriminanzregel:
Ordne dem Merkmalstr¨ ager mit Merkmalswert x
∈Rdiejenige Klasse zu, deren Dichtefunktion im Punkt x maximal wird, bei Gleichheit kann man beliebig (messbar) zuordnen.
I
Da hier f¨ ur alle x < µ
1+ µ
22 gilt f
1(x) > f
2(x) , lautet die (oder besser: eine) Diskriminanzregel
x < µ
1+ µ
22
7−→Π
1, Zuordnung zu Klasse 1 ; x
≥µ
1+ µ
22
7−→Π
2, Zuordnung zu Klasse 2 .
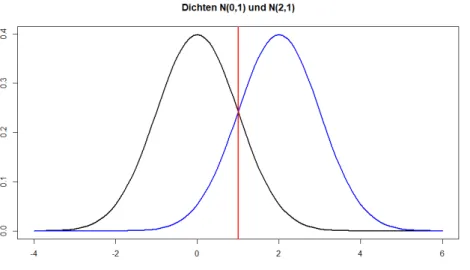
Grafik Dichtefunktionen mit µ
1= 0, µ
2= 2, σ
2= 1
Simulationsstudie Maximum-Likelihood-Diskriminanzregel
I
In einer Simulationsstudie wurden jeweils 1000 Realisierungen des Merkmals der Klasse 1 mit der Verteilung
N(0,1) und
der Klasse 2 mit der Verteilung N(2,1)erzeugt.
I
Mit der Maximum-Likelihood-Diskriminanzregel werden
Realisierungwerte <
1der Klasse 1 zugeordnet, die anderen (d.h.
≥1) der Klasse 2. Die theoretische Wahrscheinlichkeit f¨
ur eine Fehlklassifikation (eine Realisierung aus der Klasse 1 wird der
Klasse 2zugeordnet bzw. eine Realisierung aus der
Klasse 2wird der Klasse 1 zugeordnet) betr¨ agt jeweils 1
−Φ(1)
≈0.159 .
I
In der erzeugten Stichprobe werden 148 Realisierungen aus der Klasse 1 der
Klasse 2zugeordnet und 161 Realisierungen aus der
Klasse 2der Klasse 1 zugeordnet, also fehlerhaft klassifiziert.
I
Bei einer Trenngrenze von
1.5statt
1zum Beispiel w¨ urden 74
Realisierungen aus Klasse 1 und 324 Realisierungen aus
Klasse 2fehlerhaft klassifiziert.
Histogramme Simulationsstudie
Beispiel f¨ ur die Bayes sche Diskriminanzregel
I
Geg. p = 1 , g = 2 , Π
1=
N(µ1, σ
2) , Π
2=
N(µ2, σ
2) , µ
1< µ
2; µ
1, µ
2, σ
2bekannt, π
1, π
2a-priori-Wahrscheinlichkeiten f¨ ur die 1. bzw. 2. Klasse.
I Bayes
sche Diskriminanzregel: Ordne dem Merkmalstr¨ ager mit Merkmalswert x
∈Rdiejenige Klasse zu, deren a-posteriori- Wahrscheinlichkeit π(j
|x) maximal wird, bei Gleichheit kann manbeliebig (messbar) zuordnen.
I
Es gelten
π(j
|x) =f
j(x)π
jf
1(x)π
1+ f
2(x)π
2∝
f
j(x )π
j, j = 1, 2 ; π(1|x) > π(2|x)
⇔x < 1
2 (µ
1+ µ
2) + σ
2µ
2−µ
1ln π
1π
2
.
Simulationsstudie Bayes sche Diskriminanzregel
I
In einer Simulationsstudie wurden 2000 Realisierungen des Merkmals der Klasse 1 mit der Verteilung
N(0,1) und 1000 Realisierungen der
Klasse 2 mit der VerteilungN(2,1)erzeugt. Dies entspricht der Situation mit a-priori-Wahrscheinlichkeiten π
1=
23, π
2=
13.
