Research Collection
Master Thesis
Person-Specific Gaze Estimation for Unconstrained Real-World Interactions
Author(s):
Venzin, Valentin Publication Date:
2020
Permanent Link:
https://doi.org/10.3929/ethz-b-000406765
Rights / License:
In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use.
Person-Specific Gaze Estimation for Unconstrained Real-World
Interactions
Valentin Venzin
Master Thesis February 2020
Supervisors:
Dr. Xucong Zhang Mihai Bâce
Prof. Dr. Otmar Hilliges
EtH
Eidgendssische Technische Hochschule ZUrich Swiss Federal Institute of TechnoLogy Zurich
Declaration of originality
The signed declaration of originality is a component of every semester paper, Bachelor’s thesis, Master’s thesis and any other degree paper undertaken during the course of studies, including the respective electronic versions.
Lecturers may also require a declaration of originality for other written papers compiled for their courses
I hereby confirm that I am the sole author of the written work here enclosed and that I have compiled it in my own words. Parts excepted are corrections of form and content by the supervisor
Title of work (in block letters):
Person-Specific Gaze Estimation for Unconstrained Real-World Interactions
Authored by (in block letters)
For papers written by groups the names of an authors are required.
Name(s):
Venzin
First name(s):
Valentin
With my signature I confirm that
I have committed none of the forms of plagiarism described in the 'Citation etiquette’ information sheet
I have documented all methods, data and processes truthfully.
I have not manipulated any data.
I have mentioned all persons who were significant facilitators of the work I am aware that the work may be screened electronically for plagiarism.
Place, date Signature(s)
dahL:
ZClrich, 16.02.2020 UQAA£w
For papers written by groups the names of all authors are required. Their signatures collectively guarantee the entire
Abstract
Eye gaze is a promising input modality for attentive user interfaces and interactive applications on various devices. Appearance-based methods estimate the gaze direction from a monocular RGB camera and can therefore easily be deployed on unmodified devices. However, the accu- racy of appearance-based methods is limited by person-specific anatomical variation. Personal calibration is therefore necessary to achieve practical gaze estimation accuracy for real-world applications. Depending on the use case, collecting personal calibration samples could be im- practical or a tedious task for the user. In this thesis, we propose a novel method to improve few-shot person-specific gaze estimation in unconstrained environments. We leverage gaze redirection as a way to augment personal calibration data and learn a multilayer perceptron to map person-independent gaze predictions to more accurate, person-specific gaze directions.
Our method achieves promising results in a cross-device setting with unreliable calibration data which was collected without the user’s active collaboration. Our method improves the person-independent gaze estimation error by 17.9% with only two calibration samples on mo- bile phones, thus improving accuracy while keeping the cost of collecting calibration data low.
Finally, we propose a novel filter to remove unreliable samples from implicit calibration data.
This filter further improves the gaze estimation accuracy in some scenarios, paving the way for a more user-friendly integration of eye gaze into interactive systems.
Acknowledgments
I would especially like to thank my supervisors Dr. Xucong Zhang and Mihai Bâce for introduc- ing me to this project at the intersection of my research interests: Deep Learning and Human Computer Interaction. Their guidance, suggestions and feedback had a very positive impact on the outcome of this work. Thank you also to Seonwook Park for the helpful discussions and for providing crucial insight regarding the topic of gaze redirection.
I want to thank Prof. Dr. Otmar Hilliges for making this project possible and for reviewing this thesis as an examiner. A big ‘thank you’ also to the members of the AIT lab for being welcoming and for providing a generous workplace with ample resources.
I am grateful to my parents, Maria and Gabriel, for the opportunities they provided. My studies and experiences in Zürich would not have been possible without their unfailing support and encouragement.
Finally, I want to thank my friends Oliver, Luan, Flurin, Heidi, Philip and Felix for their con- tinuous support during this time.
Zürich, February 2020 Valentin Venzin
Contents
1 Introduction 3
2 Related Work 7
2.1 Gaze Estimation . . . 7
2.2 Person-Specific Gaze Estimation . . . 8
2.3 Gaze Redirection . . . 9
3 Method 11 3.1 Overview . . . 11
3.2 Gaze Estimator . . . 13
3.3 Gaze Redirector . . . 14
3.3.1 Pairing Training Samples . . . 16
3.4 Personal Gaze Adaptation . . . 16
3.4.1 Filtering Seed Calibration Samples . . . 17
4 Experiments 21 4.1 Datasets . . . 21
4.2 Gaze Estimator Baseline . . . 22
4.2.1 Cross-Dataset Experiments . . . 22
4.2.2 Within-Dataset Cross-Person Experiments . . . 23
4.3 Gaze Estimation on Redirected Samples . . . 24
4.3.1 Relative Gaze Redirection . . . 26
4.3.2 Quality of Redirected Samples . . . 28
4.4 Personal Calibration . . . 31
4.4.1 Calibration Baseline . . . 31
4.4.2 Personal Calibration using Redirected Samples . . . 31
Contents
4.4.3 Using Implicit Cross-Dataset Calibration Samples . . . 35
5 Conclusion 39
5.1 Future Work . . . 41
Bibliography 43
Contents
1
Introduction
Eye gaze conveys important non-verbal cues such as emotion or intent. Gaze is for example informative about what a person is referring to while talking. Eyes can also be used to ac- tively express feelings, for instance by eye rolling. Understanding and accurately estimating human gaze is therefore a core requirement for next-generation attentive user interfaces and other gaze-based applications. Current gaze-based interactive systems have been successfully used to explicitly control the interface of a public display [57, 56] or as an alternative interaction modality for people with motor disabilities [23, 26]. Gaze can also be used implicitly as a way to passively monitor audience attention [41] or to analyze social interaction [17].
Most gaze estimation systems require special-purpose equipment that hinders wide-scale de- ployment. A promising area of research aiming to mitigate this limitation is appearance-based gaze estimation using a single off-the-shelf RGB camera. The approach is especially interest- ing considering that many modern commodity devices feature a built-in camera, hence allowing for easy deployment. Recent methods leverage large amounts of training data to learn person- independent gaze estimator CNNs [54, 22, 55, 58, 6, 30].
These systems may not be accurate enough to support fine-grained interactions due to personal variability in appearance and eye geometry among individuals. Zhang et al. [53] report 6.4 degrees angular error using a person-independent gaze estimator in a challenging in-the-wild setting. They improve the angular error by over 60% to 2.5 degrees by fitting a personal gaze adaptation function which maps initial gaze predictions to person-specific gaze estimates. A large number (>50) of personal calibration samples are typically required to fit the mapping function. A calibration sample consists of an eye or face image and the corresponding gaze di- rection. Samples are usually collected by asking the user to fixate a sequence of visual markers on the screen. Ground truth gaze directions can be inferred from the coordinates of the mark- ers, the camera-screen relationship and the 3D head pose of the user in the camera coordinate system.
1 Introduction
Collecting personal calibration samples is tedious, cumbersome, and negatively influences the interaction experience [43]. In some application scenarios, such as for public displays, explicitly collecting calibration samples is not feasible because collaboration of the user is not guaranteed.
Moreover, interaction times might be too short to be preceded by a time consuming calibration sequence. Implicit collection of calibration samples alleviates this restriction by not requiring the user’s active participation. Implicit calibration samples can, for example, be collected while the user plays mobile games [50], reads [20] or watches videos [38]. Another option is to extract samples from mouse-click events during ordinary computer usage, assuming the user looks at the position of the cursor while performing the click [39, 14]. The drawback of collecting implicit calibration samples is lower accuracy of ground truth gaze directions, consequently worsening the performance of personal gaze adaptation methods.
