PARTIALLY LINEAR REGRESSION
MODEL
Wolfgang Hardle
1, Hua Liang
12and Volker Sommerfeld
1Institut fur Statistik und Okonometrie
and Sonderforschungsbereich 373 Humboldt-Universitat zu Berlin
D-10178 Berlin, Germany
1Institute of Systems Sciences
andBeijing 100080, China
2Abstract
Consider the semiparametric regression model Yi =XiT+g(Ti)+i (i= 1:::n), where (XiTi) are known and xed design points, is a p;dimensional unknown parameter,g() is an unknown function on 01]i are i.i.d. random errors with mean 0 and variance 2. In this paper we rst construct bootstrap statisticsn and2n by resampling. Then we prove that, for the estimatorsnandn2 of the parameters and
2
p
n(n;n) andpn(n;)pn(n2 ;2n) andpn(n2;2) have the same limit distributions, respectively. The advantage of the bootstrap approximation is explain.
The feasibility of this approach we also show in a simulation study.
Key Words and Phrases:
Semiparametric regression model, bootstrap approximation, asymptotic normality.AMS 1991 subject classication:
Primary: 62G05 Secondary: 60F15.This research was supported by Sonderforschungsbereich 373 \Quantikation und Simula- tion Okonomischer Prozesse". The work of Hua Liang was partially supported by Alexander von Humboldt Foundation. The authors are extremely grateful to Dr. Michael Neumann for his many valuable suggestions and comments which greatly improved the presentation of the paper. Corresponding Author: Hua Liang, Institut fur Statistik und Okonometrie, Spandauerstr.1, D-10178 Berlin. Email:hliang@wiwi.hu-berlin.de.
1
Consider the model given by
Yi =XiT + g(Ti) +ii = 1::: (1) where Xi = (xi1:::xip)T(p 1) and Ti(Ti 2 01]) are known design points, = (1:::p)T is an unknown parameter vector and g is an unknown function, and 1:::n are i.i.d. random variables with mean 0 and unknown variance 2:
This model is important because it can be used in applications where one can assume that the responses Yi and predictorsXi is linear dependence, but nonlinearly related to the independent variables Ti. Engle, et al. (1986) studied the eect of weather on electricity demand. Liang, Hardle and Werwatz (1997) used the model to investigate the relationship between income and age from German data. From the point of theory, this model generalizes the standard linear model, by restricts multivariatenonparametric regression which is subject to "Curse of Dimensionality" and is hard to interpret. Therefore, there is a lot of literature studied this model recently. Heckman (1986), Speckman (1988), Chen (1988) considered the asymptotic normality of estimators of and 2: Later Cuzick (1992a, b) and Schick (1993) discussed asymptotic properties and asymptotic eciency for these estimators. Liang and Cheng (1993) discussed the second order asymptotic eciency of LS estimator and MLE of : The technique of bootstrap is a useful tool for the approximation of an unknown prob- ability distribution and therefore for its characteristics like moments or condence regions.
This approximation can be performed by dierent estimators of the true underlying distribu- tion that should be well adapted to the special situation. In this paper we use the empirical distribution function which puts mass of 1=n at each residual in order to approximate the underlying error distribution (for more details see section 2). This classical bootstrap tech- nique was introduced by B. Efron (for a review see e.g. Efron & Tibshirani, 1993). Note that for a hetereoscedastic error structure a wild bootstrap procedure (see e.g. Wu, 1986 or Hardle & Mammen, 1993) would be more appropriate.
Hong and Cheng (1993) considered bootstrap approximation of the estimators for the parameters in the model (1) in the case where fXiTii = 1:::ng are i.i.d. random variables andg() is estimated by a kernel smoother. The authors proved that their bootstrap approximation is the same as the classic methods, but failed to explain the advantage of
2
the bootstrap method, which will be discussed in this paper. We will construct bootstrap statistics of and 2, and studies their asymptotic normality when (XiTi) are known design points and g() is estimated by general nonparametric tting. Analytically as well as numerically we will show that the bootstrap techniques provide a reliable method to approximate the distributions of the estimates.
The eect of smoothing parameter is studied in a simulation study. Thereby it turns out that the estimators of the parametric part are quite robust against the choice of the smoothing parameter. More details can be found in section 3.
The paper is organized as follows. In the following we explain the basic idea for estimating the parameters and give the assumptions on the Xi and Ti. Section 2 constructs bootstrap statistics of and 2. In section 3 we present a simulation study in order to complete the asymptotic results. In section 4 some lemmas required later are proven. Section 5 presents the proof of the main result. For the convenience and simplicity, we shall employ C(0 < C <1) to denote some constant not depending onn but may assume dierent values at each appearance.
