Fitting simulated random events to experimental histograms by means of parametric models
Oliver Kortner
a,*, Cˇrtomir Zupan W i W
baMax-Planck-Institut fur Physik, F. ohringer Ring 6, D-80805 M. unchen, Germany.
bLudwig-Maximilians-Universitat M. unchen, Am Coulombwall 1, D-85748 Garching, Germany.
Received 12 April 2001; received in revised form 13 January 2003; accepted 17 February 2003
Abstract
Classical chi-square quantities are appropriate tools for fitting analytical parameter-dependent models to (multidimensional) measured histograms. In contrast, this article proposes a family of special chi-squares suitable for fits with models which simulate experimental data by Monte Carlo methods, thus introducing additional randomness. We investigate the dependence of such chi-squares on the number of experimental and simulated events in each bin, and on the theoretical parameter-dependent weight linking the two kinds of events. We identify the unknown probability distributions of the weights and their inter-bin correlations as the main obstacle to a general performance analysis of the proposed chi-square quantities.
r
2003 Elsevier Science B.V. All rights reserved.
PACS: 02.50.Ph; 02.50.Sk; 07.05.Kf
Keywords: Chi-squares; Variances of simulated histograms; Maximum likelihood
1. Introduction
1.1. Need for chi-squares in particle physics A typical experimental apparatus in particle physics detects events (statisticians would call them
‘‘elementary’’). In each event, either an ‘‘initial’’
(incoming) particle decays into several ‘‘final’’
(outgoing) particles or two initial particles collide
to produce the final particles. Ideally, the 3- momenta and spin directions of the initial particles are selected and those of the final particles are measured by the apparatus. Events may thus be represented by points in the (generally multi- dimensional) phase space [1–4], formed by the 3- momentum components and helicities of the final particles. We assume that the phase space has been reduced to its relevant coordinates by eliminating those on which, for symmetry reasons, the differential cross section or decay probability cannot depend. A simple example of the latter coordinates are the spin directions in case of unpolarized initial particles and of undetected helicities of the final particles.
*Corresponding author. Tel.: +4989-32354240; fax: +4989- 3226704.
E-mail address: oliver.kortner@cern.ch, kortner@mpp- mu.mpg.de (O. Kortner).
0168-9002/03/$ - see front matterr2003 Elsevier Science B.V. All rights reserved.
doi:10.1016/S0168-9002(03)00985-9
Theory may predict the result of the measure- ment, i.e. the differential cross section or decay probability but, in most interesting cases, the theoretical model contains parameters to be determined (statisticians say: estimated) from the comparison between experimental data and model predictions. The latter have to take into account the experimental conditions, in particular the imperfect resolution and acceptance of the appa- ratus. Nowadays, with ever more complex appa- ratus and ever more powerful computers, the final predictions of the model are most often obtained by Monte Carlo (MC) simulations. The compar- ison between model and experiment then requires a fit of the model density to the experimental density. Both consist of points in phase space but the simulated points are provided with parameter dependent weights from the theoretical model. The optimal values of the parameters are obtained by minimizing suitable random functions of the parameters such as different chi-square quantities or negative logarithms of maximum likelihood;
(statisticians call this procedure point estimation).
A standard computer program for this purpose is MINUIT [5] which also explores the form of the many-dimensional parameter valley in the vicinity of the optimal value of the parameter vector (interval estimation).
The principal motivation for this article stems from meson spectroscopy where the number of measured events from a single final channel may nowadays reach the order of magnitude of 10
6; only to be matched by a comparable or even larger number of simulated events (see, e.g. Ref. [6]).
However, often the dimension of the reduced phase space is also high and the experimental resolution quite good, so that the phase space density of events (defined as the number of events in the smallest experimentally identifiable element of phase space) may still be very low.
At such low densities, maximum likelihood estimation using individual (unbinned) events is the method of choice. Unfortunately, it has at least three disadvantages:
(1) It is not easily combined with a reliable correction for imperfect 3-momentum resolu- tion of the apparatus.
(2) It does not by itself furnish a quantitative measure of goodness-of-fit [7].
(3) On a present-day desk-top computer it is prohibitively time and memory consuming, if the number of events and their complexity are as high as or even higher than in reference [6].
1.2. Binning and the classical Neyman chi-square In order to avoid these disadvantages, one is tempted to sacrifice some of the information contained in the experimental data by grouping events into bins. Then the fit may be performed by minimizing a suitable chi-square quantity X
2: (Here, X should be read as a capital w and not as a capital x: We follow the modern trend of the statistical literature in reserving the symbol w
2for the w
2probability distribution.) A X
2quantity is defined as
X
2¼ X
i
X
i2ði ¼ 1; 2; y ; KÞ: ð1Þ The summation in Eq. (1) runs over all bins i ¼ 1; 2; y ; K where K is the total number of bins.
Here and later this should be understood whenever we use the symbol P
i
: When introducing a new X
2we shall mostly not explicitly repeat the standard equation (1). The characterizing index of X
i2(e.g. X
N;i2for the Neyman X
i2; see below) should be understood to symbolize the corre- sponding total X
2quantity as well (e.g. X
N2). The contribution X
i2of bin i to X
2may, for instance, have the form
X
i2¼ ðy
in
iÞ
2s
2ið2Þ
where n
iis the number of experimental events in bin i; y
iis the model prediction for n
i; and s
2iis some measure of the variance of y
in
i:
Typically, the number of bins K is chosen so large that the total number of experimental events N ¼ X
i
n
ið3Þ
is much larger than any individual bin content n
i:
Then we may safely assume that n
iis a Poisson
distributed random variable. Of course, y
idepends
on the parameter vector ~ y y ¼ ðy
1; y
2; y ; y
rÞ where r is the number of parameters but, as a rule, y
iis assumed not to explicitly depend on any random variable. Under this condition, we may convert expression (2) into the classical Neyman
1X
N;i2(also called ‘‘modified’’ X
i2) by setting
s
2i¼ n
ið4Þ
which leads to
1
X
N;i2¼ ðy
in
iÞ
2n
i: ð5Þ
1
X
N2is antedated by the classical Pearson
1X
P2; cf. Section 2; for the terminology, see e.g. Refs.
[8–10].
The lower index 1 on the left of the symbol X
N;i2in Eq. (5) indicates that this quantity which we call univariate depends on a single random variable n
i: The entire set of bin contents n
imay be considered as a single random vector ~ n n in a K-dimensional space
~ n
n ¼ fn
i; i ¼ 1; 2; y ; Kg ð6Þ so that referring to any
1X
2¼ P
i1
X
i2as a univariate chi-square quantity is also justified.
