pr obabilities
configurations stationary?
propagate with model
relative entropy Data
pr obabilities
configurations
Stochastic inference from snapshots of the non-equilibrium steady state:
the asymmetric Ising model and beyond
Dissertation Simon Lee Dettmer
Köln 2017
of the non-equilibrium steady state:
the asymmetric Ising model and beyond
Inaugural-Dissertation zur
Erlangung des Doktorgrades
der Mathematisch-Naturwissenschaftlichen Fakult¨at der Universit¨at zu K¨oln
vorgelegt von
Simon Lee Dettmer
aus Oberhausen
K¨oln, 2017
Tag der m¨undlichen Pr¨ufung: 05. Oktober 2017
In dieser Arbeit untersuchen wir das Problem der Parameter-Inferenz f¨ur ergodische Markov-Prozesse, die gegen einen station¨aren Zustand konvergieren, der nicht durch die Boltzmann-Verteilung beschrieben wird. Unser Hauptergebnis ist, dass wir die Pa- rameter verschiedener Modelle auf der Grundlage von unabh¨angigen Stichproben aus dem station¨aren Zustand lernen k¨onnen, obwohl wir die station¨are Wahrscheinlichkeits- verteilung nicht kennen. Genauer: f¨ur die untersuchten Modelle in stetiger Zeit konnten wir die Parameter bis auf einen Skalierungsfaktor inferieren, welcher die Zeitskala bes- timmt, die nat¨urlich nicht aus statischen Messungen ermittelt werden kann; bei Mod- ellen in diskreter Zeit ist die Zeitskala bereits implizit durch die Diskretisierung gew¨ahlt und wir konnten alle Parameter der untersuchten Modelle inferieren. Als Paradigma f¨ur Nicht-Gleichgewichts-Prozesse untersuchen wir das asymmetrische Ising-Modell mit Glauber-Dynamik. Es beschreibt bin¨are Spinvariablen mit asymmetrischen paar- weisen Wechselwirkungen unter dem Ein fl uss ¨außerer Magnetfelder. Diese Magnet- felder und Wechselwirkungsst¨arken wollen wir lernen. Zu diesem Zweck haben wir in dieser Arbeit zwei verschiedene Inferenzmethoden entwickelt: die erste Methode basiert auf der Berechnung von Magnetisierungen, sowie Zwei- und Dreipunkt-Spin- Korrelationen, zum einen in einer selbstkonsistenten Form, die exakt ist, und zum an- deren in einer geschlossenen Form innerhalb einer Molekularfeld-N¨aherung; die zweite Methode beruht auf der Maximierung einer Funktion, die wir ”propagator likelihood”
nennen. Diese betrachtet fi ktive ¨ Uberg¨ange zwischen allen gemessenen Kon fi guratio-
nen und ist verwandt mit der bekannten Log-Likelihood-Funktion f¨ur Gleichgewichts-
Systeme. Der Vorteil des Molekularfeld-Ansatzes ist sein vergleichbar geringer nu-
merischer Aufwand, w¨ahrend der Vorteil des ”propagator likelihood”-Verfahrens darin
besteht, dass es die gesamte empirische Verteilung verwendet und leicht auf jeden er-
godischen Markov-Prozess angewandt werden kann. Insbesondere wenden wir die ”prop-
agator likelihood”-Methode auf weitere bekannte Nicht-Gleichgewichtsmodelle aus der
Statistischen Physik und der Theoretischen Biologie an: den einfachen asymmetrischen
Exklusionsprozess (ASEP) in stetiger Zeit mit diskreten Kon fi gurationen, sowie die
Replikatordynamik in stetiger Zeit mit kontinuierlichen Kon fi gurationen. Die Allge-
meing¨ultigkeit des ”propagator likelihood”-Ansatzes wird dadurch betont, dass er di-
rekt aus dem Prinzip hergeleitet werden kann, dass die gemessene Verteilung station¨ar
unter der Dynamik sein soll, das heißt wir minimieren die relative Entropie zwischen
der empirischen Verteilung und einer Verteilung, die durch eine Zeitentwicklung dieser
empirischen Verteilung erzeugt wird. Schließlich untersuchen wir noch eine etwas an-
dere Situation und zeigen wie die Inferenz im asymmetrischen Ising-Modell verbessert
werden kann, wenn wir mehrere Datens¨atze aus unabh¨angigen Stichproben von ver-
schiedenen station¨aren Zust¨anden haben, die durch kontrollierte St¨orungen der zugrunde
liegenden Modellparameter erzeugt werden.
