an der Unterelbe
Dr. Moritz Mercker - Biostatistisches Büro Bionum Finkenwerder Norderdeich 15 A, 21129 Hamburg Telefon: +49 163 2357602 und +49 40 181 39637
info@bionum.de, www.bionum.de 24. November 2017
1 Entwicklung der Kadaver-Korrekturfaktoren
Eine Erfassung der Kollisionsopferzahl basiert auf regelmäßigen Suchgängen, die in einem fest- gelegten Gebiet (”Suchgebiet”) um die Struktur von Interesse durchgeführt werden. Das grund- legende Problem bei solchen Kadaverzählungen besteht nun darin, dass die gefundene Kadaver- zahlNF (”Felddaten”) die tatsächliche KollisionopferzahlN in der Regel deutlich unterschätzt.
Die Hauptgründe hierfür sind [22]:
• nicht alle kollidierten Individuen verenden innerhalb des Suchgebietes;
• nicht alle Kadaver verbleiben bis zum nächsten Suchdurchgang im Gebiet: es finden Ab- transporte durch Aasfresser sowie Verwesunsprozesse statt;
• nicht alle verbliebenen Kadaver werden durch die erfassende Person aufgefunden.
Eine zusätzliche Komplexität ist dadurch gegeben, dass diese Prozesse nicht eine zufällige Un- terstichprobe der tatsächlichen Kadavermenge zur Folge haben, sondern mitunter hochselektiv sind - die Auffindwahrscheinlichkeit ist bspw. in der Regel zugunsten großer Kadaver stark ver- zerrt [17].
Wissenschaftliche Studien die sich mit der Abschätzung von Kollisionsopfern befassen, sollten in der Regel folgende Kriterien erfüllen:
1. Es sollte ein geeigneter Schätzer Nˆ verwendet werden, der die wahre KadaverzahlN ba- sierend auf der gefundenen KadaverzahlNRunter Korrektur der o.g. Verzerrungen annä- hert. Insbesondere sollte die Schätzmethode im Kontext der Versuchs- und Datenstruktur erwartungstreu, d.h., unverzerrt sein.
2. Es sollten Konfidenzintervalle berechnet werden, die den wahren WertNmit vorgegebener Wahrscheinlichkeit enthalten. Auf diesem Weg kann die Qualität der Schätzung eingesehen werden.
3. Wenn Kadaverzahlen im Rahmen von statistischen Tests verwendet werden, sollte eine geeignete Methode angewendet werden, die sowohl die Streuung der Schätzwerte unter- einander als auch die Qualität der Schätzungen mit berücksichtigt. Ein Verwenden der reinen Felddaten oder punktweisen Schätzwerte führt i. Allg. zu inadäquaten Signifikan-
zwerten.
In den vergangenen zehn Jahren wurden viele Fortschritte bei der statistischen Schätzung von N erzielt (Übersichtsartikel sind bspw. in Ref. 3 und Ref. 22 gegeben). Trotz einer Vielzahl an existierenden Schätzmethoden impliziert aber jede bisherige Methode unterschiedliche Annah- men, die in der Realität nicht unbedingt gegeben sind. Typische Einschränkungen beziehen sich auf die Regularität der Suchintervalle, die zugrundeliegende Verteilungsfunktion von Kadavern (z.B. in Bayesschen Ansätzen [23]), oder spezielle Funktionsstrukturen für Abtransport- oder Auffindraten. Zudem wird oft vernachlässigt, dass Kadaver bei einem Suchgang übersehen wer- den können um dafür zu späteren Suchgängen gefunden zu werden (”Bleed-through”). Aufgrund dieser Einschränkungen produziert jede der bisherigen Schätzmethoden unter bestimmten Be- dingungen verzerrte Ergebnisse [21] und eine universale flexible Schätzmethode existierte bisher nicht [3, 4].
Aus diesem Grund entwickeln wir hier eine neue flexible statistische Methode, die auf regelmäßi- gen Kadaver-Suchgängen und zusätzlichen Feldexperimenten zur Ermittlung von Abtransport- und Auffindrate basiert. Diese Methode erlaubt sowohl eine verzerrungsfreie Schätzung vonN unter einer Vielzahl von Bedingungen/Datenstrukturen, sowie eine Schätzung entsprechender Konfidenzintervalle. Der präsentierte Ansatz basiert auf Korrekturfaktoren vergleichbar mit der Methode der ”Sampling Weights” [24] wie sie im Kontext von ”Sightability Modellen” verwendet wird [15, 25, 30].
1.1 Experimentelles Design und mathematische Herleitung eines sta- tistischen Schätzers der wahren Kadaverzahl N
Allgemeine Notation
SeiMdie tatsächliche Menge an Vögeln die mit einer anthropogenen Struktur innerhalb eines Untersuchungszeitraums kollidiert sind, und N = sum(M) deren Summe, letzteres approxi- miert durch den statistischen SchätzerNˆ (der im Folgenden hergeleitet wird).
Wie oben beschrieben wird nur eine Teilmenge der Kadaver, MF ⊂ M, während der J Suchgänge aufgefunden. MF selbst besteht aus den einzelnen Kadaverfunden Mi assoziiert mit den Kovariat-Vektoren X~i, wobei i ein fortlaufender Index ist. Dieser Kovariat-Vektor X~i = (x1, x2, ...) beinhaltet verschiedene Informationen zum Zeitpunkt, Nummer des Such- durchgangs, zur lokalen Vegetation, u.s.w., und enthält alle Parameter die auch bei den zusätz- lich durchgeführten Experimenten (z.B. zur Auffind- und Abräum-Wahrscheinlichkeit) aufge- nommen wurden (vgl. folgende Kapitel). Diese Experimente sind notwendig um die Verbleibe- rates(), die Auffindwahrscheinlichkeitf(), die Zersetzungszeittd(), sowie den Anteil ausserhalb des Suchgebietes verendender Kadaver, Ain(), abzuschätzen. Diese Approximationen sind im Folgenden in Form von statistischen Modellenˆs(), fˆ(),ˆtd()undAˆin()gegeben.
In den folgenden Abschnitten definieren wir diese Modelle und entwickeln darauf basierend den SchätzerNˆ für die tatsächliche Anzahl an kollidierten Vögeln, wobeiNˆ die Summe der Menge an punktweisen Schätzwerten{θ(ˆX~1),θ(ˆX~2), ...}= ˆMdarstellt. Eine detaillierte Übersicht über die verwendete mathematische Notation bei der Entwicklung der Korrekturfaktoren findet sich
im Appendix 1, die detaillierte Herleitung vonNˆ in Appendix 2.