(Analogously we may define other K-dimensional vectors, e.g. ~ y y:)
1.3. Weights of events generated by Monte Carlo On the other hand, if y
ihas been obtained by a MC simulation, it does depend on the random number m
iof simulated events in bin i: Then we replace y
ið ~ y y Þ by f
ið ~ y yÞm
iwhere f
ið ~ y yÞ is a ~ y y-dependent weight obtained as the average of the theoretical weights f
ijð ~ y yÞ of individual MC events in bin i; i.e.
f
ið ~ y yÞ ¼ 1 m
iX
mij¼1
f
ijð ~ y yÞ ðj ¼ 1; 2; y ; m
iÞ: ð7Þ For typographic reasons we prefer the symbol f to the more common one w for ‘‘weight’’. Below we often simplify the notation by writing f
ijinstead of f
ijð ~ y yÞ and f
iinstead of f
ið ~ y yÞ: In complete analogy with Eq. (3), we define the total number of simulated events M by
M ¼ X
i
m
i: ð8Þ
The individual weights f
ijdepend on the method chosen to generate the MC events. Often they are generated by the GENBOD program [2] which also yields the corresponding weight f
ijðGÞpropor- tional to the phase space element [1] in the GENBOD set of coordinates; the proportionality constant, common to all bins, depends on global quantities such as M; N; the experimental lumin- osity, etc. The weight f
ijðGÞmay be multiplied by the norm jTj
2of the theoretical transition (i.e. reaction or decay) amplitude at the phase space point of the generated event, resulting in the final weight f
ij: Alternatively, f
ijðGÞmay be used by the hit-or-miss stratagem (also called acceptance–rejection meth- od [11]) to generate events distributed with phase space density; in that case f
ijis proportional to jT j
2:
1.4. Reconstruction of Monte Carlo events
We refer to the coordinates and the density adopted for the generation of the simulated events as the ‘‘MC generation space’’. Note that Eq. (7) does not imply a simple summation; in general, the summation is preceded by a tedious tracking and reconstruction needed to find the bin (or the garbage can) in which the generated event ends after all distortions have been taken into account.
Therefore, the ‘‘MC reconstruction space’’ is not equal to the MC generation space, in general. Only the MC reconstruction space has to be binned and used to class the experimental events as well. Note also that, in practice, the sizes and shapes of the bins depend on the choice of the phase space coordinates.
1.5. The randomness of weights
In general, not only m
ibut also f
iis a random
quantity: for finite values of m
iit becomes a matter
of chance how many simulated events fall into
regions of small and how many into regions of
large theoretical differential cross section (or decay
probability) in bin i . If m
i; n
i; and f
iare mutually
uncorrelated (see Sections 2 and 6), a simple
estimate of the variance Varð f
im
in
iÞ is provided
by the standard rules of error propagation in
the form
s
2i¼ f
i2Varðm
iÞ þ m
2iVarð f
iÞ þ Varðn
iÞ
¼ ð f
i2þ M
2;iÞm
iþ n
ið9Þ with
Varð f
iÞ ¼ 1
m
iM
2;i¼ 1 m
iðm
i1Þ
X
mij¼1
ð f
ijf
iÞ
2" # :
ð10Þ Of course, this estimate is possible only under the condition m
iX 2: Remember that Varð f
iÞ and M
2;iare functions of ~ y y: Note that M
2;iis an unbiased estimator of the variance of the probability distribution of the weights f
ijin bin i: In Section 6 we shall define this variance as the second central moment M
2;i(cf. Eq. (87)).
1.6. The case m
ip1
If m
ip 1; Eq. (10) cannot be used, and for m
i¼ 0 also Eq. (7) is meaningless. In both cases a straightforward remedy is to increase M or decrease K (or both). However, if none of these solutions is acceptable, an approximate one might be offered by generating additional events only in bins which are likely to contribute to bin i; and to evaluate f
iwith those among them which end up in bin i after reconstruction. However, they should not be added to the total sample of M originally simulated events, or else the probability distribu- tion of m
iwould be modified in a way difficult to control. Obviously, this prescription is applicable only to cases when only a few out of the total number of K bins contain no simulated events and when the experimental resolution is good enough so that any bin with m
i¼ 0 requires additional generation only in a small portion of the available MC generation space.
1.7. Nonrandom weights and the bivariate Neyman chi-square
For most of the present article, i.e. until its Section 6, we assume
M
2;i5 f
i2: ð11Þ
The main reason for this preliminary assumption are the unknown probability distributions of the random weights f
ij: They depend on the particular theoretical model describing a specific experiment, as well as on the boundaries of the bins, thereby precluding as detailed investigations of different chi-square quantities as are feasible if the random nature of the weights f
imay be neglected.
Under the assumption (11), Eq. (9) reduces to s
2i¼ f
i2m
iþ n
i: ð12Þ We define
2
X
N;i2¼ ð f
im
in
iÞ
2f
i2m
iþ n
ið13Þ
which depends on two random quantities m
iand n
i: We refer to such
2X
i2and to the corresponding
2
X
2quantities as bivariate and label them by a lower left index 2. The subscript N reminds us that expression (13) is an adaptation of the classical univariate Neyman
1X
N;i2; designed to take into account the statistical uncertainties of both the experiment and the simulation (provided assump- tion (11) is valid). A more convincing justification of Eq. (13) is to be found in Section 2 and Appendix B.
1.8. The classical Baker–Cousins chi-square Nearly two decades ago, Baker and Cousins [9]
have advocated the use of chi-square quantities obtained from ratios of likelihoods. (Note that their symbol m m ~ has a different meaning from ours.) Specifically, for Poisson-distributed binned data they highlight
1
X
l2¼ X
i
1
X
l;i2ð14Þ
with
1
X
l;i2¼ 2½y
in
iþ n
ilnðn
i=y
iÞ ð15Þ as a convenient chi-square quantity for point estimation, interval estimation, and goodness-of- fit testing. (In Ref. [9]
1X
l2is denoted by w
2l;p; p stands for Poisson.) Contrary to the classical Neyman
1X
N;i2of Eq. (5), expression (15) remains finite even if n
i¼ 0; and it is easy to ensure that
1
X
l2‘‘preserves the area’’, i.e., that the fitted total
number of events equals their measured number.
