Research Collection
Bachelor Thesis
Scalable Triangle Counting and LCC with Caching
Author(s):
Strausz, András Publication Date:
2021-03-05 Permanent Link:
https://doi.org/10.3929/ethz-b-000479356
Rights / License:
In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For more
information please consult the Terms of use.
Scalable Triangle Counting and LCC with Caching
Bachelor Thesis Andr´ as Strausz March 5, 2021
Advisors: Dr. Flavio Vella (UniBZ), Salvatore Di Girolamo (ETHZ)
Professor: Prof. Dr. Torsten Hoefler (ETHZ)
Department of Computer Science, ETH Z¨ urich
Abstract
Graph analytical algorithms gained great importance in recent years as they proved to be useful in a variety of fields, such as data min- ing, social network analysis, or cybersecurity. To cope with the com- putational and memory demands that stem from the size of today’s networks highly parallel solutions have to be developed.
In this thesis, we present our algorithm for shared memory as well as
for distributed triangle counting and local clustering coefficient. We an-
alyze different techniques for the computation of triangles and achieve
shared memory parallelism with OpenMP. Our distributed implemen-
tation is based on row-wise graph partitioning and uses caching to save
communication time. We take advantage of MPI’s Remote Memory
Access interface to achieve a fully asynchronous distributed algorithm
that utilizes RDMA for data transfer. We show how the CLaMPI li-
brary for caching remote memory accesses can be used in the context
of triangle counting and analyze the relationship between the caching
performance and the graph structure. Furthermore, we develop an
application-specific score used for the eviction procedure in CLaMPI
that leads to additional performance gains.
Contents
Contents ii
1 Introduction 1
1.1 Notation . . . . 2
1.2 The Local Clustering Coefficient . . . . 2
1.2.1 Significance of Triangles and LCC . . . . 3
1.3 On the difficulty of triangle computation . . . . 3
1.4 Overview of the thesis . . . . 5
2 Related works 6 2.1 Computation of triangles . . . . 6
2.1.1 Frontier intersection . . . . 6
2.1.2 Algebraic computation . . . . 8
2.2 Graph partitioning . . . . 9
2.2.1 1D partitioning . . . . 9
2.2.2 2D partitioning . . . . 9
2.2.3 Partitioning with proxy vertices . . . . 10
3 MPI-RMA and Caching 11 3.1 MPI-RMA . . . . 11
3.2 Caching . . . . 12
3.2.1 Locality . . . . 12
3.2.2 Hitting and missing . . . . 13
3.2.3 CLaMPI . . . . 13
3.2.4 Structure of CLaMPI . . . . 14
3.2.5 Handling of cache misses . . . . 14
3.2.6 Adaptive scheme . . . . 15
4 Distributed LCC with CLaMPI 17
4.1 Outline of our implementation . . . . 17
Contents
4.1.1 Graph pre-processing and distribution . . . . 17
4.1.2 Graph format . . . . 17
4.1.3 Communication . . . . 18
4.1.4 Triangle computation . . . . 18
4.1.5 Implemented algorithm . . . . 18
4.2 Caching for distributed LCC . . . . 21
4.2.1 A small scale example . . . . 21
4.2.2 A large scale example . . . . 21
4.2.3 CLaMPI for distributed LCC . . . . 22
4.2.4 Configuration of CLaMPI . . . . 22
5 Methodology 25 5.1 Network data . . . . 25
5.2 Hardware and software platform . . . . 25
5.3 Measurements . . . . 26
6 Evaluation of shared memory and distributed LCC 27 6.1 Local LCC computation . . . . 27
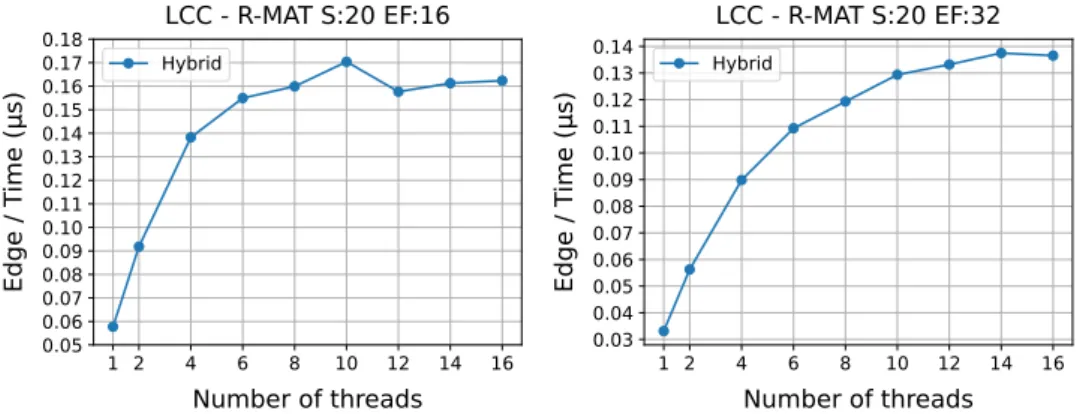
6.1.1 Performance of the hybrid method . . . . 27
6.1.2 Scaling . . . . 28
6.2 Distributed LCC . . . . 29
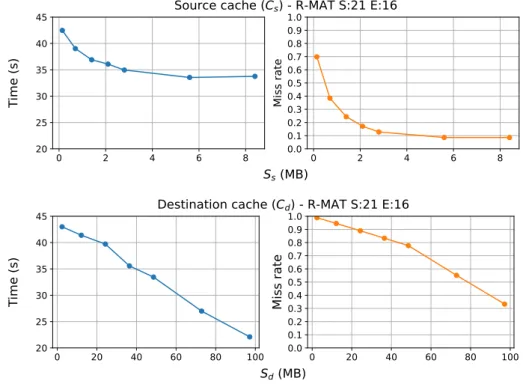
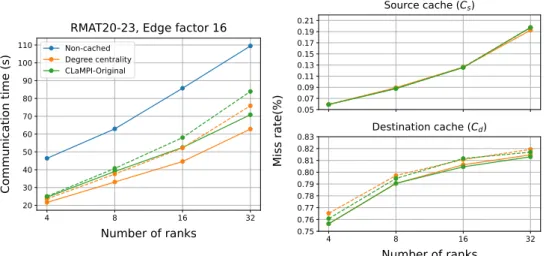
6.2.1 Caching performance . . . . 29
6.2.2 Overall performance . . . . 32
6.3 Summary and lessons learned . . . . 33
6.4 Future directions . . . . 34
6.4.1 Vectorization . . . . 34
6.4.2 Node level caching . . . . 34
Bibliography 35
Chapter 1
Introduction
With the emergence of the Internet, in various contexts entities have been connected resulting in different types of networks. The WWW itself forms a network where entities are the web pages that are connected together by hyperlinks. Taking E-mails as an example, by sending a message a link between the sender and the receiver is created. Thus, by collecting the mes- sages between a group of users we arrive at a communication network. An- other example is social networks, such as Facebook or Twitter where links between the users often represent friendship or some kind of interest to- wards the other user.