In this thesis we study the problem of inferring the parameters of ergodic Markov pro-
cesses that converge to a non-equilibrium steady state. Our main result is that for many
models, we can learn the parameters based on independent samples taken from the
steady state, even though we do not know the stationary probability distribution. To
be more precise: for the investigated models in continuous time, we could infer the pa-
rameters up to a factor that defines the time scale, which, naturally, cannot be determined
from static measurements; for the investigated models in discrete time, the time scale
is already chosen implicitly by the discretisation and we could infer all parameters. As
our main paradigm for non-equilibrium inference problems, we study the asymmetric
Ising model with Glauber dynamics. It consists of binary spins subject to external fi elds
and asymmetric pairwise spin-couplings, which we seek to infer. For this purpose we
have developed two different inference methods: the fi rst method is based on computing
magnetisations, two- and three-point spin correlations, either in a self-consistent form
that is exact, or in a closed form within a mean fi eld approximation; the second method
is based on maximising a “propagator likelihood”, which considers fi ctitious transitions
between all sampled con fi gurations and is akin to the well-known log-likelihood func-
tion used for equilibrium systems. The advantage of the mean fi eld approach is its
computational ef fi ciency, while the advantage of the propagator likelihood method is
that it uses information from the full sampled distribution and can easily be applied to
any ergodic Markov process. In particular, we apply the propagator likelihood method
to other prominent non-equilibrium models from statistical physics and theoretical bi-
ology: (i) the asymmetric simple exclusion process (ASEP) in continuous time with
discrete con fi gurations and (ii) replicator dynamics in continuous time with continuous
con fi gurations. The generality of this approach is emphasised by the fact that we can
derive the propagator likelihood directly from the principle that the sampled distribution
should be stationary under the model dynamics: we minimise the relative entropy be-
tween the sampled distribution and a distribution generated by propagating the sampled
distribution in time. Finally, we investigate a slightly different setting: we show how in-
ference can be improved in the asymmetric Ising model by considering multiple sets of
independent samples taken from several steady states, which are generated by controlled
perturbations of the underlying model parameters.
I would like to acknowledge Chau Nguyen, not only for his collaboration and
thoughtful comments concerning the project on mean fi eld inference, but also for
the enjoyable experience of teaching statistical physics classes together, where in
numerous discussions he was so kind to share with me his thorough understand-
ing of the subject. Further, I owe many thanks to my supervisor, Johannes Berg,
not only for presenting me with the problem of non-equilibrium inference, but
also for his continuous support, time, and faith, all of which he gave generously.