The Particle Data Group has been independently recommending
1X
l2in the prestigious Review of Particle Physics, starting with its 1988 issue [12].
However,
1X
l2as defined above behaves as a classical likelihood-ratio chi-square only for nonrandom y
i: Therefore, it is not optimally suited for the case of greatest interest in modern particle physics, that of theoretical predictions obtained by MC simulations.
1.9. Related work
The problem of fitting experimental histograms by randomly simulated model histograms has been previously discussed by Schmidt et al. [13] from a more practical standpoint than ours, but without taking into account the statistical uncertainties of the simulation in the fitting algorithm itself. We recommend their paper and, of course, that of Baker and Cousins as an additional introduction to the present article. A more sophisticated method than ours to take into account the random nature of theoretical predictions in the fitting algorithm has been proposed by Eberhard et al.
[14] for the special case of an adjustable linear superposition of several model distributions, each of them produced by a parameter-free MC simulation. An informative and original but quite condensed review article on the subject by Zech [15] has unfortunately remained unpublished. It reviews also unfolding, i.e. the experimentalist’s attempt to correct the measured data for imperfect acceptance and resolution of the apparatus before presenting them to the theorist (see also Ref. [16]).
We assume throughout our article that it is the job of the theorist to take experimental imperfections into account in the simulation—a less desirable (especially from the theorist’s point of view) but often unavoidable alternative to unfolding.
1.10. Preview of the present article
The purpose of the present article is to introduce a special family of bivariate chi-square quantities which take into account the random nature of both the experimental data and their theoretical simulations. They are asymptotically equivalent and w
2distributed. They differ at finite values of m
iand n
ibut they all remain finite when any of these bin contents vanish. We consider in more detail a few special chi-squares which exhibit scaling properties making their presentation relatively simple, and we discuss their characteristics at small values of m
iand n
i: In a subsequent article II [17] we shall try to correlate these characteristics with the suitability of the corresponding chi- square quantities for goodness-of-fit tests and with their performance in fitting the area of the histogram. At the end of the present article we convert the bivariate chi-square quantities into trivariate ones by multiplying them with simple bin-dependent correction factors which take in a primitive way into account the statistical fluctua- tions of the weights f
i:
2. More on the bivariate Neyman chi-square 2.1. Statistical independence of bin contents
In the preceding section we have tacitly assumed that the K K covariance matrix S [18] is diagonal with the elements s
2i: This is certainly true before the fit, provided the systematic errors are negligible and provided the boundaries of the bins are chosen without regard to the results of either the experiment or the simulation. Then the bin contents n
iare statistically independent of the bin contents m
jand the weights f
jð ~ y y Þ; for any possible values of i and j: Any triplet m
i; n
i; f
ið ~ y yÞ is statistically independent of another triplet m
j; n
j; f
jð ~ y yÞ with iaj: The weight f
ið ~ y yÞ is not independent of m
i; as is evident from Eq. (7). However, m
iand f
ið ~ y yÞ are not correlated, since the latter is an unbiased estimate of the expectation value of f
ið ~ y yÞ for any value of ~ y y that leads to real nonnegative weights f
ijð ~ y yÞ; and for any integer value of m
i> 0;
see the next subsection for a justification of this statement and Section 1.6 for a possible treatment of the case m
i¼ 0: Further comments on systema- tic errors are deferred to Section 2.3.
2.2. Expectation values and ‘‘true’’ values of random quantities
In statistics it is customary to contemplate a
countably infinite set O of statistically independent
but otherwise equal experiments and simulations.
In simple cases, it is feasible but time-consuming to realize an approximation to O by a set O
finwith a finite but preferably large number N
Oof elements.
In the set O; the content m
ior n
iof a given bin i is an ‘‘independent identically distributed (i.i.d.)’’
random variable. With respect to this set we define the expectation values
m
iEðm
iÞ ¼
deflim
NO-N
1 N
OX
NO1
m
i;
n
iEðn
iÞ ¼
deflim
NO-N
1 N
OX
NO1
n
i: ð16Þ
Note that in Eqs. (16) the summations extend over the elements of the set O
finand not over the bins i:
Henceforth, the symbol E will always indicate an expectation value with respect to the set O:
We assume the distributions of m
iand n
ito be Poisson, i.e. of the form
Pðm
ijm
iÞ ¼ e
mim
miim
i! ; Pðn
ijn
iÞ ¼ e
nin
niin
i! : ð17Þ The expectation values m
iand n
iare positive nonrandom and, in general, nonvanishing real numbers. (If the theory is sensible and the simulation correct, m
iand n
ifor a given bin i can vanish only together and only if the experimental acceptance vanishes for bin i: In this case, bin i may simply be omitted from further considera- tion.) Because the set O is approximately realiz- able, both m
iand n
i—though rarely known in practice—are physically measurable quantities, in principle. If systematic errors in the counting of events and assigning them to the particular bin i are avoided or corrected for, m
iand n
imay as well be called the true values of m
iand n
i; respectively.
Similarly to m
iand n
i; we can define the expectation values / f
iS E½f
ið ~ y yÞ which are non- random positive functions of ~ y y: However, we shall have little use for these quantities except to justify the statement in the preceding subsection about the absence of a correlation between m
iand f
i: Assume that in a particular element of the set O the value of m
iis larger than m
i; since f
ið ~ y yÞ of Eq. (7) is an unbiased estimator of / f
iS ; it is on the average equally probable that the correspond- ing value of f
i/ f
iS is positive or negative, i.e.
E½ð f
i/ f
iS Þðm
im
iÞ ¼ 0 which means that m
iand f
iare not correlated. As an illustration, consider f
i¼ P
mij¼1
f
ij=ðm
iþ xÞ with x being any positive real number. This f
iis a consistent but biased estimator of the expectation value / f
iS ; it is positively correlated with m
ifor nonvanishing values of x: Incidentally, as suggested in Section 1.6, it is perfectly possible (only time-consuming) to find f
iindependently of the MC simulation serving to fit the experimental data, thus making f
itotally independent of m
i:
Provided m
ia 0; we can define the true values f
iof f
iby
f
idef¼ n
im
i: ð18Þ
They are also positive real numbers but they do not depend on ~ y y: (In the genuinely bivariate case of model predictions obtained by MC simulations, f
icould vanish only in case of a wrong simulation yielding m
i> 0 in spite of n
i¼ 0 — or diverge if the wrong simulation yields m
i¼ 0 in spite of n
i> 0: As for the univariate limit f
i-0; m
i- N with finite n
i¼ f
im
i; see Appendix A.) Note, though, that f
icannot be defined as Eðn
i=m
iÞ: The latter expecta- tion value does not even exist, since m
i¼ 0 is among the possible values of the random variable m
i: Therefore, the alternative naming of f
ias the
‘‘true value of the ratio q
i¼ n
i=m
i’’ could be misleading.