Generally there are two methods, backtting and local likelihood ones, to estimate the linear parameter. The asymptotic variance of the two estimates is the same. Here we adopt local likelihood method. Specically, x one estimates g() as a function of to obtain g(), which is a nonparametric estimation problem. Then letting g =b g(), one estimatesb the parametric component, and this is a parametric problem. The detailed discussions can be also found in Severini and Staniswalis (1994).
To estimate g for xed , let !ni(t) = !ni(tT1:::Tn) be positive weight functions depending only on the design points T1:::Tn: Assume fXi = (xi1:::xip)TTiYii = 1:::n:g satisfy the model (1). ^g(t) = Pnj=1!nj(t)(Yj ;XjT) is just the nonparametric estimate of g(t) for xed . Given the estimator ^g(t), an estimate of n, is obtained basing on Yi =XiT + ^g(Ti) +i for i = 1:::n:
Denote f
X
= (Xf1:::Xfn)T Xfi = Xi ;Pnj=1!nj(Ti)XjY
f = (Ye1:::Yen)T Yei = Yi ;P
n
j=1!nj(Ti)Yj: Then the estimate n can be expressed as n = (f
X
TfX
);1fX
TY
fIn addition, the estimate of 2, n2 is naturally dened as 2n= 1nXi=1n (Yi;XiTn;gn(Ti))2
3
which is equal to 1nPni=1(Yei;XfiTn)2: Where gn(t) =Pnj=1!nj(t)(Yj;XjTn) is the estimate of g(t).
In the following we list the sucient conditions for our main result.
Condition 1.
There exist functions hj() dened on 01] such thatxij =hj(Ti) +uij 1in 1j p (2) where uij is a sequence of real numbers which satisfy limn!1 1nPni=1ui = 0 and
lim
n!1
n1
n
X
i=1
uiuTi =B (3)
is a positive denite matrix, and limsup
n!1
a1n max
1k n
k
X
i=1
ui
<1 (4)
holds, where ui = (ui1:::uip)T andan=n5=6log;1n:
Condition 2.
g() and hj() are Lipschitz continuous of order 1.Condition 3.
The weight functions !ni() satisfy the following:(i) max
1in n
X
j=1
!nj(Ti) =O(1) (ii) max
1ijn
!ni(Tj) =O(bn) (iii) max
1in n
X
j=1
!nj(Ti)I(jTj;Tij>cn) =O(cn) where bn =n;2=3 cn=n;1=3logn:
These conditions are not more complicated than that given in related literature. They are usually needed for establishing asymptotic normality for the estimators of the parameters.
Specically, imposing Condition 1 in that we can lead 1=nf
X
TfX
converges to B. In fact, (2) of Condition 1 is parallel to the casehj(Ti) =E(xijjTi) and uij =xij ;E(xijjTi)
when (XiTi) are random variables. (3) is similar to the result of the strong law of large numbers for random errors. (4) is similar to the law of the iterated logarithm. More detailed discussions may be found in Speckman (1988) and Gao et al. (1995).
The weight functions satised the above condition 3 are presented in Liang, Hardle and Werwatz (1997). Interested readers please nd them there.
4
SULT
The statisticsnand n2 have asymptotic standard normal distributions under mild assump- tions. Our simulation studies indicate that the normal approximation does not work very well for small samples. Therefore in this section we propose a bootstrap method as an alternative to the normal asymptotic method.
In the semiparametric regression model the observable columnn;vector
^
of residuals is given by^
=
Y
;G
n;X
Tnwhere
G
n = fgn(T1):::gn(Tn)gT. Denote n = n1 Pni=1^i. Let ^Fn be the empirical dis- tribution of^
, centered at the mean, so ^Fn puts mass 1=n at ^i;n and R xd ^Fn(x) = 0:Given
Y
, let 1:::n be conditional independent with common distribution ^Fn let be the n;vector whose ith component is i, and letY
=X
Tn+G
n+ :Informally,
^
is obtained by resampling the centered residuals. AndY
is generated from the data, using the regression model with n as the vector of parameters and ^Fn as the distribution of the disturbance terms .So we have reason to dene the estimates of and 2 as follows, respectively, n= (f
X
TfX
);1fX
TfY
and 2n = 1nXi=1n (Yei ;XfiTn)2where Yei =Yi ;Pnj=1!nj(Ti)Yj
Y
f = (Ye1:::Yen)T:The bootstrap principle is that the distributions ofpn(n;n) andpn(n2 ;2n), which can be computed directly from the data, approximate the distributions of pn(n;) and
pn(n2 ;2), respectively. As will be shown later, this approximation is likely to be very good, provided n is large enough. This fact is stated as the following theorem.