The analysis of such networks can be of benefit in many ways. Facebook, for example, might achieve a better quality of service by understanding the main drivers in creating new connections. The analysis of E-mail traffic can help for better spam filtering or in the detection of fraud. Network analysis has an important social aspect as well, as better understanding of the structure of our society will also help us identifying and supporting minorities.
While all the networks described above represent different relationships, they all share the property of consisting millions or even billions of enti- ties. Therefore, the analysis of these networks has a higher demand both in memory and computing capacity than today’s single CPU machines can offer. This leads to the necessity of the development of distributed solutions.
Lumsdaine et al. [14] point out several properties of graph problems that make it difficult to develop distributed programs with good performance.
Firstly, most graph analytical problems are data-driven, that is the computa-
tion depends on the underlying structure of the graph. However, it is often
not known before execution, what makes it difficult to evenly partition the
problem among the computing nodes. Secondly, the data access of such
problems has often poor locality that comes from the irregular and unstruc-
1.1. Notation
Graph structur e
G a given graph, G = ( V, E ) ; V, E are sets of vertices and edges.
n, m numbers of vertices and edges in G; n = | V | , m = | E | . deg ( i ) degree (out-degree) of i.
adj ( i ) adjacency of vertex i.
A adjacency matrix of G.
4
ijka triangle including the edges e
ij, e
jk, e
ik∈ E i − j − k two path including e
ij, e
jk∈ E.
Table 1.1: Symbols used in the thesis; i, j, k ∈ V are vertices.
tured relationships in the data. Finally, graph analytical problems tend to be communication-heavy because they need to explore certain regions of the graph but do less computation on the graph data.
1.1 Notation
We denote an unweighted graph that contains no multi-edges and loops as G = ( V, E ) , where V is the set of vertices and E ⊆ V × V the set of edges.
We will use i to denote the vertex v
i∈ V and e
ijfor the edge between i and j.
For undirected graphs it holds that e
ij= e
ji. We set | V | = n and | E | = m. We can define the adjacency of i as adj ( i ) = { v
j: e
ij∈ E } and the degree of i as deg ( i ) = | adj ( i )| (Note, for a directed graph, this regards to the out-degree of a vertex). We will refer by i − j − k to the two path from i to k containing the edges e
ijand e
jk. To denote a triangle consisting of vertices i,j,k and the edges e
ij, e
jkand e
ikwe use the symbol 4
ijk.
1.2 The Local Clustering Coefficient
The Local Clustering Coefficient (LCC) of a vertex i was defined by Watts and Storngratz [19] as the proportion of existing edges between the vertices adjacent to i divided by the possible number of edges that can exist between them.
Definition 1.1 (Local Clustering Coefficient) For a directed graph G the local clustering coefficient of a vertex i is defined as:
C ( i ) = |{ e
jk: v
j, v
k∈ adj ( i ) , e
jk∈ E }|
deg ( i ) ∗ ( deg ( i ) − 1 ) Similarly, for an undirected graph:
C ( i ) = 2 ∗ |{ e
jk: v
j, v
k∈ adj ( i ) , e
jk∈ E }|
deg ( i ) ∗ ( deg ( i ) − 1 )
1.3. On the difficulty of triangle computation We can see that for a pair of vertices { j, k } , in order to contribute to the numerator, the edges e
ij, e
ikand e
jkmust exist. This means that they form the triangle 4
ijkin G. Thus, if the degrees of the vertices are known and a found triangle can be assigned to the corresponding vertex, triangle counting and the computation of the local clustering coefficient can be regarded as the same problem. In the following, we will use the shorthand LCC for the local clustering coefficient and TC for triangle counting.
1.2.1 Significance of Triangles and LCC
Already in 1988, Coleman [5] argued that the existence of triangles (closure, as he calls it) is a necessary condition for the emergence of norms in societies.
He illustrates it with the simplest example, shown in Figure 1.1. If actors B and C are not connected to actor A, it may be able to negatively influence both B and C, without they had alone the power to resist. However, if there is some connection between them, collectively they may be able to sanction A, or one could reward the other for doing so. In that case, closure would stop the propagation of A’s negative influence in the network.
The LCC was found useful in numerous applications as well, such as for community detection in networks, database query optimization, or link clas- sification and recommendation. For example, Becchetti et al. [3] show that both the number of triangles and the local clustering coefficient are good measures for separating web spams from non-spam hosts. Remarkably, in the dataset they inspected, the approximated LCC was found to be the 14th best indicator for spams out of over two hundred properties.
Figure 1.1: A society with (a) and without (b) closure. Figure from [5].
1.3 On the difficulty of triangle computation
In the following, we assume that the graph is stored in a form that sup-
ports constant-time edge queries. Any graph G can have at most O( n
3)
triangles. This is the case when there is an edge between every vertex of G,
making it an n-clique. This inherently sets the worst-case running time of
1.3. On the difficulty of triangle computation any algorithm for TC at O( n
3) . We can distinguish the following two basic approaches for triangle counting:
Algorithm 1: Vertex based Triangle Counting Result: The number of triangles in G stored in counter
1:
counter = 0
2:for all i ∈ V do
3:for all j ∈ V do
4:for all k ∈ V do
5:
if ( i, j ) , ( i, k ) , ( j, k ) ∈ E then
6:
counter += 1;
7:
end if
8:
end for
9:end for
10:end for
11:
return counter;
Algorithm 2: Edge based Triangle Counting
Result: The number of triangles in G stored in counter
1:counter = 0
2:
for all i ∈ V do
3:
for all pair of distinct j, k ∈ adj ( i ) do
4:if ( i, j ) , ( i, k ) , ( j, k ) ∈ E then
5:counter += 1;
6:
end if
7:end for
8:end for
9:
return counter;
Vertex-centric. Trivially, one can find every triangle in a graph by enumer- ating the overall triplet of vertices and check whether edges exist between them. This approach is showed in Algorithm 1. This simple method leads to a Θ ( n
3) running time.