2.3. The ‘‘true’’ value of the parameter vector ~ y y The operational definition of the true value ~ y y
tof the vector ~ y y is not as simple. The latter cannot be measured directly but it is obtained as the result of the fit. Assume that we know the correct theory (up to the value of ~ y y), that we have perfect information on the performance of the experi- mental apparatus, and that the systematic errors are known to be negligible as compared to statistical ones. Nevertheless, the estimates of ~ y y will most often be biased and bias cannot be reduced by independent repetitions of experiment, simulation, and fit, i.e. by building up the set O:
The solution—provided the estimate of ~ y y is
consistent—is to aim at the asymptotic limit
m
i- N ; n
i- N ; with n
i=m
i¼ f
i¼ const:a0 for
all i ¼ 1; 2; y ; K (see the next subsection). The results are increasingly accurate statistics ~ y y ; i.e.
vector functions of the (increasingly large) bin contents m
iand n
i: In this sense, even ~ y y
tmay be considered as a physically measurable quantity.
Henceforth, whenever we use the symbol ~ y y
t; we imply that the above assumptions are valid.
Hence, our implicit definition (under the above provisos) of ~ y y
tis
mi-N;f
lim
i¼const:a0E½f
ið ~ y y
tÞ ¼ f
ið19Þ (see also Section 6).
Unfortunately, our model is often based on a theory which is only partially known and calcul- able (e.g. QCD which is reliably calculable only in the perturbative region). At best, the consequences of the unknown part can be crudely estimated as a so-called systematic theoretical error. Actually, since we have assumed (cf. Section 1.9) that imperfections of the experimental apparatus are to be faithfully simulated by the theorist, any errors in this simulation might as well be termed
‘‘theoretical’’ or—better—we should call any nonstatistical and uncorrectable error simply
‘‘systematic’’. As a rule, systematic errors cannot be reduced by identically repeating the experiment and its analysis. Therefore they furnish an irreducible limit to the measurability of ~ y y
t: In addition, systematic errors generally cause correla- tions between weights of different bins and—if they are important—nondiagonal covariance ma- trices S should enter our chi-squares. We shall not attempt a corresponding extension of the present article, though we are conscious that its scope is therefore severely limited.
2.4. Ideal form
2X
2N;iof
2X
N;i2and its asymptotic limit
2X
2N;iThe quantity
2X
N;i2of Eq. (13) with f
isubstituted by f
i; i.e.
2
X
2N;i¼ ðf
im
in
iÞ
2f
2im
iþ n
ið20Þ is, in a sense, the ‘‘ideal’’ value of
2X
N;i2; given a pair of event numbers m
iand n
i; it is neither the expectation nor the true value of
2X
N;i2: Hence-
forth, the qualifier ‘‘ideal’’ should be considered a technical term and we omit the quotation marks.
The quantity
2X
2N;idoes not depend on the parameter vector ~ y y and cannot be used for point or interval estimation but it is of theoretical interest.
Here, we consider the limiting value of
2X
2N;iin the asymptotic case m
i- N ; n
i- N with 0 o f
i¼ n
i=m
i¼ const: o N : (Note that our use of the term
‘‘asymptotic’’ does not refer to the infinite number N
Oof elements in the set O: Subsequently, we shall not always repeat the definition of this term.) We replace m
iand n
iby new variables d
iand e
i; respectively, defined by
d
idef¼ m
im
i; e
idef¼ n
in
i: ð21Þ Since we have assumed that m
iand n
iare Poisson distributed, we have
Eðd
iÞ ¼ Eðe
iÞ ¼ 0; Eðd
2iÞ ¼ m
i; Eðe
2iÞ ¼ n
i: ð22Þ To 0th order in 1=n
iand 1=m
i; i.e. if
E d
2im
2i¼ 1
m
i-0; E e
2in
2i¼ 1
n
i-0 ð23Þ we obtain
2
X
2N;i-
2X
2N;ið24Þ
with
2
X
2N;i¼ ðf
id
ie
iÞ
2n
iðf
iþ 1Þ : ð25Þ
2.5. Asymptotic w
2ð1Þ behaviour of
2X
2N;iThe quantity
2X
2N;imay be considered as a nonnegative random variable z
iwhich depends on two parameters f
iand n
i: The variable z
iis distributed according to a distribution F ðz
i; f
i; n
iÞ which is not explicitly known. However, in the limit n
i- N ; f
i¼ const: a 0; the distribution of z
iapproaches the distribution of the variable z ¼ w
2ð1Þ; irrespective of the value of f
i:
This statement may be justified by the following
argument. In the limit n
i- N ; the Poisson
distribution Pðn
ijn
iÞ approaches a Gaussian dis-
tribution Nðn
i; n
iÞ (i.e. with mean n
iand variance
n
i) [19]. Therefore, the asymptotic distribution of
the random variable d
i¼ f
im
in
i¼ f
id
ie
iis given by the folding [20] of the Gaussian Nðf
im
i; f
2im
iÞ with the Gaussian Nðn
i; n
iÞ: The resulting distribution is again a Gaussian with the mean f
im
in
i¼ 0 and the variance f
2im
iþ n
i¼ n
iðf
iþ 1Þ: Therefore [19,21], the variable z
i¼ d
i2=½n
iðf
iþ 1Þ ¼
2X
2N;iis asymptotically (i.e. for m
i- N ; n
i¼ f
im
i- N ; f
i¼ const:Þ w
2ð1Þ dis- tributed.
An alternative proof of the above statement, outlined in Appendix B, is based on the Second Limit Theorem [22], i.e. on the equality of the asymptotic moments of F ðz
i; f
i; n
iÞ with the mo- ments of w
2ð1Þ: Appendix B also contains some information on the moments of
2X
2N;iand of similar quantities (see the next section) outside the asymptotic region, which is of interest for Section 6 and article II [17].