Theorem 1.
Suppose conditions 1-3 hold. If E41 < 1 and max1inkuik C0 < 1: ThensupxP fpn(n;n)< xg;Pfpn(n;) < xg!0 (5) 5
and
supxP fpn(n2 ;n2)< xg;Pfpn(2n;2)< xg!0 (6) where and below P and E denote the conditional probability and conditional expection given
Y
:Now, we outline our proof of the theorem. First we decomposepn(n;) and pn(n; n) into three terms, and n2 and n2 into ve terms, respectively. Then we will calculate the tail probability value of each term. Some additional notations are introduced. = (1:::n)T = (e e1:::en)T ei = i ;Pnj=1!nj(Ti)j gei = g(Ti);Pnk =1!nk(Ti)g(Tk)
f
G
= (ge1:::gen)T: We have from the denitions of n and n, and 2n and n2pn(n;) = pn(f
X
TfX
);1(fX
TfG
+fX
T)e= pn(f
X
TfX
);1hXni=1
Xfigei;Xn
i=1
XfinXn j=1
!nj(Ti)jo+Xn
i=1
Xfiii
def= n(f
X
TfX
);1(H1;H2+H3):pn(n;n) = pn(f
X
TfX
);1(fX
TG
fn+fX
T )e= pn(f
X
TfX
);1hXni=1
Xfiegni;Xn
i=1
XfinXn j=1
!nj(Ti)j o+Xn
i=1
Xfii i
def= n(f
X
TX
f);1(H1 ;H2 +H3):Where
G
fn = (gen1:::genn)T with geni =gn(Ti);Pnk =1!nk(Ti)gn(Tk) for i = 1:::n:n2 = 1n
Y
fTfI;fX
(fX
TfX
);1X
fTgY
f= 1nT; 1
nT
X
f(fX
TX
f);1fX
T + 1nfG
TfI ;X
f(fX
TfX
);1fX
TgfG
;
2nf
G
TX
f(fX
TfX
);1fX
T + 2nfG
Tdef= I1;I2+I3;2I4+ 2I5: n2 = 1nf
Y
TfI;fX
(fX
TfX
);1X
fTgY
f= 1n T ; 1
n Tf
X
(fX
TfX
);1fX
T + 1nG
fnT(I;fX
(fX
TX
f);1fX
T)G
fn;
n2
G
fnTfX
(fX
TfX
);1X
fT + 2nfG
nTdef= I1 ;I2 +I3 ;2I4 + 2I5: 6
HereI is the identity matrix of order p. The following sections will prove that H1jH2j = oP(1) and H1jH2j = oP (1) and Ii = oP(n;1=2) and Ii = oP (n;1=2) for j = 1:::p and i = 2345:
We have up to now showed that the bootstrap method performs as least as well as the normal approximation with the error rate of op(1) and o(1), respectively. It is natural to expect that the bootstrap method should perform better than this however. Indeed, our numerical experience means that it is case. In fact, it is also true analytically as is shown in the following theorem.
Theorem 2.
Let Mjn() (2)] and Mjn() (2)] be the j;th moments of pn(n;) (pn(n2;2))] andpn(n;n) (pn(n2 ;n2))], respectively. Then under the conditions 1-3 and E61 <1 and max1inkuik C0 <1Mjn();Mjn() = OP(n;1=3logn) and Mjn(2);Mjn(2) =OP(n;1=3logn) for j = 1234:
The proof of theorem 2 can be completed by the arguments of Liang (1994) and similar procedures behind. We omit the details.
Theorem 2 indicates that the bootstrap distributions have much better approximation for the rst four moments for nandn2 , which are most important quantities in characterizing distributions. Indeed, by Theorem 1 and Lemma 1 given later, one can only obtain that
Mjn();Mjn() = oP(1) andMjn(2);Mjn(2) =OP(1) for j = 1234 in contrast to Theorem 2.