Abräumrate durch Aasfresser
Um die Abräum- bzw. die Verbleiberate abzuschätzen, ist eine häufige Vorgehensweise Kada- ver in einem Suchgebiet (z.B. einer Teilfläche der Untersuchungsfläche) zu verteilen, und deren Verbleib im Laufe der Zeit zu protokollieren. Auf diesem Weg ist es möglich im Falle eines Abtransportes den entsprechenden Zeitpunkt einzugrenzen. Kontrollen können bspw. alle 24 Stunden durch Begehung erfolgen, oder in wesentlich kürzeren Zeitintervallen bspw. durch mo- derne Kamera-Trapping Verfahren [26]. Die Frequenz der Kontrollen ist im Folgenden durch den Skalierungsfaktorαt relativ zur Anzahl an Tagen beschrieben, z.B. αt = 24würde stündliche Kontrollen bedeuten. Im Folgenden sind alle Zeitfenster (z.B.D(k,l)) in Einheiten vonαt·T age gegeben.
Um eine möglichst allgemeingültige Form von Regressionsmodellen für den Abtransport zu ge- währleisten, orientieren wir uns an jüngeren Studien zum Abtransport von Kadavern durch Aasfresser, und modellieren diesen zeitabhängigen Prozess im Kontext der ”Survival Analysis”
mit entsprechenden Survival-Regressionsmodellen, die eine Überprüfung vieler unterschiedli- cher möglicher Zufallsverteilungen sowie eine beliebige Anzahl an Kovariaten erlauben [6, 7, 22].
Basierend auf dem Akaike’s Information Criterion (AIC) [1] kann dann die geeignetste Zufalls- verteilung sowie ein geeignetes Set an Kovariaten ausgewählt werden, was zu dem statistische Modellˆs()führt.
ˆ
s() hängt dann von dem Zeitpunkt a (gemessen vom Zeitpunkt des Auslegens des Kadavers an) sowie einer weiteren Anzahl an Kovariaten X~s ab. Auf diesem Weg approximiert ˆs(a, ~Xs) die Verbleiberate san Kadavern (mit einem bestimmten Set an Kovariat-Werten X~s) im Zei- tintervall[0, a], was gleichbedeutend mit dem Anteil verbliebener Kadaver verglichen mit dem Start-Zeitpunkt ist. Im Folgenden sind wir ebenfalls an relativen Verbleiberaten zu ”späteren”
Zeitintervallen [a, b] mit a > 0 interessiert (d.h., wir möchten der Fragestellung nachgehen welcher Anteil der nach dem Zeitintervall[0, a] verbliebenen Kadaver nach dem Intervall[a, b]
immer noch verbleibt). In vielen bisherigen Studien wurde diese Rate übers([a, b])ˆ ≈ˆs([0, b−a]) approximiert [3, 21]. Dieser Zusammenhang ist allerdings nur dann gegeben wenn ˆs([a, b]) ex- ponentiell mit der Zeit fällt. Diese Bedingung ist allerdings leicht verletzt, z.B. wenn die Ab- räumrate an das Alter der Kadaver gekoppelt ist. Daher produzieren zeitlich nicht-konstante Verbleiberaten entsprechende Verzerrungen in bestehenden Schätzern [21].
In der vorliegenden Studie vermeiden wir diesbezügliche Verzerrungen indem wirˆs([a, b])explizit über
ˆ
s([a, b], ~Xs) = 1−ˆs(a, ~Xs)−s(b, ~ˆ Xs) ˆ
s(a, ~Xs)
= ˆs(b, ~Xs) ˆ
s(a, ~Xs) (1)
berechnen, denn ˆs(a, ~Xs)−ˆs(b, ~Xs)
ˆ
s(a, ~Xs) beschreibt uns die relative Änderung des Anteils abgeräumter Kadaver zwischen Zeitpunkt aundb. Weiter wirds(0, ~ˆ Xs) := 1gesetzt, denn ein Kadaver ist
zum Zeitpunkt des Vogelschlags nie abtransportiert.
Auffindwahrscheinlichkeit
Die Auffindwahrscheinlichkeitf()kann experimentell über die Durchführung von ”künstlichen Kadaver-Suchgängen” ermittelt werden, wobei die wahre Anzahl ausgelegter Kadaver bekannt ist (jedoch nicht dem Sucher). Hier nutzten wir ein Logistisches Generalisiertes Gemischtes Regressionsmodell (GLMM) um die experimentellen Daten zu beschreiben, da die Outcome- Variabe binärer Natur ist (”aufgefunden” versus ”übersehen”) und die Daten in suchenden Perso- nen ”genestet” sind. Die Verwendung von Gemischten Modellen verhindert Verzerrungen bedingt durch die Stochastizität in den experimentellen Daten [22].
Wie auch im Falle der Abräum-Regression ist auch hier die Betrachtung einer beliebigen Anzahl Kovariate Xf möglich; das beste Set an Kovariaten wird auch hier über AIC-Analysen [1]
ermittelt, was zum finalen Schätzer der Auffindwahrscheinlichkeit,fˆ(X~f), führt.
Zerfallszeit
Die Zerfallszeittd()beschreibt die mittlere Anzahl an Tagen bis hin zu dem Zeitpunkt, an dem ein Kadaver nicht mehr auffindbar ist, da er zu stark zerfallen / zersetzt ist. Unter bestimmten Umständen kann td() gemeinsam mits() abgeschätzt werden, was zu einer verallgemeinerten Form der Verbleiberate,s(a, ~˜ Xs), führt. Da i. Allg. aber sowohl die Zeitskalen als auch die zu- grundeliegenden Prozesse grundsätzlich unterschiedlich sind, ist zu empfehlen, beide Prozesse separat abzuschätzen. Die Abschätzung vontd()kann z.B. dadurch erfolgen, dass Kadaver über längere Zeiten ausgelegt und durch Käfige vor dem Abtransport durch Aasfresser geschützt wer- den.
Durch die starken Unterschiede in der Zeitskala zwischen Abtransport und Zerfall, hat der Zerfall oft nur eine sehr geringen Einfluss auf die effektive Auffindwahrscheinlichkeit / die Korrekturfaktoren. Der experimentelle Aufwand zur Ermittlung vontd()sollte dementsprechend angepasst werden, oft ist die Ermittlung des empirischen Mittelwertesˆtd() :=td()als simpelst- mögliches statistisches Modell ausreichend.