It is easy to see that the w
2ð1Þ asymptotic distribution of
2X
2N;iimplies that
2X
2N;iis asymp- totically w
2ð1Þ distributed. Sometimes we state simply that these quantities ‘‘are asymptotically w
2ð1Þ’’. Somewhat sloppily, one may also say that
2
X
N;i2itself is asymptotically w
2ð1Þ distributed though, of course, this is not generally true if the simulation uses a poor model or if ~ y y differs substantially from ~ y y
t:
2.6. Self-conjugacy and regularity of
2X
N;i2The quantity
2X
N;i2has some additional remark- able properties. From a statistical point of view, the random number of experimental events n
iand the random number of simulated events m
iare equivalent. Therefore, instead of trying to find the factors f
iwhich are best suited to convert—as closely as possible—m
iinto n
ifor all bins i; we may try to find the factors g
ibest suited to convert n
iinto m
i: The bivariate chi-square quantity suitable for that purpose may be obtained from
2X
N;i2of Eq. (13) by the simultaneous interchanges
m
i2 n
ið26Þ
f
i2 g
i: ð27Þ
However, from the point of view of physics, the experimental and the MC events are not equiva- lent. Both the generated (i.e. actual) and the
reconstructed (i.e. apparent) coordinates in phase space are known for MC events, but only the latter are measured for experimental events. As a consequence, if the imperfect resolution of the apparatus is to be taken into account, g
ishould be taken as
g
i¼ 1=f
ið28Þ
and f
ið ~ y yÞ evaluated using generated and recon- structed MC events in any case. (Here we have emphasized the dependence of f
ion ~ y y which is at this point a parameter vector yet to be estimated later by the fit.) Therefore, Eq. (27) must be replaced by
f
i2 1=f
i: ð29Þ
The interchange (26) implies
m
i2n
iand f
i21=f
i: ð30Þ As may be easily verified,
2X
N;i2of Eq. (13) is invariant with respect to the simultaneous inter- changes (26) and (29). For m
i> 0 and n
i> 0;
2X
N;i2vanishes at
f
iðextrÞ¼ n
im
ið31Þ in concordance with the invariance with respect to the interchanges (26) and (29).
2X
N;i2stays finite for m
i¼ 0; n
ia0 and (therefore) for n
i¼ 0; m
ia0: At m
i¼ n
i¼ 0 it may be set to zero, since it is a ratio of two forms in m
iand n
iwith the form in the numerator being of higher degree than the one in the denominator.
3. A family of special bivariate chi-square quantities
3.1. ‘‘Specialness’’ and conversion of a univariate
1
X
i2into the corresponding special bivariate
2X
i2We call ‘‘special’’ (which should be considered a technical term) any bivariate
2X
2quantity and its components
2X
i2; if the latter have the following properties:
(1) asymptotic w
2ð1Þ distribution,
(2) invariance w.r.t. the simultaneous inter-
changes (26) and (29) (subsequently referred
to as the pair (26), (29)),
(3) finite values at m
i¼ 0 and at n
i¼ 0;
(4) minimal value zero at f
i¼ f
iðextrÞ¼ n
i=m
i; if m
i> 0 and n
i> 0:
In addition, as announced in Section 2.3, correlations between different bins i are disre- garded in our special
2X
2quantities.
We have just seen that
2X
N2is special. Below we introduce a family of such special bivariate chi- square quantities. Starting from familiar univari- ate
1X
i2quantities, we first replace the theoretical prediction y
iby f
im
i: Then we check the asympto- tic distribution of the resulting
2X
i2and, if necessary, multiply the latter by a suitable correc- tion factor so as to achieve an asymptotic w
2ð1Þ distribution. If this
2X
i2still lacks any of the properties 2. – 4., we ‘‘specialize’’ it by taking a suitable linear superposition of
2X
i2and its conjugate
2X
i2;cw.r.t. the pair (26), (29).
Conversely, starting from any given bivariate
2
X
i2—be it special or not—we may recover the corresponding univariate
1X
i2if we replace f
im
iby y
i; set the remaining f
ito zero, and take into account that n
i5 m
i(cf. Eqs. (5) and (13)). A mathematically more transparent and general prescription for the limiting process leading from a bivariate
2X
i2to the corresponding univariate
1
X
i2is to be found in Appendix A.
3.2. The special
2X
P;i2and
2X
R;i2It is not difficult to find a simple special
2
X
P;i2¼ ð f
im
in
iÞ
2f
im
iðn
i=m
iþ 1Þ ¼ ð f
im
in
iÞ
2f
iðm
iþ n
iÞ ð32Þ which reduces in the univariate limit to the classical Pearson
1
X
P;i2¼ ðy
in
iÞ
2y
i: ð33Þ
The ratio G
i def 2¼ X
P;i22
X
N;i2¼ f
i2m
iþ n
if
iðm
iþ n
iÞ ð34Þ is (necessarily) invariant w.r.t. pair (26), (29), and finite both at m
i¼ 0; n
ia0 and at n
i¼ 0; m
ia0: Its
ideal form G
i¼ f
2im
iþ n
if
iðm
iþ n
iÞ ð35Þ
asymptotically tends to unity. Clearly,
2
X
R;i2 def¼
2X
P;i2G
i¼
2X
N;i2G
2i¼ f
i2m
iþ n
if
i2ðm
iþ n
iÞ
2ð f
im
in
iÞ
2ð36Þ is yet another special
2X
i2quantity (which lacks a familiar univariate limit, cf. Appendix A). Our reason for considering it is the well-known super- iority of
1X
P2over
1X
N2in goodness-of-fit tests. It should be interesting to see how
2X
R2behaves in this respect, relatively to
2X
P2and
2X
N2(see II [17]).
Incidentally, the label R has been chosen for the quantity defined in Eq. (36) because of its alpha- betical position in relation to the letters N and P.
Starting from
2X
P;i2; repeated multiplications or divisions by the factor G
ilead to an infinity of different special bivariate chi-square quantities.
Obviously, specialness does not guarantee that any given such quantity is particularly well-behaved (see Section 5) or useful in practice.
