Institut f¨ur Softwaretechnik, Fachbereich 4
JGraLab:
Konzeption, Entwurf und Implementierung einer Java-Klassenbibliothek f¨ur TGraphen
Diplomarbeit
zur Erlangung des Grades eines Diplom-Informatikers im Studiengang Informatik
vorgelegt von Steffen Kahle Mat.-Nr. 200210168
am 07.06.2006
Betreuer: Prof. Dr. J¨urgen Ebert, Institut f¨ur Softwaretechnik, Fachbereich 4 Dr. Volker Riediger, Institut f¨ur Softwaretechnik, Fachbereich 4 Koblenz, im Juni 2006
1 Einleitung 8
1.1 Motivation . . . 8
1.2 Definitionen und Schreibweisen . . . 9
1.2.1 Definition der TGraphen . . . 9
1.2.2 Beispiel eines TGraphen . . . 11
1.2.3 Erkl¨arung der formalen Definition . . . 12
1.3 Graphenlabor . . . 17
1.4 Uberblick ¨uber diese Diplomarbeit . . . .¨ 18
1.4.1 Anlehnung an bestehende Metamodelle . . . 19
1.4.2 Typisierung - Typsystem vs. Schema . . . 19
1.4.3 Performanztests . . . 20
1.4.4 Objektorientierte Zugriffsschicht . . . 20
1.4.5 Eingabe/Ausgabe . . . 22
1.4.6 Beispiel . . . 22
2 Anforderungen 23 2.1 Anforderungsliste . . . 23
2.1.1 Schema . . . 23
2.1.2 Graphen . . . 24
2.1.3 Attributierung . . . 24
2.1.4 Objektorientierte Zugriffsschicht . . . 25
2.1.5 Ubergreifende Eigenschaften der Klassenbibliothek . . . .¨ 25
2.1.6 Eingabe/Ausgabe . . . 25
2.1.7 Performanz . . . 26
2.1.8 Dokumentation . . . 26
3 Entwurf 27 3.1 Motivation . . . 27
3.2 Vergleich der Metamodelle von GXL, MOF und ecore . . . 28
3.2.1 Einf¨uhrung der Metamodelle . . . 28
Inhaltsverzeichnis
3.2.2 Beispiele f¨ur GXL, MOF und ecore . . . 36
3.2.3 Verwendungsm¨oglichkeiten der Elemente der Metamodelle in JGraLab . . . 42
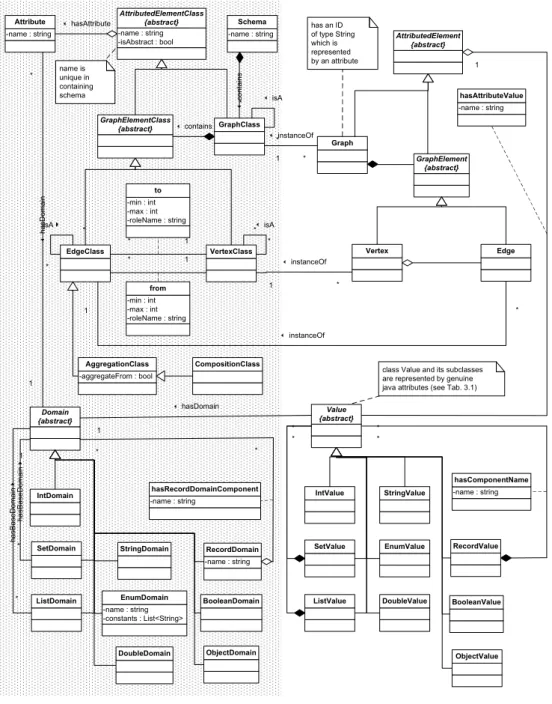
3.3 Erweiterte Definition der Meta-Ebenen in JGraLab . . . 44
3.4 Ubersichts-Klassendiagramm f¨ur JGraLab . . . .¨ 46
3.4.1 Allgemeines . . . 46
3.4.2 Die Schemaebene . . . 48
3.4.3 Wertebereichsystem . . . 51
3.4.4 Graphenebene . . . 52
3.4.5 Werte . . . 53
3.4.6 Beispiel in JGraLab . . . 54
3.5 Externe Klassendiagramme . . . 56
3.5.1 Die Schemaebene . . . 59
3.5.2 Die Graphenebene . . . 61
3.5.3 Das Wertebereichsystem . . . 64
3.5.4 Die Werte . . . 67
3.5.5 Beispielzugriffe auf die Werte . . . 68
4 Implementierung 82 4.1 Experimente bez¨uglich des Speicher- und Laufzeitverhaltens . . . 82
4.1.1 Allgemeine Beschreibung eines Beispielgraphen . . . 83
4.1.2 Beschreibung der objektorientierten Implementierung von TGra- phen . . . 83
4.1.3 Identifizierung der Knoten und Kanten bei der objektorientier- ten Speicherung . . . 86
4.1.4 Beschreibung der Verwendung einer Inzidenzliste f¨ur die Im- plementierung von TGraphen . . . 87
4.1.5 Identifizierung der Knoten und Kanten bei der Inzidenzliste . . 90
4.1.6 Durchf¨uhrung einer Speicherplatz und Performanzmessung . . 90
4.2 Objektorientierte Zugriffsschicht . . . 94
4.2.1 Motivation f¨ur eine OOAccess-Schicht . . . 94
4.2.2 Schnittstellen f¨ur eine Attributkapselung . . . 96
4.2.3 Beispiel f¨ur einen Attributzugriff . . . 98
4.2.4 Fabrikmethoden f¨ur den Objektzugriff . . . 101
4.2.5 Die JGraLab-Paketstruktur . . . 103
4.2.6 Die Ausf¨uhrung des Compilers zur Laufzeit . . . 103
4.2.7 Interne Klassendiagramme zur Generierung der Attribute . . . . 105
4.2.8 Gesamtskizzierung des Ablauf der Generierung der Objektori- entierten Zugriffsschicht . . . 107
4.3 Eingabe/Ausgabe . . . 109
4.3.1 Allgemeine Beschreibung des Beispiels . . . 109
4.3.2 Das GraLab-Dateiformat .G . . . 109
4.3.3 Nicht speicherbare Information in .G . . . 119
4.3.4 Das Type-System-Editor Dateiformat .TED . . . 121
4.3.5 Das JGraLab-Dateiformat . . . 125
4.3.6 Realisierung des neuen Dateiformats . . . 134
4.4 Ausnahmebehandlung . . . 140
4.4.1 Ubersicht . . . 140¨
4.4.2 M¨ogliche Ausl¨oser der Exceptions . . . 141
5 Beispiel 144 5.1 Ubersicht des Beispiels . . . 144¨
5.2 Code zur Erzeugung des M2 Graphenschemas . . . 144
5.3 Code zur Erzeugung des M1 Graphen . . . 148
5.4 Wichtige Benutzungshinweise . . . 150
5.5 Traversierung von Graphen . . . 150
5.5.1 Traversierung aller Knoten eines Graphens . . . 150
5.5.2 Traversierung aller Kanten eines Graphens . . . 151
5.5.3 Traversierung aller Inzidenzen eines Knotens . . . 152
6 Bewertung 153 6.1 Entwicklungen und Erfahrungen . . . 153
6.2 Weiterentwicklungen und Ausblick . . . 156
6.3 Zusammenfassung . . . 158
Abstract
Im Rahmen dieser Diplomarbeit wird das bisher unter C++ implementierte Graphenla- bor als Java-Klassenbibliothek JGraLab neu entwickelt.
Im GUPRO-Ansatz des Instituts f¨ur Softwaretechnik an der Universit¨at Koblenz-Landau bilden so genannte TGraphen eine Datenstruktur, um z.B. Quellcode zu repr¨asentieren.
TGraphen sind typisierte, attributierte, gerichtete und angeordnete Graphen.
Das Graphenlabor bietet eine Klassenbibliothek, um TGraphen als interne Datenstruk- tur effizient benutzen zu k¨onnen. Diese API bietet Traversierungs- und Manipulati- onsm¨oglichkeiten f¨ur TGraphen und ihr Typsystem an.
F¨ur die neue Version des Graphenlabors, JGraLab, werden Metamodelle analysiert und ein eigenes JGraLab-Metamodell entworfen, welches als Basis f¨ur den Entwurf dient.
JGraLab bekommt eine objektorientierte Zugriffsschicht, sowie ein neues Dateiformat zum Austausch von Schema und Graphen.
An dieser Stelle m¨ochte ich meinen Betreuern, Prof. Dr. J¨urgen Ebert und Dr. Volker Riediger f¨ur ihre ausf¨uhrliche Betreuung danken.
Unsere zweiw¨ochentlichen Treffen sorgten nicht nur f¨ur eine konstante Kontrolle der Leistung, sondern auch immer wieder daf¨ur, dass sich der ber¨uchtigte
”Metaknoten“ im Gehirn St¨uck f¨ur St¨uck aufl¨oste. Vor allem Dr. Volker Riediger danke ich hiermit spezi- ell, da er trotz seines st¨andig vollen Terminplans immer noch Zeit f¨ur die ausf¨uhrliche Beantwortung meiner zahlreichen Fragen fand.
Des Weiteren m¨ochte ich besonders meinen Eltern danken, da sie mir das Studium erm¨oglicht haben. Erst mit Hilfe ihrer konstanten mentalen und finanziellen Unterst¨ut- zung ist es mir gelungen, mein Studium innerhalb dieses Zeitraums erfolgreich zu ab- solvieren.
Um ein tiefgehendes Verst¨andnis dieser Arbeit zu bekommen, beantwortet dieses Kapi- tel grundlegende Fragen nach der Motivation der Entwicklung eines Graphenlabors. Es werden an dieser Stelle auch Begriffe und Schreibweisen formal definiert, damit in der gesamten Arbeit die Begriffsdom¨ane hinreichend gekl¨art ist. Zum Abschluß der Einlei- tung wird ein ¨Uberblick ¨uber diese Diplomarbeit gegeben.
1.1 Motivation
Der Begriff Graphentechnologie beschreibt einen Ansatz des Erstellens von Anwen- dungssoftware mittels extensiver Nutzung von Graphentheorie und Graphenalgorith- men. Graphen werden besonders f¨ur die Repr¨asentation von strukturierten Daten ver- wendet. Der Ansatz der Graphentechnologie benutzt eine Reihe von Konzepten, Kon- ventionen und Software, um Graphen nahtlos als Mittel der Kommunikation, als ma- thematische Basis f¨ur eine Formalisierung und als effiziente Klassenbibliothek f¨ur die Implementation verwenden zu k¨onnen.