1 Introduction 1
1.1 Thesis overview . . . . 1
1.2 Markov processes . . . . 2
1.2.1 Discrete con fi gurations: Markov chains . . . . 4
1.2.2 Continuous con fi gurations . . . . 9
1.2.3 Equilibrium versus non-equilibrium steady states . . . . 19
1.3 Stochastic inference . . . . 25
1.3.1 The Bayesian framework and maximum likelihood . . . 27
1.3.2 Equilibrium inference from snapshots of the steady state 31 1.3.3 Non-equilibrium inference from time-series data . . . . 35
2 The asymmetric Ising model 37 2.1 The model and its history . . . . 37
2.2 Glauber dynamics . . . . 38
2.2.1 Interaction symmetry and detailed balance . . . . 40
2.2.2 Callen’s identities . . . . 42
2.3 Connection with neural networks . . . . 44
2.4 Stochastic inference from time-series data . . . . 46
2.4.1 Maximum likelihood of time-series . . . . 46
2.4.2 The Gaussian mean fi eld theory and time-shifted corre- lations . . . . 50
3 Self-consistent equations and non-equilibrium mean fi eld theory 55 3.1 The general theory . . . . 56
3.1.1 Deriving self-consistent equations . . . . 56
3.1.2 Exact inference based on direct sample averages of the self-consistent equations . . . . 59
3.1.3 Expanding the self-consistent equations with non-equilibrium mean fi eld theory . . . . 60
3.2 Inference in the asymmetric Ising model . . . . 66
3.2.1 Callen’s identities and their mean fi eld expansion . . . . 66
3.2.2 Parameter inference for sequential Glauber dynamics . . 78
3.2.3 Model selection . . . . 79
4 The propagator likelihood 85 4.1 The concept . . . . 85
4.1.1 Minimising relative entropy . . . . 86
4.2 Stochastic inference . . . . 88
4.2.1 Models with discrete con fi gurations (Markov chains) . . 88 4.2.2 Models with continuous con fi gurations . . . . 92 4.2.3 Non-equilibrium models in statistical physics and theo-
retical biology . . . . 95 5 Learning from perturbations in the asymmetric Ising model 105 5.1 General setting and considerations . . . 105 5.2 Mean fi eld inference . . . 106 5.3 Inference with the Gaussian mean fi eld theory . . . 108 5.3.1 Self-consistent equations for the two-point correlations. . 109 5.3.2 Inference from perturbations in sequential Glauber dy-
namics . . . 110
6 Conclusions and Outlook 115
References 121
A Further mean fi eld equations for the asymmetric Ising model 127
A.1 Magnetisations to third order . . . 127
A.2 Correlations under sequential Glauber dynamics . . . 127
A.3 Correlations under parallel Glauber dynamics . . . 129
B Description of the moment-matching inference algorithm 131
1
Introduction
To begin at the beginning
Dylan Thomas
1.1 Thesis overview
This thesis addresses the problem of inferring the parameters of ergodic Markov processes based on independent samples taken from the non-equilibrium steady state.
In this fi rst chapter, we recall the standard results on ergodic Markov pro- cesses concerning the convergence to steady states and their classi fi cation into equilibrium and non-equilibrium steady states. We then formulate our stochastic inference problem and give a brief overview of established inference methods for equilibrium steady states and for time-series data. First, we motivate the max- imum likelihood method within the framework of Bayesian reasoning, before brie fl y mentioning the equilibrium mean fi eld approximation and the pseudo- likelihood method. Second, we discuss inference based on maximum likelihood for time series.
In chapter 2, we give some background on our main paradigm for non- equilibrium inference problems: the asymmetric Ising model. We will introduce Glauber dynamics and show that this dynamics converges to a non-equilibrium steady state for the case of asymmetric couplings between spins; we motivate the consideration of asymmetric couplings by brie fl y discussing the connection of the asymmetric Ising model with neural networks. In the following, we describe Callen’s identities characterising the spin moments, since they will be used for inference in chapters 3 and 5. We discuss maximum likelihood inference based on time-series data and present some minor results we found for inference in sequential Glauber dynamics, before presenting the Gaussian mean fi eld theory of M´ezard and Sakellariou (2011), which we will use for inference in chapter 5.
In chapter 3, we develop our fi rst method for stochastic inference from snap- shots of the steady state, which is based on fi tting sampled observables to self- consistent equations, which we derive as generalisations of Callen’s identities.
We show how these self-consistent equations can be used to infer model param-
eters by replacing steady state expectation values with sample averages. In the
following, we discuss how to approximately evaluate the self-consistent equa-
tions in a closed-form within an expansion around non-equilibrium mean fi eld
theory. The presentation of this expansion was inspired by the work of Kappen
and Spanjers (2000), who developed the non-equilibrium mean fi eld theory for the asymmetric Ising model. Here, we provide a straightforward generalisation of their theory and formulate it for a wider class of ergodic Markov processes.
Finally, we use these methods to address the stochastic inference problem for the asymmetric Ising model.