I
Mit der
Bayesschen Diskriminanzregel werden Realisierungwerte
<
1 +12ln(2)≈1.347der Klasse 1 zugeordnet, die anderen der
Klasse 2.I
In der erzeugten Stichprobe werden 177 Realisierungen aus der Klasse 1 der
Klasse 2zugeordnet und 255 Realisierungen aus der
Klasse 2der Klasse 1 zugeordnet (also fehlerhaft klassifiziert), dies entspricht einer relativen H¨ aufigkeit von 0.144.
I
Bei einer Trenngrenze von
1statt
1.347zum Beispiel w¨ urden 314
Realisierungen aus Klasse 1 und 154 Realisierungen aus
Klasse 2fehlerhaft klassifiziert, dies entspricht einer relativen H¨ aufigkeit von
0.156.
Histogramme Simulationsstudie
3.2 Diskrimination bei bekannten Verteilungen
I
Allgemeine Maximum-Likelihood-Diskriminanzregel (ML-Diskriminanzregel) bei bekannten Verteilungen:
x
∈R
i, falls L(i; x) = max
j=1,...,g
L(j ; x) mit
L(j ; x) := f
j(x) , j = 1, . . . , g , (Likelihood-Funktion) mit speziellen Vereinbarungen im Fall mehrfacher Maxima, so dass eine messbare Zuordnung realisiert wird.
I
Beispiel Π
1=
0 1 0.5
0.5
, Π
2=
0 1
0.25 0.75
;
x = 0 : L(1; 0) = 0.5 >
0.25= L(2; 0) , Zuordnung zu Π
1;
x = 1 : L(1; 1) =
0.5<
0.75= L(2; 1) , Zuordnung zu Π
2.
ML-Diskrimination f¨ ur Normalverteilungen mit identischen regul¨ aren Kovarianzmatrizen
I
Satz 3.2.1 Geg. Π
j=
Np(µ
j, Σ) , Σ regul¨ ar, j = 1, . . . , g . Die ML-Diskriminanzregel ist dann gegeben durch: x
∈R
i ⇔(x
−µ
i)
TΣ
−1(x
−µ
i) = min
j=1,...,g
(x
−µ
j)
TΣ
−1(x
−µ
j) und eine geeignete Vereinbarung im Fall mehrfacher Minima.
I
Def. 3.2.2 Die Zahl d
M(x, µ
j) :=
(x
−µ
j)
TΣ
−1(x
−µ
j)
1/2ist der
Mahalanobis-Abstand von x zum Erwartungswertvektor µ
j(oft wird auch keine Quadratwurzel gezogen) .
I
Bem. Nimmt der
Mahalanobis-Abstand zwischen dem Merkmalsvektor x und dem Erwartungswertvektor µ
i
der i−ten Klasse das Minimum unter allen
Mahalanobis-Abst¨ anden
zwischen x und µ
j(j = 1, . . . , g ) an, so wird der Merkmalstr¨ ager
mit dem Merkmalsvektor x der i
−ten Klasse zugeordnet.Allgemeiner Fall von 2 Klassen: Diskriminanzfunktion
I
Bem.
Im Fall mit g = 2 gilt: x
∈R
1, falls L(1; x) > L(2; x) , d.h. falls ln L(1; x)
L(2; x) = ln L(1; x)
−ln L(2; x) > 0 .
I
Def. 3.2.3 Die Funktion
h(x) := ln L(1; x)
L(2; x) = ln L(1; x)
−ln L(2; x) , x
∈Rp, wird Diskriminanzfunktion genannt.
I
Bem.
Die Diskriminanzfunktion teilt
Rpin zwei Teilmengen. Mit der
ML-Diskriminanzregel liegt x in R
1, wenn h(x) > 0 gilt.
Zwei Normalverteilungen mit gleichen Kovarianzmatrizen
I
Satz 3.2.4
Geg. Π
j=
Np(µ
j, Σ) , Σ regul¨ ar, j = 1, 2 . Dann gelten
x
∈R
1 ⇔h(x) = (µ
1−µ
2)
TΣ
−1x
−1
2 (µ
1+ µ
2)
> 0 . x
∈R
2 ⇔h(x)
≤0 .
Folglich ist die Diskriminanzfunktion h(x) (affin) linear, ihre Nullstellenmenge
{x∈Rp: h(x) = 0} beschreibt eine Hyperebene (die Trennebene) im Raum
Rp, die durch den Schwerpunkt (den Mittelpunkt) der beiden Erwartungswertvektoren (µ
1
+ µ
2
)/2 geht.