Das Institut f¨ur Softwaretechnik der Universit¨at Koblenz-Landau verwendet insbeson- dere so genannte TGraphen (vgl. Abschnitt 1.2.1) f¨ur diesen Ansatz, also typisierte, attributierte, gerichtete und angeordnete Graphen. Jegliche Kanten und Knoten d¨urfen Attribut-Werte-Paare besitzen, wobei die Attribute dieser Knoten oder Kanten von ih- rem Typ bestimmt werden. Zus¨atzlich existieren mehrere Anordnungen der Elemente innerhalb eines TGraphen.
Diese Graphen repr¨asentieren im Besonderen Objektgeflechte, welche in der Objektori- entierung benutzt werden. Generell sind sie allerdings in deutlich ausgedehnter Weise verwendbar und besitzen viele zus¨atzliche Eigenschaften, wie z.B. ein Typsystem, wel- ches Mehrfachvererbung unterst¨utzt.
Um Anwendungssoftware mit der Unterst¨utzung f¨ur TGraphen zu entwickeln, existiert eine Klassenbibliothek mit dem Namen GraLab (vgl. Abschnitt 1.3). Diese Bibliothek erlaubt es einem Anwender, TGraphen als eine interne Datenstruktur anzusehen und
1.2. Definitionen und Schreibweisen damit M¨oglichkeiten der Manipulierung sowie Traversierung anzubieten. Zus¨atzlich erm¨oglicht sie einen Austausch dieser TGraphen und ihres Typsystems mittels eines eigenen Dateiformats [Eb03-2].
Motiviert wird eine Neuentwicklung von GraLab haupts¨achlich durch die m¨ogliche Ver- wendung stark objektorientierter Konzepte. So ist es sinnvoll, TGraphen sowie ihre Ele- mente direkt als Objekte ansehen zu k¨onnen. Auch Attribute der Kanten und Knoten k¨onnen im Sinne der Objektorientierung betrachtet werden.
Zus¨atzlich f¨ordert eine Anlehnung an geltende Konzepte aus der Softwaretechnik das Verst¨andnis und erweitert die Sprachdom¨ane. Aus diesem Grunde bekommt JGraLab ein eigenes Metamodell, welches an bestehenden Metamodellen angelehnt wird.
Das bisherige GraLab wurde in C und C++ mit einem sehr hohen Fokus auf Geschwin- digkeit realisiert. In den letzten Jahren wurde die Rechnergeschwindigkeit jedoch um ein Vielfaches gesteigert, so dass inzwischen eine leichte Verschiebungen des Fokus auf die Benutzerfreundlichkeit und erweiterte Funktionalit¨at gelegt werden kann. Zu diesem Zweck wird in dieser Diplomarbeit die Programmiersprache Java f¨ur die Implementati- on des neuen JGraLab eingesetzt.
1.2 Definitionen und Schreibweisen
In diesem Abschnitt werden die wichtigsten Fachtermini eingef¨uhrt und erkl¨art. Die- se werden in der gesamten Arbeit verwendet. Weitere spezifische Begriffe werden an entsprechender Stelle erl¨autert. Eine formale Definition der wichtigsten Begriffe ist not- wendig, bevor man erkl¨aren kann, was ein Graphenlabor ¨uberhaupt ist und inwiefern diese Arbeit dies verbessern kann.
Graphen sind eine essentielle Datenstruktur der Informatik und insbesondere dieser Di- plomarbeit. Viele algorithmische Probleme k¨onnen auf Graphen zur¨uckgef¨uhrt werden.
Graphen sind zum einen eine anschauliche sowie effiziente Datenstruktur und k¨onnen zum anderen mit formalen Methoden untersucht werden.
1.2.1 Definition der TGraphen
Ein Graph besteht aus Knoten und Kanten. Knoten kann man sich anschaulich als Punk- te innerhalb einer Ebene vorstellen. Kanten w¨urden dann diese Punkte innerhalb der Ebene verbinden. Die r¨aumliche Position dieser Knoten und Kanten ist allerdings v¨ollig
unerheblich, lediglich zwischen welchen Punkten es welche Kanten gibt, spielt eine Rolle.
In dieser Diplomarbeit werden sogenannte TGraphen verwendet, eine spezielle Art von Graphen. TGraphen werden durch die folgenden Eigenschaften definiert, sie sind:
• Typisiert: Jegliche Elemente eines TGraphen (also Kanten und Knoten, ferner auch die Graphen selbst) k¨onnen typisiert werden.
• Attributiert: Jedes Graphelement darf Attribut-Werte-Paare besitzen.
• Gerichtet: Generell sind TGraphen immer gerichtet, k¨onnen aber, ohne die Dar- stellung zu ¨andern, als ungerichtete Graphen angesehen werden. Dadurch kann z.B. gleichzeitig eine gerichtete und eine ungerichtete Traversierung der Graphen stattfinden.
• Angeordnet: Innerhalb eines Graphen existieren prinzipiell einige Anordnungen der Graphelemente untereinander. Zun¨achst besitzen alle Knoten v∈V eines Gra- phen g eine Anordnung, welche mit Vseq(g) bezeichnet wird. Diese Anordnung muss nichts mit der Struktur des Graphen zu tun haben, sie ordnet lediglich jedem Knoten eindeutig eine Stelle innerhalb der Vseq-Liste des Graphen zu.
Eine weitere Anordnung existiert f¨ur Kanten, sie wird Eseq(g) genannt. Auch hier ist die Struktur des Graphen und selbst Vseq irrelevant f¨ur die Anordnung von Eseq.
Des Weiteren existiert eine dritte Anordnung innerhalb von TGraphen, n¨amlich die Folge aller inzidenten Kanten eines jeden Knotens Iseq(v)1. Es existieren dem- nach in jedem Graphen so viele Iseq-Listen, wie es Knoten gibt.
Die formale Definition f¨ur TGraphen ist die folgende [Stef06], S.16:
1In vorangegangener Literatur (z.B. [Laen98], [Stef06]) wird diese Folge auchΛseq genannt. Da dieser Bezeichner jedoch auch in der Implementation vorkommen soll, wird auf Sonderzeichen verzichtet.
1.2. Definitionen und Schreibweisen Definition (TGraph)
Seien
typeID eine endliche Menge von Typbezeichnern, attrID eine endliche Menge von Attributbezeichnern, Value eine endliche Menge von Attributwerten, V eine endliche Menge von Knoten und
E eine endliche Menge von Kanten.
Dann ist
G = (Vseq, Eseq, Iseq, type, value) ein TGraph, falls gilt:
• Vseq∈seq V ist eine Anordnung von V,
• Eseq∈seq E ist eine Anordnung von E,
• Iseq : V→seq(E× {in,out}) ist eine Inzidenzabbildung f¨ur die gilt:
∀e∈E∃! v, w∈V :
(e,out)∈ran Iseq(v)∧(e,in)∈ran Iseq(w),
• type : V∪E→typeID ist eine Typisierung und
• value : V∪E→(attrID 7 7→Value) ist eine Attributierung.
TGraphen ¨ahneln sehr stark Objektgeflechten, welche in der Objektorientierung ver- wendet werden. Allerdings sind TGraphen wesentlich allgemeiner gehalten und besit- zen zus¨atzliche Eigenschaften: Kanten selbst sind vollkommen eigenst¨andige Objekte, zudem wird im Typsystem sowohl Mehrfachvererbung von Knoten als auch von Kan- ten unterst¨utzt. Zus¨atzlich kann die Traversierung auch gegen die Richtung gerichteter Kanten geschehen.
Generell lassen sich durch TGraphen auch wesentlich einfachere Graphen darstellen.
Dies geschieht, in dem man einfach die ¨uberfl¨ussigen Eigenschaften der TGraphen weg l¨asst.
F¨ur die Manipulation und Traversierung von TGraphen sowie ihrer Eigenschaften dient das so genannte GraLab (siehe Abschnitt 1.3) [Eb03].
1.2.2 Beispiel eines TGraphen
Um die Definition der TGraphen zu untermauern, wird die Abbildung 1.1 gezeigt und angelehnt an [EbKu02] beschrieben. Der gezeigte TGraph repr¨asentiert den folgenden
Code auf einer abstrakten syntaktischen Ebene:
1 int main() 2 {
3 int a;
4 int b;
5
6 ...
7
8 a = max(a,b);
9
10 ...
11
12 b = min(b,a);
13
14 ...
15 16 }
Die Methodenmain, max undmin werden von Knoten des Typs Function repr¨asen- tiert. Als Attribut besitzen sie den Namen der Methode. FunctionCall-Knoten stellen den Aufruf derminundmaxFunktionen dar und sind mit dem Aufrufenden mit isCal- ler sowie mit dem Aufgerufenen mittels isCallee-Kanten assoziiert. isCaller-Kanten sind mittels eines line-Attributs attributiert, welches auf die Zeilennummer referenziert.
Eingabeparameter, welche durch Variable-Knoten mit dem Attribut name repr¨asen- tiert werden, sind mit isInput-Kanten verbunden. Die Anordnung der Parameterlisten wird durch die Anordnung der Inzidenzen der auf FunctionCall zeigenden isInput- Kanten gew¨ahrleistet. Die erste Kante vom Typ isInput, welche zu v2 (repr¨asentiert max(a,b)) inzident ist, ist die Kante, welche von Knoten v6 kommt und die Variable adarstellt. Die zweite isInput-Kante verbindet sich mit dem Knoten v7 (welcher f¨ur die Variablebsteht). Die Inzidenzen der mit Knoten v3 assoziierten isInput-Kanten zeigen exakt die umgekehrte Reihenfolge. Die Ausgabeparameter werden mit ihren Methoden- aufrufen schließlich mittels isOutput-Kanten verbunden.
1.2.3 Erkl ¨arung der formalen Definition
An dieser Stelle werden die Begriffe aus der vorangegangenen formalen Definition der TGraphen nat¨urlichsprachlich erkl¨art und weitere Begriffe eingef¨uhrt und erl¨autert.