Anteil der Kadaver die innerhalb des Suchgebietes verenden
Es ist wichtig den Anteil der Kadaver die ausserhalb des Suchgebietes verenden abzuschätzen, da es sonst zu einer starken Unterschätzung der Gesamtsumme der Vogelschlagopfer kommen kann [2]. Da visuelle Methoden oder die Verwendung von markierten Individuen nur die Unter- suchung von sehr kleinen Stichproben erlauben [2, 5], verwenden wir hier eine Methode die der Distance-Korrektur [9, 31] ähnelt:
Wenn aufgefundene Kadavermengen hinreichend groß sind, kann eine abgeschnittene (”trun- cated”) Halb-Normalverteilung bezüglich des Abstandes jedes Kadavers zur anthropogenen Struktur via Maximum Likelihood gefittet werden. Hier ist es wichtig eine abgeschnittene Halb- Normalverteilung übereinstimmend mit den Grenzen des Suchgebietes zu verwenden, da es sonst zu einer drastischen Überschätzung von Ain() kommen kann. Die aus diesem Fit abgeleitete Varianz kann dann wiederum in eine nicht-abgeschnittene Halb-Normalverteilung eingesetzt
werden, um darauf basierend den AnteilAin()zu berechnen, der sich innerhalb der o.g. Gren- zen befindet. Die Varianz / Konfidenzintervalle für Ain()kann dann bspw. mittels Bootstrap der Kadaverdaten ermittelt werden. Hierbei sollten ggf. Moving-Block-Bootstrap Verfahren ein- gesetzt werden, um die zeitlichen (und möglicherweise auch örtlichen) Abhängigkeiten adäquat zu berücksichtigen [11, 20].
Das Verwenden einer (abgeschnittenen) Halb-Normalverteilung ist allerdings nur für statische Strukturen legitim. Bei zusätzlichen ballistischen Effekten (wie z.B. im Kontext von Windturbi- nen) sind komplexere Modelle erforderlich [19]. Es bleibt zu bemerken, dass die Daten vor dem Fitting-Prozess bereits hinsichtlich der Auffind- und Abtransportrate korrigiert sein sollten, um diesbezügliche Verzerrungen zu vermeiden.
Herleitung und Berechnung des Schätzers Nˆ
SeiX~ider mit dem im Suchdurchgangj∈ {1,2, ..., J}aufgefundenen Kadaveriassoziierte Vek- tor, der alle Kovariablen der ”besten” Regressionsmodelles(),ˆ fˆ(),ˆtd()undAˆin()enthält (vgl.
vorherige Abschnitte). Sei weiter D(j,k) die Anzahl an Tagen zwischen Suchdurchgang j und Suchdurchgangk, skaliert durch den Faktorαt(vgl. Abschnitt ”Abräumrate durch Aasfresser”).
Im Folgenden entwickeln wir Korrekturfaktorenθ(ˆX~i), die jeden Kadaver i um die Anzahl an Kadavern (mit gleichen Kovariaten) korrigieren, die ausserhalb des Suchgebietes verendet sind, von Aaasfressern abgeräumt wurden, durch die Sucher übersehen wurden, oder zerfallen sind.
Die Formel für Nˆ zur Abschätzung der wahren Kollisionszahl N basiert auf einer gleichzei- tigen Anwendung / Umgewichtung der Rohdaten durch die in den vorherigen Abschnitten entwickelten Regressionsmodelles(),ˆ fˆ(),tˆd()undAˆin(). Insbesondere istNˆ als die Summe der korrigierten Einzelkadaverθˆ(j)(X~i)und möglichen imputierten fehlenden Datenθˆimputk über
Nˆ =
I
X
i=1
θ(ˆX~i) +
K
X
k=1
θˆkimput (2)
gegeben. Jeder Wertθˆ(j)(X~i)ist wiederum gegeben über θˆ(j)(X~i) = 1
ˆ
sM(D(j,j−1), ~Xi)·fˆ(X~i)·Aˆin(X~i)
− 1−fˆ(X~i) fˆ(X~i)·PJ
n=j+1θˆ(n)(X~i)L(n)j (X~i) ˆAin(X~i)
. (3)
Diese Gleichung muss iterativ gelöst werden um θˆ(j)(X~i)zu erhalten: Indem mitθˆ(J)(X~i) ge- startet wird (welches eindeutig definiert ist, vgl. Appendix 2), ist im Folgenden θˆ(J−1)(X~i) eindeutig gegeben, welches uns θˆ(J−2)(X~i),..., bis hin zuθˆ(j)(X~i)liefert.
Weiterhin benötigen wir zum Lösen der Gleichung 3 die folgenden zwei Definitionen, nämlich ˆ
sM(D(j,j−1), ~Xi) ={s(t, ~ˆ Xi)|t= 1, ..., D(j,j−1)}
sowie
L(j+m)j (X~i) = 1−fˆ(X~i)m−1
·fˆ(X~i)·ˆsM([D(j,j−1), D(j,j+m)], ~Xi),
welche auf Gleichung 1 basieren. Für weitere Details bezüglich der sukzessiven Herleitung dieser Formeln verweisen wir auf den Appendix 2.
