„Zentrum“ und „Peripherie“. Zur Bewertung der phonotakti- schen Wortstruktur.
8
0
0
Volltext
(2)
(3)
(4)
(5)
(6)
(7)
(8)
Abbildung
ÄHNLICHE DOKUMENTE
Diese Platten berühren sich in der Mauermitte nicht, sind aber, an den Stossfugen nur in einem Saums_chlage sich berührend, auf das engste schliessend gearbeitet.. Auch in den
13 Die Begriffe in der Tabelle (Rechtschreibfehler, Fehlen von Elementen, Kasusfehler, falsche Wortstellung, falsche Wortwahl, falsche Präposition, Genusfehler,
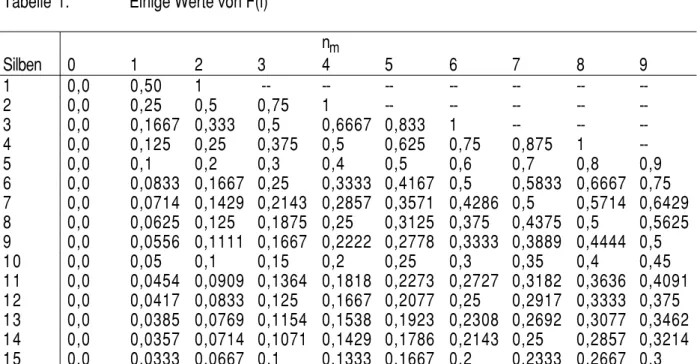
Hier liegt die Vorstellung zugrunde, dass die (zuf¨ allig ausgew¨ ahlte) Frau am Tag genau n M¨ oglichkeiten hat, ein einzelnes Wort zu sprechen, und jedes dieser W¨ orter
Für die experimentellen Analysen werden mittels hochenergetischer Synchrotronstrahlung hoch aufgelöste 3D-Tomogramme von Proben vor und nach einer Zugbelastung erzeugt, die das
Auch geht es hier nicht einfach um eine Frage, die sich durch eine Reise in die Vergangenheit beantworten läßt.. Für diese Sounds gibt es zeitgenössische und vergangene
(Im Übrigen ereilt auch andernorts Kunstwerke im städtischen Raum das Schicksal peripherer Wahr- nehmung, ohne dass dafür eine Randlage nötig wäre. Mithin kann sogar eine
In unserer Sicht steht aber bei dieser Struktur – trotz des Aus- rufezeichens – nicht die Feststellung einer Normabweichung im Vordergrund; vielmehr handelt es sich um eine
Es soll hier nun aufgezeigt werden, dass dieses Konstrukt auch auf syntaktische Funktionsfelder mit Ge- winn anwendbar ist, auch wenn der für eine Kategorie jeweils