The goal of this thesis is to improve person-specific gaze estimation in real-world settings, leveraging the gaze redirection technique for domain specific data augmentation. Given an input eye image, the task of gaze redirection is to generate a novel synthetic eye image, similar to a real sample, such that the depicted gaze direction matches the desired target gaze. Instead of directly specifying the target gaze, one can formulate a differential gaze redirector where the desired change in gaze direction is specified. Relative gaze redirection is better suited to aid personal calibration because it preserves personal gaze bias. Gaze redirection has previously been used to facilitate eye contact during video conferencing [33, 45, 8] and for video editing or post-production of movies [47].
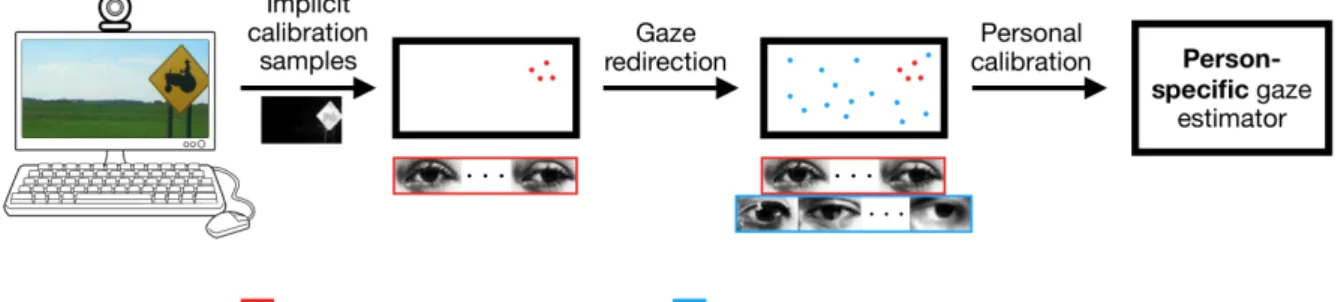
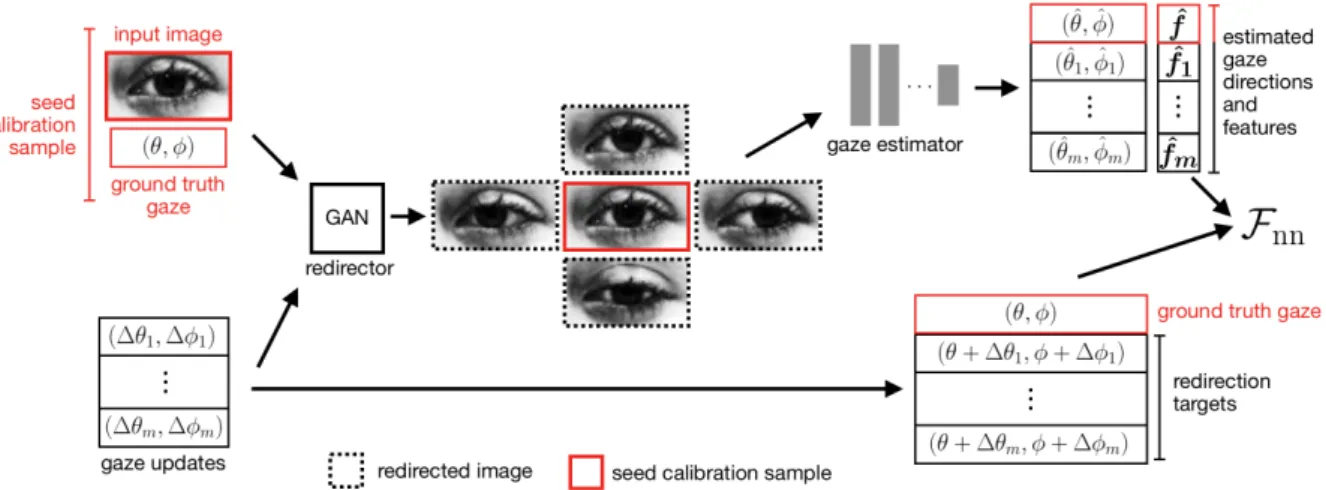
Figure 1.1:Method overview. Given a small set of implicit calibration samples, we synthesize additional gaze-redirected calibration samples. The samples are then used to fit a calibration function that maps the output of a person-independent estimator to a person-specific gaze estimate.
(Saliency images taken from [37].)
Figure 1.1 shows an overview of our method. Given a fewseed calibration samples, our method finds a mapping function which adapts the output of a pre-trained, person-independent gaze es- timator to a more accurate, person-specific gaze prediction. A pre-trained gaze redirector gen- erates additionalredirected calibration samples, using the previously collected seed samples as input. The target gaze directions can be chosen such that the entire gaze range of interest is covered, therefore keeping the number of required seed calibration samples low. The resulting set of seed- and redirected calibration samples is used to train a multilayer perceptron for per- sonal gaze adaptation. Overfitting can be avoided by generating a large number of redirected calibration samples.
To further improve the usability of interactive systems, we investigate the potential of gaze redi-
rection as a way to detect reliable calibration samples. Implicitly collected calibration samples are inherently unreliable. For example, when collecting samples based on mouse-click events [39], a common assumption is that the user looks at the cursor while performing the click.
However, this might not always be the case. Moreover, samples with eye occlusions might occur more frequently because the user is – by design – not actively paying attention to the calibration procedure.
We build on the assumption that reliable seed samples produce better quality redirections. That is, the estimated gaze directions of the generated eye images better match the corresponding target gaze directions. When specifying relative redirection angles, the error in the annotated gaze direction of the unreliable calibration sample would propagate to its redirections. Input images with artifacts or occlusions could cause erratic gaze redirections. To score a seed cali- bration sample, we compute the Earth Mover’s Distance1 – a similarity measure between two probability distributions – between the estimated gaze directions of its redirected eye images and the corresponding target gaze directions. Only the top-scoring seed calibration samples and their redirected calibration samples are used to fit the calibration function.
The contribution of this thesis is three-fold.
1. We explore the feasibility of cross-dataset person-specific gaze estimation using gaze redirection for domain specific data augmentation. We focus on implicit calibration data collected in real-world settings.
2. We propose a way to filter out low quality seeds and redirected calibration samples.
3. We conduct extensive analysis on the redirection and calibration components of our method, providing useful insight regarding various design choices.
Our method requires less than three calibration samples to improve personal gaze estimation in real-world settings. In a within-dataset cross-person experiment with explicit calibration sam- ples we outperform a calibration-free gaze estimator baseline by 10% using only two calibration samples. In a cross-dataset setting, our method outperforms the calibration-free baseline using a single seed sample. Depending on the target device, improvements range from 2.6% to 13.3%
using calibration data from real-world settings. Finally, we show that filtering out unreliable implicit seed samples can improve gaze estimation performance in some cases.
1http://homepages.inf.ed.ac.uk/rbf/CVonline/LOCAL_COPIES/RUBNER/emd.htm
1 Introduction
2
Related Work
This thesis relates to previous work on gaze estimation, personal calibration and gaze redirec- tion. We discuss the most relevant works respectively in sections 2.1, 2.2 and 2.3.
2.1 Gaze Estimation
Gaze estimation is the task of estimating human gaze directions. Methods can broadly be cate- gorized into model-based and appearance-based approaches [11].
Model-based approaches fit a geometric model of the eye to the input image. The gaze direction is inferred from the relation of certain model elements such as the eyeball center or the iris.