Edge-centric. Shifting our focus from vertices to edges, we can solve TC by enumerating over every two-paths. The pseudo-code of this approach is shown in Algorithm 2. We do Θ ( deg ( i )
2) work for every vertex, resulting in a overall running time of Θ ( ∑
i∈Vdeg ( i )
2) .
Whereas the vertex-centric approach depends only on the number of vertices
in G, the running time of the edge-centric algorithm is dependent on the
structure of the graph. For example, if every vertex has a constant degree,
vertex-based TC would still have a time complexity of Θ ( n
3) but an edge-
based algorithm would run in Θ ( n ) . We note that for a graph with a highly
1.4. Overview of the thesis skewed degree distribution a basic edge-based algorithm would spend most of the work at vertices with the highest degree, even though many of its neighbors may have degree one and thus they can not be part of a triangle.
For an extreme example, one can consider a star-graph for which the edge- centric algorithm is in Θ ( n
2) , but it has zero triangles. This shows how pre-processing the graph can have a significant effect on the running time.
1.4 Overview of the thesis
In this thesis we particularly focus on real-world graphs. Such networks have a power law degree distribution, that means that the fraction of P ( k ) nodes having degree k is:
P ( k ) ∼ k
−αtypically for 2 < α < 3. Its main implication for our purpose is the emer- gence of hubs in such networks, that is, the network will have a small num- ber of nodes having a degree multiple orders of magnitude bigger than the rest of the network.
The focus of this thesis is two-fold. Firstly, we analyse different methods used for triangle computation and develop a hybrid method to achieve bet- ter performance on shared memory. We take advantage of OpenMP [6]
for shared memory parallelism on edge level. Secondly, we analyze our distributed program for triangle counting that relies on a 1-dimensional partitioning scheme of the vertices. For the communication between the computing nodes, we take advantage of MPI’s Remote Memory Access [10]
interface. We use CLaMPI [7], a software cache for remote memory access.
We analyze how CLaMPI’s design choices and the graph structure affect the
caching performance and thus, the overall communication time.
Chapter 2
Related works
In the following, we give an overview of the different techniques used for distributed triangle counting. Instead of discussing related papers in detail, we focus on the two main parts of TC, namely the computation of triangles and the partitioning of the graph.
2.1 Computation of triangles
2.1.1 Frontier intersection
One way to compute the triangles is by intersecting the adjacency lists of every pair of vertices i, j for which e
ij∈ E. We will use A and B to denote the adjacency lists of i and j respectively.
Naive intersection. In case the adjacency lists are not sorted, a naive way to compute A ∩ B would be to compare every element in A with every element in B resulting in a running time of O(| A | ∗ | B |) .
Hashing. Still without sorting, one can utilize hashing to reduce the compu- tation time. Using one of the lists a hash table can be built with the help of some adequately chosen hash function. The computation of the intersection is then achieved by hashing every element from the other list and checking whether a match exists. The method’s main advantage is that the hash table built from the adjacency of vertex i can be reused for the intersection with every other vertex j ∈ adj ( i ) . However, there is extra place necessary for storing the hash table which can be a bottleneck for big graphs. Moreover, the handling of collisions in the hash table is another key part, which can also be time-consuming.
Pandey et al. [16] utilize hashing, but instead of hashing every element, they
use a certain number of bins in which they store multiple elements. An
2.1. Computation of triangles Algorithm 3: Sorted set intersection for A ∩ B
Result: The number of common elements in A and B
1:counter = 0
2:
i, j = 0
3:
while i < length ( A ) and j < length ( B ) do
4:if A [ i ] == B [ j ] then
5:
counter += 1;
6:
i += 1;
j += 1;
7:
else if A [ i ] < B [ j ] then
8:
i += 1;
9:
else
10:
j += 1;
11:
end if
12:end while
13:return counter;
element j ∈ B is then first hashed into one of the bins and then compared to every element belonging to that bin using linear search.
For the following two algorithms we assume that the neighborhood lists are sorted in increasing order.
Sorted set intersection (SSI). We can traverse the two lists simultaneously by comparing the current elements and progressing in the array whose cur- rent element is smaller. The pseudo-code of SSI is given in Algorithm 3.
Trivially, SSI computes the intersection of two lists in O(| A | + | B |) .
Binary search. Alternatively, the intersection of two lists can be seen as locating every element from one list in the other one. Thus, the problem becomes doing | A | lookups in a sorted array of length | B | , which can be done in O(| A | ∗ log (| B |)) by using binary search. The algorithm is outlined in Algorithm 4. To minimize the time complexity one should always assign the longer list as the search tree and the shorter one as the array of keys.
This method was first introduced by Hu et.al. [11].
By comparing the running times of the binary search-based and sorted set intersection-based algorithms, we see that SSI is faster if:
p + q ≤ p ∗ log
2( q ) (2.1)
q ≤ p ∗ ( log
2( q ) − 1 ) (2.2) q
p ≤ log
2( q ) − 1 (2.3)
As our focus is on graphs with highly skewed degree distribution, we would
expect that
pqis big for most of the edges, favoring the binary search method.
2.1. Computation of triangles Algorithm 4: Binary search for A ∩ B
Result: The number of common elements in A and B
1:Assuming length ( A ) < length ( B )
2:
counter = 0
3:
bottom = 0 top = length ( B ) − 1
4:for all x ∈ A do
5:
while bottom < top − 1 do
6:mid = b( top − bottom ) /2 c
7:if x < B [ mid ] then
8:
top = mid;
9:
else if x > B [ mid ] then
10:bottom = mid;
11:
else
12:
counter += 1;
13:
break
14:
end if
15:end while
16:end for
17:
return counter;
We emphasize that the two methods above assume sorted adjacency lists.