In chapter 4, we develop our second inference method, based on maximis- ing a function we call the propagator likelihood. We give a derivation of this function based on minimising relative entropy and illustrate the method for sev- eral toy models spanning the different classes of Markov processes, including the Ornstein-Uhlenbeck process and the asymmetric simple exclusion process (ASEP). Then we use the method to infer the parameters of more challenging models: the asymmetric Ising model (again) and replicator dynamics.
In chapter 5, we consider a slightly different setting and investigate how in- ference in the asymmetric Ising model can be improved by considering multiple sets of independent samples, which are taken from several steady states gener- ated by known perturbations of the underlying parameters. We begin with some general considerations concerning the observables required for a well-de fi ned inference problem and discuss the different roles of perturbations of the external fi elds and perturbations of the couplings. Next, we develop a simple inference algorithm based on the expressions for magnetisations and two-point correla- tions obtained in the non-equilibrium mean fi eld theory of chapter 3 and discuss some basic properties of the approach. We follow with a more powerful infer- ence method based on the Gaussian mean fi eld theory of M´ezard and Sakellar- iou (2011), which we use to derive self-consistent equations for the equal-time two-point correlations. In the case of vanishing external fi elds, these equations become linear in the couplings and allow for a computationally highly ef fi cient inference algorithm that can easily be scaled to large system sizes. We investi- gate the performance of this method by considering an example where half of the couplings is set to zero in the perturbation and compare the approach to the setting considered chapters 3 and 4.
Finally, in chapter 6 we summarise and interpret our results in addition to giving a perspective on possible future directions for research. Section 3.2, ap- pendix B, and parts of appendix A were previously published in (Dettmer et al., 2016); chapter 4 has appeared in (Dettmer and Berg, 2017).
1.2 Markov processes
A stochastic process { X ( t )} is a sequence of random variables { X ( t )} t ∈ I , where
the index t denotes time, which could be discrete, I = { 0 , 1 ,..., T } , or continu-
ous, I = [ 0 , T ] , with a possibly in fi nite time horizon T = ∞ . Examples for the ran-
dom variables could be the continuous-time positions of a set of gas molecules, the daily temperature at noon on the roof of Cologne Cathedral, or the weekly draw of lottery numbers. Due to the randomness of the variables we cannot make de fi nite predictions about outcomes, but instead have to content ourselves with statements about the probabilities of different outcomes. This probability may be interpreted as a subjective belief concerning different events occurring (Bayesian interpretation) or as their relative frequencies in the limit of a large ensemble of copies of the process, each taking a different (random) realisation (frequentist interpretation).
Figure 1.1: Andrei Andreye- vich Markov, who researched the stochastic processes nowadays named after him, was less inter- ested in physical applications of these processes but instead pre- ferred to use them for studying poetry.
In general, there will be relationships con- necting the different variables, e.g. given that today the temperature at Cologne Cathedral is 21 ◦ C, it is highly unlikely that tomorrow the temperature will be − 10 ◦ C. These relation- ships can be captured by conditional proba- bilities, which tell us how the observed re- alisation of the stochastic process until time t 1 in fl uences the probability of some event A taking place at a later time t 2 > t 1 . The inter-dependence of the random variables may be arbitrarily complicated, however, for many applications we can focus on classes of pro- cesses with very simple relationships. The simplest case is when the variables are statisti- cally independent, e.g. knowledge of the past draws of lottery numbers does not in fl uence the probabilities of particular numbers appear- ing in next week’s draw. This case will not be discussed in this thesis. For processes with real inter-dependencies between the variables, the simplest case is when the probability of the future event A depends on the past history of the process only via the present state X ( t 1 ) , i.e.
P ( X ( t 2 ) ∈ A |{ X ( s )} s ≤ t
1) = P ( X ( t 2 ) ∈ A | X ( t 1 )) ∀ t 2 > t 1 , (1.1)
which is known as the Markov property. Sequences of random variables obey-
ing the Markov property are known as Markov processes, in recognition of
Andrei Markov who studied these processes for the purpose of extending the
weak law of large numbers to random variables that are not statistically inde-
pendent (Markov, 2006; Seneta, 2006). The reason for the widespread use of Markov processes is not just their simplicity, but for many real-world processes it can be argued that the Markov property should hold true with a high degree of accuracy. For example, in the kinetic theory of gases (see e.g. Redner et al.