Model-based gaze estimation can further be subdivided into shape-based and reflection-based methods. Reflection-based methods [34, 13, 59, 60] require an external infrared light source to create reflections (glints) on the cornea – the outermost layer of the eye. The reflections are used to extract eye features for model fitting. While commercial implementations in eye- tracking hardware outperform appearance- and shape-based methods [53], they can be sensitive to illumination perturbations and do not work for large distances. Shape-based methods [2, 18, 42, 31] directly fit an eye model to visual features in the image such as eye corners, pupil center or the edge of the iris. However, high resolution eye images may be necessary for robust feature extraction. These requirements and the potential need for dedicated hardware have largely prevented model-based methods to be deployed in in-the-wild settings.
In contrast, appearance-based methods aim to directly map image pixels to gaze directions, enabling easy integration with a wide range of commodity devices. Because no visual eye features are required, these methods outperform model-based approaches in settings where a large user-camera distance results in low resolution input images [53].
2 Related Work
Appearance-based methods [55, 6, 30, 22, 58] leverage large amounts of training data to tackle challenges such as varying illumination conditions, head motion and (partial) occlusions. Early datasets contained a fixed number of gaze targets [44, 36], thus being of limited use to train robust gaze estimators. The UT-Multiview [40] and Eyediap [7] datasets feature a larger number of gaze directions and head poses. However, they were recorded in a laboratory setting with respectively one and two fixed lighting conditions.
More recent datasets cover a wide variety of gaze directions, head poses, illumination conditions and inter-person variability. GazeCapture [22] and TabletGaze [16] were recorded using the front facing camera of handheld devices during everyday usage. While the in-the-wild nature of the datasets is suitable to learn robust gaze estimators for unconstrained settings, the datasets were annotated with 2D gaze points rather than with 3D gaze directions, hence making them less suitable for cross-device applications. Instead, we used MPIIGaze [55] in our experiments since its calibration samples are annotated with 3D gaze vectors and were also recorded in-the- wild. Gaze estimators trained on MPIIGaze can achieve state-of-the-art performance despite containing fewer calibration samples than GazeCapture or TabletGaze [29].
The increasing scale and availability of training data has given rise to a variety of learning-based methods. Early approaches include linear regression [25], random forests or k-nearest neigh- bors [40]. Recent works focus on convolutional neural networks (CNNs), often building on architectures that have proven themselves in image classification tasks. GazeNet [55], for ex- ample, adapts the VGG16 [35] architecture to take the head pose (pitch and yaw) as additional input modality and to output gaze directions instead of probability distributions for image clas- sification. Park et al. [30] propose an architecture with intermediate supervision in form of a pictorial eye representation, outperforming GazeNet in experiments on MPIIGaze. While, in- tuitively, the gaze direction is closely related to the eye region, it has been shown that using the full face image as input can improve the accuracy of gaze estimation [22, 58]. Zhang et al. [50]
propose an architecture with device specific encoders and decoders but shared feature encoding layers, improving cross-device gaze estimation.
In this thesis, we focus on single eye inputs for gaze estimation to better accommodate gaze redirection methods which generate novel training images. Due to its simplicity and the avail- ability of pre-trained weights for parts of the network, we use GazeNet as the backbone for gaze estimation in our method.
2.2 Person-Specific Gaze Estimation
Several works focus on person-independent gaze estimation [54, 55, 58, 30], relying on di- verse datasets such as MPIIGaze [55] for interpersonal variability. Calibration-free methods have been used for passive attention analysis on unmodified devices [28] and public displays [41] or for eye contact detection [51]. While person-independent gaze estimation has demon- strated its potential in real-world applications, gaze estimates are coarse grained due to person- specific anatomical differences. Zhang et al. [55] report a 53.7% performance improvement when training a person-specific gaze estimator (training and testing on calibration data from the same person) as opposed to a person-independent gaze estimator (leave-one-person-out cross- validation), thereby underlining the difficulty of person-independent gaze estimation.
2.3 Gaze Redirection Requiring a large number of training samples to learn a person-specific gaze estimator is a severe limitation for gaze-based applications. Some works therefore adopt a personal gaze adaptation step into their pipeline. A person-independent gaze estimator is first learned on training data from multiple people. Given a moderately sized set of calibration samples from a target person, the gaze estimator produces uncalibrated gaze estimates. The idea is to fit a mapping function from these estimates to the corresponding ground truth and to then use the mapping during inference for unseen images. Lightweight mapping functions include linear models [24] or cubic polynomials [53]. Instead of using person-independent gaze estimates as input, Krafka et al. [22] extract features from hidden layer activations of their network. Using these features, they fit a SVR to predict the subject’s gaze location. Yu et al. [49] show that fine-tuning the person-independent estimator improves performance, even for a small number of calibration samples.
Recent methods tackle person-specific gaze estimation on a more fundamental level by propos- ing specialized frameworks. These methods require only few samples for personal calibration, i.e. less than 9, and are therefore interesting in terms of usability for gaze-based interactive systems. Liu et al. [24] argue that it is easier to learn the relative difference between two eye images than to estimate absolute gaze directions. For an unseen eye image, their differential network infers the person-specific gaze direction from gaze differences to a small set of calibra- tion samples. Park et al. [29] leverage meta learning to adapt a gaze estimation network to the current user. Similar to our approach, Yu et al. [49] synthesize additional calibration samples by applying gaze redirection on a small set of initial calibration samples.
While few-shot person-specific gaze estimation reduces the cost of collecting calibration sam- ples, active collaboration of the user is still required. Various implicit calibration methods have been proposed to avoid explicit calibration. One approach is to treat visual saliency maps as probability distribution of the user’s gaze point [3, 38]. Other works leverage interactions on personal computers. Huang et al. study how gaze can be inferred from different cursor behav- iors [14]. Sugano et al. incrementally improve their gaze estimator using mouse-click events [39]. Huang et al. additionally exploit key-presses as input modality and propose a validation mechanism to filter out bad calibration samples [15]. Another idea is to detect the user’s atten- tion by correlating gaze with the position of a moving target on the screen [32]. Zhang et al. use mobile games, text editing and browsing a media library to collect implicit calibration samples on multiple devices [50].
Implicit calibration techniques do not require the user’s active collaboration and therefore could improve the usability of gaze-based systems. However, implicit calibration samples are inher- ently less reliable than explicit samples. In this thesis, we study the applicability of few-shot person-specific gaze-estimation on implicit calibration samples.
2.3 Gaze Redirection
Given an eye image, gaze redirection is the problem synthesizing a new image where the de- picted gaze matches a specified direction. Early works were motivated by video conferencing applications: The camera is typically placed above or below the screen, causing the gaze di- rection of the user to appear misplaced. Wolf et al. propose an approach where an eye patch is
2 Related Work
replaced in real-time with a suitable pre-recorded version of the same eye [45]. Their method produces realistic looking redirections, however, the need for pre-recorded eye images and ded- icated hardware limits its real-world applicability.
Some works use random forests [21] or CNNs [8, 49] to predict a flow-field which is used to directly move pixels from the input image such that the gaze direction changes as desired. One challenge to train these models is to acquire paired training data. To learn gaze redirection between two eye images, only the depicted gaze should change while annoyance factors such as the illumination condition should remain constant in both images. Yu et al. [49] address this problem by utilizing synthetic eye images, generated with UnityEyes [46], to train their network. In a subsequent domain adaptation phase, their CNN is fine-tuned on unpaired real eye images. A gaze lossensures that the generated eye image matches the target gaze while a cycle consistency loss [61] incentivizes the network to retain personal appearance features.
Warping-based methods produce good results but they struggle with cases where part of the eye is occluded because they only move existing pixels rather than generating new pixels.
Wood et al. [48] employ a model fitting approach for gaze redirection, avoiding the need for aligned training data. They first fit a 3D eye region model to the input image, simultaneously recovering the appearance. In a second step, they warp the eyelids from the original image and re-render the model with rotated eyeballs. While they achieve better results for large redirec- tion angles, their model makes strong assumptions which do not always hold in practice. For example, the method cannot handle images with glasses or other forms of occlusion.