Validierung der Schätzmethode
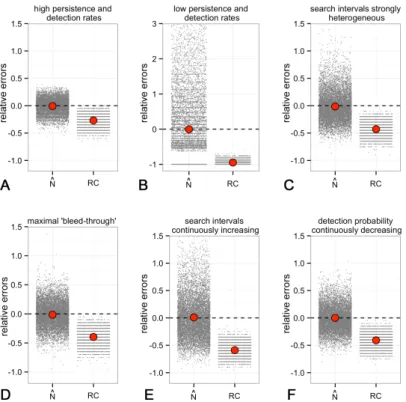
Um die korrekte mathematische Herleitung sowie die fehlerfreie Implementierung der Schätzme- thode in R [28] zu validieren, führten wir umfangreiche Studien mit simulierten Daten durch, wobei die wahre Anzahl an Kollisionsopfern hier bekannt war. Basierend auf diesen virtuel- len Kollisionsdaten kreierten wir (basierend auf Monte-Carlo-Algorithmen) künstliche Feldda- ten, die gegenüber den ursprünglichen Kollisionsdaten hinsichtlich Abtransport, Auffinden, und Verenden ausserhalb des Suchgebietes ausgedünnt waren. Auf diese Felddaten wurde dann der Schätzer angewendet um die ursprüngliche Anzahl an Kadavern zu schätzen. Dieses Prozedere führten wir für verschiedene Extremfälle von Daten durch (z.B. extrem inhomogene Suchinter- valle, niedrige Auffind- oder hohe Abtransportraten, u.s.w.) und für jeden dieser Fälle wieder- holten wir das Ausdünnen und das Schätzen 10.000 mal. Es zeigte sich, dass der Schätzer unter allen Bedingungen verzerrungsfrei arbeitet (Abb. 1)
Abbildung 1: Relative Fehler des Schätzers (Nˆ) und der unkorrigierten Rohdaten (RC) hinsicht- lich der wahren Anzahl an kollidierten Individuen – Simulationsstudie unter mehreren extremen Datenbedingungen. Kleine graue Punkte: Ergebnis einzelner Simulationen. Große rote Punkte:
Empirischer Mittelwert der relativen Fehler.
Schätzung der Varianz
Die Berechnung der Varianz bzw. des Konfidenzintervalles des SchätzwertesNˆ ist nicht trivi- al, da eine ganze Reihe unterschiedlicher Faktoren die Varianz beeinflusst. Insbesondere wenn die Schätzmethode einen hohen Grad an Komplexität zeigt, stoßen analytische Methoden zur Berechnung der Varianz oft an ihre Grenzen [27]. Verfügbare analytische Varianz-Schätzer (wie z.B. in Ref. 30 präsentiert) beziehen sich auf weitaus simplere Modelle verglichen mit dem hier präsentierten. Und selbst im Falle dieser simpleren Modelle führten die analytischen Schätzer zu einer Reihe unterschiedlicher Probleme. Z.B. wurde gezeigt, dass einige dieser analytischen Schätzer nicht verzerrungsfrei sind, und zudem Fehler bei der numerischen Implementierung der recht komplexen Formeln zu zusätzlichen Verzerrungen führten [15].
Bootstrap-Methoden stellen eine mögliche attraktive Alternative zu analytischen Varianz-Schätz- methoden dar [16, 24, 27]. Hier werden sämtliche die Variananz beeinflussenden Ereignisse mit- tels geeigneten Resampling-Algorithmen angewandt auf die Originaldaten nachgestellt, sämt- liche stochastische Prozesse werden dabei basierend auf Monte-Carlo-Simulationen reprodu- ziert [10, 11, 14].
Im Zuge der Berechnung von Nˆ werden verschiedene zugrundeliegende Zufallsprozesse durch empirische Mittelwerte approximiert; diese im folgenden dargestellten Zufallsprozesse führen zu einer Vergrößerung der Varianz und müssen daher im Kontext des Resampling-Verfahrens berücksichtigt werden:
1. Ein kollidierter Vogel kann innerhalb oder ausserhalb des Suchgebietes verenden;
2. Ein Kadaver kann von Aasfressern abgeräumt werden oder nicht;
3. Der Zeitpunkt des Verendens (z.B. zischen zwei Suchdurchgängen) ist variabel und beein- flusst die Abtransportwahrscheinlichkeit bis zum folgenden Suchdurchgang;
4. Ein nicht-abgeräumter Kadaver kann bei einem und allen folgenden Suchdurchgängen vom Sucher entdeckt werden oder nicht;
5. Sämtliche für die Korrekturfaktoren verwendeten statistische Modelle sind verzerrt (auf- grund des Stichprobenfehlers)
6. Die Imputation von fehlenden Werten ist mit entsprechenden Unsicherheiten verbunden.
Eine genaue Motivation und Beschreibung des entwickelten und Verwendeten Resampling- Algorithmus inklusive der Methoden zur Berechnung von Konfidenzintervallen für Nˆ findet sich im Appendix 3.
Die Verwendung von Nˆ im Kontext von statistischen Tests
Der o.g. Bootstrap-Ansatz bezieht sich alleinig auf diejenigen Unsicherheiten / Zufallsprozesse, die bei der Ausdünnung der wahren Kadavermenge M zu der aufgefunden Feldsumme MF und der darauf basierenden Schätzung von MdurchMˆ eine Rolle spielen. In sofern wird hier alleinig die Streuung berücksichtigt, die durch Prozesse und Schätzungen nach dem Anfallen der wahren KadavermengeMbasiert; die wahre Kadavermenge und -summe wird hier erst mal als fest angenommen. Dies ist legitim, wenn die die wahre KadaversummeN für ein spezifisches Gebiet und eine spezifische Periode geschätzt werden soll.
Werden nun jedoch statistische Tests (wie z.B. in unserem Falle der BACI-Test oder die Fusions- modelle) auf die SchätzmengeMˆ angewendet, so spielt neben den o.g. Schätzungs-basierten Un- sicherheiten auch die ”intrinsische” Streuung der Daten eine wichtige Rolle, d.h. die Variabilität in dem DatensatzMdie man beobachten würde, wenn das gesamte Kadaver-Such-Experiment mehrfach durchgeführt werden würde (und die wahre Anzahl der Kadaver jeweils bekannt wä- re). Diese letztgenannte Variabilität wird i. Allg. durch die verwendeten Regressionsmethoden über die Varianz / Standardfehler der jeweiligen Regressionskoeefizienten repräsentiert.
Um korrekte p-Werte zu den Regressionskoeffizienten zu erhalten, müssen sowohl die ”extrinsi- sche Varianz” (VE, als Resultat der Schätzmethode) als auch die ”intrinsische Varianz” (VI, als Resultat der Variabilität in den wahren Kadaverzahlen) in geeigneter Weise kombiniert werden, wobei VE über die Variabilität in den Bootstrap-resamples und VI über die im Kontext der Regression berechneten Standardfehler der Regressionskoeffizienten abgeschätzt werden kön- nen. Analog zu den Techniken der ”Multiplen Imputation” [18, 29, 32] berechnen wir die finale Varianz für einen Regressionskoeffizienten wie folgt: Sei βˆ eine skalare Statistik (wie z.B. ein Regressionskoeffizient), die basierend aufMˆ geschätzt wurde, undVˆI die über die Regressions- methode geschätzte Varianz. Seien weiterβˆ1,βˆ2, ...,βˆmdie skalaren Statistiken die anhand der Boot-Resamples Mˆ1,Mˆ2, ...,Mˆm geschätzt wurden. Dann berechnet sich die Schätzung der Gesamt-VarianzVˆ von βˆüber
Vˆ = ˆVI +m+ 1 m
VˆE,
mitVˆE=Pm
k=1( ˆβ−βˆi)2. Im Wesentlich werden hier also Schätzwerte beider VarianzenVI und VE addiert, einzig der Faktor(m+ 1)/mkorrigiert für die Stochastizität in der Schätzung von VE, die ja auf Resampling beruht.Vˆ ist approximativt-verteilt mitν = (m−1) 1 + m·VˆI
(m+1)·VˆE
2
Freiheitsgraden [18, 29]. Darauf basierend kann dann der p-Wert fürβˆberechnet werden.