Even though, with many data sets, this is given for free, this overhead has to be taken into account when comparing these algorithms with others.
2.1.2 Algebraic computation
We describe the following method for an undirected graph G, but it can be extended to directed graphs as well. The adjacency matrix A of G can be written as the sum of the lower and upper triangular matrix L and U. The entries of L represent all the edges e
ij∈ E for which i < j and similarly U stores the edges e
ij∈ E, such that j < i. Therefore, by computing B = LU the matrix B will store every two-paths i − j − k for which i < j < k. Such two paths are closed into a triangle if the edge e
ik∈ E. Therefore, to obtain every triangle in G we can compute C = A ◦ B (Hadamard product). To attain the LCC for node i one can sum the values of the ith row of C and then divide it by the degree of the vertices.
TC implementations based on the algebraic computation method take ad- vantage of the sparsity of G and use highly-optimized libraries for sparse matrix multiplication. A parallel implementation with further improve- ments can be found in the paper from Azad and Buluc¸ [1], and a distributed algebraic-based TC algorithm has been implemented by Hutchinson [12] us- ing the Apache Accumulo distributed database.
Aznaveh et al. [2] implemented shared memory parallel TC and LCC com-
putation based on the SuiteSparse GraphBLAS implementation of the Graph-
2.2. Graph partitioning
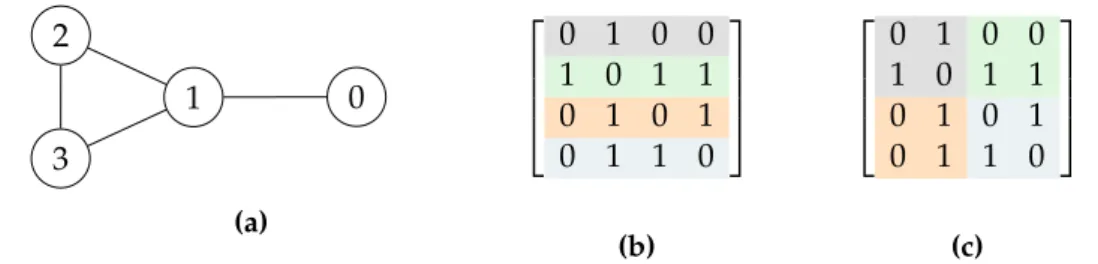
0 1
2
3
(a)
0 1 0 0 1 0 1 1 0 1 0 1 0 1 1 0
(b)
0 1 0 0 1 0 1 1 0 1 0 1 0 1 1 0
(c)
Figure 2.1: An example graph (a) and its basic 1D (b) and 2D (c) partitioning BLAS standard. The implementation uses OpenMP to achieve multithread- ing. They follow the algebraic method as well and compute the product of the upper and lower triangular matrix of the adjacency matrix with sparse matrix multiplication. For the LCC additional work is necessary to attain the degree of the vertices which leads to a significantly lower speedup com- pared to TC.
2.2 Graph partitioning
In the following, we discuss several techniques to achieve distributed TC.
We note that both the time spent with communication and computation can depend on the partitioning scheme. We assume that there are p computing nodes available P
1, P
2, . . . , P
p, p = 2
kfor some k and p divides n.
2.2.1 1D partitioning
One dimensional partitioning assigns equal sized blocks of vertices to nodes, that is we partition V into p distinct sets V = V
1∪ V
2. . . ∪ V
p. A basic 1D partitioning can be achieved by:
V
k=
v
i: i ∈
( k − 1 ) ∗ p n , k ∗ p
n
The node that owns vertex i will own every edge starting from i, and it will compute the LCC of i.
Whereas 1D partitioning can be done without pre-processing and introduces no space overhead, it suffers from the in-equal distribution of edges if G has a highly-skewed degree distribution. To partially overcome this one can sort the vertices by degree and instead of a block-based distribution cyclically distribute the vertices among the computing nodes.
2.2.2 2D partitioning
Two dimensional partitioning assigns edges to processes in a grid based
manner, partitioning the adjacency matrix A into a grid with dimensions
2.2. Graph partitioning
√ p × √
p such that E = E
1,1∪ E
1,2. . . ∪ E
1,√p∪ . . . E
√p,√p. The basic 2D partitioning of a graph is given by:
E
u,v=
e
ij: i ∈
( u − 1 ) ∗ √ p n , u ∗ √
p n
∧ j ∈
( v − 1 ) ∗ √ p n , v ∗ √
p n
The difference between 1D and 2D partitioning is visualized in Figure 2.1. To intersect the neighborhood lists of nodes i and j one has to first gather them issuing √
p − 1 vertical and horizontal communications with other processes.
To overcome this communication overhead, Tom and Karpys [18] developed a TC algorithm for undirected graphs following a parallel matrix multipli- cation scheme. They solve TC by computing a matrix C whose entry c
ijstores the number of triangles that contain e
ij. This can be computed by c
ij= U
i,∗L
i,∗if the triangles are ordered by i < j < k. However, a process P
i,jonly stores the parts L
i,(i+j)mod√pand U
(i+j)mod√p,j. Therefore, it firsts multiplies its local blocks and then shifts L left by one along its row in the processor grid and U up by one along its column. After √
p local multiplies and shifts the desired entry is computed.
2.2.3 Partitioning with proxy vertices
To completely avoid communication every process can store additional proxy
vertices and corresponding edges that are necessary for computing triangles
locally. This method was introduced for TC by Hoang et al. [8] who split
the partitioning of the graph into 3 steps. First, every vertex gets assigned
to a process by a 1D partitioning scheme. Then proxy vertices are created
for every edge whose endpoint does not belong to the same process as its
starting point. Finally, the newly added proxy edges are connected. We note
that care has to be taken in order not to count a triangle multiple times.
Chapter 3
MPI-RMA and Caching
3.1 MPI-RMA
For communication between processes, we take advantage of MPI’s Remote Memory Access programming environment [10]. MPI-RMA allows pro- cesses to directly read from or write to non-local memory regions using remote direct memory access (RDMA). RDMA is implemented in hardware and can bypass the operating system allowing faster communication with lower CPU usage than other communication methods.