In this thesis, we build on He et al.’s [12] GAN-based method for gaze redirection. Since eye images are generated from scratch, the method is well suited for real-world settings because it can handle occlusions and large redirection angles. The authors build on conditional GANs [27]: The generator is conditioned on the input image and the desired target gaze direction. In addition to the commonly used adversarial loss, judging if the generated image is real or fake, the discriminator also functions as a gaze estimator in order to compare the depicted gaze in the generated image to the target gaze direction. Despite gaze loss and cycle consistency loss, the method still requires paired training data because of an auxiliary perceptual losswhere the appearance of the gaze-redirected image is directly compared to the appearance of the input image.
We adapt He et al.’s method in two ways. First, we specify the desired change in pitch and yaw rather than the target gaze direction because it better preserves personal characteristics related to the gaze direction. Secondly, we propose a heuristic to align calibration samples based on the similarity of the corresponding head poses, allowing the use of real-world datasets which do not readily provide aligned calibration samples.
3
Method
Our goal is to improve person-specific calibration for gaze-based user interfaces. By using gaze redirection for data augmentation, we aim to keep the number of needed calibration samples to be minimal, potentially reducing the required effort from the user. We present an overview of our method in Section 3.1 and discuss the three main components: Gaze estimation, gaze redirection and personal gaze adaptation in sections 3.2, 3.3 and 3.4.
3.1 Overview
We differentiate between a training- and an inference phase. During training, we want to find a personal calibration function. In inference mode, this function is used to map the output of a person-independent gaze estimator to a person-specific gaze estimate.
As illustrated in Figure 3.1, the training procedure follows these steps.
1. A small set of seed calibration samples is collected using existing implicit or explicit calibration methods. A seed sample x = (I,g) consists of a normalized eye image I ∈ RH×W and the corresponding ground truth gaze direction g = (θ, φ), specified by pitchθ∈Rand yawφ∈R.
2. Given a seed sample x and gaze updates ∆gj = (∆θj,∆φj), a GAN-based redirec- tor generatesredirected calibration samples. The gaze updates ∆gj specify the desired change in pitch and yaw with respect tog. Thus, thej-th redirected sample ofxconsists of the generated eye imageIgenand the target gazegt = (θ+ ∆θj, φ+ ∆φj).
3. A pre-trained person-independent gaze estimator is used to estimate the gaze directions ˆ
g = (ˆθ,φ)ˆ of all calibration images. Furthermore, the estimator extracts featuresfˆ∈R`,
3 Method
Figure 3.1: Training. Given a set of seed samples with corresponding ground truth gaze directions, the gaze redirector generates redirected samples according to user-specified gaze updates. A pre-trained person-independent gaze estimator predicts the gaze directions of all calibration samples and extracts corresponding featuresfˆ. Given these features, the ground truth of the seed samples and the target gaze directions of the redirected samples, the mapping Fnn is learned.
from each input image, capturing additional information related to the estimated gaze direction.
4. Finally, we train a neural networkFnn on the featuresfˆ. The goal is to learn a mapping between gaze estimates ˆg and, respectively, the ground truth gaze directions g of seed samples and the target gazesgt of redirected samples.
During inference, as shown in Figure 3.2, the goal is to estimate the person-specific gaze direc- tiongˆ0 = (ˆθ0,φˆ0)from an input image. We first apply the person-independent gaze estimator on the input image to extract features fˆ. The desired person-specific gaze direction is estimated fromfˆby the trainedFnn.
Figure 3.2: Inference. The pre-trained gaze estimator extracts featuresfˆfrom an input image. Given these features, the mapping function Fnn predicts the person-specific gaze directiongˆ0 = (ˆθ0,φˆ0).
3.2 Gaze Estimator
3.2 Gaze Estimator
We use GazeNet [55] for appearance-based gaze estimation. The CNN is based on the VGG16 architecture [35]. As illustrated in Figure 3.3, GazeNet learns the mapping from an eye image I ∈ RH×W to a two dimensional gaze angle gˆ = (ˆθ,φ), whereˆ θˆ ∈ R and φˆ ∈ R denote estimated pitch and yaw. Weights are learned by minimizing the mean squared error.
Lgaze=||g−g||ˆ 22 (3.1)
whereg = (θ, φ)is the ground truth gaze direction ofI. Because we did not observe a signifi- cant performance difference in preliminary experiments, we omit the head pose input to the fc6 layer to simplify training on different datasets and on synthetic data.
Figure 3.3:GazeNet architecture [55]. The convolutional layers are inherited from VGG16 [35]. Using PCA, we extract featuresfˆfrom the activations of the fc7 layer of a trained model.
The trained gaze estimator model can be used as feature extractor [22]. The extracted multi- dimensional features capture richer information than the two-dimensional gaze estimatesˆg. Let ψfc7(I)∈R4096be the activations of the last hidden layer when feeding eye imageI as input to the CNN. We apply PCA to derive a more tractable dimension for our downstream calibration task [51].
fˆ=PCA(ψfc7(I)) (3.2)
where fˆ∈ R100. We specify a fixed target dimensionality rather than the amount of variance that should be retained by the PCA subspace to accommodate efficient, randomized methods for PCA [10].
Preprocessing We follow the normalization techniques for appearance based gaze esti- mation as summarized by Zhang et al. [52] to cancel out the influence of variable head pose and camera-user distance. We then extract 36x60 pixel eyepatches from the original images based on detected landmarks. Eye images are converted to grayscale and we apply histogram equalization. We flip the right eye images along the vertical axis and mirror the gaze direction accordingly [55]. This lets us treat left and right eyes in the same way.
3 Method
3.3 Gaze Redirector
We adapt the gaze redirector in [12] to be used in our project with the following changes.
1. To redirect the gaze of an input image, we specify a gaze update, i.e. the desired change in pitch and yaw, rather than the target gaze direction.
2. Minimizing the auxiliary perceptual loss requires paired input and target images. We propose a heuristic to pair eye images in order to alleviate this constraint.
Figure 3.4 shows the adapted method. The data is preprocessed as described in Section 3.2.
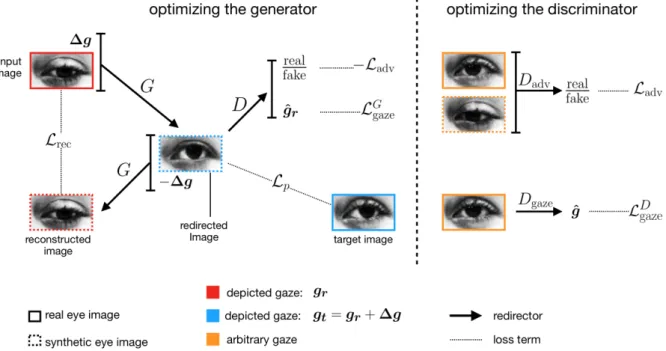
Figure 3.4:Gaze redirector, adapted from He et al.’s method [12]. Left: Given an input image with ground truth gazegrand a gaze update∆g, the generator synthesizes a redirected eye image Igen with target gazegt = gr+∆g. With the cycle consistency lossLrec,Gis trained to retain personal features while redirecting. Igen is further judged by the discriminator on whether it fits the distribution of real eye images and against the target gaze directiongt. In the perceptual lossLp, the redirected image is directly compared to a target image in order to achieve similar appearance. Right: The discriminator is trained to discriminate real and fake images and to estimate gaze directions.