3 NUMERICAL RESULTS
In this section we present a small simulation study in order to illustrate the nite sample behavior of the estimator. We investigate the model
Yi =Xi + g(Ti) +i (7)
where g(Ti) =sin(Ti), = (15)0 and i Uniform(;0:30:3). The independent variables Xi = (Xi(1)Xi(2)) andTiare realizations of aUniform(01) distributed random variable. We analyze sample sizes of 3050100 and 300. For nonparametric tting, we use a Nadaraya- Watson kernel weight function with Epanechnikov kernel. We performed the smoothing with
7
sample size n=30
standardized observations
densities
-0.05 0.0 0.05
051015
• • • •• •• •••••
•
•
•
•
•
•
•
•
•
•
•• •• •
•
•
•
•
•
•
•
•
•
•
•
•
••
•• •
• • • • • •
Figure 1
: Plot of of the smoothed bootstrap density (lines), the normal ap- proximation (stars) and the smoothed true density (vertical lines).dierent bandwidths using some grid search. Thereby it turned out that the results for the parametric part are quite robust against the bandwidth chosen in the nonparametric part.
In the following we present only the simulation results for the parameter 2, those fore 1 are similar.
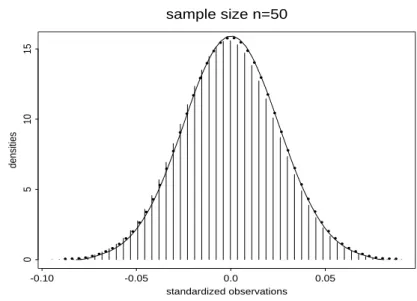
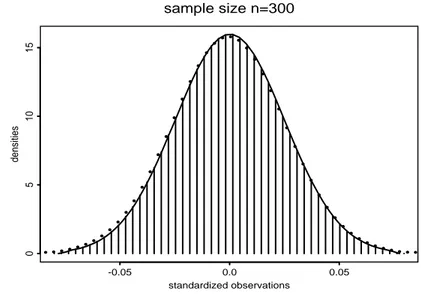
In gures 1 to 4 we plotted the smoothed densities of the estimated true distribution of
pn(b2 ;2)= withb b2 = 1nPni=1(~Yi ; ~XiTn)2 for sample sizes 30, 50, 100, 300. Addition- ally we added to these plots the corresponding bootstrap distributions and the asymptotic normal distributions, where we estimated the asymptotic variance 2B;1 by b2Bb;1 with B =b n1 Pni=1 ~XiT ~Xi and sigmab 2 dened above. It turns out that the bootstrap distribution and the asymptotic normal distribution well approximates the true one even for moderate sample sizes of n = 30.
4 SOME LEMMAS
Under the conditions of Theorem 1, Gao et al.(1995) obtained asymptotic normalities of n and 2n and convergence rate of gn, which are given in Lemma 1. Lemma 2 presents the limit of 1=nf
X
TfX
. Its proof is referred to Chen (1988) and Speckman (1988). Lemma 3 provides the boundedness for g(Ti);Pnk =1!nk(Ti)g(Tk) and geni(Ti);Pnk =1!nk(Ti)genk(Tk), whose proof is immediate. Lemma 4 shows that pnH1j and pnH1j are O(n1=3logn) in dierent probability senses. Lemma 5 gives a general result for nonparametric regression,8
sample size n=50
standardized observations
densities
-0.10 -0.05 0.0 0.05
051015
• • • • •• ••••••
•
•
•
•
•
•
•
•
•
•
••• • •
•
•
•
•
•
•
•
•
•
•
•
•
••
•• • •• • • • •
Figure 2
: Plot of of the smoothed bootstrap density (lines), the normal ap- proximation (stars) and the smoothed true density (vertical lines).sample size n=100
standardized observations
densities
-0.05 0.0 0.05
051015
• • • • •• •• •
•••
•
•
•
•
•
•
•
•
•
•
••• • •
•
•
•
•
•
•
•
•
•
•
•
•
••
• •• • • • • • •
Figure 3
: Plot of of the smoothed bootstrap density (lines), the normal ap- proximation (stars) and the smoothed true density (vertical lines).9
sample size n=300
standardized observations
densities
-0.05 0.0 0.05
051015
• • • • •• •••••
•
•
•
•
•
•
•
•
•
•
••• • •
•
•
•
•
•
•
•
•
•
•
•
•
••
• •• • • • • •
Figure 4
: Plot of of the smoothed bootstrap density (lines), the normal ap- proximation (stars) and the smoothed true density (vertical lines).whose proof is strongly based on an exponential inequality for bounded independent random variables, that is, Bernstein's inequality. It will be used in the remainder of this section.
Lemma 1.