3.3. The special
2X
l;i2obtained by conversion and specialization from
1X
l;i2On the way to the bivariate generalization of
1
X
l;i2of Eq. (15), the first two steps of the procedure sketched above yield
2
X
aux;i2¼ 2 f
im
in
in
ilnð f
im
i=n
iÞ
f
iþ 1 ð37Þ
which is asymptotically w
2ð1Þ but neither invariant w.r.t. the interchanges (26), (29) nor finite at m
i¼ 0: Taking its conjugate w.r.t. these interchanges
2
X
aux;i2;c¼ 2 n
if
im
iþ f
im
ilnð f
im
i=n
iÞ
f
iþ 1 ð38Þ
we may define the desired special bivariate
2X
l;i2by
2
X
l;i2 def¼ 1 m
iþ n
ið
2X
aux;i2m
iþ
2X
aux;i2;cn
iÞ
¼ 2
ðm
iþ n
iÞð f
iþ 1Þ ½ðm
in
iÞð f
im
in
iÞ
þ m
in
ið f
i1Þ lnð f
im
i=n
iÞ: ð39Þ
With some care we may check that
2X
l;i2reduces to
1
X
l;i2in the univariate limit. In the next section we introduce yet another special bivariate
2X
i2quan- tity which looks quite different from
2X
l;i2but has the same univariate limit, as shown in Appendix A. We derive it from a ratio of likelihoods and call it
2X
L;i2; the index L standing for both likelihood and the kinship with
2X
l;i2:
4. A special
2X
L;i2deduced from the likelihood for the ratio of two independent bin contents
4.1. Log-likelihood from Appendix C
In Appendix C we use a Bayesian approach followed by specialization (see preceding section) to make it plausible that the log-likelihood function ln Lð ~ y yÞ for the estimation of the para- meter vector ~ y y in the bivariate case may be taken as
ln Lð ~ y yÞ ¼ X
Ki¼1
ln L
i½f
ið ~ y y Þ
¼ X
Ki¼1
fn
iln f
ið ~ y yÞ ðm
iþ n
iÞ
ln½1 þ f
ið ~ y y Þg: ð40Þ The log-likelihood ln Lð ~ y y Þ is a sum of individual terms contributed by the different bins i which are respectively maximal at f
i¼ f
iðextrÞwith
f
iðextrÞ¼ n
im
i: ð41Þ
We have
ln L
ið f
iðextrÞÞ ¼ ðm
iþ n
iÞ n
im
iþ n
iln n
im
iln m
iþ n
im
i¼ m
iln m
iþ n
iln n
iðm
iþ n
iÞ lnðm
iþ n
iÞ: ð42Þ 4.2. The special
2X
L2obtained from log-likelihood
In the standard way [9,23], a bivariate like- lihood-ratio chi-square can be deduced from
Eqs. (40) and (42) by defining
2
X
L2¼ X
i
2
X
L;i2ð43Þ
with
2
X
L;i2¼ 2f½ln L
ið f
iðextrÞÞ ln L
i½f
ið ~ y yÞg
¼ 2½m
iln m
iþ n
iln n
iðm
iþ n
iÞ lnðm
iþ n
iÞ þ m
ilnð1 þ f
iÞ þ n
ilnð1 þ 1=f
iÞ: ð44Þ As it stands,
2X
L;i2is invariant w.r.t. pair (26), (29), and assumes finite values both at m
i¼ 0; n
ia0 and at m
ia0; n
i¼ 0 (cf. Section 5). It vanishes at m
i¼ n
i¼ 0 and reaches its minimal value of zero at f
iðextrÞ: We can easily check that it is asymptotically equal to
2X
2N;iof Eq. (25), as expected. Therefore, it is special.
4.3. Comments on Appendix C
For readers of Appendix C a few comments might be in place. Clearly, we cannot offer a proper ‘‘derivation’’ of
2X
L2: Our attitude in front of this incapability is very similar to that of Cousins [24] who says, when faced with a particular Bayesian versus frequentist dilemma, that his approach ‘‘can be charitably described as pragmatic’’. In our case we have indications (see II [17]) that
2X
L2might be useful in statistical inference and hypothesis testing, so we do not worry very much about the way it has been obtained.
On the other hand, Appendix C may convey an
intuitive understanding why bivariate
2X
2iquan-
tities depend on a single parameter f
i; leading to
their asymptotic w
2ð1Þ behaviour. However, it also
raises some doubts whether it is advisable to
restrict bivariate
2X
i2quantities to the members of
the special family. Log-likelihoods like
ln Lðfjm; n; bÞ of Eq. (C.12) or even more general
ones with aaa
0; bab
0might prove useful in
practice.
5. Scaling and functional behaviour of special bivariate chi-squares
5.1. Scaling variables
In this section, except at its very end, we assume nonzero values of both m
iand n
i: All our
2X
i2quantities depend on the variables m
i; n
i; and f
i: The first two may be replaced by the variables s
iand q
i; defined by s
i def¼ 2m
in
im
iþ n
i¼ 2 1 m
iþ 1
n
i1
ð45Þ and
q
i def¼ n
im
ið46Þ
respectively. Often it is advantageous to replace either f
ior q
iby the variable u
idefined by u
i def¼ ln f
im
in
i¼ ln f
iq
i: ð47Þ
Note that the scaling factor s
isatisfies s
iX 1 for any pair of nonzero m
i; n
ivalues. We have s
i¼ 1 only for m
i¼ n
i¼ 1:
The five different quantities
2X
Y;i2ðY ¼ N; P; R; l; or L) can all be written in the form
2
X
Y;i2¼ s
ic
Y;i: ð48Þ
The hereby newly defined ‘‘reduced
2X
Y;i2quan- tities’’ c
Y;idepend only on two of the three quantities q
i; f
i; and u
i: As a consequence of the invariance of our five special
2X
Y;i2w.r.t. the pair (26), (29), the quantities c
Y;iare invariant w.r.t.