The generator network G is conditioned on a real input image Ir ∈ RH×W and the desired change in pitch and yaw ∆g = (∆θ,∆φ). GivenIr and a gaze update ∆g, the generator is trained to synthesize an eye imageIgen =G(Ir,∆g)with target gazegt = (θt, φt). Target pitch and yaw should respectively satisfyθt =θr+ ∆θandφt =φr+ ∆φ, wheregr = (θr, φr)is the ground truth gaze direction associated withIr. In contrast to the original authors, we condition G on the gaze update rather than on the target gaze, applying the understanding that relative change in gaze is easier to learn [29, 24]. The experiments in Section 4.3 further motivate the use of gaze updates by showing that the person-specific bias in the eye images can be lost when conditioningGon the target gaze, thus impeding our calibration method.
3.3 Gaze Redirector
We briefly discuss the adapted training objectives of the framework.
Adversarial Loss A network Dadv is trained to discriminate between real and fake eye im- ages. The adversarial loss is defined similarly as in WGAN-GP [9].
Ladv =EIr∼pIr(I)[Dadv(Ir)−Dadv(G(Ir,∆g))]
+λgpEI∼pˆ Iˆ(I)ˆ[(||∇IˆDadv(Iˆ)||2−1)2] (3.3) pIr(I) denotes the probability distribution of real images. The second term stabilizes training by ensuring 1-Lipschitz continuity of the discriminator. By minimizing Ladv, G is given the incentive to generate images matching the distribution of real eye images.
The hyperparameter was set toλgp = 10in all experiments.
Gaze Loss The authors propose an auxiliary gaze estimation loss to facilitate the desired change in gaze direction. They introduce an additional gaze estimation network Dgaze, which takes an eye image as input and outputs pitch and yaw. Dgaze is trained by mini- mizing the mean squared error between the ground truth gaze directiongr ofIr and the estimated gaze directionDgaze(Ir).
LDgaze=EIr∼pIr(I)||gr−Dgaze(Ir)||22 (3.4) To achieve gaze redirection, the MSE between the target gazegt =gr+∆gand the gaze estimate of the generated eye imageIgen =G(Ir,∆g)is minimized.
LGgaze =EIr∼pIr(I)||gt−Dgaze(Igen)||22 (3.5) The weights of Dgaze remain fixed while minimizing LGgaze. In practice,Dgaze and Dadv share most layers.
Reconstruction Loss In order to retain personalized features in the generated imageIgen, the following cycle consistency loss is minimized [61].
Lrec=EIr∼pIr(I)||G(Igen,−∆g)−Ir||1 (3.6) Intuitively speaking,G(Igen,−∆g)should undo the redirection by redirectingIgenby the negative gaze update−∆g= (−∆θ,−∆φ).
Perceptual Loss The perceptual loss Lp penalizes G for generating an eye image Igen = G(Ir,∆g) which differs perceptually from a target image It. He et al. adopt the style and content losses proposed by Johnson et al. [19]. The idea is to exploit the difference in hidden layer activations of a pre-trained VGG16 network when respectively providing IgenandItas inputs.
The overall training objectives forGandDare as follows.
LG =−Ladv+λpLp+λgazeLGgaze+λrecLrec (3.7)
LD =Ladv+λgazeLDgaze (3.8)
where we set the hyperparametersλp = 100, λgaze = 5andλgaze = 50in all experiments.
3 Method
3.3.1 Pairing Training Samples
The perceptual loss requires paired training imagesIr andIt which, ideally, only differ in the depicted gaze direction. For example, the head pose and the lighting condition should be the same in Ir and It. In some datasets, such as ColumbiaGaze [36], paired calibration samples can easily be extracted because of consistent lighting during data collection and a discrete set of head poses. In general, however, paired samples might not be readily available. We propose a heuristic to pair eye images based on the similarity of their head poseh = (θh, φh). Similar to gaze directions, head poses are defined by pitchθh ∈Rand yawφh ∈R.
To compute theangular distancebetween two head poses, respective pitch and yaw first have to be converted into cartesian coordinates. Leta= (θ, φ)be a tuple of pitch and yaw, for example a gaze direction or a head pose.
T(a) = [cosφcosθ,−sinφ,cosφsinθ] (3.9) The angular distance between two tuplesa1 anda2is defined as follows.
γ(a1,a2) = arccos T(a1)|·T(a2)
||T(a1)|| · ||T(a2)|| (3.10) LetC = {(Ii,gi,hi)|1 ≤ i ≤ n}be the set of calibration samples that are used to train the redirector. Each sample is additionally annotated with the corresponding head pose. We create n clusters of sizekp+ 1as follows. For fixedxi ∈ C, we selectkp distinct calibration samples xj ∈ C \ {xi}, where j = 1, . . . , kp, from the same user and side (left/right eye) with minimal angular distance γ(hi,hj). Note that some calibration samples might occur in more clusters than others. Given the clusterCi, we pair calibration samples according to the cartesian product Ci× Ci but exclude pairs where the same calibration sample appears twice. The final number of pairs isn·kp·(kp+ 1).
3.4 Personal Gaze Adaptation
We are givenn seed calibration samples of the formxi = (Ii,gi). Using the pre-trained gaze estimator, featuresfˆiare extracted from the eye imageIi. The set ofprocessedseed samples is defined as follows.
Pseed ={(fˆi,gi)|1≤i≤n} (3.11) wheregi = (θi, φi). We synthesize m redirected samples for each seedxi. The gaze updates
∆θj(i) and∆φ(i)j , for1 ≤ j ≤ m, are drawn from uniform distributions such that the resulting target pitch and yaw fall into device-specific ranges[θmin, θmax]and[φmin, φmax].
∆θ(i)j ∼ U(θmin−θi, θmax−θi) (3.12)
∆φ(i)j ∼ U(φmin−φi, φmax−φi) (3.13)
3.4 Personal Gaze Adaptation
The set of processed redirected calibration samples is defined as follows.
Pred ={(fˆj(i),g(i)j )|1≤i≤n∧1≤j ≤m} (3.14) where fˆj(i) is extracted from the generated image G(Ii,∆gj(i)) and gj(i) = (θi + ∆θj(i), φi +
∆φ(i)j ).
We train the neural networkFnnon the input-target pairs(fˆ,g)∈ Pseed∪ Pred. Note that there is no distinction between seed and redirected calibration samples at this point. We use the MSE as training objective with an additional L2 regularization term. Fnnconsists of four fully connected ReLU layers with, respectively, 512, 384, 256 and 128 hidden units.
3.4.1 Filtering Seed Calibration Samples
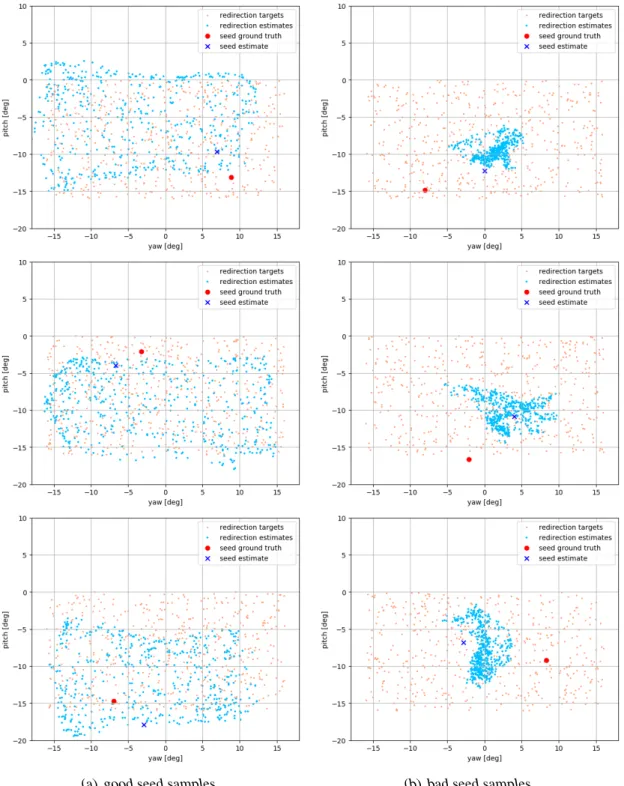
Implicitly collected calibration samples xi = (Ii,gi) might be unreliable [50]. That is, the annotated gaze direction gi might not faithfully represent the gaze depicted inIi. We propose to use the Earth Mover’s Distance1 (EMD) in a scoring function to filter out unreliable seed samples. The EMD, also known as the Wasserstein metric, is a measure of distance between two probability distributions, informally denoting the minimum cost of moving one distribution to another. We select thekhighest scoring seed samples and their redirections to learn the gaze adaptation function Fnn. We show in Section 4.4.3 that this method improves calibration in some scenarios.