I
Bem.
Wird eine affin lineare Diskriminanzfunktion zur Klassifizierung genutzt, spricht man auch von
” linearer Diskriminanzanalyse
(LDA)“.
Zwei Normalverteilungen mit regul¨ aren Kovarianzmatrizen
Bem.
Besitzen die Normalverteilungen unterschiedliche Kovarianzmatrizen, f¨ uhrt die Maximum-Likelihood-Diskriminanzregel zu einer quadratischen Diskriminanzfunktion. Das entsprechende Verfahren wird auch
” quadratische Diskriminanzanalyse (QDA)“ genannt.
Im univariaten Fall (p = 1) gilt dann x
∈R
1 ⇔x
2
1 σ
12 −1
σ
22−2x
µ
1σ
12 −µ
2σ
22+ µ
21σ
21 −µ
22σ
22
< 2 ln σ
2σ
1.
Beispiel 3.2.5
Geg. Π
j=
N2(µ
j, Σ) ; j = 1, 2 ; Σ =
1 0 0 2
; µ
1=
1
1
; µ
2=
0
0
.
Merkmalstr¨ ager mit Merkmalsvektor x = 1
2 , 1
T.
Bayes sche Diskriminanzregel
I
Wenn man bereits
” Vorurteile“ bzw. Vorinformationen ¨ uber die Zugeh¨ origkeiten zu den g Klassen hat, kann man diese mit in die Diskriminanzregel aufnehmen.
I
Geg. zus¨ atzlich a-priori-Wahrscheinlichkeiten π
1 ≥0, . . . , π
g ≥0 mit
g
X
j=1
π
j= 1 f¨ ur die Klassen Π
1, . . . , Π
g.
⇒
a-posteriori-Wahrscheinlichkeiten π(i|x) = L(i ; x)π
iPg
j=1
L(j; x)π
j ∝L(i; x)π
i, i = 1, . . . , g .
I Bayes
sche Diskriminanzregel: Ordne den Merkmalsvektor x zur Klasse i zu, d.h. x
∈R
i, falls
π
iL(i; x) = max
j=1,...,g
π
jL(j ; x)
(mit speziellen Vereinbarungen im Fall mehrfacher Maxima).
Bemerkungen zur Bayes schen Diskriminanzregel
I
Die Maximum-Likelihood-Diskriminanzregel erh¨ alt man im Fall π
1= . . . = π
g=
g1.
I
Im Spezialfall g = 2 f¨ uhrt das auf eine Verschiebung des kritischen Wertes der Diskriminanzfunktion: x
∈R
1 ⇔h(x) > ln(π
2/π
1) .
I
Insbesondere lautet die
Bayessche Diskriminanzregel bei 2 Klassen von p-dimensional normalverteilten Merkmalsvektoren mit gleichen Kovarianzmatrizen Σ = Σ
1= Σ
2(vgl. Satz 3.2.4)
x
∈R
1 ⇔h(x) = (µ
1−µ
2)
TΣ
−1x
−1
2 (µ
1+ µ
2)
> ln π
2π
1; x
∈R
2 ⇔h(x)
≤ln
π
2π
1
;
bzw. mit der Diskriminanzfunktion h
1(x) := h(x)
−ln π
2π
1:
Zuordnung zu Π
1falls h
1(x) > 0 , sonst zu Π
2.
Fortsetzung Beispiel 3.2.5
Zus¨ atzlich geg.
π
1= 2
3 , π
2= 1
3 .
3.3 Diskrimination, wenn Verteilungen bis auf Parameter bekannt sind
I
Sind die Verteilungen der zuf¨ alligen Merkmalsvektoren f¨ ur die einzelnen Klassen nicht bekannt, ben¨ otigt man eine Lernstichprobe (Trainingsstichprobe) von Merkmalstr¨ agern mit beobachteten Merkmalsvektoren, f¨ ur die die Zugeh¨ origkeit zu einer Klasse bekannt sein muss. Dann kann man f¨ ur weitere Merkmalstr¨ ager die
Diskrimination z.B. mit Hilfe gesch¨ atzter Parameter durchf¨ uhren.