1.2. Definitionen und Schreibweisen
name = "main"
v1 : Function
v2 : FunctionCall v3 : FunctionCall
line = 8 e1 : isCaller
line = 12 e1 : isCaller
name = "max"
v4 : Function
name = "min"
v5 : Function
e3:isCallee e4:isCallee
name = "a"
v6 : Variable
name = "b"
v7 : Variable e9:isOutput
e5:isInput e8:isInput
e10:isOutput
e6:isInput e7:isInput
{1} {2} {2} {1}
Abbildung 1.1: Beispiel f¨ur einen TGraphen [EbKu02], S.4
Graphen besitzen endliche Mengen V von Knoten und E von Kanten. Eine Kante e∈ E verbindet zwei Knoten v1,v2 ∈ V (eine genauere Definition des Wortes
”verbindet“
wird in den folgenden Abschnitten eingef¨uhrt). Diese Knoten m¨ussen nicht notwendi- gerweise verschieden sein, sie k¨onnen durchaus denselben Knoten bezeichnen. Falls v1
= v2 ist, so nennt man e eine Schlinge.
Diese Mengen von Knoten und Kanten sind innerhalb des sie beinhaltenden Graphen angeordnet. Diese Anordnungen werden Vseq (f¨ur die Knoten) und Eseq (f¨ur die Kan- ten) genannt.
Als inzident zu einem Knoten v ∈ V wird eine Kante e ∈ E bezeichnet, wenn v ein mit der Kante e verbundener Knoten ist. Damit wird ein weiterer Begriff festgelegt: Ein Verbindungspunkt zwischen einem Knoten und einer Kante wird eine Inzidenz genannt.
Jede Inzidenz eines gerichteten Graphen besitzt eine Richtung Dir ={in, out}. Zeich- nerisch wird diese Richtung mittels einer Pfeilspitze an der zugeh¨origen Kante ausge- dr¨uckt. Dabei zeigt der Pfeil genau in in-Richtung.
In diesem Zusammenhang werden hier die beiden Funktionenα,ω: E→V eingef¨uhrt.
Diese beiden Funktionen ordnen einer Kante e∈E jeweils genau zwei Knoten v1,v2∈ V zu. Damit ist eine explizite Unterscheidung zwischen Anfangs- (α(e)) und Endknoten
(ω(e)) m¨oglich. Als alternative Bezeichnung f¨ur Anfangs- und Endknoten ist auch Start- und Zielknoten erlaubt.
Per Definition kann es keine Kanten geben, die nur an einer ihrer beiden Seiten mit einem Knoten verbunden sind. Demzufolge existieren pro Kante immer genau zwei Inzidenzen.
Die Folge der Inzidenzen eines Knotens v ∈V wird mit Iseq(v) bezeichnet. Es lassen sich also alle mit einem Knoten verbundenen Kanten mittels dieser Folge durchlaufen.
Die in der Definition eingef¨uhrte Inzidenzabbildung kann nun folgendermaßen nat¨urlich- sprachlich erkl¨art werden: Wenn eine Kante e zwischen zwei Knoten v1 und v2 besteht, als Anfangsknoten v1 (α(e) = v1) und als Endknoten v2 (ω(e) = v2) besitzt, dann be- sitzt v1 eine Inzidenz (e,out) und v2 eine Inzidenz (e,in). Zeichnerisch befindet sich das
”stumpfe“ Ende des Pfeils an v1 und die Pfeilspitze an v2.
Als Grad δ eines Knotens wird die Anzahl der Inzidenzen, welche mit einem Kno- ten verbunden sind, bezeichnet. Definiert ist der Grad mittels der Gleichung δ(v) =
|Λseq(v)|. Wenn ein Knoten nur eine Schlinge als verbundene Kante hat, besitzt er da- mit einen Grad von 2.
Falls ein Knoten eines Graphen mit keiner Kante verbunden ist, nennt man diesen Kno- ten isoliert.
Sollten zwei Kanten denselben Anfangs- und denselben Endknoten besitzen, werden sie als Mehrfachkanten bezeichnet.
Da es explizit eingehende und ausgehende Kanten gibt, macht eine Differenzierung zwi- schen Innengradδ−und Außengradδ+Sinn. So entspricht der Innengrad eines Knotens der Anzahl an eingehenden Kanten und der Außengrad eines Knotens der Anzahl an ausgehenden Kanten.
Im selben Sinne kann man auch die Folge der inzidenten Kanten eines Knotens nach der Richtung unterscheiden. Demnach istΛseq−(v) die Folge der eingehenden (in) und Λseq+(v) die Folge der ausgehenden (out) Kanten von v. Anzumerken ist, dass bei der FolgeΛseq(v), welche nicht zwischen Innengrad und Außengrad unterscheidet, Schlin- gen zweimal auftreten (n¨amlich einmal in Richtung in und einmal in Richtung out).
Die Abbildung 1.2 zeigt einen gerichteten Beispielgraphen, um die Terminologie zu vertiefen. Der Graph besitzt die Knotenmenge v1, v2, v3 und die Kantenmenge e1, e2, e3. Die Anordnung der InzidenzlistenΛseq(v1)undΛseq(v2)ist in geschweiften Klam- mern in der Abbildung mit angegeben. Der Knoten v3 besitzt keinerlei inzidente Kanten,
1.2. Definitionen und Schreibweisen damit ist er isoliert.
Der Knoten v2 besitzt zwei inzidente Kanten, damit besitzt er den Grad δ(v2) = 2.
Beide Kanten, welche mit v2 verbunden sind, sind eingehende Kanten. Damit l¨asst sich der Grad noch st¨arker differenzieren: Sein Innengradδ−(v2)ist 2 und sein Außengrad δ+(v2)ist 0.
Der Knoten v1 ist mit allen drei Kanten inzident. Die Kante e3 beginnt und endet im Knoten v1, damit wird sie als Schlinge bezeichnet. Da der Grad eines Knotens v ¨uber die Sequenz I seq(v) definiert ist, ist der Gradδ(v1) = 4, da nicht die Schlinge e3 selbst gez¨ahlt wird, sondern ihre Verbindungen (= Inzidenzen) zum Knoten v1. Der Innen- und Außengrad des Knotens v1 l¨asst sich mitδ−(v1) = 1undδ+(v1) = 3angeben.
Da die beiden Kanten e1 und e2 denselben Anfangs- und Endknoten (n¨amlich v1 und v2) besitzen, sind sie Mehrfachkanten.
v1 v2
v3 e1
e2 e3
{1}
{2} {3}
{4}
{1}
{2}
Abbildung 1.2: Beispielgraph zur Erl¨auterung der Terminologie
Orientierung
Das Konzept der Orientierung wird eingef¨uhrt, um z.B. beim Traversieren von Graphen die Kanten unabh¨angig von ihrer Richtung betrachten zu k¨onnen. Formal betrachtet ist eine orientierte Kante~e ein Paar (e,d)∈E×Dir mit Dir ={in,out}. Dir bezeichnet auch hier die Richtung, ob eine Kante bez¨uglich eines Knotens als eingehend oder ausgehend betrachtet wird.
~e = (e, out) wird als normalisierte oder normal orientierte Kante bezeichnet. Norma- lisiert bedeutet in Graphen, dass man die Kante vom Kantenanfang zum Kantenende
(entspricht der symbolischen Kantenspitze) betrachtet. Dies ist die Sichtweise vonα(e) nachω(e).
Die Funktionenα,ω, this und that werden auf die Menge der orientierten Kanten E×Dir folgendermaßen erweitert:
• α(e,out) :=α(e)
• α(e,in) :=α(e)
• ω(e,out) :=ω(e)
• ω(e,in) :=ω(e)
• this(e,out) :=α(e)
• this(e,in) :=ω(e)
• that(e,out) :=ω(e)
• that(e,in) :=α(e)
Im Gegensatz zu α(e) und ω(e) sind die Werte der Funktionen this(e) und that(e) von der Orientierung abh¨angig.
Abbildung 1.3: Orientierung von Kanten [Laen98], S.9 [DaWi03]
Wenn die Richtung der Kanten des Graphen f¨ur die verwendeten Traversierungsalgo- rithmen irrelevant ist, kann man nur die Funktionen this und that benutzen. Damit steht der ungerichtete Graph unmittelbar zur Verf¨ugung. In ungerichteten Graphen braucht man sich daher nicht mehr um Anfangs- und Endknoten zu k¨ummern, obwohl auch diese immer noch abfragbar sind.
1.3. Graphenlabor
1.3 Graphenlabor
Die Verwendung von TGraphen wird mittels einer Klassenbibliothek unterst¨utzt. Diese Unterst¨utzung besteht darin, dem Benutzer bei der Verwaltung eines Typsystems und der Verwendung von TGraphen zu helfen, indem es Graphen als eine interne Daten- struktur ansieht.
Funktionalit ¨at
Um mit TGraphen arbeiten zu k¨onnen, existiert eine Klassenbibliothek namens Gra- phenlabor oder kurz GraLab [Eb03]. Diese kann ein Typsystem erstellen, welches f¨ur die Typisierung von Graphen, Kanten und Knoten dient. Dieses Typsystem kann gespei- chert und auch wieder geladen werden.
Diese Typen definieren Attribute. Ein Typ im Typsystem kann eine gewisse Anzahl von Attributen besitzen. Wie in Abschnitt 1.2.1 beschrieben, zeichnen sich diese Attribute durch einen Namen und einen Wertebereich aus. In der formalen TGraphen-Definition ist jedoch nicht modelliert, dass der Typ die Attribute eindeutig bestimmt, dies trifft auf GraLab allerdings explizit zu.
Um Attribute nicht mehrmals definieren zu m¨ussen, wenn man sie in mehreren Typen unterbringen m¨ochte, lassen sich diese Attribute durch Mehrfachvererbung der entspre- chenden Typen replizieren.
Der Wertebereich eines Attributs kann aus einer Reihe von definierten Wertebereichen ausgew¨ahlt werden. GraLab unterst¨utzt die Basiswertebereiche Integer, Float, Boolean und String, sowie die komplexen Wertebereiche Liste, Tupel und Verbund (Record) [Laen98], S.10.
Bei der Erstellung von Graphelementen, also Knoten und Kanten, wird diesen jeweils genau ein Typ zugewiesen. Damit besitzen sie alle Attribute ihres Typs. Der Anwender kann die Attribute der konkreten Graphelemente anschließend mit Werten f¨ullen. Damit sind diese Graphen schließlich typisiert und attributiert.