The assumption is that the redirected samples of a good seed more closely match their target gaze directions than the redirections of abad seed. To score thei-th seed sample, we consider the empirical target- and estimated gaze distributions.
Gt={gi+∆gj(i)|1≤j ≤m} (3.15)
Gest ={ˆg(i)j |1≤j ≤m} (3.16)
wheremis the number of redirections per seed. Figure 3.5 illustratesGtandGestgiven good and bad seed samples. Let Cj1,j2 =γ(gj1,gj2)be the cost matrix containing all angular distances between pairs(gj1,gj2)∈ Gest× Gt. The EMD can be formulated as a linear program.
M∗ = arg min
M m
X
j1=1 m
X
j2=1
Mj1,j2Cj1,j2
subject to
m
X
j1=1
Mj1,j2 = 1 m
m
X
j2=1
Mj1,j2 = 1 m Mj1,j2 ≥0
(3.17)
1http://homepages.inf.ed.ac.uk/rbf/CVonline/LOCAL_COPIES/RUBNER/emd.htm
3 Method
M∗ ∈ Rm×m is intuitively understood as a soft assignment between gaze directions fromGest andGt, minimizing the overall distance between them. The linear program 3.17 can be solved inO(m3)[1]. Finally, we score seedxiusing the reciprocal EMD.
EMD(xi) = Pm
j1=1
Pm j2=1Mj∗
1,j2Cj1,j2 Pm
j1=1
Pm j2=1Mj∗
1,j2
(3.18) σEMD(xi) = 1
EMD(xi) (3.19)
Given the scores computed withσEMDof all available seed samples, thekhighest scoring seeds – and therefore thek seeds whose redirections have the smallest EMD among target- and esti- mated gazes – are chosen to learn the gaze adaptation functionFnn.
3.4 Personal Gaze Adaptation
(a) good seed samples. (b) bad seed samples.
Figure 3.5:Examples of the empirical gaze distributionsGest(redirection estimates) andGt(redirection targets). The ground truth gaze direction and person-independent gaze estimate of the seed samples – taken from MPIIGaze [55] – are also displayed for reference. Our assumption is that the redirections of good seed samples (left column) better match the desired target gaze directions than the redirections of bad seed samples (right column). Gest andGtbelonging to a good seed would therefore be more similar to one another, the EMD would be smaller, resulting in a higher score withσEMD.
3 Method
4
Experiments
We briefly describe the datasets which we used to evaluate our method in Section 4.1 and show some baseline gaze estimation experiments in Section 4.2. In Section 4.3, we discuss gaze estimation on a large number of redirected calibration samples. Finally, in Section 4.4, we show that using redirected samples in a few-shot setting can improve personal calibration.
Gaze Estimation Error Theangular erroris defined as the angular distance (Equation 3.10) between a predicted gaze direction and the desired target gaze.
4.1 Datasets
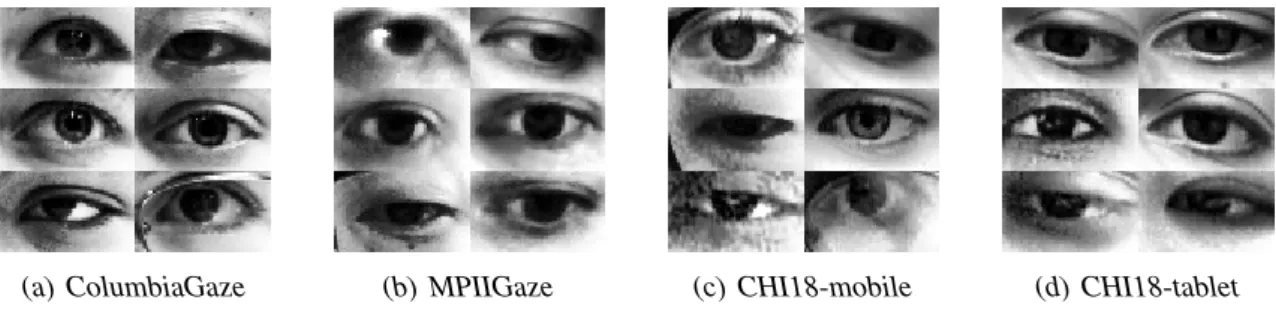
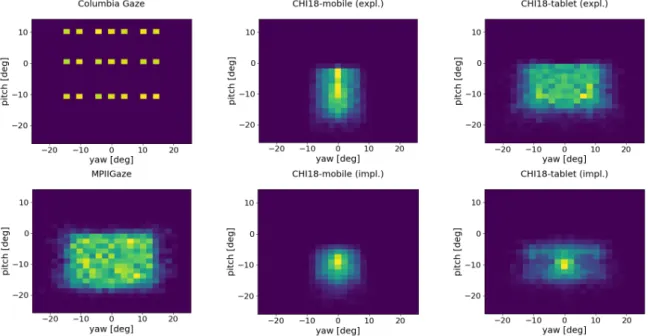
We conducted experiments on MPIIGaze [55], ColumbiaGaze [36] and CHI18 [50]. Figure 4.1 shows eye images from each dataset and Figure 4.2 illustrates the distribution of gaze directions.
MPIIGaze contains explicit calibration samples from 15 study participants. The data was recorded during several months of personal laptop use and under various lighting con- ditions. Each subject contributes 1500 left eyes and 1500 right eyes.
CHI18 provides explicit and implicit calibration samples of 20 subjects. Data was collected on mobile phones, tablets, laptops, desktop computers and TVs under various illumination conditions. We focus on the mobile phone (CHI18-mobile) and tablet (CHI18-tablet) ses- sions because, as seen in Figure 4.2, they cover similar gaze directions as MPIIGaze. To collect implicit calibration samples, subjects were recorded while playing various games.
The calibration samples were extracted from the recording based on timestamps of touch events, assuming that the subject looked at the touch position during the interaction.
4 Experiments
ColumbiaGaze contains high resolution images from 56 subjects, recorded in a controlled laboratory environment. Participants were asked to fixate a discrete number of dots on a wall while keeping their head stable.
(a) ColumbiaGaze (b) MPIIGaze (c) CHI18-mobile (d) CHI18-tablet Figure 4.1:Randomly selected, preprocessed, eye images sampled from the four different datasets.
The CHI18 dataset was the ideal choice to evaluate our method because it contains implicit as well as explicit calibration samples. Being able to use implicit samples is desirable because collecting implicit instead of explicit samples may reduce the required effort from the user.
Additionally, having explicit calibration samples from the same subject and collected using the same device is helpful for testing since they are more reliable than implicit samples. However, we conducted several experiments on MPIIGaze because it is publicly available and contains more calibration samples than CHI18. The in-the-wild nature of MPIIGaze and CHI18 aligns well with our goal of improving person-specific gaze estimation for unconstrained environ- ments. Yet, we included some baseline results on ColumbiaGaze because the gaze redirector [12] was originally designed and evaluated on ColumbiaGaze. We preprocessed all datasets as discussed in Section 3.2.