In MPI-RMA processes are organized into communication groups in which the participants can expose a certain region of their local memory through the creation of a window. Processes may allocate a new memory region to be shared in the window, attach an already allocated region or establish a win- dow without an underlying memory buffer and subsequently bind regions to it. Furthermore, MPI-RMA allows processes to share a buffer attached to a window between multiple processes by shared window allocation. This can be useful for multicore nodes where MPI processes on the same node share memory. Remote accesses to a window are always addressed relative to the start of the window at the target process.
Once a window is established, processes can read from or write to this
now shared memory region. The two basic operations for data movement
are MPI Get and MPI Put for the reading and writing of non-local mem-
ory. Furthermore, additional atomic operations are defined to accumu-
late data. The MPI CAS function can be used for remote atomic com-
pare and swap operation and MPI Accumulate for updating data by com-
bining the existing remote data and the data sent with the accumulator. The
MPI GetAccumulate allows remote read-modify-write operations. A simpler
version of MPI GetAccumulate is MPI FetchAndOp that limits the data to a
single element in order to allow hardware optimizations and thus achieve
faster completion.
3.2. Caching Communication in MPI-RMA is always non-blocking and is split into epochs that are started and ended by synchronization. The process-local mem- ory region can be accessed by other processes during an exposure epoch, whereas a process can access remote data during an access epoch. Processes may be simultaneously in an access and exposure epoch. Epochs form a unit of communication and all communication operations are completed at epoch closure.
There are two methods to achieve synchronization between processes based on whether the target process is involved in synchronization. In active target synchronization, a process exposes its memory region for an epoch, during which it can allow either only read or both read and write operations. Fine- grained synchronization can be achieved by allowing processes to decide for which other processes they open an access or exposure epoch. On the other hand, with fence synchronization, all processes synchronously call fence to start or end an epoch. With passive target synchronization processes always make their memory available either to processes that specifically locked it or globally to all processes in the communicator. In the single-process lock- /unlock model acquiring a lock guarantees local memory consistency and releasing the lock closes the epoch and guarantees remote memory consis- tency.
3.2 Caching
A cache is a small storage that aims at speeding up the access of instructions or data by storing frequently used elements. Caches can be implemented in hardware, such as CPU or GPU caches, or in software such as Web caches.
Data caches became very important in recent years as the rate of improve- ment in processors exceeded the rate of improvement in storage and data bus technologies. Thus, data movement became a bottleneck in computa- tion making the need for a hierarchical storage structure that stores a small set of regularly accessed data ”closer” to the CPU. In the case of hardware caches, this is achieved by different technologies used for caches than for main memory which supports faster data access. A software cache reduces data movement by storing a subset of the commonly accessed data locally thus saving remote communication.
3.2.1 Locality
Caches are based on the locality principle which says that programs tend to access either the same data multiple times or elements close to the previ- ously accessed ones.
Temporal locality. Data that has been recently accessed is likely to be ac-
cessed in the near future as well. Examples of this are variables that are
3.2. Caching frequently used in a program (e.g. counters, or some constant).
Spatial locality. Nearby elements are often accessed close together in time.
When traversing an array a program sequentially loads the elements from memory. Thus, if we cache some elements beforehand we can reduce the number of memory accesses and increase performance.
3.2.2 Hitting and missing
We call the set of data elements referenced by a program during a time period [ t − τ, t ] the working set, denoted by W ( t, τ ) . A cache hit occurs if the accessed element was present in the cache. Otherwise, we have a cache miss and the element has to be transferred from some other storage unit. In case of a miss, an old entry, called the victim, may need to be evicted in order to make space for the new element. This is called the eviction procedure and is crucial for good cache performance. Cache misses can be classified into three groups:
Compulsory misses. Every element in the working set has to be loaded into the cache first, resulting in a compulsory cache miss.
Capacity misses. If the working set of a program is bigger than the size of the cache, there will be no space left for some elements, causing capacity misses. The number of capacity misses can be reduced by increasing the cache size, or by a better eviction strategy.
Conflicting misses. Every element in the cache has to have an address to be accessible. If two elements from the working set map to the same address, they will produce a conflicting miss. Conflicting misses can be also reduced by the eviction strategy, or by the structure of the cache. For example, by using a fully associative cache, i.e. we store every entry under the same address in an array, we can fully eliminate conflicting misses, for the prize of longer lookup times. For hardware caches, increasing the cache size can also reduce the number of conflicting misses.
3.2.3 CLaMPI
CLaMPI [7] is a caching layer for remote memory access. It is built on top of
the MPI-RMA programming environment with the intention to fit into MPI’s
semantics thus enabling caching with minimal code changes necessary from
the user. ClaMPI stores remote memory reads (called a get operation in
MPI-RMA) that return the desired part of an exposed memory region from
another process inside the communication group. CLaMPI handles variable-
sized entries to flexibly support such read operations. In the following, we
discuss its most important design choices that will be useful for the analysis
of its performance for triangle counting.
3.2. Caching 3.2.4 Structure of CLaMPI
CLaMPI implements a caching layer using two data structures, a hash table to index the entries and an AVL tree to store the free regions in the under- lying memory allocated for the cache. For a cache C
wthat stores gets issued on the window w, we denote the corresponding hash table by I
wand the size of the memory reserved by S
w.
A get targeting a caching enabled window w is first hashed to check whether it is present in the cache. To minimize hash collisions four hash functions h
0. . . h
3are used that are randomly selected until either the entry is found in the cache (cache hit) or a free space in the index is found. A conflicting miss occurs if for an entry e no empty index is found with any of the hash functions.
For the entries in the cache a contiguous memory of size S
wis allocated. S
wshould be a multiple of the CPU’s cache line size. The AVL tree used for storing free regions serves free region queries in O( logN ) time, where N is the number of free regions. Furthermore, it provides a best fit policy for the allocation of new entries. Nonetheless, due to the contiguous memory layout, after several evictions, the storage may get fragmented. This can lead to capacity misses even if there is altogether enough memory to serve an insertion.