GraLab bietet zwei verschiedene Arten von Attributen an:
• Persistente Attribute: Wenn Informationen dauerhaft an Graphen, Kanten und Knoten gespeichert werden m¨ussen, bietet es sich an, persistente Attribute zu erstellen. Diese Attribute k¨onnen bei einer Speicherung des Graphen auf einem Datentr¨ager festgehalten werden. Ein anschließender Ladevorgang l¨adt diese At-
tribute wieder in den Speicher und ordnet sie wieder den Graphelementen zu, zu denen sie geh¨oren.
• Tempor¨are Attribute: Manchmal kann es sinnvoll sein, Attribute nur tempor¨ar an Graphen, Kanten und Knoten zu speichern, da diese nicht persistent gemacht werden m¨ussen. Sinnvoll ist dies z.B. bei einem Graphenalgorithmus, welcher sich seine soeben besuchten Knoten merken muss. Dazu stattet er sie mit ei- nem booleschen Flag aus, welches durch ein tempor¨ares Attribut realisiert werden kann.
Wie bereits implizit bei den persistenten Attributen erw¨ahnt, lassen sich TGraphen spei- chern und anschließend wieder laden. Zu diesem Zweck (und zur Speicherung des Typsystems) existiert ein eigenes Dateiformat .G, welches in Kapitel 4.3 ausf¨uhrlich aufgeschl¨usselt wird.
Mit GraLab k¨onnen diese TGraphen erstellt, abgefragt, manipuliert und traversiert wer- den. Dar¨uber hinaus sind jegliche Transformationen von TGraphen durchf¨uhrbar.
Existierende Versionen
Es existieren bisher zwei Versionen von GraLab - eine Variante in C++ [Eb03] (fr¨uher C) und eine Variante in Java. Die C++ Version zeichnet sich insbesondere durch eine sehr hohe Geschwindigkeit aus. Im Rahmen einer Diplomarbeit wurde das C++ GraLab bereits in eine Java-Version ¨ubersetzt [Laen98] und im Laufe der Jahre weiterentwickelt.
Beide Versionen sind im Sinne der Funktionalit¨at sehr ¨ahnlich, im Java-GraLab wurden kaum neue Funktionen hinzugef¨ugt. Somit bildet die Java-Version von GraLab ledig- lich eine ¨Ubersetzung der C++ Version, welche ihrerseits kaum objektorientierte Funk- tionalit¨at besitzt. Die wesentlichen Vorteile der Objektorientierung konnten aus diesem Grunde nicht in diese ¨Ubersetzung mit einfließen.
1.4 ¨ Uberblick ¨ uber diese Diplomarbeit
Diese Diplomarbeit hat zum Ziel, im Sinne einer Neuentwicklung von JGraLab eine ganze Reihe von Verbesserungsm¨oglichkeiten einzuf¨uhren. Diese werden in den n¨achs- ten Abschnitten beschrieben.
1.4. ¨Uberblick ¨uber diese Diplomarbeit
1.4.1 Anlehnung an bestehende Metamodelle
In den bisherigen Implementationen von GraLab existiert ein explizites Typsystem. Die- ses Typsystem besitzt einige Einschr¨ankungen, welche haupts¨achlich auf seinen nicht objektorientierten Charakter zur¨uckzuf¨uhren sind.
Um die Beschreibung des neuen Typsystems weiter zu formalisieren, den Sprachge- brauch klarer zu definieren und aktuelle Entwicklungen in der Softwaretechnik in das Projekt mit einfließen zu lassen, wird ein Metamodell (= ein Modell, welches Mo- delle beschreibt) f¨ur JGraLab eingef¨uhrt. Das zu entwickelnde Klassendiagramm f¨ur JGraLab wird an dieses Metamodell angelehnt. Dies erlaubt zus¨atzlich eine vereinfach- te Interoperabilit¨at verschiedenster Modelle.
Durch die Verwendung eines Metamodells kann die gesamte JGraLab-Architektur zu- s¨atzlich in mehrere Meta-Ebenen eingeteilt werden (siehe Kapitel 3.2.1), um z.B. Selbst- beschreibung zu f¨ordern.
Es existieren eine Reihe von Metamodellen, welche sich f¨ur diesen Vergleich eignen.
Diese werden in Kapitel 3.2.1 beschrieben, analysiert und bez¨uglich ihrer Eignung f¨ur JGraLab bewertet.
1.4.2 Typisierung - Typsystem vs. Schema
Das Typsystem des alten GraLab bestimmt lediglich die Attribute, die ein Graphele- ment eines bestimmten Typs tragen darf. Jedes Graphelement bekommt genau einen Typ zugewiesen.
Zus¨atzlich existiert eine Vererbungshierarchie der Typen untereinander, damit k¨onnen Attribute aus den Oberklassen geerbt werden. Auch die Verwendung von Mehrfachver- erbung stellt keine Probleme dar.
Das bisherige so genannte Typsystem wird neu konzipiert und Schema genannt. Zus¨atz- lich werden Typen nun Klassen genannt.
Ein Schema bietet eine h¨ohere Funktionalit¨at als ein Typsystem, da es z.B. explizite Graphklassen, Knotenklassen und Kantenklassen einf¨uhren kann: Damit kann es Ein- schr¨ankungen in der Vererbungshierarchie definieren, z.B. dass eine Kantenklasse nur Attribute einer anderen Kantenklasse erben darf. Durch diese Vererbung wird auch die einfache Benutzung abstrakter Klassen erm¨oglicht. Es kann durch die Verwendung von Multiplizit¨aten Einschr¨ankungen des Verbindens von Knoten und Kanten einf¨uhren, auch Rollennamen bei mehreren Kanten zwischen Knoten sind denkbar. Weitere Cons-
traints sind durch Kompositionen m¨oglich.
Ein Schema bietet zus¨atzlich auch eine andere Sichtweise auf die Graphen: Graphen, Kanten und Knoten k¨onnen nun als Instanzen ihrer Graphen-, Kanten- und Knotenklas- sen angesehen werden.
Generell wird mit einem Schema das Graphenlabor n¨aher an aktuelle Entwicklungen aus der Objektorientierung herangef¨uhrt. Um diesen Gedanken weiterzuf¨uhren, wird die Erstellung einer objektorientierten Zugriffsschicht besprochen.
Die Erstellung des JGraLab-Schemas wird in Kapitel 3.4 behandelt.
1.4.3 Performanztests
Die alten Versionen von GraLab (in C und C++) besitzen eine sehr hohe Ausf¨uhrungs- geschwindigkeit bei gleichzeitig niedrigem Speicherplatzverbrauch.
Da das neue JGraLab aufgrund der Einf¨uhrung des funktional komplexeren Schemas, der verschiedenen Metaebenen und nicht zuletzt der Verwendung der Sprache Java einen deutlich h¨oheren Verwaltungsaufwand besitzt, sollen mehrere Implementationsm¨oglich- keiten getestet werden, um eine ausreichend schnelle Verarbeitungsgeschwindigkeit zu gew¨ahrleisten.
Zu diesem Zweck werden Tests mit zuf¨allig erstellten Graphen mit mehreren Millionen Graphelementen durchgef¨uhrt. Diese Tests werden sowohl auf Rechengeschwindigkeit gemessen als auch bez¨uglich ihres Speicherplatzverbrauchs ausgewertet.
Die Beschreibung der Implementationsm¨oglichkeiten und die Durchf¨uhrung der Tests ist in Kapitel 4.1 zu finden.
1.4.4 Objektorientierte Zugriffsschicht
Die bisherigen Versionen von GraLab bieten durch eigene Methoden die Funktionalit¨at an, auf Attribute und auf Graphelemente zugreifen zu k¨onnen. Man muss also immer die von GraLab bereitgestellten Methoden verwenden, um z.B. an den Inhalt eines Attributs zu gelangen.
Dieser Zugriff auf die Attribute im GraLab ist etwas umst¨andlich, da es keine konkre- ten Methoden der Form getX():Wert oder setX(Wert) (X = Attributname) gibt. Man be- kommt nur ¨uber extra Attribut-Objekte Zugriff auf die Werte der Attribute selbst, indem
1.4. ¨Uberblick ¨uber diese Diplomarbeit man diese Attributobjekte als Parameter in speziellen Abfrage-Methoden angibt.
Zus¨atzlich besitzt ein Graph im alten GraLab immer nur Kanten oder Knoten, die je- weils einen Typ haben (welcher ihre Attribute definiert). Es w¨are hilfreich, wenn die- se Kanten oder Knoten direkt Instanzen ihres Typs w¨aren. Das bedeutet, dass es z.B.
konkrete A-Objekte geben w¨urde, anstatt dass es ein Graphelement gibt, welches eine Referenz auf den Typ namens A besitzt.
In der Objektorientierung findet der Zugriff auf Java-Attribute echter Java-Objekte nor- malerweise durch Getter und Setter statt (auch ein Zugriff direkt auf Attribute ist m¨og- lich, aber durch Kapselung mittels desprivate-Schl¨usselworts nicht erw¨unscht). Hier ist keine zus¨atzliche Verwendung von weiteren Methoden n¨otig.
Nach diesem Gesichtspunkt soll nun auch der Zugriff auf JGraLab-Objekte und -Attri- bute m¨oglich werden. Attribute von Knoten, Kanten und Graphen sollen wie echte Java- Attribute behandelt werden k¨onnen, d.h. der Zugriff soll ¨uber Getter und Setter gesche- hen.
Zus¨atzlich soll es m¨oglich sein, direkt konkrete GraLab-Objekte ¨uber die Angabe ihrer Klasse instanziieren zu k¨onnen (und damit auf die Benutzung einer GraLab-Methode mit expliziter Angabe eines Typs zu verzichten). Man m¨ochte also nur noch mit Instan- zen von Klassen hantieren.
Weiter gedacht soll dieser direkte Zugriff auf Instanzen der Graphen-, Knoten- und Kantenklassen auch auf die Navigation innerhalb der Graphenlisten ¨ubertragbar sein, also auf die globale Kantenliste Vseq(g), die globale Knotenliste Eseq(g) und die kno- tenabh¨angigen Inzidenzlisten Iseq(v). Bisher konnten diese Listen lediglich durch optio- nale Angabe eines Typs eingeschr¨ankt werden. Dieser Zugriff soll nun ohne Parameter direkt ¨uber den Namen der konkreten Klasse geschehen. Die Typisierung soll damit in den Namen gezogen werden.