4.2 Gaze Estimator Baseline
Our method adopts personal gaze adaptation to improve the accuracy of a person-independent gaze estimator. Figure 4.3 summarizes the performance of calibration-free gaze estimators on ColumbiaGaze, MPIIGaze, CHI18-mobile and CHI18-tablet, thus providing an important base- line for the person-specific estimators. Circumventing additional effects introduced by personal gaze adaptation, the calibration-free setting is additionally well suited to analyze cross-dataset behavior (Section 4.2.1) and how explicit- and implicit calibration data differ (Section 4.2.2).
Table 4.1 details the different training scenarios.
4.2.1 Cross-Dataset Experiments
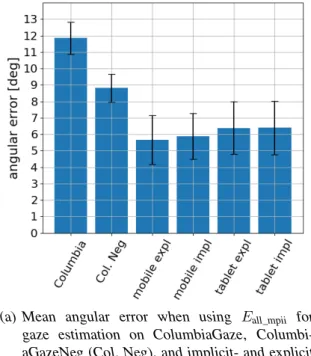
In a cross-dataset experiment, we trained an estimatorEall_mpii on all subjects from MPIIGaze and test on ColumbiaGaze, CHI18-mobile and CHI-tablet. The results are summarized in Fig- ure 4.3(a). Because MPIIGaze does not contain samples with positive pitch angle (cf. Fig- ure 4.2), we excluded such samples from ColumbiaGaze for a more meaningful comparison (ColumbiaGazeNeg). With 11.8 and 8.8 degrees angular error, Eall_mpii performs poorly on ColumbiaGaze and ColumbiaGazeNeg. On CHI18-mobile, we achieved 5.7 and 5.9 degrees
4.2 Gaze Estimator Baseline
Figure 4.2:Pitch and yaw of gaze directions in ColumbiaGaze, MPIIGaze, CHI18-mobile (implicit- and explicit calibration) and CHI18-tablet (implicit- and explicit calibration). We selected 6800 random samples across all subjects of the respective dataset for each plot. The 21 gaze direc- tions in ColumbiaGaze result from combining(0◦,±5◦,±10◦,±15◦)yaw with(0◦,±10◦) pitch. Calibration samples in MPIIGaze and CHI18 have negative pitch angles because the camera is positioned above the screen on the recording devices. The gaze directions of the implicit calibration samples tend to cluster towards the center of the angle range whereas the gaze directions of the corresponding explicit calibration session are more evenly distributed.
respectively on the explicit and implicit calibration samples. For the tablet session, the angu- lar error is 6.4 degrees in both cases. ColumbiaGaze seems to be more challenging forEall_mpii. This might be due to the higher frequency of extreme gaze angles – e.g.±30◦yaw – or differing image characteristics, such as image resolution.
The results in this experiment, together with the qualitative similarity seen in Figure 4.1 and the gaze range overlap in Figure 4.2, suggest that the CHI18 and the MPIIGaze datasets are reasonably similar to each other. This observation and the lacking performance of Eall_mpii on ColumbiaGaze partly motivated us to train the redirector on MPIIGaze instead of Columbi- aGaze and use it in experiments involving MPIIGaze and CHI18.
4.2.2 Within-Dataset Cross-Person Experiments
We trained leave-one-subject-out estimatorsEloo_mpiion MPIIGaze. In a cross-validation exper- iment, we were able to reproduce 5.5 degrees angular error as reported by Zhang et al. [55] for the same gaze estimator architecture.
For CHI18-mobile and CHI18-tablet, we fine-tuned leave-one-subject-out estimators on im- plicit and (separately) on explicit calibration samples. We tested on the explicit calibration samples of the left-out subject and averaged the angular error over all folds. As seen in Fig- ure 4.3(b), the explicit estimators outperform the implicit estimators: Respectively 4.3 and 4.6
4 Experiments
Identifier Mode # Est # Subj # Samples Type Training Data
Eall_mpii all 1 15/est. 3000/subj. explicit MPIIGaze
Eloo_mpii LOO 15 14/est. 3000/subj. explicit MPIIGaze
Emobile_expl LOO 19 18/est. 400/subj. explicit fine-tune on CHI18-mobile
Emobile_imp LOO 18 17/est. 400/subj. implicit fine-tune on CHI18-mobile
Etablet_expl LOO 18 17/est. 400/subj. explicit fine-tune on CHI18-tablet Etablet_impl LOO 17 16/est. 400/subj. implicit fine-tune on CHI18-tablet
Table 4.1:Training setup. LOOabbreviates ‘leave-one-subject-out’; In these cases, we trainednesti- mators(# Est)on the respectiven−1remaining subjects (# Subj). Training modeallmeans that all subjects from the dataset have been used as training data. Unfortunately, some of the 20 subjects in the CHI18 dataset had to be excluded due to incomplete data.
degrees angular error on mobile phones and 5.7 and 5.9 degrees on tablet devices. This aligns with the intuition that the implicit calibration samples are less reliable than the explicit calibra- tion samples [50].
Interestingly, testing on the implicit calibration samples yielded lower angular errors than test- ing on the explicit samples. The gaze estimator achieved 3.9 and 5.4 degrees angular error with the explicit estimators when testing on the implicit samples of the left-out subjects of CHI18-mobile and CHI18-tablet. Based on Figure 4.2, we suspect that this is due to the higher frequency of gaze directions near the center of the screen.
Training Parameters Gaze Estimator We trainedEloo_mpii and Eall_mpii for 15000 itera- tions on MPIIGaze with a batch size of 256. Because there are only 400 samples per subject in the CHI18 dataset, we initialized the weights of the Emobile_* andEtablet_* estimators with a model which was trained on MPIIGaze and train for additional 5000 iterations. We used the Adam optimizer withβ1 = 0.9andβ2 = 0.95and used a fixed learning rate to10−5.
4.3 Gaze Estimation on Redirected Samples
The gaze redirector [12] was originally trained and evaluated on ColumbiaGaze [36]. The dataset is a good fit for studying photo-realistic gaze redirection with GANs because it contains high quality images due to the laboratory setting. We were able to reproduce the quantita- tive gaze estimation results when training a gaze redirector RCG on 50 out of 56 subjects in ColumbiaGaze and testing on the remaining subjects.
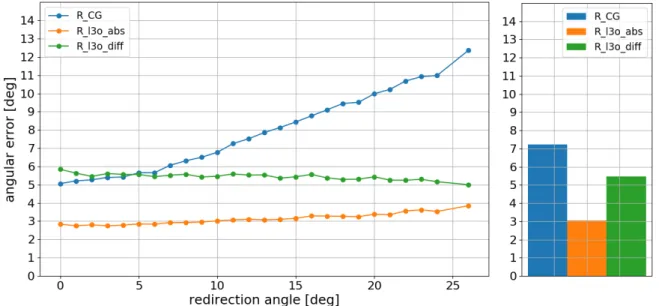
Our target datasets were MPIIGaze and CHI18 as they contain calibration data from real-world interactions. As a first baseline, we tested how wellRCG redirects MPIIGaze calibration sam- ples. Figure 4.4 shows the angular error between predicted gazegˆand target gazegt as a func- tion of the redirection angle γ(ˆg,gt) in a leave-one-subject-out cross-validation experiment.
Redirecting by less than one degree resulted in 5.1 degrees angular error. When redirecting by
4.3 Gaze Estimation on Redirected Samples
(a) Mean angular error when using Eall_mpii for gaze estimation on ColumbiaGaze, Columbi- aGazeNeg (Col. Neg), and implicit- and explicit calibration samples from CHI18-mobile (mobile impl/expl) and CHI18-tablet (tablet impl/expl).
