Starke Silben und Spracherwerb
Phonetische Modelle des Spracherwerbs Hauptseminar Phonetik SoSe 2007
Prof. Dr. Jonathan Harrington
Referentin: Larissa Nubert
Fragestellung
Welchen Beweis gibt es bei Erwachsenen für eine rhythmisch/metrische Segmentierung- Strategie („metrical segmentation strategy“
= MSS), um neue Wörter aufzudecken?
Einleitung
• Frage: Wie können Hörer in der
gesprochenen Sprache Wörter erkennen und deren Bedeutung wahrnehmen?
• Problem: Die Wortgrenzen sind im
Sprachfluss nicht immer eindeutig
gekennzeichnet!
Wieso funktioniert die Worterkennung dennoch (fast) immer problemlos?
Welche Mechanismen werden zur
Erkennung angewandt?
Gliederung
I. 3 Theorien zur Worterkennung II. Studien/Ergebnisse
• Studie/Ergebnisse Culter/Norris 1988: MSS
• Studie/Ergebnisse McQueen et al. 1994
• Studie Cutler/Butterfield 1992
III. MSS „metrical segmentation strategy“
I. Theorien zur Worterkennung
3 Theorien:
• Der sequenzielle Prozess
• Der prosodische Segmentierungsprozess
• Der Konkurrenzprozess
1. Theorie zur Worterkennung
Der sequenzielle Prozess:
• Die Wörter werden der Reihe nach von links nach rechts wahrgenommen.
• Annahme: Der Onset des nächsten Wortes
kann erst dann erkannt werden, wenn das
aktuelle Wort erfolgreich erkannt worden
ist.
Voraussetzung für die sequenzielle
Erkennung: Die Wörter müssen vor ihrem Offset „einzigartig“ sein und als diese
erkannt werden.
Probleme:
• Die meisten Wörter werden erst nach ihrem Offset als eindeutig erkannt.
• Einbettung von Wörtern, sowie Suffixe erschweren den Erkennungsprozess.
Bsp. boy - boycott, run – running – runner
2. Theorie zur Worterkennung
Der prosodische Segmentierungsprozess
• Die Worterkennung erfolgt über den
Prozess der lexikalischen Segmentierung.
• Basis: Die prosodische Struktur der Sprache
• Prinzip der MSS
Der prosodische
Segmentierungsprozess
Modell:
• Es gibt Annahmen darüber, wo Wortgrenzen wahrscheinlich auftreten und dadurch wird gefolgert, wo es angemessen ist mit dem lexikalischen Zugang („lexical access“) zu beginnen.
• MSS:
Starke Silben setzten die Segmentierung in Gang
3. Theorie zur Worterkennung
Der Prozess der wortinternen Konkurrenz:
SHORTLIST (Norris, 1994)
• 2 Stufenmodell
• 1. Phase: Aktivierung:
Eine Kandidatenmenge wird als „Shortlist“ angelegt
• 2. Phase: Konkurrenz:
Die verbleibenden Kandidaten werden zu einem
Netzwerk verbunden, und durch laterale Inhibition
weiter verringert, bis das Zielwort erkannt ist.
Theorie: Kombination aus SHORTLIST und MSS
• McQueen et al. (1994), Norris et al. (1995) Annahme:
• Wörter mit starker erster Silbe werden stärker aktiviert, als Wörter mit schwacher erster Silbe.
• Aktivierung nur an diesen Stellen (MSS); nicht mehr an jeder möglichen Stelle (SHORTLIST)
• Konkurrenz Effekte sind größer für schwach-
starke, als für stark-schwache Wörter.
II: Studien/Ergebnisse
• Cutler/Norris (1988): Annahme der MSS
• McQueen et al. (1994) und
Cutler/Butterfield (1992): Unterstützung
und Erweiterung der Theorie der MSS
Studie Cutler/Norris 1988
• MSS = „metrical segmentation strategy“
• Vorschlag: Die lexikalische Erkennung
wird bei Akzentsprachen (Bsp. Engl.) durch metrische Segmentierung in Gang gesetzt.