Nicht nur die Navigation innerhalb der Graphenlisten soll ¨uber Methodennamen ge- schehen k¨onnen, auch bereits die Erstellung von konkreten Graphen, Kanten und Kno- ten kann mittels so genannter Fabrik-Methoden geschehen. Dazu bietet z.B. ein Graph Methoden an, um seine Kanten und Knoten zu erstellen. Bisher wurde die Erstellung dieser Objekte nur durch Aufruf ihrer Konstruktoren erm¨oglicht.
Eine genauere Motivation und die erweiterte Beschreibung der objektorientierten Zu- griffsschicht wird in Kapitel 4.2 behandelt. Weitere Vereinfachungen des Zugriffs wer- den in Kapitel 4.2.4 bei den Fabrik-Methoden besprochen.
1.4.5 Eingabe/Ausgabe
Das bisherige GraLab besitzt ein eigenes Dateiformat mit der Dateiendung .G. Dieses Format ist menschenlesbar und unterst¨utzt das sehr schnelle Einlesen und Abspeichern von Typsystem und Graphen.
Um Graphen und ihr Schema ablegen zu k¨onnen, wird ein neues Dateiformat notwen- dig, da das neue JGraLab einige Funktionalit¨at anbietet, die nicht mittels .G persistent gemacht werden kann. Zu diesem Zweck werden in Kapitel 4.3 bestehende Dateiforma- te beschrieben und analysiert. Es werden Beispiele gegeben, um zu ¨uberpr¨ufen, welche Eigenschaften dieser Dateiformate sich in das neue Format ¨ubernehmen lassen.
In diesem Rahmen wird auch der verwendete Parser beschrieben, zus¨atzlich werden Besonderheiten bei der Speicherung z.B. von Attributwerten erl¨autert.
Die Optimierung der Geschwindigkeit des Lade- und Speichervorgangs ist in diesem Kapitel (4.3) ein weiteres Thema, da durch die objektorientierte Zugriffsschicht ein großer Overhead an Rechenzeit notwendig wird.
1.4.6 Beispiel
In Kapitel 5 wird ein Beispiel zur Verwendung von JGraLab aufgezeigt. Dieses dient vor allem zur Vertiefung der im Kapitel 4 beschriebenen Implementierung.
Des Weiteren werden in diesem Kapitel zu beachtende Rahmenbedingungen bei der Verwendung von JGraLab sowie M¨oglichkeiten der Traversierung von Graphen erl¨autert.
2 Anforderungen
In diesem Kapitel werden die Anforderungen f¨ur das neue JGraLab konkretisiert. Es wird eine idealisierte Anforderungsliste erstellt, um die Wunschvorstellungen festzu- halten.
2.1 Anforderungsliste
In der folgenden Anforderungsliste wird die gew¨unschte Funktionalit¨at des neuen JGra- Lab beschrieben. Sie stellt eine idealisierte Vision dar, welche vor dem eigentlichen Entwurf aufgestellt wurde.
2.1.1 Schema
1.1 Knoten und Kanten sollen typisiert werden k¨onnen.
1.2 Nachdem das Schema definiert wurde, soll es, soweit sinnvoll, weiterhin ver¨ander- bar sein (das bisherige
”Exportieren“ von Typen f¨allt damit weg).
1.3 Subtyp-Relationen sollen m¨oglich sein.
1.4 Mehrfachvererbung soll unterst¨utzt werden, sofern keine Konflikte (gleiche Na- men der Attribute, etc.) existieren.
1.5 Das neue Typsystem soll mehr Schema-Charakter besitzen, d.h. es soll festgelegt werden k¨onnen, ob der definierte Typ ein Kantentyp oder Knotentyp ist und mit welchen Kanten sich ein Knoten wie oft verbinden darf.
1.6 Eine Komposition (existenzabh¨angige Knoten/Kanten) soll m¨oglich sein, so dass bei Bedarf z.B. kaskadierendes L¨oschen m¨oglich wird.
1.7 Ein minimales Schema soll existieren, dies soll nur jeweils einen attributlosen Graphen-, Knoten- und Kantentyp beinhalten.
1.8 Das minimale Schema soll die Basis f¨ur jedes selbstdefinierte Schema bilden.
2.1.2 Graphen
2.1 Kanten und Knoten sollen unabh¨angig und eindeutig identifizierbar sein.
2.2 Mehrfachkanten sollen m¨oglich sein.
2.3 Kanten sollen gerichtet sein.
2.4 Zu einem gerichteten Graphen soll der ungerichtete Graph unmittelbar zur Verf¨u- gung stehen.
2.5 Ein Graph soll dynamisch ver¨andert k¨onnen (Einf¨ugen, L¨oschen von Knoten und Kanten w¨ahrend der Laufzeit).
2.6 Alle Kanten und Knoten sollen eine sichtbare Reihenfolge besitzen, welche ver¨an- dert werden kann.
2.7 Methoden zur Traversierung aller Knoten und Kanten sowie aller Kanten eines Knotens sollen verf¨ugbar sein, dabei soll die Traversierung auch vom Typ ab- h¨angig gemacht werden k¨onnen.
2.1.3 Attributierung
3.1 Knoten und Kanten sollen attributiert werden k¨onnen.
3.2 Knoten und Kanten sollen typunabh¨angig tempor¨ar attributiert werden k¨onnen.
Tempor¨are Attribute werden nicht persistent gespeichert.
3.3 F¨ur die tempor¨aren Attribute soll ein Schichtsystem existieren, welches threadsafe sein soll.
3.4 Die Wertebereiche der Attribute sollen definiert werden k¨onnen. Hierbei sollen die typischen Dom¨anen Int, Double, Boolean, String, List, Record, Tuple und Enum unterst¨utzt werden. Des Weiteren soll die M¨oglichkeit existieren, Java Ob- jects zuzulassen. Diese sollen zudem persistent gemacht werden k¨onnen.
2.1. Anforderungsliste
2.1.4 Objektorientierte Zugriffsschicht
4.1 Aus dem Schema sollen Java-Klassen erzeugt werden, die eine Verwendung des Graphen, bzw. der Knoten und Kanten als Javaobjekte erlaubt.
4.2 Die Klassenbezeichner sollen den Typen im Schema entsprechen.
4.3 Die Attribute der Kanten und Knoten sollen als Java-Attribute ¨uber Getter und Setter verf¨ugbar werden.
4.4 Der Code soll aus dem Schema automatisch generiert werden k¨onnen.
4.5 Die Ausf¨uhrung der OO-Access-Schicht soll optional sein und sich ausschließlich der Methoden der Schema/Graphen-Schicht bedienen.
2.1.5 ¨ Ubergreifende Eigenschaften der Klassenbibliothek
5.1 Ein zuschaltbarer Undo-Mechanismus soll vorhanden sein und die Definition von Marken (f¨ur Rollbacks bis zu einem vorher definierten Punkt) unterst¨utzen.
5.2 Ein Transaktionskonzept soll entweder vorhanden oder vorbereitet sein.
5.3 Die Java-API soll threadsafe implementiert werden, so dass Mehrprozessorbetrieb unterst¨utzt wird. Einzelne Operationen (wie z.B. update, create) sollen atomar ausf¨uhrbar sein. Die Thread-Sicherheit soll aus Performanzgr¨unden abschaltbar sein.
5.4 Zuschaltbares Checking (dynamische Typ¨uberpr¨ufung w¨ahrend der Laufzeit) soll existieren.
5.5 Zuschaltbares Tracing (Logging aller wichtigen Operationen f¨ur Debug-Zwecke) soll existieren.
5.6 Das Endprodukt soll als JAR-Datei zur Verf¨ugung stehen.
2.1.6 Eingabe/Ausgabe
6.1 Graph-Dateien (.G) sollen vom Programm gelesen und geschrieben werden k¨onnen.
6.2 Optional: Import und Export sowohl der TGraphen als auch des Schemas soll mittels GXL m¨oglich sein. Alternative: Der bisherige Konverter von .G auf GXL soll genutzt werden.
6.3 Optional: Die Definition des Typsystems und der Graphen soll mittels EMF m¨og- lich sein.
6.4 Es soll ein eigenes Dateiformat hinzu kommen, welches alle Java-Objekte seria- lisiert speichern und laden kann.
6.5 Unicode (UTF-16) soll intern unterst¨utzt werden. F¨ur die Speicherung soll UTF-8 ausreichen.
2.1.7 Performanz
7.1 Es sollen zwei Programmversionen bez¨uglich ihres Laufzeitverhaltens gemessen werden und sich bei der endg¨ultigen Implementation f¨ur die schnellere der fol- genden entschieden werden:
7.1.1 Kanten und Knoten werden durch Java-Objekte dargestellt.
7.1.2 Kanten- und Knoten-Objekte entstehen nur tempor¨ar f¨ur den Zugriff, intern werden sie als Inzidenztabelle repr¨asentiert.
7.2 Das Java-GraLab, insbesondere die Ein- und Ausgabe, soll nicht mehr als zehn mal langsamer sein als das C++-GraLab.
7.3 Mehrere Millionen Kanten und Knoten sollen auf einem heutigen Durchschnitts- rechner im Speicher gehalten werden k¨onnen.
2.1.8 Dokumentation
8.1 In der Dokumentation sollen gef¨allte Entscheidungen dokumentiert werden.
8.2 Der Quellcode soll mit Javadoc-Kommentaren in englischer Sprache versehen werden.
8.3 UML-Diagramme sind in die Dokumentation zu ¨ubernehmen.
Im Verlauf dieser Arbeit wird versucht, m¨oglichst alle Punkte zu erf¨ullen. Dennoch ist diese Liste eindeutig als Vision anzusehen, da einige Punkte erst im Entwurf oder auch erst in der Realisierung genauer durchdacht werden k¨onnen.
Im Abschnitt 6.1 wird beschrieben, welche dieser Anforderungen erf¨ullt werden konn- ten und welche ge¨andert werden mussten.
3 Entwurf
Dieses Kapitel beschreibt den Entwurf von JGraLab. Im ersten Teil dieses Kapitels wird der Sinn eines Metaebenen-gest¨utzten Entwurfs beschrieben. Anschließend findet eine Analyse von bestehenden Metamodellen statt, um eine erste Basis f¨ur den Entwurf eines Ubersichtsklassendiagramms zu schaffen. Nach einer Begriffskl¨arung wird im dritten¨ Teil das ¨Ubersichtsklassendiagramm im Sinne der UML 2.0 entwickelt. Abschließend wird dieses noch grobgranulare Klassendiagramm aufgeteilt, die Teildiagramme weiter verfeinert, einzeln beschrieben und mit Methoden versehen.