I
Vor. 3.3.1
Es liegt eine Datenmatrix x vor, mit jeweils n
jRealisierungen der Population Π
j, j = 1, . . . , g , d.h.
x = (x
T1, . . . , x
Tg)
T, x
j ∈Rnj×p, x
j= (x
j1, . . . , x
jnj)
T.
Mit diesen Daten soll eine passende Diskriminanzregel gelernt
werden.
Prinzip der Stichproben-ML-Diskriminanzregel
Prinzip 3.3.2
(i)
Die unbekannten Parameter von Π
jwerden mit x
j
gesch¨ atzt.
(ii)
Danach benutzt man die ML-Diskriminanzregel zur Zuordnung mit
gesch¨ atzten statt theoretischen Parametern.
Univariates Beispiel Stichproben-ML-Diskriminanzregel
3.3.3 Bsp.
Geg. p = 1 , g = 2 , Π
1=
N(µ1, σ
2) , Π
2=
N(µ2, σ
2) , µ
1< µ
2; µ
1, µ
2, σ
2unbekannt;
Lernstichproben x
1= (x
11, . . . , x
1n1)
T, x
2= (x
21, . . . , x
2n2)
T; Sch¨ atzwerte µ
j ≈µ ˆ
j= x
j= (x
j1+ . . . + x
jnj)/n
j, j = 1, 2 .
Diskriminanzregel (Fall x
1< x
2) : x
∈R
1falls x <
12(x
1+ x
2) . Zahlenbeispiel:
x
1= (4.09, 1.11, 3.73, 5.21, 2.99, 4.36, 3.46, 2.01, 1.72, 3.38)
T, x
2= (4.57, 5.41, 3.82, 4.12, 5.20, 4.91, 6.12, 3.72, 2.93, 4.85)
T, x
1= 3.21 , x
2= 4.57 ,
1
2 (x
1+ x
2) = 3.89 . x
∈R
1falls x < 3.89 ,
sonst x
∈R
2.
Punktdiagramm Daten:x1schwarz,x2rotSch¨ atzung der Parameter der Klassenverteilungen
I
Vor. 3.3.4
Neben Vor. 3.3.1 sind die Daten in den g Klassen p-dimensional normalverteilt mit den Erwartungswertvektoren µ
1
, . . . , µ
g
und
¨
ubereinstimmenden Kovarianzmatrizen Σ = Σ
1= . . . = Σ
g, d.h.
X
j ∼Np(µ
j, Σ) , j = 1, . . . , g ; µ
jund Σ sind unbekannt.
I
Beh. 3.3.5
Sch¨ atzwerte aus erwartungstreuen Sch¨ atzfunktionen aus den Datenmatrizen x
jsind unter Vor. 3.3.4
I f¨ur die Erwartungswertvektoren ˆ
µj =xj = 1 nj
nj
X
k=1
xjk, j= 1, . . . ,g;
I f¨ur die Kovarianzmatrizen Σˆ
j=s
j = 1
nj−1
nj
X
k=1
(xjk−xj)(xjk−xj)T, j = 1, . . . ,g.
Sch¨ atzung der gemeinsamen Kovarianzmatrix
Beh. 3.3.6
Eine geeignete Sch¨ atzmatrix (mit einer erwartungstreuen Sch¨ atzung) der gemeinsamen Kovarianzmatrix Σ ist unter Vor. 3.3.4 und mit
n = n
1+ . . . + n
ggegeben durch Σ ˆ = ˜ s = 1
n
−g
g
X
j=1
(n
j−1)s
j= 1
n
−g
g
X
j=1 nj
X
k=1
(x
jk−x
j)(x
jk−x
j)
T=: 1
n
−g w .