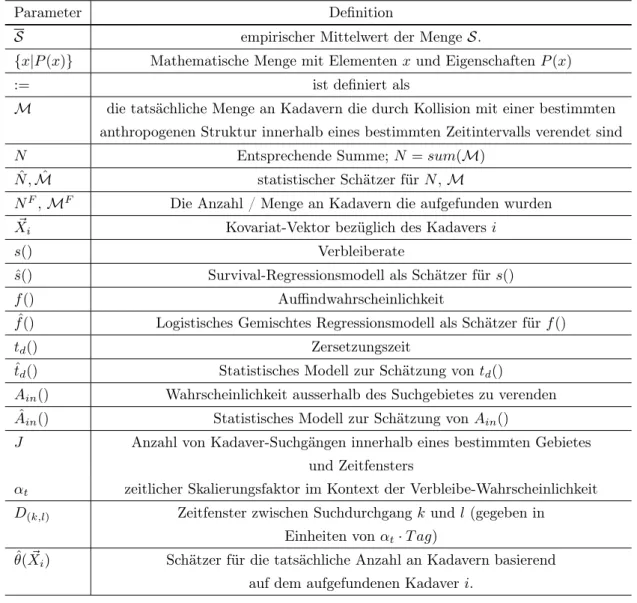
Appendix 1: Notation
1. Notation
Parameter Definition
S empirischer Mittelwert der MengeS.
{x|P(x)} Mathematische Menge mit Elementenxund EigenschaftenP(x)
:= ist definiert als
M die tatsächliche Menge an Kadavern die durch Kollision mit einer bestimmten anthropogenen Struktur innerhalb eines bestimmten Zeitintervalls verendet sind
N Entsprechende Summe; N=sum(M)
N ,ˆ Mˆ statistischer Schätzer fürN,M
NF,MF Die Anzahl / Menge an Kadavern die aufgefunden wurden
X~i Kovariat-Vektor bezüglich des Kadaversi
s() Verbleiberate
ˆ
s() Survival-Regressionsmodell als Schätzer für s()
f() Auffindwahrscheinlichkeit
fˆ() Logistisches Gemischtes Regressionsmodell als Schätzer fürf()
td() Zersetzungszeit
ˆtd() Statistisches Modell zur Schätzung vontd()
Ain() Wahrscheinlichkeit ausserhalb des Suchgebietes zu verenden Aˆin() Statistisches Modell zur Schätzung vonAin()
J Anzahl von Kadaver-Suchgängen innerhalb eines bestimmten Gebietes und Zeitfensters
αt zeitlicher Skalierungsfaktor im Kontext der Verbleibe-Wahrscheinlichkeit D(k,l) Zeitfenster zwischen Suchdurchgangkundl (gegeben in
Einheiten vonαt·T ag)
θ(ˆX~i) Schätzer für die tatsächliche Anzahl an Kadavern basierend auf dem aufgefundenen Kadaveri.
Tabelle 1: Definitionen und Notationen Teil I
θˆimput Imputierte Kadaverzahl für eine Datums-Gebiets-Kombination mit fehlendem Wert NˆiF Bootstrap-Resample der gefundenen KadaversummeNF
Nˆi Bootstrap-Resample vonNˆ
nboot Gesamt-Anzahl der Bootstrap-resamples
Q Skalare empirische Statistik
Qreal tatsächlicher Wert, approximiert durchQ
E(X) Erwartungswert vonX
Tabelle 2: Definitionen und Notationen Teil II
Appendix 2: Herleitung des Schätzers N ˆ
Im Folgenden präsentieren wir eine detaillierte Herleitung des Schätzers Nˆ, gegeben durch Gleichung 3 im Haupt-Manuskript.
Verbleib- und Auffindkorrektur
Die Korrektur der Rohdaten um die Auffind- und Abtransportprozesse mittels Korrekturtermen θˆ(s,f)(X~i)basiert im Wesentlichen um Erweiterungen der Ansätze die in ”Sightability Modellen”
verwendet wurden [3, 12, 25, 27]. Eine erste naive Abschätzung der korrigierten Anzahl ist durch θˆ(j)(s,f)(X~i) = 1
ˆ
sM(D(j,j−1), ~Xi)·fˆ(X~i) (4) gegeben. Da der exakte Zeitpunkt des Vogelschlags für jeden Kadaver unbekannt ist, istsˆM(D(j,j−1), ~Xi) als der empirische Mittelwert über alle möglichen Zeitpunkte definiert, also
ˆ
sM(D(j,j−1), ~Xi) :={s(t, ~ˆ Xi)|t= 1, ..., D(j,j−1)}. (5) Wir nehmen hier an, dass die Kollisionswahrscheinlichkeit konstant in der Zeit ist. Wenn diese typische zeitabhängige Muster zeigt, sollte eine entsprechende Gewichtungsfunktion (abhängig von der Tageszeit) mit den WertensˆM(t, ~Xi)multipliziert werden.
Weiterhin is es wichtig anzumerken dass für den ersten Suchdurchgang gilt, dass Kadaver aus be- liebigen vorherigen Zeitpunkten die Schätzungen verzerren würden. Es ist daher empfohlenDbef
Tage vor dem ersten regulären Suchdurchgang eine aussergewöhnlich intensive Suche durchzu- führen um möglichst alle existierenden Kadaver zu beseitigen, um anschliessend D(1,0)=Dbef
für den ersten regulären Suchdurchgang zu setzen.