3.1 Motivation
Wie in Abschnitt 1.4.2 bereits eingef¨uhrt, wird in diesem Entwurfs-Kapitel eine M¨oglich- keit gesucht, das alte GraLab-Typsystem mit mehr Schema-Charakter auszustatten. Zu diesem Zweck bietet es sich an, aktuelle Entwicklungen der Softwaretechnik zu beach- ten.
Eine dieser Entwicklungen ist die Verwendung von Metamodellen f¨ur den Entwurf.
Ein Metamodell ist eine Beschreibung, wie ein Modell konstruiert werden darf. Man verwendet Metamodelle, um genau festzulegen, welche Elemente ein Modell beinhalten kann. Durch diese Eigenschaft wird die Sprachdom¨ane genauer definiert.
Diese Metamodelle sind in der Lage, durch ihre Instanziierung prinzipiell Modelle zu erzeugen. In einigen F¨allen ist es jedoch sinnvoll, gleich mehrere Metaebenen zu defi- nieren. Damit k¨onnten also nicht nur Modelle von Modellen (=Metamodelle) existieren, sondern auch Modelle von Modellen von Modellen (=Metametamodelle) und so fort.
Solche Modelle ben¨otigen eine klare Identifizierung innerhalb dieser Ebenen, da hier Verwirrung bereits vorprogrammiert ist. Aufgrund dieser Tatsache bekommen die Ebe- nen den Bezeichner M, gefolgt von einer Zahl. Pro Meta-Ebene erh¨oht sich diese Zahl um 1.
M0 hat hierbei eine Sonderstellung: Sie bezeichnet Objekte der realen oder fiktiven
Welt, welche mittels der M1-Elemente ausgedr¨uckt werden.
Elemente der Ebene M1 stehen im allgemeinen f¨ur Instanzen von M2-Modellen. Ein Beispiel f¨ur M1-Elemente w¨aren z.B. Instanzen von einfachen UML-Klassen.
In der Ebene M2 findet sich das Modell f¨ur die M1-Instanzen wieder. Dies w¨aren z.B.
Klassendiagramme der UML.
Die Ebene M3 beschreibt damit das Modell der M2-Elemente oder das Metamodell der M1-Instanzen, bzw. das Metametamodell der M0-Objekte.
Es ist noch eine weitere Ebene M4 (und so fort...) denkbar, welche das M3-Modell beschreiben k¨onnte. Dies ist allerdings in den wenigsten F¨allen notwendig, da es das nat¨urliche Verst¨andnis nicht unbedingt verbessert, sondern eher verkompliziert. Daher wird die Ebene M3 meist selbstbeschreibend ausgelegt, damit keine M4 Ebene mehr notwendig wird.
Diese Ebenenstruktur soll nun f¨ur JGraLab eingef¨uhrt werden. Zu diesem Zweck wer- den aktuelle Entwicklungen aus der Softwaretechnik beschrieben und analysiert, welche Metamodelle verwenden.
3.2 Vergleich der Metamodelle von GXL, MOF und ecore
In diesem Abschnitt werden die Metamodelle von GXL, MOF und ecore aufgelistet, beschrieben, Beispiele gegeben und analysiert, um Erkenntnisse f¨ur den Entwurf zu sammeln. Die Modelle (Abb. 3.2, 3.3, 3.4) sind auf das Wesentliche reduziert worden.
3.2.1 Einf ¨ uhrung der Metamodelle
Ahnlich wie im letzten Abschnitt generalisiert beschrieben, werden an dieser Stelle die¨ Ebenen definiert, welche speziell f¨ur JGraLab ben¨otigt werden.
• M3, Meta-Schema: Die M3-Ebene beschreibt, welche Elemente ein Graphen- schema beinhalten darf. Sie legt fest, was z.B. eine Graphenklasse oder was eine Knotenklasse ¨uberhaupt ist. Diese Ebene soll selbstbeschreibend sein. Damit ist keine M4-Ebene mehr notwendig.
3.2. Vergleich der Metamodelle von GXL, MOF und ecore
Abbildung 3.1: Die Ebenen von JGraLab
• M2, Schema: Instanzen von M3-Modellen bilden die M2-Ebene, das konkre- te Graphenschema selbst. Sie legen fest, welche Elemente ein Graph besitzen darf. Dies geschieht in Form von Graphen-, Knoten- und Kantenklassen. Die M2- Ebene kann mittels zweier Notationen beschrieben werden. Erstens als Instanz der M3-Ebene in Form eines Objektdiagramms und zweitens als UML-Diagramm, um als Schema f¨ur die M1-Ebene zu dienen.
• M1, Graphen: Werden M2-Schemata instanziiert, kommt man zu den Graphen selbst. Sie bestehen aus Knoten und Kanten, welche eine Instanz aus ihrer jewei- ligen Knoten- oder Kantenklasse bilden.
In den folgenden Abschnitten werden die Metamodelle der Abbildungen 3.2, 3.3 und 3.4 zun¨achst einmal beschrieben. Sie entsprechen der soeben definierten Ebene M3.
GXL
GXL1 ist ein XML-basiertes Austauschformat, um Graphen und ihr Schema zu spei- chern. Speziell wird es im Reengineering-Bereich eingesetzt, um die Interoperabilit¨at zwischen verschiedenen Tools zu gew¨ahrleisten. Es kann mehr als nur TGraphen dar- stellen, auch hierarchische Graphen und Hypergraphen sind m¨oglich. Dabei k¨onnen so- wohl die Graphen als auch das dazugeh¨orige Schema innerhalb eines einzigen Formats ausgetauscht werden [HoSc02-1].
In Abbildung 3.2 ist das Wichtigste des GXL Metamodells dargestellt. Auf Hypergra- phen und auf hierarchische Graphen wird verzichtet. Das gezeigte Subset von GXL kann TGraphen-Schemata darstellen.
1GXL: Graph eXchange Language
-name : string GraphClass
-name : string -isAbstract : bool
GraphElementClass {abstract}
-name : string AttributeClass
NodeClass
-isDirected : bool EdgeClass
1 *
contains
*
* isA
* *
hasAttribute
-limits : int x int -isOrdered : bool
from
* 1
-limits : int x int -isOrdered : bool
to
* 1
-aggregate : (from, to) AggregationClass CompositionClass
AttributedElementClass {abstract}
Domain {abstract}
*
0..1 hasDomain
Abbildung 3.2: Metamodell GXL
3.2. Vergleich der Metamodelle von GXL, MOF und ecore Das Hauptelement des GXL Metamodells bildet die abstrakte Klasse AttributedEle- mentClass. Sie aggregiert eine Reihe von AttributeClasses, welche jeweils unterschied- liche Attribute darstellen k¨onnen. Aus der AttributedElementClass l¨asst sich die Klasse GraphClass spezialisieren, welche einen Graphtyp darstellt. Diese Klasse kann wieder- um abstrakte Klassen vom Typ GraphElementClasses enthalten, welche ihrerseits eine weitere Spezialisierung der AttributedElementClass bildet.
Durch die isA-Assoziation der GraphElementClass k¨onnen Graphelementklassen (n¨am- lich EdgeClasses und NodeClasses) untereinander eine Hierarchie bilden. Hierbei k¨on- nen sowohl EdgeClasses als auch NodeClasses untereinander ihre Eigenschaften verer- ben.
Die Verbindung zwischen Edge- und NodeClasses ¨ubernehmen zwei Assoziationsklas- sen (from und to), welche jeweils die Kardinalit¨aten enthalten.
Es ist im GXL-Metamodell nicht festgeschrieben, dass Kanten nur mit Knoten verbun- den werden k¨onnen, sie lassen sich beliebig verketten. Allerdings unterbindet der so genannte GXL-Validator dies, jedoch ist diese Einschr¨ankung nicht so im Metamodell untergebracht [Kacz03].
Als Spezialf¨alle der EdgeClass existieren die AggregationClass und ferner die Compo- sitionClass, welche eine Aggregation bzw. eine Komposition darstellen.
In diesem Auszug des GXL-Metamodells wurde aus ¨Ubersichtsgr¨unden die Definiti- on der Wertebereiche weggelassen. Folgende Dom¨anen werden von GXL unterst¨utzt (hierbei wurde sich an OCL orientiert) [HoSc02-2]:
• Atomare Wertebereiche: Int, Float, Bool, String
• Aufz¨ahlungswertebereich: Enum
• Zusammengesetzte Wertebereiche: Bag, Set, Seq, Tup
MOF
MOF2 wurde entwickelt, um nachtr¨aglich eine Metaebene f¨ur UML zu repr¨asentieren.
Wie GXL ist sie selbstbeschreibend, d.h. sie kann sich durch ihr Metamodell selbst instanziieren. Die Spezifikation MOF 1.4 ist die derzeit g¨ultige Variante, Version 2.0
2MOF: Meta Object Facility
-multiplicity : int x int StructuralFeature
{abstract}
-isAbstract : bool GeneralizableElement
{abstract}
Attribute Reference
-multiplicity : int x int AssociationEnd
Class DataType
1
*
isOfType
*refersTo 1
* 1
exposes Association
* Generalizes*
-name : string ModelElement
{abstract}
NameSpace {abstract}
TypedElement {abstract}
Classifier {abstract}
contains
Abbildung 3.3: Metamodell MOF
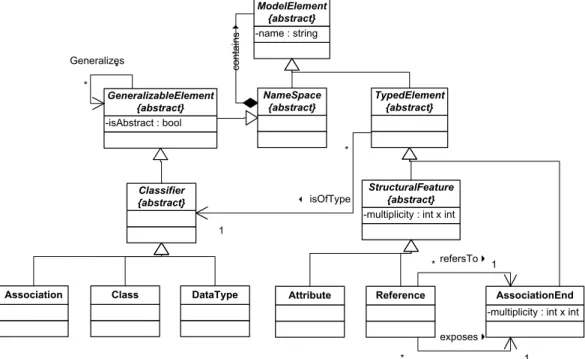
3.2. Vergleich der Metamodelle von GXL, MOF und ecore steht zur Zeit noch in der Abnahmephase [OMG05]. MOF 1.4 wird in den n¨achsten Zeilen beschrieben.