Beispiel 3.3.7 (Simulation f¨ ur Beispiel 3.2.5)
Lernstichprobe Klasse 1 k x
1k1x
1k21 1.83 -0.41 2 0.72 -0.57 3 0.64 0.92 4 1.09 2.66 5 3.25 2.49 6 1.83 1.08 7 2.31 -0.04 8 3.50 2.32 9 2.17 3.36 10 0.57 1.79 x
1= 1.791 1.360 s
21= 1.102 1.907 r
1= 0.336
Lernstichprobe Klasse 2 k x
2k1x
2k21 -0.75 -0.60 2 1.26 0.02 3 0.04 1.00 4 0.19 1.37 5 0.46 -0.88 x
2= 0.240 0.182 s
22= 0.528 0.962
r
2= 0.053
⇒
˜ s =
0.925 0.348 0.348 1.616
˜ s
−1=
1.176
−0.254−0.254
0.673
Streudiagramm Beispiel 3.3.7
blau: Merkmalsvektoren Klasse 1 ,
rot: Merkmalsvektoren Klasse 2.Stichproben-ML-Diskriminanzregel
Beh. 3.3.8
Unter obigen Voraussetzungen 3.3.4 gilt
I
die folgende Stichproben-ML-Diskriminanzregel: x
∈R
i ⇔x
∈R
i ⇔(x
−µ ˆ
i
)
TΣ ˆ
−1(x
−µ ˆ
i
) = min
j=1,...,g
(x
−µ ˆ
j
)
TΣ ˆ
−1(x
−µ ˆ
j
) und eine geeignete Vereinbarung im Fall mehrfacher Minima.
I
Im Spezialfall von 2 Klassen erh¨ alt man mit der aus der Lernstichprobe gesch¨ atzten (
” gelernten“) Diskriminanzfunktion h(x) = (x ˆ
1−x
2)
T˜ s
−1
x
−1
2 (x
1+ x
2)
die (oder besser: eine) Zuordnungsregel
x
∈R
1 ⇔ˆ h(x) > 0 , x
∈R
2 ⇔h(x) ˆ
≤0 .
Streudiagramm Beispiel 3.3.7 mit Trenngerade
blau: Merkmalsvektoren Klasse 1 ,
rot: Merkmalsvektoren Klasse 2 ;Rauten: Mittelwertvektoren.
Bayes sche Stichprobendiskriminanzregel (2 Klassen)
I
Beh. 3.3.9
Unter obigen Voraussetzungen 3.3.4 f¨ ur 2 Klassen gilt mit a-priori-Wahrscheinlichkeiten π
1, π
2mit der angepassten gesch¨ atzten Diskriminanzfunktion
h ˆ
1(x) = ˆ h(x)
−ln π
2π
1die
Bayessche Stichprobendiskriminanzregel
x
∈R
1 ⇔h ˆ
1(x) > 0 , x
∈R
2 ⇔h ˆ
1(x)
≤0 .
I
Bem.
M¨ oglicherweise werden die a-priori-Wahrscheinlichkeiten π
1, π
2auch aus der Stichprobe gesch¨ atzt (und in der gesch¨ atzten Diskriminanzfunktion statt π
1, π
2genutzt):
ˆ
π
1= n
1n
1+ n
2, π ˆ
2= n
2n
1+ n
2.
Streudiagramm Bsp. 3.3.7 mit Bayes scher Trenngerade
blau: Merkmalsvektoren Klasse 1 ,
rot: Merkmalsvektoren Klasse 2 ;gestrichelt: Trenngerade
Bayessche Diskriminanzregel;
gr¨un: Erwartungswertvektoren, Trenngeraden theoretische Verteilungen.
3.4 Einige relevante statistische Tests 3.4.1 Test auf Normalverteilung
I
Verschiedene Apassungstests k¨ onnen f¨ ur multivariate Daten verallgemeinert werden. Dies trifft auch auf die Fragestellung der Uberpr¨ ¨ ufung einer vorliegenden Normalverteilung zu.
I
Eine Variante einer Verallgemeinerung f¨ ur multivariate Daten des
Shapiro-Wilk-Testes auf Normalverteilung kann mit dem R-Paket
mvnormtest (Befehl mshapiro.test()) realisiert werden.