3.2.5 Handling of cache misses
As CLaMPI caches remote memory reads at the moment of issuing the re- mote read, the data targeted by the read is not yet available. However, a corresponding entry is allocated in the cache, therefore an entry’s state is not either missing or cached but can be pending. Pending is an intermediate state meaning that it has been successfully indexed as well as a suitable space has been reserved for it but the data has not arrived yet. An entry transfers from pending to cached at epoch closure.
Compulsory misses. A compulsory miss means that the data was not found in the cache, however, there has been a free entry found in I
was well as a space big enough to store the data. The entry’s state always becomes pending.
Conflicting misses. In case of a conflicting miss there is enough space to store the data but all h
0( e ) . . . h
3( e ) led to a collision in the hash table. A victim is chosen randomly out of these four entries and evicted. Therefore, similarly to a compulsory miss, an entry’s state always becomes pending after a conflicting miss.
Capacity misses. A capacity miss means that there is no free region big
enough to store the data, therefore a victim has to be selected. CLaMPI
3.2. Caching does not guarantee insertion in case of a capacity miss but always evicts one entry. This is because multiple evictions may be necessary to make a space big enough for the entry. This could lead to a significant overhead.
Furthermore, if the entry is a highly accessed one, after several evictions enough space may be freed to cache. As a result, after a capacity miss the element may stay in missing status.
For the handling of capacity misses the following algorithm is used to choose a victim entry to evict. First, an interval I
w[ i : i + α ] in the hash table is se- lected randomly, where the length of the interval α can be set by the user.
Assuming that the entries in the hash table are uniformly distributed (which is a corollary of the hash function used) this interval represents a random sample of entries.
A score R is assigned to every entry at insertion which is then used for selecting the victim. R is computed by the entries temporal score R
tand positional score R
p, R = R
t∗ R
p. The score of an entry seeks to maximize the caching performance by representing an entry’s probability to be used in the future as well as counteracting fragmentation in the memory allocated for the cache.
The temporal score follows a least recently used scheme and is computed by R
t=
last time accessednumbef of gets issued in the window
. The positional score assigns a lower value to entries that have bigger free spaces adjacent to them. On the one hand, this reduces fragmentation. On the other hand, by evicting an entry with a lower positional score, it is more likely that enough space will be freed up to store the new entry. Let ¯ s
ibe the average size of entries present in the cache after the i-th get and q
ethe size of free memory adjacent to the entry e. The positional score of an entry e after i gets is then given by:
R
ip( e ) = min
| s ¯
i− q
e|
¯ s
i, 1
3.2.6 Adaptive scheme
CLaMPI’s performance is highly dependent on the size of memory allocated for the cache and on the configuration of the index table. In the context of caching remote memory accesses, the working set W ( t, τ ) can be viewed as the set of gets issued in the time interval [ t − τ, t ] . Denoting the set of cached entries at time t that belong to the working set by γ ( t, τ ) we have the following two constraints:
| γ ( t, τ ) ≤ | I
w| and ∑
g∈γ(t,τ)
size ( g ) ≤ | S
w|
3.2. Caching As for the memory size, while it is beneficial to increase S
wif the total size of gets exceeds the total capacities of the machine, one has to bound S
win order not to run out of memory.
The size of the hash table (index size) also influences the caching perfor- mance as well as the overhead of CLaMPI. In case when | I
w| is too small the number of conflicting misses will get large, thus constantly evicting entries leading to a bad utilization of the cache memory. On the other hand, if | I
w| is too big, the random set selected for eviction after a capacity miss may be empty. As CLaMPI always evicts an entry, this would lead to traversing more than α elements and thus increasing the overhead.
As finding the correct settings for I
wand S
wcan be cumbersome, CLaMPI offers an adaptive mode that dynamically adjusts them. A sign for a too small I
wis when the portion
con f lictingtotal gets
exceeds some bound. A too big I
wcan be detected based on the number of empty entries traversed at eviction
after a capacity miss. While it is important to have a hash table and memory
size suitable to the program, as changing any of the parameters requires the
invalidation of the cache, caching performance may be decreased due to the
numerous flushes.
Chapter 4
Distributed LCC with CLaMPI
In the following, we outline our distributed implementation for the com- putation of the local clustering coefficient and discuss how caching can be done in order to reduce communication.
4.1 Outline of our implementation
4.1.1 Graph pre-processing and distribution
We start by reading in the edge list of the graph from external storage in parallel. As a second preparation step, we remove every loops and multi- edges in the graph.
As we hope that caching can significantly reduce communication we min- imize the overhead of pre-processing and partitioning. By this reason, we use 1D partitioning to distribute the graph and after partitioning the only pre-processing applied is the removal of vertices that have a degree less than two. It is easy to see that such vertices cannot be part of a triangle.
4.1.2 Graph format
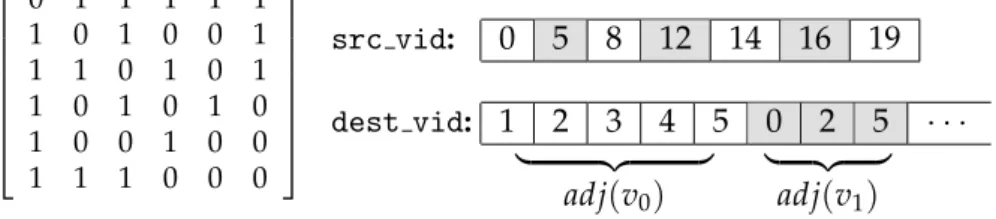
We convert the edge list of the graph into a compressed sparse row (CSR)
format. CSR stores a binary matrix using two arrays that we call src vid and
dest vid. For a graph G the pair of entries src vid[i], src vid[i+1] store
the beginning and the end of the adjacency list of the vertex i. Respectively,
the slice dest vid[src vid[i]:src vid[i+1]] stores the adjacency of the
vertex i. Note that the out-degree of a vertex i is thus given by deg[i] =
row[i+1] - row[i].
4.1. Outline of our implementation
0 1 1 1 1 1
1 0 1 0 0 1
1 1 0 1 0 1
1 0 1 0 1 0
1 0 0 1 0 0
1 1 1 0 0 0
src vid: 0 5 8 12 14 16 19 dest vid: 1 2 3 4 5 0 2 5 · · ·
| {z } | {z } adj ( v
0) adj ( v
1)
Figure 4.1: A graph represented by its adjacency matrix and the correspond- ing CSR representation.