• Unterschiedliche Silbenstruktur:
starke vs. schwache Silben
• Starke Silben (s): Silben mit Vollvokal, tragen Erst- oder Zweitakzent
• Schwache Silben (w): Silben mit
reduziertem Vokal, meistens [ə], tragen
keinen Akzent
Experiment Cutler/Norris 1988
• „word-spotting task“: Erkennung von realen
Wörtern eingebettet am Beginn von zweisilbige Pseudo-Wörter
• Zeitmessung Folgerung wie schnell (leicht) oder langsam (schwer) die Erkennung war.
Bsp. Erkennung von mint in /m І nte І f/ (stark-starke
Silben) und /m І ntəf/ (stark-schwache Silben)
MSS
• Starke Silben setzten die Segmentierung in Gang.
• Starke Silben sind meist der Onset von lexikalischen Wörtern und somit wird an diesen Stellen der lexikalische Zugang begonnen. (s. Cutler/Butterfield)
• Wichtig: Ein prälexikaler Mechanismus
muss starke Silben im Wortfluss erkennen.
Cutler/Butterfield 1992
• Annahme: starke Silben sind meist die initialen Silben von lexikalischen Wörtern
• „Misperception“-Experimente; die Hörer bekamen unverständliche/schwer verständliche
Wortäußerungen und sollten aufschreiben, was sie gehört haben
• „Misperceptions“ treten an Wortgrenzen auf
• Mögliche Fehler: Grenzen hinzufügen oder tilgen
Ergebnis Culter/Butterfield
vor starken Silben werden Grenzen
eingefügt; vor schwachen Grenzen getilgt
Grenzeinfügung vor starken Silben führt zur Wahrnehmung von lexikalischen
Wörtern; Grenzeinfügung vor schwachen
Silben spricht für grammatikalische Wörter
Folgerung:
Starke Silben sind meistens die initialen Silben von lexikalischen Wörtern, während schwache Silben meistens nicht wortinitital sind und verstärkt bei grammatikalischen Wörtern auftreten.
• Engl.: 90% der Inhaltswörter beginnen mit
starker Silbe; ca. 75% aller starken Silben
sind die initialen Silben von Inhaltswörtern
(Cutler/Carter, 1987)
Ergebnis Cutler/Norris 1988
Annahme war:
• Starke Silben setzten die Segmentierung in Gang.
• Starke Silben sind meist der Onset von
lexikalischen Wörtern und somit wird an
diesen Stellen der lexikalische Zugang
begonnen.
Ergebnis Cutler/Norris:
• Zu erkennende Zielwörter (s) (am Beginn von Wörtern) sind schwieriger in ss-
Pseudo-Wörtern zu erkennen, als in sw.
Bsp.: mint in /m І nte І f/ (stark-starke Silben) ist schwieriger zu erkennen, als in /m І ntəf/
(stark-schwache Silben)
Zielwörter schwieriger zu erkennen in ss, als sw
Grund:
• MSS besagt, dass an starken Silben eine Segmentierung ausgelöst wird, also hier: an der zweite Silbe /te
Іf/ in
/m
Іnte
Іf/ (ss) wird eine Segmentierung ausgelöst (die zweite Silbe von der ersten getrennt) : und somit die Erkennung von mint behindert wird.
• Bei /m
Іntəf/ (sw) ist das Erkennen von mint einfacher, weil die schwache Silbe /təf/ keine Segmentierung
auslöst.
Bestätigung der MSS: Segmentierung bei starken Silben
McQueen et al. 1994
• SHORTLIST-Modell: Aktivierung und Konkurrenz
• Annahme: SHORTLIST und MSS als
Kombinationsmodell der Worterkennung.
Stärkere Aktivierung (SHORTLIST) der
starken Silben (MSS)
Experiment McQueen et al. 1994
• Worterkennungstest wie bei Cutler/Norris
• Erkennung von realen Wörtern in zweisilbigen Pseudo-Wörtern, am Beginn oder am Ende
Bsp.: mess in /nəmεs/ (ws) und /dəmεs/ (ws)
Zielwörter am Ende
Bsp.: sack in /sækrəf/ (sw) und /sækrək/ (sw)
Zielwort am Anfang
Experiment McQueen et al.