Suppose the conditions of Theorem 1 hold. Thenpn(n;)!N(02B;1) sup
t201]
jgn(t);g(t)j=Op(n;1=3logn) (8) and
pn(n2;2)!N(0V ar(21)) (9)
Lemma 2.
If conditions 1-3 hold. Then limn!1
n1f
X
TfX
=BLemma 3.
Suppose that conditions 2 and 3 (iii) hold. Then max1in
g(Ti);Xn
k =1
!nk(Ti)g(Tk)=O(n;1=3logn) max
1in
geni(Ti);Xn
k =1
!nk(Ti)genk(Tk)=OP(n;1=3logn)
The same conclusion as the rst part holds for hj(Ti);Pnk =1!nk(Ti)hj(Tk) for j = 1:::p:
Lemma 4.
Suppose conditions 1-3 hold and Ej1j3 <1. ThenpnH1j =O(n1=2log;1=2n) and pnH1j =O(n1=2log;1=2n) for j = 1:::p (10) 10
Proof.
Their proofs can be completed by the same methods for Lemmas 2.4 and 2.5 of Liang (1996). We omit the details.(
Bernstein's Inequality
)Let V1:::Vn be independent random variables with zero means and bounded ranges: jVijM: Then for each > 0PfjXn
i=1
Vij> g2expn;2=2(Xn
i=1
varVi+M)]o:
Lemma 5.
Assume that condition 3 holds. Let Vi be independent with mean zero and EV14 <1: Thenmax
1in
n
X
k =1
!nk(Ti)Vk=OP(n;1=4log;1=2n):
Proof.
Denote Vj0 = VjI(jVjjn1=4) and Vj00 = Vj ;Vj0 for j = 1:::n: Let M = Cbnn1=4. From Bernstein's inequalityPnmax
1in
n
X
j=1
!nj(Ti)(Vj0;EVj0)> C1n;1=4log;1=2no
n
X
i=1
PnXn
j=1
!nj(Ti)(Vj0;EVj0)> C1n;1=4log;1=2no
2nexpn; C1n;1=2log;1n
P
n
j=1!2nj(Ti)EVj2+ 2cnbnlog;1=2n
o
2nexpf;C12C logngCn;1=2 for some largeC1 > 0:
This and Borel-Cantelli Lemma imply that max
1in
n
X
j=1
!nj(Ti)(Vj0;EVj0)=OP(n;1=4log;1=2): (11) On the other hand, from condition 3(ii), we know
max
1in
n
X
j=1
!nj(Ti)(Vj00;EVj00) max
1k n
max
1in
j!nk(Ti)jXn
j=1
jVjj=OP(n;2=3) and
max
1in
n
X
j=1
!nj(Ti)EVj00 max
1k n
max
1in
j!nk(Ti)jXn
j=1
n;1EjVjj4
Cn;2=3logn max
1in
EjVij4
= o(n;1=4log;1=2n): (12)
11
Combining the results of (11) to (12), we obtain max
1in
n
X
k =1
!nk(Ti)Vk=OP(n;1=4log;1=2n): (13) This completes the proof of Lemma 5.
Lemma 6.
Suppose conditions 1-3 hold and Ej1j3 <1. ThenpnH2j =o(n1=2) and pnH2j =o(n1=2) for j = 1:::p
Proof.
Denote hnij =hj(Ti);Pnk =1!nk(Ti)hj(Tk): Observe the fact,pnH2j = Xn
i=1 n
n
X
k =1
xek j!ni(Tk)oi
= Xn
i=1 n
n
X
k =1
uk j!ni(Tk)oi+Xn
i=1 n
n
X
k =1
hnk j!ni(Tk)oi
; n
X
i=1 h
n
X
k =1 n
n
X
q =1
uq j!nq(Tk)o!ni(Tk)ii
Using conditions 3 (i) and (ii) and the remark in Lemma 3, we can deal with each term as (13) by letting Vi = i in Lemma 5. The above each item can be proved to be oP(n1=2) by using Lemma 5 and the argument for proving Lemma 5. The same technique is also suggested to pnH2j: We omit the details.
Lemma 7.
Under the conditions of Lemma 5. In=oP(n1=2) where In=Xni=1 X
j6=i
!nj(Ti)(Vj0;EVj0)(Vi0;EVi0):
Proof.