4.1.3 Communication
We use MPI’s One Sided interface to read non-local partitions of the graph by creating two communication windows w
sand w
din which processes share its local src vid and dest vid arrays. Both windows are created with a communication group containing every process. We follow the passive target synchronization method as the graph is never changed hence there is no synchronization necessary. At the beginning of the computation, we globally lock both windows and unlock them only when every process is finished. As a result, the processing of vertices is fully asynchronous.
By distributing the graph among multiple processes, source vertex IDs be- come local in the CSR representation. We denote by n the number of vertices in G and by p the number of computing nodes used. In order to determine which process owns a vertex, and what is its local ID we can use the follow- ing rules:
Local ID to global ID: global ID = local ID * (n / p) + local ID Global ID to local ID: local ID = global ID / (n / p)
Process ID: dest proc = global ID % (n / p) 4.1.4 Triangle computation
Every process computes the LCC score of all the vertices it owns one after the other, to achieve locality. We follow the edge-centric way of TC and count the number of triangles of which vertex i is part of by computing adj ( i ) ∩ adj ( j ) for every j ∈ adj ( i ) . We achieve shared memory parallelism by doing the computation of the intersection in parallel, for which we used OpenMP.
4.1.5 Implemented algorithm
The outline of the final algorithm is depicted in Algorithm 5. Lines 1-5
represent the reading, pre-processing and 1D distribution of the graph. In
4.1. Outline of our implementation
line 7 the graph is already distributed, and thus the communication epoch
for both windows w
sand w
dcan be started. In the case of an edge having an
endpoint that belongs to a different process, the remote read of its degree
and adjacency list happens in Lines 17-18. We note that the remote read
targeting w
dis dependent on the read targeting w
sas src vid[i] stores
the address of the adjacency list of the vertex i in dest vid. Lines 24-36
compute the intersection, where we dynamically assign the lists based on
their lengths, as well as choose the method used for the intersection. In Line
40 the computation of LCC of every local vertex has been finished.
4.1. Outline of our implementation Algorithm 5: Distributed LCC computation
Result: Local clustering coefficient for every local vertex.
1:
edge list ← ReadInGraph(G);
2:
edge list ← NormalizeGraph(edge list);
3:
edge list ← 1DPartitioning( edge list );
4:
src vid , dest vid ← BuildCSR( edge list );
5:
local verts = n / p ;
6:lcc[] ;
7:
MPILockAll() // Start the communication epoch for all processes.
8:
for v src in 0 . . . local verts-1 do
9:
src degree = src vid[i+1] - src vid[i] ;
10:
src adjacency list = dest vid[src vid[i]:src vid[i+1]-1];
11:
triangle count = 0;
12:
for all v dest in src adjacency list do
13:dest processID = b v dest / local verts c ;
14:v dest local = v dest % local verts;
15:
// If the endpoint of the edge is non-local, it has to be attained.
16:
if dest processID ! = myID then
17:
dest degree ← RemoteRead(dest processID, v dest, src window);
18:
dest adjacency ← RemoteRead( dest processID , v dest , dest window );
19:
else
20:
dest degree = src vid[v dest local+1] - src vid[v dest local] ;
21:dest adjacency list =
dest vid[src vid[v dest local]:src vid[v dest local+1]-1] ;
22:end if
23:
// Prepare for intersection.
24:
if length(dest adjacency list) < length(src adjacency list) then
25:shorter list = dest adjacency list;
26:
longer list = src adjacency list;
27:
else
28:
shorter list = src adjacency list;
29:
longer list = dest adjacency list;
30:
end if
31:
// Decide which method to use for intersection. The intersection is done in parallel.
32:
if DecideIntersection( shorter list , longer list ) then
33:
triangle cnt += SortedSetIntersection( shorter list , longer list );
34:
else
35:
triangle cnt += BinarySearchIntersection( shorter list , longer list );
36:
end if
37:end for
38:
lcc[i] = ComputeLCC(triangle cnt, src degree)
39:end for
40:
MPIUnlockAll() //Close the communication epoch for all processes
41:return lcc;
4.2. Caching for distributed LCC
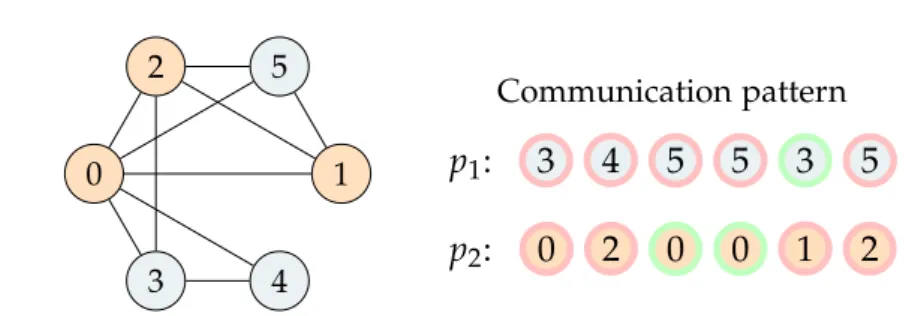
0 1
2
3 4
5 Communication pattern
p
1: 3 4 5 5 3 5 p
2: 0 2 0 0 1 2
Figure 4.2: (Left) The graph from Figure 4.1 partitioned with 1D partitioning among two processes. (Right) The sequence of remote accesses, with green showing cache hits.
4.2 Caching for distributed LCC
In case multiple local vertices have a common non-local neighbor, the same data has to be transferred several times. In order to decrease communication one can introduce caching to store, next to the own vertices, some of the most often accessed non-local vertices as well. This approach is most similar to the proxy vertices method discussed in Section 2.2.3. The entries in the cache can be regarded as a dynamically determined sub-graph containing vertices that have been accessed regularly and thus are expected to be accessed in the future as well.