Die Darstellung von MOF wurde in diesem Modell (Abb. 3.3) stark reduziert. Dennoch bietet MOF auch hier mehr Freiheiten an, als gew¨unscht.
Kernelement des Metamodells bildet die Klasse ModelElement, welche sich in Na- mespace und TypedElement spezialisieren l¨asst. Ein Namespace kann zwar mehrere ModelElements aggregieren, jedoch kann es aufgrund des abstrakten Charakters keine Graphen-Klasse repr¨asentieren.
Die ¨uber Namespace spezialisierte Klasse GeneralizableElement bietet durch die Gene- ralizes-Assoziation auf sich selbst die Vererbungshierarchie an, welche auf ihre Spezia- lisierungen Classifier und anschließend Association, Class und DataType wirkt.
Eine Class kann einem Knotentyp entsprechen, eine Association zu einem Teil einem Kantentyp (es werden f¨ur einen Kantentyp weitere Elemente ben¨otigt), sowie ein Da- taType den herk¨ommlichen Datentypen f¨ur Attribute, sowohl primitive als auch zusam- mengesetzte.
Auf der anderen Seite l¨asst sich ein TypedElement in AssociationEnd sowie in die ab- strakte Klasse StructuralFeature spezialisieren, welche ihrerseits die Klassen Attribute und Reference generalisiert.
Um eine Assoziation zwischen Class-Objekten zu beschreiben, werden 3 Elemente des Metamodells ben¨otigt: Als erstes bildet die Association in einfacher Ausf¨uhrung den Kernkantentyp, welcher Klassen vom Typ Attribute enthalten kann (dies geschieht
¨uber die Komposition der abstrakten Klasse Namespace). Die beiden Verbindungs- punkte zwischen Kanten- und Knotentypen werden mittels der zweiten Klasse Asso- ciationEnd repr¨asentiert. Diese Punkte k¨onnen Inzidenzen in Graphen entsprechen. Die Class-Klasse enth¨alt zur Navigation zwei sogenannte References, welche jeweils auf das anliegende (exposes) und auf das entfernte (refersTo) AssociationEnd zeigen. Eine Association beinhaltet schließlich zwei AssociationEnds [GeRa03], [OMG02].
Die folgenden Datentypen existieren in MOF:
• Primitive Type fasst die primitiven Datentypen Boolean, Integer, Long, Float, Double und String zusammen.
• Structured Type bildet ein Tupel.
• Enumeration Type repr¨asentiert den Aufz¨ahlungswertebereich.
• Alias Type weist einem Datentypen einen weiteren Namen zu.
• Collection Type kann beliebig viele Objekte eines bestimmten Basisdatentyps aufnehmen.
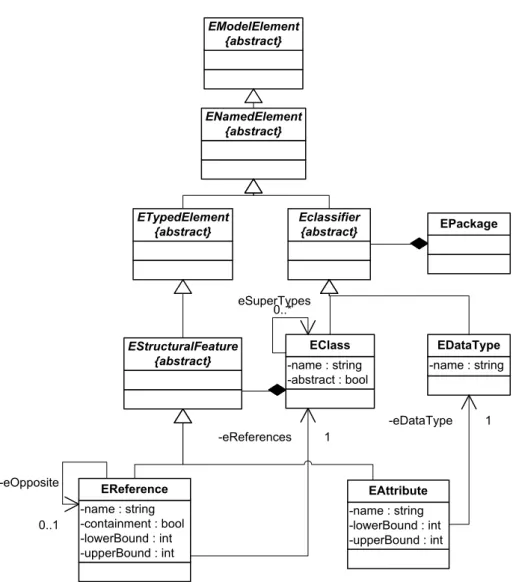
ecore
Ecore (Abb. 3.4) ist das M3-Modell des EMF3. Es basierte urspr¨unglich auf dem MOF Modell 1.4 und wurde sp¨ater an OMGs EMOF 2.04angeglichen. Es dient dazu, Modelle in EMF zu beschreiben.
Im Vergleich zum vorherigen Abschnitt sieht man, dass ecore sehr an MOF angelehnt ist. Auch hier bildet das EModelElement den Kern des Modells. Zudem korrespondieren die Spezialisierungen von ENamedElement, n¨amlich ETypedElement, EClassifier und ferner EStructuralFeature mit MOF.
Die Klasse EClass kann einen Knotentyp darstellen, welcher durch die Vererbung der Komposition zu EStructuralFeature Attribute (Klasse EAttribute) besitzt und selbst eine Vererbungshierarchie unterst¨utzt. Die Klasse EDataType beschreibt den Wertebereich des Attributs.
Kantentypen k¨onnen durch EReferences repr¨asentiert werden, es existieren hiervon bei ungerichteten Graphen zwei Exemplare, mit denen jeweils andere Richtungen beschrie- ben werden. Durch eOpposite wird jeweils auf die andere EReference referenziert. Her- vorzuheben ist, dass nur EClasses Attribute besitzen k¨onnen, EReferences k¨onnen es nicht. Damit k¨onnen Assoziationen nicht direkt beschrieben werden [BaGra05].
Alternativ k¨onnte eine Kantenklasse als EClass modelliert werden, damit wird die Ver- wendung von Attributen an Kantenklassen wieder erm¨oglicht.
Folgende Datentypen werden von ecore unterst¨utzt [IBM04]:
• Einfache Datentypen: EBoolean, EByte, EChar, EDouble, EFloat, EInt, ELong, EShort, EString, EByteArray
3EMF = Eclipse Modelling Framework
4EMOF = Essential MOF, die zur Zeit in der Abnahmephase befindliche Teilmenge einer Nachfolge- version von MOF 1.4, gleicht ecore bis auf Namensunterschiede sowie der dort nicht vorhandenen Unterscheidung zwischen Referenzen und Attributen.
3.2. Vergleich der Metamodelle von GXL, MOF und ecore
-name : string -abstract : bool
EClass
-name : string EDataType
-name : string -lowerBound : int -upperBound : int
EAttribute -name : string
-containment : bool -lowerBound : int -upperBound : int EReference
eSuperTypes0..*
-eDataType 1 -eReferences 1
-eOpposite
0..1
EModelElement {abstract}
ENamedElement {abstract}
ETypedElement {abstract}
Eclassifier {abstract}
EStructuralFeature {abstract}
EPackage
Abbildung 3.4: Metamodell ecore
• Komplexe Datentypen: EDate, EBigInteger, EBigDecimal, EResource, EResource- Set, EFeatureMapEntry, EFeatureMap, EEnummerator, EList, ETreeIterator
3.2.2 Beispiele f ¨ ur GXL, MOF und ecore
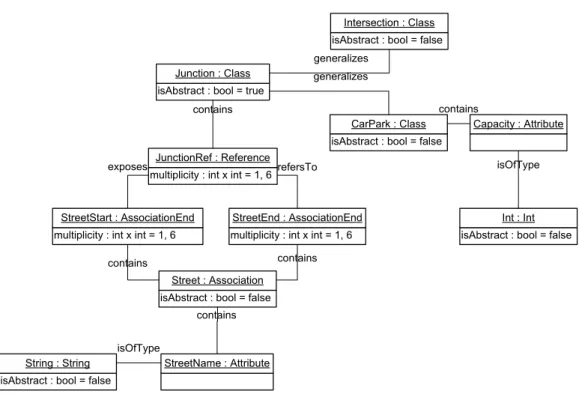
An dieser Stelle wird ein Schema definiert (Abb. 3.5), welches mittels der verschiedenen Metamodelle instanziiert wird.
Diese Beispiele vertiefen das Verst¨andnis der Metamodelle, zus¨atzlich l¨asst sich anhand dieser Beispielmodelle nochmals genauer feststellen, welche Elemente der Metamodel- le in das neue JGraLab-Metamodell ¨ubernommen werden k¨onnen.
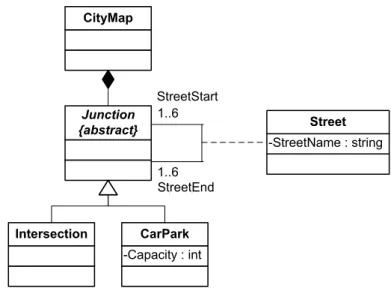
Allgemeine Beschreibung des Beispiels
Junction {abstract}
CityMap
Intersection
-Capacity : int CarPark
-StreetName : string Street StreetStart
StreetEnd 1..6
1..6
Abbildung 3.5: Beispiel f¨ur ein Graphenschema
Die Graphklasse CityMap (Stadtplan) soll Kanten vom Typ Street (Straße) und Kno- ten vom Typ Intersection (Kreuzung) und CarPark (Parkplatz) beinhalten. Die beiden
3.2. Vergleich der Metamodelle von GXL, MOF und ecore Knotentypen k¨onnen zu einem abstrakten Typ Junction (Verbindungspunkt) zusammen- gefasst werden.
Ein Parkplatz besitzt ein Attribut Capacity vom Typ Int. Jede Straße besitzt zudem ein Attribut StreetName vom Typ String. Straßen d¨urfen nur mit Verbindungspunkten verbunden werden und umgekehrt, die Kombinationen Verbindungspunkt-Verbindungs- punkt und Straße-Straße scheiden aus. Es d¨urfen minimal 1 und maximal 6 Verkn¨upfun- gen pro Knoten existieren.
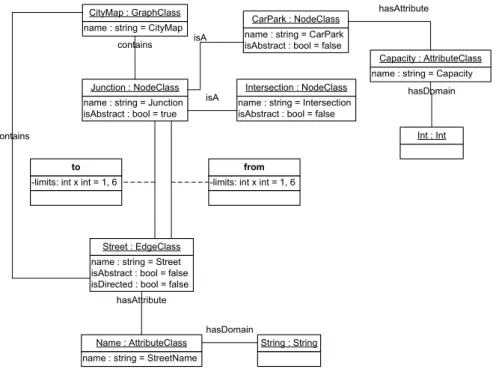
GXL
-limits: int x int = 1, 6 from -limits: int x int = 1, 6
to
name : string = CityMap CityMap : GraphClass
name : string = Street isAbstract : bool = false isDirected : bool = false Street : EdgeClass
name : string = StreetName Name : AttributeClass name : string = Junction isAbstract : bool = true
Junction : NodeClass
name : string = Intersection isAbstract : bool = false
Intersection : NodeClass name : string = CarPark isAbstract : bool = false CarPark : NodeClass
contains
contains
hasAttribute
isA isA
name : string = Capacity Capacity : AttributeClass hasAttribute
hasDomain
String : String
hasDomain
Int : Int
Abbildung 3.6: Beispiel f¨ur ein Graphenschema in GXL
In der Darstellung des Schemas 3.5 als Instanz des GXL-Metamodells (Abb. 3.2) kann das Beispiel relativ gut ausgedr¨uckt werden (Abb. 3.6), es existiert ein Stadtplan vom Typ GraphClass, Straßen vom Typ EdgeClass, Verbindungspunkte bzw. Kreuzungen und Parkpl¨atze vom Typ NodeClass.