Testergebnisse f¨ ur Beispiel 3.3.7
I
1. Lernstichprobe (vgl. R-Skript f¨ ur Bezeichnungen)
> mshapiro.test(t(bsp3 3 7 lk1)) Shapiro-Wilk normality test data: Z
W = 0.9108, p-value = 0.2865
I
2. Lernstichprobe
> mshapiro.test(t(bsp3 3 7 lk2)) Shapiro-Wilk normality test data: Z
W = 0.95874, p-value = 0.7992
I
Zusammengefasste Lernstichprobe
> mshapiro.test(t(bsp3 3 7 lg)) Shapiro-Wilk normality test data: Z
W = 0.96272, p-value = 0.7395
3.4.2 Test auf Kovarianzhomogenit¨ at
I
Voraussetzung zur Anwendung der MANOVA (siehe 3.4.3) und der Nutzung der oben angegebenen Diskriminanzfunktionen ist die Gleichheit (Homogenit¨ at) der Kovarianzmatrizen. Ein m¨ oglicher Test dazu f¨ ur normalverteilte Daten ist der M-Test von
Box.
I
Voraussetzung Die Daten sind p-dimensional normalverteilt.
I
Hypothesen
I Die Kovarianzmatrizen sind in alleng Klassen gleich, H0 : Σ
1=. . .=Σ
g =Σ.
I Es gibt unterschiedliche Kovarianzmatrizen in deng Klassen, HA : es gibt j 6=l : Σ
j 6=Σ
l.
I
Sch¨ atzer f¨ ur Teilstichproben µ ˆ
j:= X
j= 1 n
jnj
X
k=1
X
jk; f¨ ur Kovarianzmatrix S
j:= 1
n
−1
nj
X
(X
jk−X
j)(X
jk−X
j)
T.
Fortsetzung M-Test von Box
I
Gepoolte Kovarianzmatrix
˜ S := 1 n
−g
g
X
k=1
(n
k−1)S
k=: 1 n
−g W , W ist die Inner-Gruppen-Streumatrix, auch Inner-Gruppen- SPP-Matrix (within groups
sum of squares andproducts).I
Testgr¨ oße
T = (1
−c)
"
(n
−g ) ln det ˜ S
−g
X
k=1
(n
k −1) ln det S
k#
= (1
−c)
g
X
k=1
(n
k −1) ln det
S
−1kS ˜
mit c = 2p
2+ 3p
−1 6(p + 1)(g
−1)
g
X
k=1
1
n
k −1
−1 n
−g
!
.
Fortsetzung M-Test von Box
I
Asymptotische Verteilung
T
asymt.∼χ
2p(p+1)(g−1)/2Die Approximation ist gut, falls n
k> 20 , g
≤5 , p
≤5 .
I
Kritischer Bereich K =
nt
∈R: t > χ
2p(p+1)(g−1)/2 ; 1−αo
.
Testergebnisse f¨ ur Beispiel 3.3.7
(vgl. R-Skript f¨ ur Berechnungen)
I
p(p + 1)(g
−1)/2 = 3 ;
I
χ
2p(p+1)(g−1)/2 ; 1−α≈7.82 f¨ ur α = 0.05 ;
I
c
≈0.205 ;
I
s
1 ≈
1.102 0.486 0.486 1.907
, s
2 ≈
0.528 0.038 0.038 0.962
,
˜ s
≈
0.925 0.348 0.348 1.616
;
I
det S ˜
≈1.374 , det S
1 ≈
1.865 , det S
2≈
0.506 ;
I
Realisierungswert der Testgr¨ oße t
≈0.990
⇒
t < χ
2p(p+1)(g−1)/2 ; 1−α, t
6∈K ,
H0wird nicht abgelehnt, es gibt
keine signifikanten Unterschiede zwischen den Kovarianzmatrizen.
3.4.3 Test auf Gleichheit der Erwartungswertvektoren
I
Bem.
Dies ist eine Aufgabenstellug der multivariaten Varianzanalyse (MANOVA). Analog zum univariaten Fall wird die Streuung innerhalb der Klassen verglichen mit der Streuung zwischen den Klassen.
I
Voraussetzungen
I Die Daten sindp-dimensional normalverteilt.
I Die Kovarianzmatrizen in deng Klassen stimmen ¨uberein, d.h.
Σ1=Σ
2=. . .=Σ
g=Σ.
I
Hypothesen
I Die Erwartungswertvektoren sind in alleng Klassen gleich (in diesem Fall ist die Diskriminanzanalyse nicht sinvoll),
H0 : µ1=. . .=µg.
I Es gibt unterschiedliche Erwartungswertvektoren in deng Klassen (in diesem Fall ist die Diskriminanzanalyse sinvoll),
H : es gibt j 6=l :µ 6=µ .