• Annahme: Die Erkennung von Zielwörtern wird durch Konkurrenten erschwert.
mess in /dəmεs/ ist schwieriger zu erkennen, da hier die Konkurrenten domestic, domesticated auftreten.
mess in /nəmεs/ ist somit einfacher zu erkennen, weil es keine Konkurrenten gibt.
sack in /sækrəf/ ist schwieriger (Konkurrent sacrifice)
zu erkennen, als in /sækrək/ (keine Konkurrenten)
Ergebnis McQueen et al. 1994
• Kombinationsmodell SHORTLIST und MSS
• SHORTLIST: der lexikalische Zugriff ist effektiv an allen mögliche Stellen möglich
• MSS: lexikalischer Zugang ist effektiv bei starken Onsetsilben möglich
Durch die Kombination der Modelle ergibt sich
nun eine Steigerung (stärke Aktivierung) für nur
die lexikalischen Kandidaten, die mit einer starken
Silbe im Onset beginnen.
Erkennung von Zielwörtern:
Die Erkennung von Zielwörtern in ws-Pseudo- Wörtern ist einfacher als in sw-Wörtern. (=MSS)
• Antworten sind schneller, als auch akkurater in ws (da hier: Segmentierung; stärkere Aktivierung,
Segmentierung direkt am Onset des Zielwortes), als in sw-Pseudo-Wörtern (da hier: keine
Segmentierung)
Die Erkennung ist schwieriger, wenn die
Zielwörter Onsets von realen längeren Wörtern
waren; einfacher bei richtigen Pseudo-Wörtern.
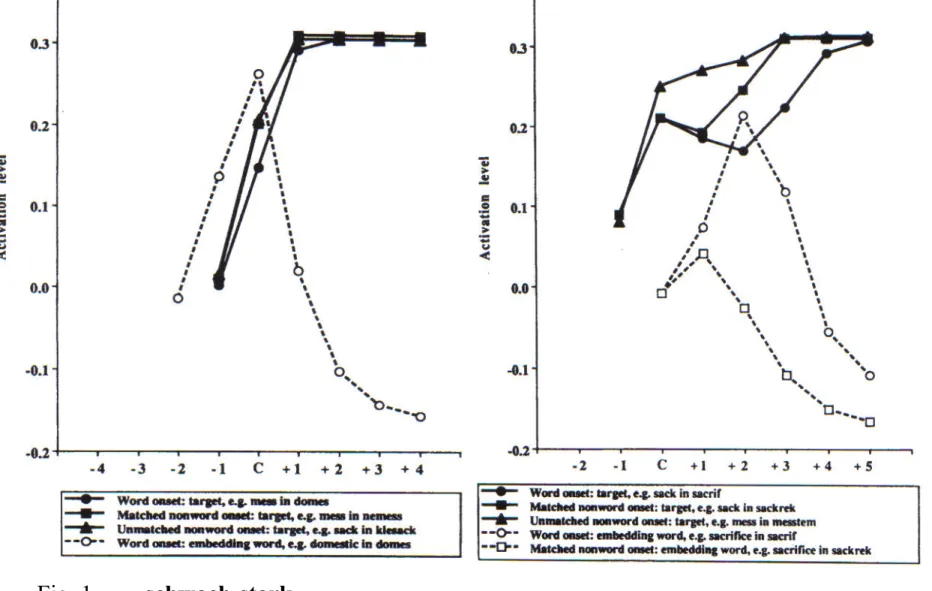
Fig. 1:
- ws = größere Aktivierung, leichtere Erkennung
- Zielwort am Ende
- Konkurrenten: weniger Aktivierung, Erkennung schwieriger
- Keine Konkurrenten: stärker Aktivierung
Quelle: McQueen et al. 1994, S. 626
Fig. 2:
- sw = geringere
Aktivierung, schwierigere Erkennung
- Zielwort am Beginn
- Konkurrenten: weniger Aktivierung, Erkennung schwieriger
- Keine Konkurrenten:
stärkere Aktivierung
Fig. 1 schwach-stark
größere Aktivierung, leichtere Erkennung Fig. 2 stark-schwach
Geringere Aktivierung, schwierigere Erkennung
Tabelle: Reaktionszeiten für ws vs. sw Wörter
Nonword onsets
Stress pattern Word onset Target matched Target unmatched WS
RT (ms) 665 558 569
Error rate (%) 44 26 24
Example /dəmεs/ /nəmεs/ /kləsæk/
SW
RT (ms) 843 847 843
Error rate (%) 57 45 46
Example /sækrəf/ /sækrək/ /mεstəm/