the simultaneous interchanges
q
i2 1=q
i; f
i2 1=f
ið49Þ which imply
u
i2 u
i: ð50Þ
Note, though, that scaling is not a necessary consequence of specialty. As an example of a special
2X
i2quantity that does not scale, consider any
2X
Y;i2multiplied by a positive definite factor 1 þ kF ðm
i; n
iÞ where k is a real parameter, and F is a finite function of m
iand n
i; invariant w.r.t. their interchange and tending to zero as m
i- N or n
i- N :
5.2. Reduced
2X
Y;i2quantities c
Y;ias functions of two scaling variables
The simplest among the five c
Y;iquantities is c
P;igiven by (cf. Eq. (32))
c
P;i¼ ð f
iq
iÞ
22f
iq
i¼ ðe
ui1Þ
22e
ui¼ cosh u
i1 ð51Þ which is a (necessarily even) function of the sole variable u
i:
From Eqs. (34) and (36) we find
c
N;i¼ c
P;i=G
ið52Þ
and
c
R;i¼ c
P;iG
ið53Þ
with
G
i¼ f
i2þ q
if
iðq
iþ 1Þ ¼ f
ie
uiþ 1 e
uiþ f
i¼ cosh u
iþ q
i1
q
iþ 1 sinh u
i: ð54Þ The quantity c
l;i(cf. Eq. (39)) may be expressed as
c
l;i¼ c
P;iþ H
ið55Þ
with H
i¼ 1 f
i1 þ f
if
i2q
2i2f
iq
iln f
iq
i¼ 1 f
i1 þ f
iðsinh u
iu
iÞ
¼ 1 q
ie
ui1 þ q
ie
uiðsinh u
iu
iÞ: ð56Þ Finally, for c
L;iwe find (cf. Eq. (44))
c
L;i¼ ð1 þ q
iÞ ln 1 þ 1=f
i1 þ 1=q
iþ ð1 þ 1=q
iÞ ln 1 þ f
i1 þ q
i: ð57Þ We leave the explication of c
L;iin terms of the pair of variables q
i; u
ior the pair f
i; u
ias an exercise for the reader.
5.3. Consequences of asymptotic equivalence of
2
X
Y;i2for c
Y;iðu
i¼ 0Þ
As u
i- 0; all five c
Y;iquantities behave as u
2i=2:
This is a manifestation of their asymptotic
equivalence: for a given interval ½0; X
i2of values
of
2X
Y;i2; the corresponding values of c
i¼ X
i2=s
ilie the nearer to u
i¼ 0 the larger is the value of s
ii.e., the better the pair m
i; n
ifulfils the condition m
ib 1 and n
ib 1:
Incidentally, we may define a sixth c
Y;iquantity for which we choose the symbol c
a;i(a for
‘‘asymptotic’’) by c
a;i def¼ u
2i2 ð58Þ
which is clearly invariant w.r.t. interchange (50), i.e. also w.r.t. the pair (26),(29). It is easy to verify that the quantity
2
X
a;i2¼ s
iu
2i2 ¼ m
in
im
iþ n
iln
2f
im
in
ið59Þ is special, if we assume m
iln m
i¼ m
iln
2m
i¼ 0 at m
i¼ 0 and likewise for n
i:
5.4. The u
i-even and u
i-odd components of c
Y;iFor a presentation of the different c
Y;iquan- tities it is of particular interest to consider them as functions of either the pair f
i; u
ior the pair q
i; u
i; and to take their u
i-even and u
i-odd components defined as
e
Y;ið f
i; u
iÞ ¼
12½c
Y;ið f
i; u
iÞ þ c
Y;ið f
i; u
iÞ ð60Þ o
Y;ið f
i; u
iÞ ¼
12½c
Y;iðf
i; u
iÞ c
Y;ið f
i; u
iÞ ð61Þ e
Y;iðq
i; u
iÞ ¼
12½c
Y;iðq
i; u
iÞ þ c
Y;iðq
i; u
iÞ ð62Þ o
Y;iðq
i; u
iÞ ¼
12½c
Y;iðq
i; u
iÞ c
Y;iðq
i; u
iÞ: ð63Þ We call the quantities e
Y;iand o
Y;i‘‘mean level’’
and ‘‘asymmetry’’, respectively. From now on, we shall often omit the argument u
iwhen referring to e
Y;iand o
Y;i: Since c
Y;iare nonnegative and invariant under the simultaneous interchanges (49)–(50), we have
e
Y;ið1=xÞ ¼ e
Y;iðxÞ ð64Þ o
Y;ið1=xÞ ¼ o
Y;iðxÞ ð65Þ 1 p o
Y;iðxÞ=e
Y;iðxÞ p 1 ð66Þ for either x ¼ f
ior x ¼ q
i: From Eq. (65) follows
o
Y;ið1Þ ¼ 0: ð67Þ
Eqs. (64) and (65) show that it suffices to investigate the mean levels e
Y;iand the asymme- tries o
Y;ifor 0 o f
ip 1 and for 0 o q
ip 1: (Recall that the assumption announced at the beginning of this section implies q
ia0: In Section 2.2 we argued that f
icannot vanish. By similar arguments, a sensible f
imay be small but never zero, in practice.)
5.5. Limiting behaviour of the u
i-even and u
i-odd components of c
Y;iClearly, since all c
Y;ivanish at u
i¼ 0; so do all e
Y;iand o
Y;i: Their limiting behaviour as u
i- þ N is displayed in Tables 1 and 2. Note that all e
Y;ið f
i; u
i- þ N Þ and o
Y;ið f
i; u
i- þ N Þ are pro- portional to e
ui; except that e
a;i¼ u
2i=2 and o
a;i¼ o
P;i¼ 0: On the other hand, their limiting beha- viour as u
i- þ N at constant q
ivaries widely, from approaching a q
i-dependent constant ðe
N;iðq
iÞ; o
l;iðq
iÞ; and o
N;iðq
iÞÞ to an e
2uidependence ðe
R;iðq
iÞ and o
R;iðq
iÞÞ: Tables 1 and 2 are helpful in understanding the detailed behaviour of different mean levels and asymmetries as displayed in the
Table 1
Limiting behaviour of mean levelseY;iðqi;uiÞand asymmetries oY;iðqi;uiÞ ðY¼P;N;R;l;L;or a) at 0oqi¼const:oN and ui-þN(i.e.fi-þN)
Y eY;iðqi;ui-þNÞ oY;iðqi;ui-þNÞ
P eui
2
0
N 1
4ð2þ1=qiþqiÞ 1
4ð1=qiqiÞ
R e2ui
4 1qi
1þqi e2ui
4
l ui 1
2ð1=qiqiÞ
L 1
2ð2þ1=qiþqiÞui 1
2ð1=qiqiÞui
a u2i
2
0
following figures. The figures may be obtained directly from Eqs. (51)–(58) and (60)–(63); com- pressed analytical expressions for most of the different e
Y;iand o
Y;iare easily derived from these equations.