4.2.1 A small scale example
To illustrate how caching can reduce communication, consider the scenario depicted in Figure 4.2. We partitioned the graph using 1D partitioning among two processes p
1(blue) and p
2(orange). If no caching is used 12 times the neighborhood list of a non-local vertex is read by either of the processes.
Now suppose we operate with a cache layer that can store the adjacency of one vertex, and after an entry was inserted into the cache it does not get evicted. Assuming we process the vertices in increasing order, p
1would cache the neighborhood list of v
3and p
2of v
0. This would result in 3 cache hits leading to a reduction in communication by 25%. We have 3 capacity misses and 5 compulsory misses limiting the best achievable improvement to 42%.
4.2.2 A large scale example
In general, by distributing the graph among several processes a high por- tion of the edges will have endpoints belonging to different partitions. For example, for a graph with 2
20vertices and 2
24edges partitioned into 4 parti- tions by the 1D method 95% of the edges go between two distinct partitions.
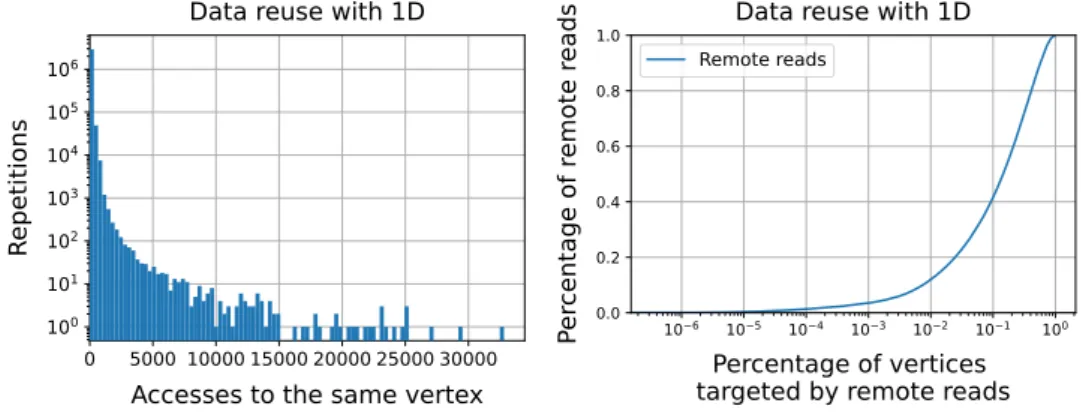
Therefore, communication may become dominant in LCC computation. Fur-
4.2. Caching for distributed LCC thermore, as most real-world networks follow a power law, a big portion of the remote reads will target the same vertices. Figure 4.3 shows how the highest degree nodes contribute to the number of remote accesses and to the total data transferred between processes. We can see that only 10% of the highest degree vertices make up more than 40% of the number of remote reads.
Figure 4.3: Data reuse for the SNAP-LiveJournal graph. (Detailed in Table 5.1)
4.2.3 CLaMPI for distributed LCC
As discussed earlier, we use CLaMPI to cache remote reads. The caching happens at lines 17 and 18 in Algorithm 5. We enable caching for both windows, that is we have a cache layer C
sfor src vid and C
dfor dest vid at every process. We denote the sizes of the arrays of a graph’s CSR rep- resentation by | src vid | and | dest vid | . Moreover, we use | src vid |
iand
| dest vid |
ifor parts locally stored at the process p
i. 4.2.4 Configuration of CLaMPI
Assuming that vertices are assigned randomly to computing nodes, the in- degree of a vertex explicitly correlates with the number of times it will be remotely accessed. Using p computing nodes, a node p
iwill access a non- local vertex j in expectation
deg−p(j)−ptimes. Therefore, if caching is done properly, we expect to store some of the highest in-degree nodes.
For the configuration of C
Sthis has no special implications as src vid stores
only the location of the adjacency arrays. Thus, for every vertex indepen-
dently from its degree, the corresponding cache entry will have a size of
two.
4.2. Caching for distributed LCC However, C
dis closely dependent on this observation. As we focus on scale- free graphs, the difference between degrees is huge and a small percent of the vertices is expected to be adjacent to most of the edges.
Cache size. While the bigger the cache is the better performance we could achieve, we have to limit the cache size in order to simulate a scenario where memory becomes a bottleneck. As C
sdepends only on the number of ver- tices, we can tune it so that we achieve a relatively low miss rate. On the other hand, S
ddepends on the number of edges in the graph, therefore its size has to be more limited.
Index size. To set the index size we have to estimate the number of entries we expect to store in a cache with a given size. For C
sthis is I
s= S
s/2, as every entry will have a size of two.
We first describe the rule for setting the index size of C
dfor undirected graphs in which case in-degree equals out-degree. Let the size of C
dbe S
dand denote the total size of the non local adjacency lists for a process p
iby d
i( d
i= | dest vid | − | dest vid |
i). To get a good approximation we will use that the underlying graph is a power law graph, that is the fraction of p ( k ) vertices having degree k can be well approximated by p ( k ) = C ∗ k
−αfor some constant C, and 2 < α < 3.
Assume that k is a continuous real variable following a power law p ( k ) . We are interested only in the case where 2 < α. As p ( k ) represents a probability distribution, we can compute C as:
1 =
Z
∞kmin
p ( x ) dx ⇒ C = R
∞1
kmin
x
−αdx = ( 1 − α ) [ x
1−α]
∞kmin
= ( α − 1 ) ∗ k
αmin−1(4.1) Keeping the assumption that the graph’s degree distribution is approxi- mated by a continuous power law p ( k ) , the fraction of vertices that have degree bigger than k is given by:
p ( k ) =
Z
∞k
P ( x ) dx = C ∗
Z
∞k
x
−αdx = C
α − 1 k
−(α−1)= k
k
min 1−α(4.2) Furthermore, we can compute the fraction that such vertices make up out of the sum of all degrees (e.g out of | dest vid | ) as:
W ( k ) = R
∞k
x
−αdx R
∞kmin
x
−αdx = k
k
min 2−α(4.3)
By re-organizing both to eliminate
kkmin
![Figure 1.1: A society with (a) and without (b) closure. Figure from [5].](https://thumb-eu.123doks.com/thumbv2/1library_info/3901479.1524453/8.892.315.570.723.859/figure-society-b-closure-figure.webp)