(2010)) the molecular chaos assumption argues that the trajectories ( x ( t ), v ( t )) of gas particles are effectively Markov processes, due to the great number of particle collisions occurring on time-scales much shorter than the observation time.
Of course not all real-world random processes are Markovian and whether a process obeys the Markov property depends also on the choice of variables.
Consider a point-mass in classical mechanics described by its position x and momentum p. We know that knowledge of the current position x ( t ) is not suf fi - cient to predict the future trajectory of the particle so the position process { x ( t )}
does not obey the Markov property. However, adding the momentum p ( t ) yields the necessary information and the joint process {( x ( t ), p ( t ))} is indeed a Markov process 1 . In fact, many probabilistic models with memory can be made Markov processes by adding auxiliary variables (see e.g. Lei et al. (2016)).
1.2.1 Discrete con fi gurations: Markov chains
Markov processes can be classi fi ed by (i) whether time is discrete or continu- ous, and (ii) whether the con fi guration space Ω X ( t ) is discrete or continuous.
Markov processes with discrete con fi gurations are called Markov chains. The theory is simplest for these Markov chains and for this reason we pick them as our starting point for an exposition of the standard results on Markov pro- cesses (see e.g. Feller (1968); Gardiner (2009); Grimmett and Stirzaker (2001);
Klenke (2013); Levin and Peres (2008)) most pertinent to the framing our stochas- tic inference problem.
1.2.1.1 Discrete time
We consider a set of n possible con fi gurations Ω = {ω 1 ,..., ω n } , assumed by the random variables X 0 , X 1 , X 2 ,... , where X t is a short-hand for X ( t ) . As exam- ples we can think of the energy levels assumed by a quantum harmonic oscilla- tor, the number of particles present in a subsystem connected to a reservoir of chemical potential µ . The discretisation of time could correspond to measure- ments taking place at fi xed time intervals. In this case, we can use the Markov
1 A free point-mass would of course obey deterministic dynamics, which can be
considered a limiting case of random processes. By adding interactions with a heat
bath we can introduce randomness into the process and the same statement applies.
property to iteratively rewrite the joint probability distribution of a set of ran- dom variables X 0 , X 1 ,..., X k in terms of the single-step conditional probabilities P ( X t = x t | X t − 1 = x t − 1 ) as
P ( X k = x k ,..., X 0 = x 0 ) = P ( X k = x k | X k−1 = x k−1 ,..., X 0 = x 0 )
× P ( X k−1 = x k−1 ,..., X 0 = x 0 )
= P ( X k = x k | X k−1 = x k−1 ) P ( X k−1 = x k−1 ,..., X 0 = x 0 )
=... = P ( X 0 = x 0 ) t=1 ∏ k P ( X t = x t | X t − 1 = x t − 1 ) . (1.2)
The conditional probabilities P ( X t = x t | X t − 1 = x t − 1 ) are also called transition probabilities. The most commonly studied Markov chains are time-homogeneous chains, where the transition probabilities do not depend on the time t of the tran- sition. Hence, the process is fully described by the initial condition P ( X 0 = x 0 ) and the matrix of transition probabilities
T i j : = P ( X 1 = ω j | X 0 = ω i ) . (1.3) In particular, by summing over intermediate time-steps, the distribution of the random variable at time t, p i ( t ) : = P ( X t = ω i ) , can be written as the matrix product of the initial distribution p ( 0 ) and the transition matrix T taken to the power t
p i ( t ) = [ p ( 0 ) T t ] i = ∑ j=1 n p j ( 0 )( T t ) ji . (1.4)
For the special case of deterministic initial conditions where the process starts in a con fi guration x 0 ∈ Ω , i.e. p j ( 0 ) = δ ω
j,x
0, we reserve the notation
p ( x , t | x 0 , 0 ) : = P ( X ( t ) = x | X ( 0 ) = x 0 ) , (1.5) which is called the propagator, since it takes the probability distribution at time 0 (concentrated in con fi guration x 0 ) and propagates this distribution forward in time to create the probability distribution at time t. Due to the linearity of the equations, we can write the solution for an arbitrary initial condition p ( 0 ) as a sum over propagators
p i ( t ) = ∑ j=1 n p (ω i , t |ω j , 0 ) p j ( 0 ) . (1.6)
T HE STEADY STATE AND CONVERGENCE OF THE M ARKOV CHAIN
Under certain conditions on the transition matrix T , the single-time distribution
p ( t ) converges to a unique distribution π , called the steady state (or stationary
distribution), independent of the initial probability distribution p ( 0 ) . We call these chains ergodic. It is clear that the steady state has the property of remain- ing unchanged when propagating the distribution with the transition matrix
π = π T , (1.7)
which we use as the de fi nition of a steady state.