Forts. Test auf Gleichheit der Erwartungswertvektoren
I
Streuungsmatrix innerhalb der Klassen W :=
g
X
j=1
(n
j −1)S
j=
g
X
j=1 nj
X
k=1
(X
jk−X
j)(X
jk−X
j)
T;
I
Streuungsmatrix zwischen den Klassen B :=
g
X
j=1
n
j(X
j−X)(X
j −X)
Tmit X = 1 n
g
X
j=1 nj
X
k=1
X
jk;
I
totale Streuungsmatrix S
total:=
g
X
j=1 nj
X
k=1
(X
jk−X)(X
jk−X)
T;
I
Streuungszerlegung
S
total= W + B ;
Forts. Test auf Gleichheit der Erwartungswertvektoren
I
Testgr¨ oßen basieren z.B. auf der Spur der Matrix W
−1B oder auf Λ = det W
det B + W = det
I+ W
−1B
−1.
I
Testgr¨ oße im Zweigruppenfall (g = 2) T = (n
−p
−1)n
1n
2pn(n
−2) (X
1−X
2)
TS ˜
−1(X
1−X
2) .
I
Kritischer Bereich
K =
{t ∈R: t > F
p;n−p−1; 1−α}.
Testergebnisse f¨ ur Beispiel 3.3.7
(vgl. R-Skript f¨ ur Berechnungen)
I
F
p;n−p−1; 1−α≈3.89 f¨ ur α = 0.05 .
I
Realisierungswert der Testgr¨ oße t
≈4.364 .
⇒
t
∈K ,
H0wird abgelehnt, es gibt signifikante Unterschiede
zwischen den Erwartungswertvektoren.
3.5 Wahrscheinlichkeit f¨ ur Fehlklassifikation
I
Bei bekannten Verteilungen kann man Wahrscheinlichkeiten f¨ ur eine Fehlklassifikation (theoretisch) berechnen.
I
Ist
p
ij:=
Z
Ri
L(j ; x)
dx=
ZRi
f
j(x)
dxdie Wahrscheinlichkeit daf¨ ur, dass ein Merkmalstr¨ ager aus der j -ten Klasse der i -ten Klasse zugeordnet wird, dann ist p
ijf¨ ur i
6=j eine Fehlklassifikationswahrscheinlichkeit .
I
Die Fehlklassifikationswahrscheinlichkeiten sollten m¨ oglichst klein sein.
I
Sind die Verteilungen der Populationen Π
1, . . . , Π
gnicht bekannt, k¨ onnen verschiedene Ans¨ atze zur Sch¨ atzung dieser
Wahrscheinlichkeiten genutzt werden.
3.5.1 Nutzung gesch¨ atzter Parameter
I
Bsp. Geg. g = 2 , Π
i=
Np(µ
i, Σ) , i = 1, 2 .
I
Die Diskriminanzfunktion (bei bekannten Parametern) lautet dann h(x) = (µ
1−
µ
2
)
TΣ
−1x
−1 2 (µ
1
+ µ
2
)
, x
∈Rp.
I
F¨ ur einen Zufallsvektor X aus Π
1gilt h(X)
∼N11
2 ∆
2, ∆
2, ist X aus Π
2gilt h(X)
∼N1
−
1 2 ∆
2, ∆
2
, mit
∆
2:= (µ
1−µ
2)
TΣ
−1(µ
1−µ
2)
(Quadrat des
Mahalanobis-Abstandes zwischen µ
1und µ
2) .
Fortsetzung Beispiel
I
Hieraus folgt
p
12=
P(h(X)> 0|Π
2) = Φ
−
∆ 2
= p
21=
P(h(X)< 0|Π
1) .
I
Mit gesch¨ atzten Parametern erh¨ alt man mit
∆ ˆ
2= (x
1−x
2)
T˜ s
−1(x
1−x
2) und
˜ s = 1 n
1+ n
2−2
(n
1−1)s
1+ (n
2−1)s
2: ˆ
p
12= ˆ p
21= Φ
−∆ ˆ 2
!
.
I
F¨ ur Beispiel 3.2.5 bzw. 3.3.7 p
12= Φ
−√
1.5 2
!