5.6. General behaviour of the even components of c
N;iand c
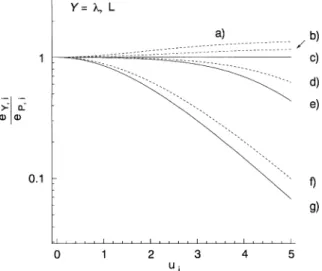
R;iFig. 1 shows the different mean levels e
Y;i; divided by e
P;i; as functions of u
iat a few values of either q
ior f
i; for Y ¼ N and R. (We abstain from showing e
P;iitself and e
a;i; both of which depend in a well-known way on u
ionly.) Note the logarithmic scale on the ordinate. A comment is due concerning the values of e
Y;iðY ¼ N; RÞ at q
i¼ 0: In the case of e
R;iðq
iÞ; this value coincides with the limit of e
R;iðq
iÞ for q
i-f: The mean level e
N;iðq
iÞ behaves anomalously. At q
i¼ 0; we obtain analytically e
N;iðq
i¼ 0Þ=e
P;i¼ e
R;iðq
i¼ 0Þ=e
P;i¼ cosh u
i: On the other hand, at any finite value of q
ia 0; e
N;iðq
iÞ approaches a constant r
i¼ ð2 þ 1=q
iþ q
iÞ=4 as u
i- þ N (see Table 1), i.e.
e
N;iðq
iÞ=e
P;idecreases as e
ui: Qualitatively, we can understand what is happening by noticing the behaviour of e
N;iðq
iÞ=e
P;ifor q
i¼ 0:1 and q
i¼ 0:01 in Fig. 1. With decreasing q
i; the relative mean level e
N;iðq
iÞ=e
P;isnuggles ever more closely up to
cosh u
ifor small u
i-values, only to plunge below 1 at ever larger u
i: Analytically we obtain
e
N;iðq
iÞ X e
P;ifor 0 o q
ip 3 ffiffiffi p 8
and
0 p u
io u
m;ið68Þ
Table 2
Limiting behaviour of mean levelseY;iðfi;uiÞand asymmetriesoY;i ðfi;uiÞ ðY¼P;N;R;l;L;or a) at 0ofi¼const:oNandui-þN (i.e.qi-0)
Y eY;iðfi;ui-þNÞ oY;iðfi;ui-þNÞ
P eui
2
0
N ð1=fiþfiÞeui
4 ð1=fifiÞeui
4
R ð1=fiþfiÞeui
4 ð1=fifiÞeui
4
l eui
2
1fi
1þfi eui
2
L 1
filnð1þfiÞ þfiln 1þ1 fi
eui 2
1
filnð1þfiÞ filn 1þ1 fi
eui 2
a u2i
2
0
Fig. 1. Mean levels eY;iðqi;uiÞ and eY;iðfi;uiÞof reduced chi- square quantities cY;i for Y¼N and R divided by eP;i¼ coshui1:a) Nðfi-0 orqi-0Þand R (anyqi). b) N and R ðfi¼0:01Þ: c) N and R ðfi¼0:1Þ: d) N and R ðfi¼1Þ:
e) Nðqi¼0:01Þ:f ) Nðqi¼0:1Þ:g) Nðqi¼1Þ:
with
u
m;i¼ lnðh
iffiffiffiffiffiffiffiffiffiffiffiffiffi h
2i1 q
Þ ð69Þ
h
i¼ ð1 q
iÞ
24q
i: ð70Þ
Otherwise
e
N;iðq
iÞ p e
P;i: ð71Þ
Incidentally, this example should caution against a cavalier treatment of multiple limiting processes which are not commuting, in general. An analo- gous case is that of e
N;ið f
iÞ=e
p¼ e
R;ið f
iÞe
p- 1=
ð2f
iÞ for large values of u
iand f
i- f:
5.7. General behaviour of the even components of c
l;iand c
L;iFig. 2 shows e
Y;i=e
P;ifor Y ¼ l and L: The scale on the ordinate comprises two decades instead of the four decades of Fig. 1 which means that, on the average over all variables, e
l;iand e
L;iare about two orders of magnitude closer to e
P;ithan e
N;iand e
R;i: Even more remarkable is the closely similar behaviour of e
l;iand e
L;i: The straight line at e
Y;i=e
P;i¼ 1 in Fig. 2 is valid for Y ¼ l and any value of f
ibut also for Y ¼ L at f
i- 0: This checks
with Table 2. However, Table 1 contradicts the hypothesis that it could be strictly valid for q
i- 0 and either Y ¼ l or L: The example of Y ¼ N and small q
iof Fig. 1 suggests what happens. As q
i-0;
e
Y;iðq
iÞ=e
P;i(Y ¼ l or L) approaches the value of 1 for a restricted range of u
i; say u
io 5; in the sense that for any positive value e o 1 a sufficiently small positive value of q
i¼ q
iðeÞ can be found such that 1 eoe
Y;iðq
iÞ=e
P;io1 for any u
io5: However, at u
i-values beyond the order of magnitude of ln q
iðeÞ; the relative mean level e
Y;iðq
iÞ=e
P;itends to zero.
5.8. General behaviour of the odd components of c
Y;iFig. 3 shows the relative asymmetries o
Y;i=e
Y;i(not o
Y;i=e
P;iÞ for Y ¼ R; l; and L: Here the scale on the ordinate is linear. Note again the close similarity between Y ¼ l and L: Note also that o
N;i=e
N;i¼ o
R;i=e
R;i; both at given q
iand at given f
i(cf. Eqs. (52)–(53)). Of course, the asymmetries are zero for Y ¼ P and a. They also vanish at q
i¼ 1 or at f
i¼ 1 for any Y (cf. Eq. (67)). The limits q
i- 0 and f
i- 0 behave normally in the sense that the limiting values of o
Y;i=e
Y;iare equal to their
Fig. 2. Same asFig. 1but forY¼l(full curves) andY¼L (dashed curves). a) Lðfi¼1Þ:b) L ðfi¼0:1Þ:c)l(anyfi or qi-0) and Lðfi-0 or qi-0). d) Lðqi¼0:01Þ:
e)lðqi¼0:01Þ:f) Lðqi¼1Þ:g)lðqi¼1Þ:
Fig. 3. Relative asymmetries oY;iðqi;uiÞ=eY;iðqi;uiÞ and oY;iðfi;uiÞ=eY;iðfi;uiÞof reduced chi-square quantitiescY;i for Y¼R andl(full curves), andY¼L (dashed curves). a)land Lðfi-0 orqi-0Þ:b)lðfi¼0:3Þ:c) Lðqi¼0:3Þ:d) Lðfi¼ 0:3Þ:e)lðqi¼0:3Þ:f) allYðfi¼1 orqi¼1Þ:g) Rðqi¼0:3Þ:
h) Rðfi¼0:3Þ:i) Rðfi-0 orqi-0Þ: