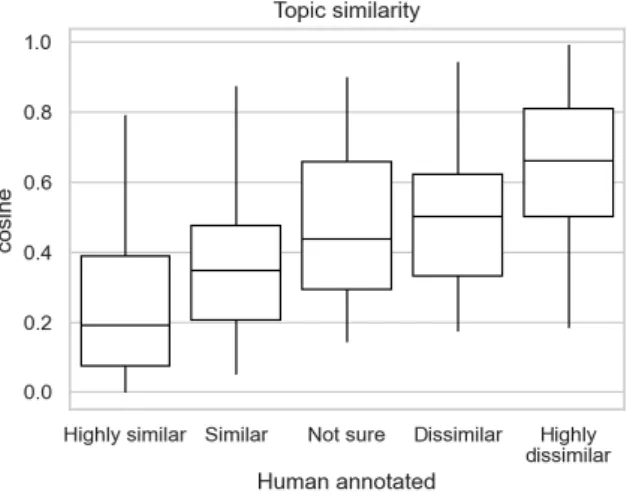
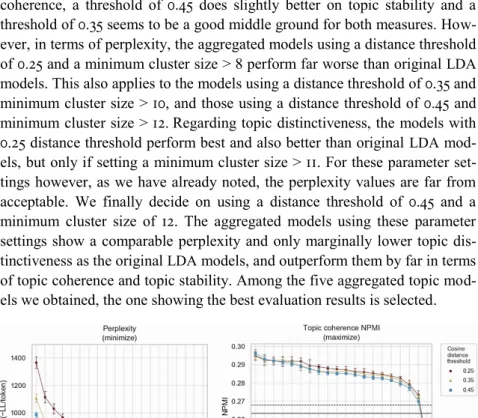
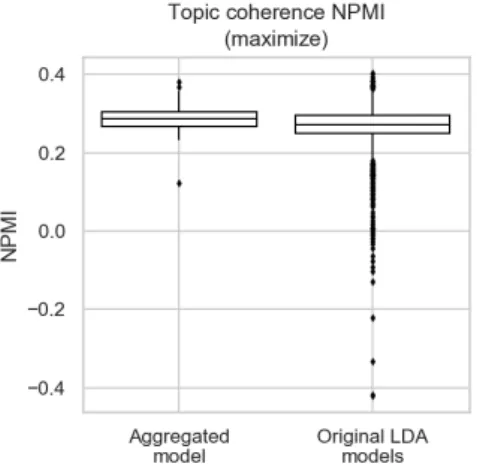
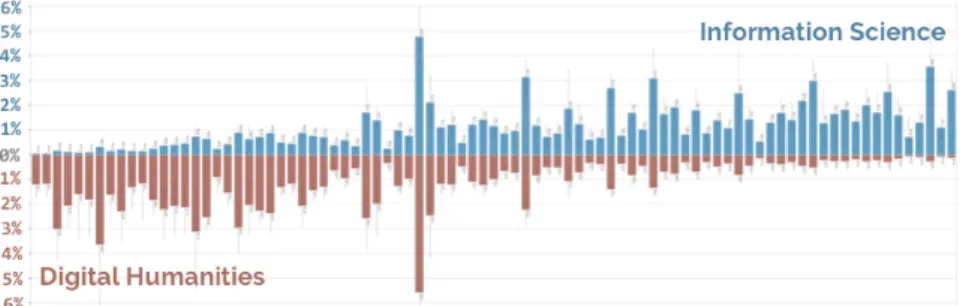
Same same, but different
27
0
0
Volltext
(2)
(3)
(4)
(5)
(6)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
Abbildung

+7
ÄHNLICHE DOKUMENTE
In this research work we study the mechanism of re-broadcasting (called “retweeting”) information on Twitter; specifically we use Latent Dirichlet Allocation to analyze users
(C) Kaplan-Meier survival analysis showed that mRNA overexpression of LANCL2 or EGFR was not associated with OS and PFS of IDH1/2-wild-type GBM patients (n=145).... Figure S3 : The
Consumers are becoming immune to advertising by fast forwarding through TV adverts using their hard disc recorders, blocking or ignoring internet banner advertising, and failing
It supports the professional integration of university graduates and experienced experts from developing, emerging and transition countries, who have completed their training
- Impact on Patient: how technology consultations influence the experience of living with illness and engagement with clinical care. Part 4 – Virtual
Alternatives to oil as an energy source, keep oil price tied to other energy prices. Supply shortages do not justify enforced and rapid switch to renewables,
Sub-collections based on time as well as on other cate- gories as mentioned above are generated on-the-fly, using faceted search or keyword search. Figure 4 shows an ex- tract
The children mark in animals in a given landscape and they should imagine and create stepping stone biotopes to help the animals there.. Before this step it would be advisable