= 0.2701 , p ˆ
12= Φ
−
1.684 2
= 0.1998 .
3.5.2 Resubstitutionsmethode
I
Prinzip Man wendet die aus einer Lernstichprobe konstruierte Diskriminanzregel auf die Lernstichprobe selber an und bestimmt die relative H¨ aufigkeit von Fehlklassifikationen.
I
Sei n
ijdie Anzahl der n
jIndividuen von Π
j, deren Merkmalsvektor x in R
iliegt, die also zu Π
izugeordnet werden m¨ ussen.
I
Dann ist eine Sch¨ atzung der indivuellen Fehlerraten gegeben durch ˆ
p
ij= n
ijn
j, i
6=j .
I
F¨ ur Beispiel 3.3.7 (ML-Diskriminanzregel, siehe Streudiagramm Folie 31)
n
12= 1 , n
21= 3 , p ˆ
12= 1
5 = 0.2 , p ˆ
21= 3
10 = 0.3 .
3.5.3 Cross-Validation-Prinzip (
” jack-knifing“)
I
Ausgangspunkt Die in 3.5.1 und 3.5.2 vorgestellten Methoden sind oft zu optimistisch, da diesselben Daten, die die
Diskriminanzregel definieren, zu deren Bewertung herangezogen werden.
I
Cross-Validation (Kreuzvalidierung) ist eine Methode zur Bewertung von statistischen Verfahren, bei der Teile des (bekannten)
Datenmaterials nicht zur Konstruktion des Verfahrens, sondern zu seiner Kontrolle genutzt werden.
I
Wird jede einzelne Beobachtung einmal zur Kontrolle genutzt,
spricht man auch von einer Leave-One-Out-Methode oder
Leave-One-Out-Kreuzvalidierung.
Leave-One-Out-Methode
I
Geg. x
T= (x
T1, . . . , x
Tj, . . . , x
Tg) .
I
Vorgehen
(i) Streiche r−tes Datum xjr aus x
j.
(ii) Bestimme die Diskriminanzregel mit den verbleibenden n−1 Daten, das Ergebnis sind die Regionen R1(jr), . . . ,Rg(jr).
(iii) Wende die Diskriminanzregel auf das gestrichene Datum xjr an;
mache dies nj mal, d.h. f¨ur r= 1, . . . ,nj.
(iv) Sei n∗ij die Anzahl der F¨alle, bei denen xjr aus Πj in Ri(jr) liegt, d.h. Πi zugeordnet werden w¨urde.
(v) Die gesuchten Sch¨atzungen sind ˆ pij =n∗ij
nj .
3.6 Fisher s lineare Diskriminanzfunktion
I
Bem. Bei dieser Methode wird der Verteilungstyp der Populationen Π
1, . . . , Π
gnicht vorausgesetzt.
I
Prinzip Man finde eine lineare Funktion der Datenmatrix, d.h.
einen Vektor a
∈Rpmit
z :=
x
1a
.. . x
ga
=
z
1.. . z
g
(z
j ∈Rnj) , so dass in z
Streuung zwischen den Gruppen Streuung innerhalb der Gruppen
= max
!.
Dann ist die Variation zwischen den Gruppen so groß wie m¨ oglich
und die Variation innerhalb der Gruppen so klein wie m¨ oglich und
Fisher s lineare Diskriminanzfunktion
I
Man kann zeigen, dass diese Aufgabenstellung ¨ aquivalent ist zu a
Tb a
a
Tw a
= max
! a.
(b und w sind die entsprechenden Ausdr¨ ucke f¨ ur die Variation zwischen (between) und innerhalb (within) der Gruppen, siehe 3.4.3.) Man kann weiterhin zeigen, dass die L¨ osung dieses Problems folgendermaßen bestimmt werden kann.
I
Def.
Sei a
∗6=0
pein Eigenvektor zum gr¨ oßten Eigenwert von w
−1b .
Die Funktion
Rp 3x
7→(a
∗)
Tx
∈Rheißt
Fishers lineare
Diskriminanzfunktion.
Diskriminanzregel
Diskriminanzregel
x wird der Klasse i zugeordnet, d.h. x
∈R
i, falls f¨ ur alle j
6=i gilt
|(a∗