(b) We trained leave-one-subject-out gaze estima- tors separately on the implicit- and explicit cali- bration samples from CHI18-mobile (Emobile_impl
andEmobile_expl) and CHI18-tablet (Etablet_impland Etablet_expl) and tested on the explicit samples from the respective device.
Figure 4.3:Person-independent gaze estimation baseline. Bars denote the mean angular error over all subjects of the respective dataset. Error bars indicate standard deviations.
more than 25 degrees, the angular error of more than 12.0 degrees was too inaccurate to be considered useful in our method.
A natural next step was to directly train the redirector on MPIIGaze. We compared two redi- rector types: The baseline Rl3o_abs was trained using absolute target gaze directions [12] and Rl3o_diff was trained by specifying gaze updates as described in Section 3.3. In both cases, we trained five models in a leave-three-subjects out manner. When generating images, we made sure to use the model which was not trained on the subject in question. As seen in Figure 4.4, training on MPIIGaze especially improved the angular error for large redirection angles. E.g.
when redirecting by 20 degrees the angular error is reduced from 9.5 degrees withRCGto 3.2 degrees withRl3o_abs or 5.4 degrees withRl3o_diff.
Figure 4.5 shows qualitative results. The leftmost column depicts input images together with their ground truth gaze directions. We randomly picked a target sample with similar head pose and used its ground truth gaze direction as target for the redirection. Note that choosing a target sample is not necessary for inference but it helps to visualize the target gaze and how the generated eye image could look. While using gaze updates rather than absolute target gaze directions did not seem to have a perceptible impact, training on a different dataset appeared to be problematic as the generated images seem blurry. Even though, we did not focus on photo- realism, this was further motivation to not use ColumbiaGaze in subsequent experiments.
4 Experiments
Figure 4.4: Left: Angular error on redirected MPIIGaze samples vs. redirection angle. The datapoint at xrepresents the mean angular error of all redirections with a redirection angle betweenxand x+ 1degrees. Small redirection angles were more frequent in this experiment.Right: Mean angular error over all redirections (no binning). WhileRCGwas trained on ColumbiaGaze, Rl3o_absandRl3o_diffwere trained on MPIIGaze, respectively using absolute target gazes and gaze updates. The experiment was conducted in a leave-one-subject-out manner, using the Eloo_mpiigaze estimators.
Training Parameters Gaze Redirector As discussed in Section 3.3, paired eye images are required to train the gaze redirector. In the case of ColumbiaGaze, there are only 5 distinct head poses; calibration samples can therefore easily be paired. We formed the cartesian product of all calibration samples (21 gaze directions) for fixed head pose, user and side (left/right eye).
For MPIIGaze, we used the method described in Section 3.3.1 withkp = 4to pair calibration samples based on the angular distance between head poses.
RCG, Rl3o_abs andRl3o_diff where respectively trained for 2.2M, 1.5M and 2.9M iterations with a minibatch size of 32. We increased the number of iterations ofRl3o_diff, compared toRCG, to compensate for the imperfect pairing of calibration samples. TheRl3o_abs baseline was stopped early because we only observed marginal qualitative and quantitative improvements during training. We used the Adam solver with β1 = 0.5, β2 = 0.999 and a fixed learning rate of lr= 0.0002.
4.3.1 Relative Gaze Redirection
When using the absolute redirector modelsRl3o_abs, we achieved 3.0 degrees angular error on average in the cross-person experiment illustrated in Figure 4.4. This is 2.5 degrees lower than with the relative redirector modelsRl3o_diff. Performing leave-one-person-out cross-validation on the real calibration samples of MPIIGaze also yielded 5.5 degrees angular error, reinforcing the impression that 3.0 degrees is too low.
We suspect following reason for the low angular with Rl3o_abs. The redirector might learn to
4.3 Gaze Estimation on Redirected Samples
Figure 4.5:Redirected samples. The leftmost column shows input images. Columns two to four show redirected images generated byRCG,Rl3o_absandRl3o_diff, respectively. The rightmost col- umn depicts target images; their ground truth gaze was used as redirection target. The two rows below the horizontal line show examples where the redirectors did not perform well – the redirection angle was large in both cases.
generate eye images with the specified target gaze regardless of the gaze direction depicted in the input image. In particular, the person-specific gaze bias of the input image might be lost.
Since the redirector and estimator models, which are used on a specific subject, were trained on the same data, the two models have the same ‘understanding’ of gaze directions. Hence the low angular error.
While this might look like a welcome performance boost, it may actually be detrimental to our method. As described in Section 3.4, we want to pool together seed and redirected samples to fit a single calibration function which captures the personal gaze bias. The relationship between the seed gaze prediction and the ground truth and the relationship between the gaze predictions of the redirected samples and their targets gazes should therefore be similar. Consider the four randomly selected seed samples depicted in the left column in Figure 4.6. Using absolute target gazes as input to the redirector lead to the estimated gazes of the redirected samples being close the their targets but far from the prediction of the seed sample. Finding a calibration function mapping predictions to target and ground truth gaze directions might be difficult in this case.
4 Experiments
As seen in the right column of Figure 4.6, the estimated gazes clustered around the gaze predic- tion of the seed sample when usingRl3o_diff. This could indicate that the personal bias tends to be preserved when specifying gaze updates.
4.3.2 Quality of Redirected Samples
To substantiate our intuition regarding relative and absolute gaze redirection, we performed a person-specific gaze estimation experiment. As a baseline, we trained gaze estimatorsEps for each subject in MPIIGaze on 2500 randomly chosen samples. The remaining 500 samples were set aside for testing. We generated two additional trainsets containing 2500 redirected samples respectively using absolute target gazes and gaze updates for redirection. These trainsets were then used to train gaze estimatorsEps_diffandEps_abs, which were evaluated on the same testset asEps.
Figure 4.7, summarizes the results: UsingEps, the estimator achieved 2.6 degrees angular error averaged over all subjects which is close to the 2.5 degrees reported by Zhang et al. [55]. Train- ing on the relatively redirected samples resulted in 3.7 degrees angular error while usingEps_abs resulted in 5.7 degrees angular error.
These results align well with our intuition from the previous section. When specifying absolute target gazes, the redirector seemed to ‘smooth out’ the person-specific bias. Therefore, training an estimator on these redirected samples failed to capture the person-specific bias and the re- sulting angular error is similar as in the cross-person experiment. This did not seem to be the case when specifying gaze updates during training. The performance loss of about 1.1 degrees when using (relatively) redirected samples compared to real calibration samples was expected because the redirector introduces additional noise on top of the real calibration samples.
4.3 Gaze Estimation on Redirected Samples
Figure 4.6:Four randomly selected seed samples from MPIIGaze and their ground truth- and estimated gaze directions. The same seeds are depicted in both columns. We sampled 21 target gaze directions close to the seed samples and generated redirections withRl3o_abs(absolute target gaze) in the left column andRl3o_diff (relative gaze updates) in the right column. Eloo_mpii was used for gaze predictions.
4 Experiments
Figure 4.7:Person-specific gaze estimation. Left: For each subject in MPIIGaze, we set aside 500 calibration samples for testing. The remaining 2500 samples were used to train person- specific estimatorsEps. Furthermore, we used the redirector modelsRl3o_abs andRl3o_diffto generate two additional trainsets per subject. On these, we respectively trained the estimator Eps_absandEps_diff.Right:Mean angular error over all subjects. Error bars indicate standard deviations.
![Figure 3.3: GazeNet architecture [55]. The convolutional layers are inherited from VGG16 [35]](https://thumb-eu.123doks.com/thumbv2/1library_info/5361223.1683557/23.892.205.731.427.630/figure-gazenet-architecture-convolutional-layers-inherited-vgg.webp)