”Bleed-through”
Nun haben wir die Tatsache zu berücksichtigen, dass Kadaver in einem Suchdurchgang über- sehen und dann in späteren Suchdurchgängen gefunden werden können (”bleed-through”). Von den o.g. 1/ sˆM(D(j,j−1), ~Xi)·fˆ(X~i)
=:CKadavern werden im Durchschnitt
C·ˆsM(D(j,j−1), ~Xi)·(1−f(ˆX~i)) = (1−fˆ(X~i))
fˆ(X~i) =:K (6) Kadaver nach demj-ten Suchdurchgang im Gelände verbleiben, dennKstellt also die Anzahl an Kadavern dar, die bis zum Ende desj-ten Suchdurchgang weder von Aasfressern abgeräumt noch von Zählern gefunden wurden. SeiD(j,j+m)nun die Anzahl an Tagen bis zum(j+m)-ten Suchdurchgang nach dem Durchgang mit dem Indexj. In diesem Fall ist die durchschnittliche Wahrscheinlichkeit einen von denK Kadavern beim Suchdurchgang mit der Nummer(j+m) durch
1−fˆ(X~i)m−1
·fˆ(X~i)·ˆsM([D(j,j−1), D(j,j+m)], ~Xi) =:L(j+m)j , (7)
gegeben, wobei ˆ
sM([D(j,j−1), D(j,j+m)], ~Xi) :={s([t, Dˆ (j,j+m)], ~Xi)|t= 1, ..., D(j,j−1)}. (8) (für die Definition vons([t, Dˆ (j,j+m)], ~Xi)siehe im Haupt-Manuskript). Übersetzt bedeutet dies:
Einer der K Kadaver wurde während des(j+m)-ten Suchdurchganges aufgefunden ohne bei einem der vorherigen Suchdurchgänge gefunden oder abtransportiert worden zu sein. Es gilt jedoch zu beachten, dass dieser im Suchdurchgang(j+m) gefundene Kadaver wiederum mit einem Korrekturfaktor θˆ(s,f)(j+m) multipliziert werden würde (da wir ja nicht wissen, dass es ein
”bleed-through-Fund” ist, was wiederum zu entsprechenden Verzerrungen führen würde. Dies würde bedeuten, dass insgesamt (bezogen auf alle folgenden Suchdurchgänge)
K·
J
X
n=m+1
θˆ(n)(s,f)L(n)j (9)
Kadaver ”zu viel” in dem Schätzer Nˆ berechnet werden würden. Wir definieren daher den korrigierten Schätzer über
θˆ(s,f)(j) = 1 ˆ
sM(D(j,j−1), ~Xi)·fˆ(X~i)−K·
J
X
n=j+1
θˆ(s,f)(n) L(n)j . (10)
Hier können die Werte θˆ(s,f)(n) iterativ bestimmt werden: Basierend auf θˆ(s,f)(J) = 1/ f(ˆX~i)· ˆ
sM(D(J,J−1), ~Xi)
(d.h., es werden keine Kadaver nach dem Suchdurchgang J gefunden) er- geben sich alle anderen Werteθˆ(J−1)(s,f) ,θˆ(s,f)(J−2), ...,θˆ(s,f)(j) sukzessiv über die Formel
θˆ(s,f)(m) = 1 ˆ
sM(D(m,m−1), ~Xi)·fˆ(X~i)−K·
J
X
n=m+1
θˆ(s,f)(n) L(n)j . (11)
Zerfall und Verenden ausserhalb des Suchgebietes
In dem Fall, dass die Zerfallszeitˆtd(X~i)in einem unabhängigen Experiment approximiert wur- de, setzen wir im letzten Schritt der o.g. Iteration (d.h. beim Berechnen vonθˆ(s,f)(j) basierend auf Gleichung 10)L(n)j = 0wennD(j,n)>ˆtd(X~i)gilt. Auf diesem Wege berücksichtigen wir die Tatsache, dass Kadaver nach mehr alstˆd(X~i)nicht mehr aufgefunden werden können.
θˆ(j)(s,f)(X~i)kann nun einfach um den Anteil an Kadavern korrigiert werden, die ausserhalb des Suchgebietes verenden, nämlich indem stattdessen
θˆ(j)(s,f)(X~i)
Aˆin(X~i) =: ˆθ(j)(X~i) (12) berechnet wird.
Imputation von fehlenden Werten
Es mag vorkommen dass bestimmte (Unter-)Gebiete zu bestimmten Zeitpunkten nicht erfasst werden können, bspw. durch extrem hohe Vegetation oder landwirtschaftliche Nutzung. Insbe-
sondere für die Schätzung der absoluten Kadaversummen (z.B. pro km) ist es notwendig, diese Werte zu imputieren. Im Folgenden bedienen wir uns hierfür den Techniken der (multiplen) Imputation [8, 29, 32]. Auf der einen Seite bietet dieser Ansatz eine elegante Methode dafür, fehlende Werte in Abhängigkeit von der durchschnittlichen (jahres-)zeitlichen und örtlichen Entwicklung zu interpolieren. Auf der anderen Seite erlauben diese Methoden die durch die Interpolation verursachten Unsicherheiten korrekt in finale Signifikanzwerte zu propagieren.
In der Praxis addieren wir hierfür zuerst alle korrigierten Kadaverwerte (gegeben durch Glei- chung 12) für jede existierende Datums-Untergebiet-Kombination auf. Anschliessend fitten wir den den zeitlichen örtlichen Verlauf über ein Generalisiertes Additives Regressionsmodell (GAM) [29]. Wir wählen hier ein GAM statt eines GLM(M)s da wir denken, dass ein additiver Prediktor das in hohem Maße nichtlineare saisonale Verhalten von Vogelzug und -brutgeschehen am besten beschreiben kann. Zum Schluss imputieren wir die Werteθˆ1imput, ...,θˆimputK basierend auf der Vorhersage des GAMs, wobei hier eine Poisson-Verteilung aufgrund der Count-Data zugrundegelegt wird [33, 34].
Der finale Schätzer berechnet sich nun aus den Schätzwerten θˆ1...,θˆI sowie den imputierten Wertenθˆ1imput, ...,θˆimputK und ist gegeben durch
Nˆ =
I
X
i=1
θˆi+
K
X
k=1
θˆimputk . (13)
Appendix 3: Resampling Algorithmus
Hier präsentieren und motivieren wir das detaillierte Bootstrap-Resampling-Schema welches dazu dient, die mit den Korrekturfaktoren verbundenen Unsicherheiten korrekt in die finalen Kadaverzahlen zu übertragen, bzw. entsprechende Konfidenzintervalle zu berechnen.