Die Instanzen der Assoziationsklassen from und to k¨onnen zwischen Straßen und Ver- bindungspunkten bestehen, um die Multiplizit¨aten auszudr¨ucken.
Die beiden Attribute k¨onnen mit je einer Instanz der AttributeClass repr¨asentiert werden und verweisen auf ihre entsprechenden Dom¨anen Int und String.
Fazit des GXL-Beispiels
In GXL kann das Beispiel vollst¨andig ausgedr¨uckt werden.
MOF
isAbstract : bool = true Junction : Class
isAbstract : bool = false CarPark : Class isAbstract : bool = false
Intersection : Class
generalizes generalizes
isAbstract : bool = false Street : Association
contains
StreetName : Attribute
multiplicity : int x int = 1, 6 StreetEnd : AssociationEnd
contains contains
exposes refersTo
multiplicity : int x int = 1, 6 StreetStart : AssociationEnd
multiplicity : int x int = 1, 6 JunctionRef : Reference
contains
isAbstract : bool = false String : String
isOfType
isAbstract : bool = false Int : Int Capacity : Attribute contains
isOfType
Abbildung 3.7: Beispiel f¨ur ein Graphenschema in MOF
In MOF (Abb. 3.7) kann kein Objekt CityMap erstellt werden, da keine direkte nicht- abstrakte Aggregation von Modellelementen existiert. Im Diagramm existieren Kanten- typen (also Streets, entsprechend Instanzen der Klasse Association) und Junctions (Ver- bindungspunkte, entsprechend Instanzen der Klasse Class). Verbindungspunkte lassen sich in MOF als abstrakt markieren. Das name-Attribut wurde im Objektdiagramm aus
3.2. Vergleich der Metamodelle von GXL, MOF und ecore Ubersichtlichkeitsgr¨unden weggelassen, da es in allen Objekten vorkommt. Eine Juncti-¨ on kann weiter zu Intersection und CarPark spezialisiert werden, da die abstrakte Klasse Classifier eine Generalizes-Assoziation auf sich selbst besitzt.
Eine Junction beinhaltet eine JunctionRef, welche mittels der exposes und der refersTo Verkn¨upfung auf die beiden AssociationEnds referenziert. Die beiden AssociationEnd- Objekte geh¨oren zur Street und repr¨asentieren ihre Endpunkte, an welcher sie mit einer Junction verkn¨upft wird.
Multiplizit¨aten k¨onnen als multiplicity-Attribute von AssociationEnds ausgedr¨uckt wer- den. Die Attribute StreetName und Capacity k¨onnen ¨ahnlich wie in den anderen Spra- chen als Attribute von Street bzw. CarPark modelliert werden.
Fazit des MOF-Beispiels
In MOF kann das Beispiel nicht vollst¨andig ausgedr¨uckt werden, da die Entsprechung einer Graphklasse fehlt. Zus¨atzlich sind Kantenklassen kompliziert zu modellieren.
ecore
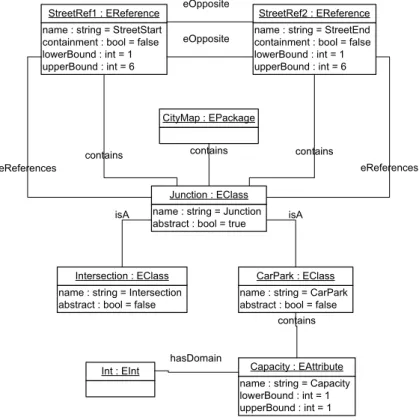
Im ecore-Modell (Abb. 3.8) wird als Graphenklasse ein EPackage verwendet. Dieses beinhaltet ein Objekt vom Typ EClass. ¨Uber die abstrakte Klasse EStructuralFeature k¨onnen die EReferences in einer EClass beinhaltet werden.
Im ecore-Modell existiert keine direkte Entsprechung einer Kantenklasse, im Beispiel wird ein Kantentyp durch zwei EReferences repr¨asentiert, die sich gegenseitig durch eOpposite referenzieren k¨onnen. Durch die eReferences-Verkn¨upfung wird auf eine Junction verwiesen. Das containment-Attribut wird auf false gesetzt, die Kardina- lit¨aten k¨onnen angegeben werden.
Das Capacity-Attribut kann inklusive seiner Dom¨ane EInt als EAttribute dargestellt wer- den.
Nicht modelliert werden kann das Attribut StreetName, da in ecore die EReferences keine Attribute tragen k¨onnen.
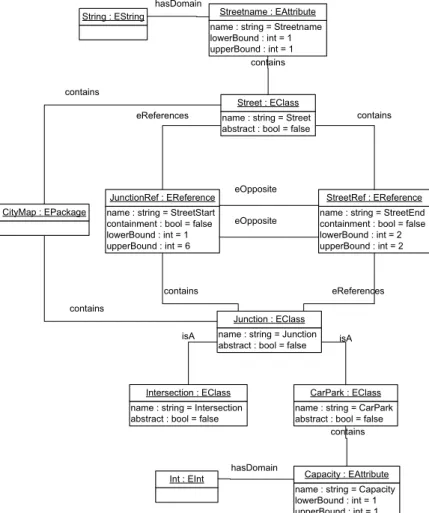
Alternativ kann die Kantenklasse als EClass modelliert werden. Damit besteht je eine EReference zwischen der Kantenklasse und der Knotenklasse (Abb. 3.9). Die Kanten- klasse kann in das EPackage aufgenommen werden.
name : string = Intersection abstract : bool = false
Intersection : EClass
name : string = CarPark abstract : bool = false
CarPark : EClass name : string = StreetStart
containment : bool = false lowerBound : int = 1 upperBound : int = 6
StreetRef1 : EReference
name : string = StreetEnd containment : bool = false lowerBound : int = 1 upperBound : int = 6
StreetRef2 : EReference eOpposite
eOpposite
eReferences eReferences
isA isA
CityMap : EPackage
contains
contains contains
name : string = Junction abstract : bool = true
Junction : EClass
name : string = Capacity lowerBound : int = 1 upperBound : int = 1 Capacity : EAttribute
contains
Int : EInt
hasDomain
Abbildung 3.8: Beispiel f¨ur ein Graphenschema in ecore
3.2. Vergleich der Metamodelle von GXL, MOF und ecore
name : string = Intersection abstract : bool = false
Intersection : EClass
name : string = CarPark abstract : bool = false
CarPark : EClass name : string = StreetStart
containment : bool = false lowerBound : int = 1 upperBound : int = 6
JunctionRef : EReference
name : string = StreetEnd containment : bool = false lowerBound : int = 2 upperBound : int = 2
StreetRef : EReference eOpposite
eOpposite
eReferences contains
isA isA
CityMap : EPackage
contains
contains eReferences
name : string = Junction abstract : bool = false
Junction : EClass
name : string = Capacity lowerBound : int = 1 upperBound : int = 1 Capacity : EAttribute
contains
Int : EInt
hasDomain name : string = Street abstract : bool = false Street : EClass name : string = Streetname lowerBound : int = 1 upperBound : int = 1
Streetname : EAttribute
contains String : EString
hasDomain
contains
Abbildung 3.9: Alternatives Beispiel f¨ur ein Graphenschema in ecore
Fazit des ecore-Beispiels
In ecore sind Assoziationen wiederum anders modelliert wie in GXL und MOF. At- tribute von Assoziationen lassen sich nur ¨uber einen Umweg modellieren, wenn die Kantenklasse durch eine EClass repr¨asentiert wird.
3.2.3 Verwendungsm ¨ oglichkeiten der Elemente der Metamodelle in JGraLab
In diesem Abschnitt sollen die zuletzt beschriebenen Metamodelle auf Gemeinsamkei- ten sowie auf Eignung f¨ur TGraphen gepr¨uft werden, um ein JGraLab Metamodell zu entwickeln. Das Metaschema soll selbstbeschreibend sein.
Wir unterscheiden zwischen einem internen und einem externen Klassendiagramm f¨ur JGraLab. Das externe Klassendiagramm zeigt die Sicht des Anwenders auf die Klas- senbibliothek, hier wird von internen Attributen und Methoden abstrahiert. Es k¨onnen im internen Klassendiagramm eventuelle Geschwindigkeitsoptimierungen und Hilfs- klassen einfließen, die das Verst¨andnis der Modelle beeintr¨achtigen k¨onnen. Das interne Klassendiagramm ist somit nur f¨ur Entwickler relevant, welche JGraLab erweitern oder verbessern m¨ochten.
GXL
Die Klassen GraphClass, NodeClass sowie EdgeClass lassen sich nahezu 1:1 in JGraLab
¨ubernehmen. Die GraphElementClass bietet durch das isAbstract-Attribut eine brauch- bare M¨oglichkeit an, abstrakte Typen zu deklarieren.
Des Weiteren lassen sich die Aggregation sowie die Komposition ¨ubernehmen (z.B.
zum kaskadierten L¨oschen von Graphobjekten), da das Modell selbstbeschreibend sein soll. Das isOrdered-Attribut kann wegfallen, da TGraphen immer angeordnet sind.
Was das GXL-Metamodell nicht bietet, ist die Einschr¨ankung, dass EdgeClasses nur durch EdgeClasses und NodeClasses nur durch NodeClasses generalisiert werden k¨on- nen. Um dem JGraLab-Metamodell mehr Ausdruckskraft zu verleihen, bietet es sich an, dort die isA-Assoziation in die jeweiligen Unterklassen zu verschieben.
Des Weiteren soll es in JGraLab nicht m¨oglich sein, from- und to-Assoziationen von
![Abbildung 1.1: Beispiel f¨ur einen TGraphen [EbKu02], S.4](https://thumb-eu.123doks.com/thumbv2/1library_info/5219584.1669532/13.892.173.675.173.501/abbildung-beispiel-f-ur-einen-tgraphen-ebku-s.webp)