In some cases one or more steady states may exist, but the Markov chain might not converge for arbitrary initial conditions. For chains with fi nite con- fi guration space, |Ω| < ∞ , the existence and uniqueness of the steady state is guaranteed by the condition of irreducibility, stating that the chain can reach any con fi guration from any starting point in a fi nite number of steps with pos- itive transition probability. These are the most studied chains and all Markov chains considered in this thesis will be irreducible. Markov chains that are not irreducible can be divided into irreducible sub-chains and then only the transi- tions between the subclasses have to be accounted for additionally. For in fi nite con fi guration spaces, |Ω| = ∞ , irreducibility is not suf fi cient to ensure the ex- istence of a normalisable steady state. In addition, we require that the average time of return to any initial con fi guration is fi nite. These chains are called posi- tive recurrent. The Markov chain actually converges to the unique steady state, independent of the initial condition, if the chain is aperiodic. In an aperiodic chain, the possible paths that start from an initial con fi guration and return to the starting point must not have a common divisor to their number of steps. An ex- ample for a periodic chain is the simple random walk on Z , where the chain hops one place to the left or one place to to right in every time step, so the chain can return to a con fi guration only after an even number of steps.
The results above on the convergence of Markov chains have been known for a long time. More recently, people have studied how long the Markov chain ac- tually takes to converge to the steady state and how this time depends on the size of the con fi guration space; this fi eld is known as Markov mixing times (Levin and Peres, 2008).
E XAMPLE : BIASED RANDOM WALK ON N 0
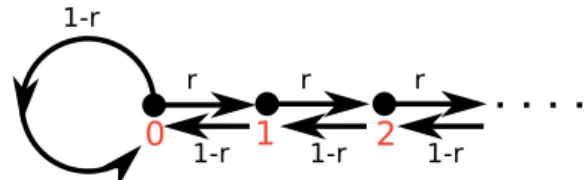
The biased random walk on N 0 is most simply de fi ned by a picture of the chain’s con fi gurations and transition probabilities (Fig. 1.2).
In each time step, the chain moves one place to the right with probability
r, or one place to the left with probability 1 − r, except when the chain is in 0
where instead of moving to − 1, the chain remains in 0. The chain is obviously
irreducible and aperiodic, since the chain can remain in 0 for an arbitrary number
of time steps. The chain therefore converges to a unique steady state if and
only if the chain is positive recurrent. We can check this condition by actually
r
0 1-r 1 2
1-r
r r
1-r 1-r
Figure 1.2: Schematic view of the transition rules for the biased random walk on N 0 .
computing the steady state. The steady state de fi ning equation (1.7) becomes r π i−1 + ( 1 − r )π i+1 = π i , i = 1 , 2 ,... (1.8) ( 1 − r )π 0 + ( 1 − r )π 1 = π 0 . (1.9) These equations can be solved iteratively and we obtain
π i = r
1 − r i
π 0 . (1.10)
The steady state is normalisable if and only if r /( 1 − r ) < 1 ⇔ r < 1 / 2:
1 = ∑ ∞
i = 0
π i = ∑ ∞
i = 0
r 1 − r
i
π 0
r 1−r