Die Basis-Idee besteht (wie bei allen Bootstrap-Algorithmen) darin, dass tatsächlich stattfin- dende (Varianz-produzierende) Prozesse mittels Monte-Carlo-Simulationen nachgestellt werden, und um so die tatsächlich zu erwartende Streuung virtuell nachzuempfinden. Es gilt zu beach- ten, dass bei dem im Folgenden präsentierten Algorithmus ausschließlich diejenigen Varianz- produzierenden Prozesse berücksichtigt werden, die bei der Reduktion der tatsächlichen Ka- daverzahl N zur ”Feldsumme” NF (z.B. Todeszeitpunkt, Abtransport, Auffinden, ausserhalb des Suchgebietes verenden) und bei den zusätzlichen Feldexperimenten eine Rolle spielten, und somit die Schätzung vonN durchNˆ beefinflussten.Nselbst wird hier also als fix angenommen, was bedeutet, dass wir über den präsentierten Algorithmus Konfidenzintervalle für Kadaver- summen von spezifischen Perioden / Flächen berechnen. Im Kontext von statistischen Tests allerdings müsste zusätzlich noch die Streuung des Wertes N selbst um einen zugrunde lie- genden Mittelwert berücksichtigt werden, die zu beobachten wäre, wenn dasselbe Experiment mehrfach durchgeführt werden würde (mehr Details finden sich im Abschnitt ”Die Verwendung vonNˆ im Kontext von statistischen Tests”).
Das verwendete Resampling-Schema umfasst die folgenden Schritte:
1. Wir wenden unsere Schätzmethode auf die original-Kadaverdaten (mit entsprechenden Kovariaten) an und erhalten darüber einen Datensatz mit korrigierten Werten, M, derˆ die wahre Menge Mapproximiert.
2. Mˆ wird wieder in Einzelbeobachtungen (plus Rest) aufgesplittet, wobei die jeweiligen Kovariate erhalten bleiben. Dieser Datensatz simuliert die tatsächliche Gesamtmenge an Vogelschlagopfern, bevor Abräum-, Auffind,- u.s.w. Prozesse stattgefunden haben.
3. Auf jeden der Kadaver in diesem Datensatz wenden wir virtuell sämtliche Zufallsprozesse an, die den finalen Schätzwert beeinflussen. Insbesondere sind dies:
• Zufälliger Zeitpunkt des Verendens zwischen zwei Suchdurchgängen
• Zufälliges Verenden ausserhalb des Suchgebietes
• Zufälliger Abtransport durch Aasfresser basierend auf dem zeitlichen Abstand zum Verenden sowie auf allen weiteren Kovariaten
• Zufälliges Auffinden / Übersehen durch suchende Personen, basierend auf den Ko- variaten.
Beim virtuellen Übersehen eines Kadavers wird dieser auf das Datum des kommenden Suchdurchgangs verschoben, nachdem wiederum ein möglicher Abtransport durch Aas- fresser stattgefunden hat, sodass ”Bleed-through” (das Auffinden zu späteren Suchdurch- gängen) berücksichtig wird. Für alle diese Monte-Carlo-Simulationen von Zufallsprozes- sen verwendeten wir diejenigen Wahrscheinlichkeiten, die uns durch die Regressionsmo- delle der entsprechenden Feldexperimente vorhergesagt wurden. Allerdings wird hier die Regression nicht mit den Originaldaten sondern mit geeigneten Resamples der experi- mentellen Daten durchgeführt. Dies berücksichtigt den Stichprobenfehler, der bei jedem Experiment entsteht.
Es resultiert ein ”virtueller Datensatz von aufgefundenen Kadavern” MFi .
4. Zum Schluss berechnen wir basierend auf MFi eine neue Schätzmenge Mˆi, so wie es in dem Anschnitt ”Herleitung und Berechnung des Schätzers Nˆ” beschrieben wurde. Bei der Imputation folgten wir der Idee der ”Multiplen Imputation” und streuten für jedes Resample erst den Erwartungswert des GAMS gemäß seines Standardfehlers an den zu imputierenden Stellen, um darauf basierend dann Kadaverzahlen mit einem zufälligen Poisson-Prozess zu generieren. Diese Vorgehenseise berücksichtigt die Unsicherheiten, die mit der Imputation von Daten verknüpft sind [18, 29, 32].
Die Resample-SchätzmengeMˆikann nun dafür genutzt werden einen Bootstrap-Resample- Wert von Interesse zu generieren, wie z.B. ein Resample der geschätzten Gesamtsumme Nˆi, oder den Parameter eines aufMˆi angewendeten Regressionsmodells.
Im Falle der Schätzung einer Kadaversumme folgt eine Menge von Resample-Werten{Nˆ1,Nˆ2, ...}
die nun dafür verwendet werden kann, Konfidenzintervalle fürNˆ zu berechnen. Da es sich bei ei- ner Summe wieNˆ um eine nicht-pivotale Quantität handelt (der Standardfehler vonNˆ varriiert mit der Größe des Schätzwertes selbst), müssen Methoden verwendet werden die diese Verzer- rung korrigieren. Zudem beobachten wir, dass die Bootstrap-ResamplesNˆi oft im hohen Maße nicht-normal umNˆ streuen. Wir verwenden daher zur Berechnung der Konfidenzintervalle von Nˆ die moderne ”non-parametric bias-corrected and accelerated (BCa) Bootstrap-Methode” [13],
die nicht-Normalität und nicht-Pivotalität berücksichtigt.
Insgesamt wurdenN = 1100Resample-MengenMˆibasierend aufMˆ generiert, und dienten als Basis für Berücksichtigung der mit der Schätzmethode einhergehenden Unsicherheiten in allen präsentierte finalen p-Werten und Kadaversummen.
Literatur
[1] H. Akaike. Information theory and an extension of the maximum likelihood principle.
International Sympossium on Information Theroy, Second Edition:267–281, 1973.
[2] N. Bech, S. Beltran, J. Boissier, J. F. Allienne, J. Resseguier, and C. Novoa. Bird mortality related to collisions with skilift cables: do we estimate just the tip of the iceberg? Animal Biodiversity and Conservation, 35 (1):95–98, 2012.