Letjn=hn2=3log2ni ( a] denotes the integer portion of a:) Aj =nh(j;1)njn i+ 1 :::h
jn
jn
io Acj = f12:::ng;Aj and Aji =Aj ;fig: Observe that In can be decomposed as follows,
In = Xjn
j=1 X
i2A
j X
k 2A
j i
!nk(Ti)(Vk0;EVk0)(Vi0;EVi0) +Xjn
j=1 X
i2A
j X
k 2A c
j
!nk(Ti)(Vk0;EVk0)(Vi0;EVi0)
def= Xjn
j=1
Unj+Xjn
j=1
Vnj
def= I1n+I2n: (14)
12
Where
Unj = X
i2A
j
pnij(Vi0;EVi0)def= X
i2A
j
unij Vnj = X
i2Aj
qnij(Vi0;EVi0)def= X
i2Aj
vnij and
pnij = X
k 2A
j i
!nk(Ti)(Vk0;EVk0) qnij = X
k 2A c
j
!nk(Ti)(Vi0;EVi0):
Notice that fvniji 2 Ajg are conditionally independent random variables given Enj =
fVkk 2 Acjg with E(vnijjEnj) = 0 and E(vnij2 jEnj) 2(max1injqnijj2) def= 2qnj2 for i2Aj and satisfy max1injvnijj2n1=4qnj for qnj = max1injqnijj:
On the other hand, by the same reason as that for Lemma 5, qn = max
1jjn
jqnjj= max
1jjn
max
1in j
X
k 2A c
j
!nk(Ti)(Vk0;EVk0)j
= OP(n;1=4log;1=2n)
Denote the numbers of the elements in Aj by #Aj: By applying Bernstein's inequality, we have, for j = 1:::jn
PnjVnjj> C
pn
plognjn
EnjoC exp
(
;
Cn(log;1n)jn;2 2qn2#Aj +jn;1n1=4qn
)
Cn;1=2:
It follows from the bounded dominant convergence theorem, the above fact and #Aj jnn that
PnjVnjj> C
pn
plognjn
o
C exp
(
;
Cjn;2
2qn2njn;1+jn;1n1=4qn
)
Cn;1=2 for j = 1:::jn: Then
I2n =oP(pn): (15)
Now we consider I1n: Note that fVk1 k ng are i.i.d. random variables, and the denition of Unj we know that
PfjI1nj > Cpn(log;1=2n)g Cn(log;1n)E
8
<
: j
n
X
j=1
Unj
9
=
2
13
= Cn(log;1n)Xjn
j=1
EUnj4 + Xjn
j
1 6=j
2
EUnj21EUnj22
Cn(log;1n)jn2(#Aj)2b4nhE(V10;EV10)4 +fE(V10;EV10)2g2i
Cn;1=2: (16)
HenceI1n =oP(pn). Combining (14), (15) with (16), we complete the proof of Lemma 7.
5 PROOF OF THEOREM 1
In this section we present the proof of Theorem 1. First, we prove (5). From (10) and Lemma 6, we only need to prove pn(f
X
TfX
);1fX
T converges in distribution to a k;variate normal random variate with mean 0 and covariance matrix2B;1:Let qii be the ith diagonal element of the matrix f
X
(fX
TfX
);1X
fT. According to propo- sition 2.2 of Huber (1973), if we know maxiqii ! 0 as n ! 1, then pn(fX
TfX
);1fX
T is asymptotically normal. Since the covariance matrix of pn(fX
TfX
);1fX
T is given by n(fX
TfX
);1R u2dFbn(u). Recall the denition of Fbn(u) and the result given in Lemma 2, the asymptotic variance of pn(n;n) is 2B;1:We now prove maxiqii!0. Sincen;1(f
X
TX
f)!B by Lemma 2, it follows from Lemma 3 of Wu (1981) that maxiqii!0: This completes the proof of (5).Next, we will prove (6). First we continue to give the following preliminary results. In Lemma 5, letting Vi be i, E and P be E and P , then we have
max
1in
n
X
k =1
!nk(Ti)k =OP (n;1=4log;1=2n):
This and Lemma 3 and the fact
j
pnI3jCpn max
1in n
gn(Ti);Xn
k =1
!nk(Ti)gn(Tk)2+Xn
k =1
!nk(Ti)k 2o lead that jpnI3j=oP (1):
Using the similar arguments as for proving pn(f
X
TfX
);1fX
T ! N(02B;1) one can conclude thatpnI2 =oP (1) pnI4 =oP (1):
Now, we consider I5. We decomposeI5 into three terms, and prove each term tends to zero.
More precisely,
I5 = 1nnXi=1n genii ;Xn
k =1
!ni(Tk)k2;Xn
i=1 n
X
k 6=i
!ni(Tk)i k o 14