[3] J Bernardino, R Bispo, H Costa, and M Mascarenhas. Estiating bird and bat fatality at wind farms: a practical overview of estimator, their assumptions and limitations. New Zealand Journal of Zoology, 40 (1):63–74, 2013.
[4] J Bernardino, R Bispo, M Mascarenhas, and H Costa. Are we properly assessing bird and bat mortality at onsore wind farms? Proceedings of the 32nd Annual Meeting of International Association for Impact Assessment., 2012.
[5] K Bevanger. Estimates and population consequences of tetraonid mortality caused by collisions with high tension power lines in Norway. J Appl Ecol, 32:745–753, 1995.
[6] R. Bispo, J. Bernardino, T.A: Marques, and D. Pestana. Modeling carcass removal time for avian mortality assessment in wid farms using survival analysis. Environ Ecol Stat, 2012.
[7] R. Bispo, J. Bernardino, T:A: MArques, and D. Pestana. Discrimination between para- metric survivial models for removal times of bird carcasses in scavenger removal trials at wind turbine sites. Studies in Theoretical and Applied Statistics, pages 65–72, 2013.
[8] C.J.F.T. Braak, A.J van Strien, R. Meijer, and T.J. Verstrael. Analysis of monitoring data with missing values: which method? Proceedings of the 12th international confenrence of IBCC and EOAC, pages 663–673, 1994.
[9] S.T. Buckland, D.R. Anderson, K.P. Burnham, J.L. Laake, D.L. Borchers, and L. Tho- mas. Introduction to Distance Sampling: Estimating Abundance of Biological Populations.
Oxford University Press, New York, 2001.
[10] A.J. Canty, A.C. Davidson, D.V. Hinkley, and V. Ventura. Bootstrap diagnostics and remedies. The Canadian Journal of Statistics, 34(1):5–27, 2006.
[11] A.C. Davison and D.V. Hinkley. Bootstrap Methods and Their Application. Cambridge University Press, 1997.
[12] D.R. Diefenbach, D.W. Brauning, and J.A. Mattice. Variability in grassland bird counts related to observer differences and species detection rates. The Auk, 120(4):1168–1179, 2003.
[13] B. Efron. Better bootstrap confidence intervals. Journal of the American Statistical Asso- ciation, 82(397):171–185, 1987.
[14] B. Efron and R.J. Tibshirani:. An introduction to the bootstrap. New York: Chapmann &
Hall, 1993.
[15] J.R. Fieberg. Estimating population abundance using sightability models: R sightability- model package. Journal of Statistical Software, 51 (9), 2012.
[16] J.R. Fieberg. Written communication. 2015.
[17] T. Grünkorn, A. Diedrichs, B. Stahl, D. Poszig, and G. Nehls. Entwicklung einer Metho- de zur Abschätzung des Kollisionsrisikos von Vögeln an Windenergieanlagen - Endbericht 2005. Bio Consult SH, 2005.
[18] Ra Hughes, Jac Sterne, and K. Tilling. Comparison of imputation variance estimators.
Stat Methods Med Res, Apr 2014.
[19] M. M. P. Huso and D. Dalthorp. Accounting for unsearched areas in estimating wind turbine-caused fatality. The Journal of Wildlife Management, 78(2):347–358, 2014.
[20] Hyunsu Ju. Moving block bootstrap for analyzing longitudinal data.Commun Stat Theory Methods, 44(6):1130–1142, 2015.
[21] F. Korner-Nievergelt, P. Korner-Nievergelt, O. Behr, I. Niermann, R. Brinkmann, and B. Hellriegel. A new method to determine bird and bat fatality at wind energy turbines from carcass searches. Wildlife Biology, 17:350–363, 2011.
[22] Fränzi Korner-Nievergelt, Oliver Behr, Robert Brinkmann, Matthew A. Etterson, Manuela M. P. Huso, Daniel Dalthorp, Pius Korner-Nievergelt, Tobias Roth, and Ivo Niermann.
Mortality estimation from carcass searches using the r-package carcass: a tutorial.Wildlife Biology, 21:30–43, 2015.
[23] Fränzi Korner-Nievergelt, Robert Brinkmann, Ivo Niermann, and Oliver Behr. Estimating bat and bird mortality occurring at wind energy turbines from covariates and carcass searches using mixture models. PLoS One, 8(7):e67997, 2013.
[24] S. Lohr. Sampling: design and analysis. Second edition. Brooks/Cole, Pacific Grove, Cali- fornia, USA, 2010.
[25] J.A. Manning and E.O. Garton. A sightability model for correcting visibility and availibi- lity bias in standardized surveys of breeding burrowing owls in southwest agroecosystem environments. Management and Conservation, 76(1):65–74, 2011.
[26] J. Paula, R. Bispo, A. Leite, P. Pereira, H. Costa, C. Fonseca, M. Mascarenhas, and J Bernardino. Camera-trapping as a methodology to assess the persistence of wildife cacarcass resulting from collisions with human-made structures. Wildlife Research, 2015.
[27] A.T. Pearse, P.D. Gerard, S.J. Dinsmore, R.M. Kaminski, and K.J. Reinecke. Estimation and correction of visibility bias in aerial surveys of wintering ducks.The Journal of Wildlife Management, 72(3):808–813, 2008.
[28] R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria., ISBN 3-900051-07-0, URL http://www.R- project.org/, 2016.
[29] D.B. Rubin. Multiple Imputation for Nonresponse in Surveys. J. Wiley & Sons, New York, 1987.
[30] R.K. Steinhorst and M.D. Samuel. Sightability adjustment methods for aerial surveys of wildlife populations. Biometrics, 45:415–425, 1989.
[31] L. Thomas, S. T. Buckland, K. P. Burnham, D. R. Anderson, J. L. Laake, D. L. Borchers, and S. Strindberg. Distance Sampling. John Wiley & Sons, Ltd, Chichester, 2002.
[32] C.Y. Yuan. Multiple imputation for missing data: Concepts and new development.
http://www.ats.ucla.edu/stat/sas/library/ multipleimputation.pdf, pages 267–25, 2004.
[33] A. Zuur, E. Ieno, and G.M. Smith. Analysing Ecological Data. Springer Science+Business Media, LLC, 2007.
[34] A.F. Zuur, E.N. Ieno, N.J. Walker, A.A. Saveliev, and G.M. Smith. Mixed Effect Models and Extensions in Ecology with R. Springer Science+Business Media, LLC, 2009.