7. Neuronale Netze
Einf¨ uhrung (1)
Ein k¨unstliches neuronales Netz ist vom Konzept her eine Realisierung von miteinander verschalteten Grundbausteinen, sogenannter Neuro- nen, welche in rudiment¨arer Form die Vorg¨ange im biologischen Vor- bild, unserem Gehirn, nachahmen. Wichtige Eigenschaften sind:
• Lernf¨ahigkeit,
• Parallelit¨at,
• Verteilte Wissensrepr¨asentation,
• Hohe Fehlertoleranz,
• Assoziative Speicherung,
• Robustheit gegen St¨orungen oder verrauschten Daten,
2
Einf¨ uhrung (2)
Der Preis f¨ur diese Eigenschaften ist:
• Wissenserwerb ist nur durch “Lernen” m¨oglich.
• Logisches (sequenzielles) Schließen ist schwer.
• Sie sind oft langsam und nicht immer erfolgreich beim Lernen.
Aus diesem Grunde werden Neuronale Netze nur dort angewandt, wo gen¨ugend Zeit f¨ur ein Lernen zur Verf¨ugung steht. Sie stehen in Kon- kurrenz z.B. zu Vektorraum-Modellen oder probabilistischen Modellen.
Es gibt viele fertige Softwarepakete f¨ur Neuronale Netze, siehe z.B.
Liste unter http://de.wikipedia.org/wiki/K¨unstliches_neuronales_Netz
Einf¨ uhrung (3)
Ein Neuronales Netz besteht aus verbundenen Neuronen
(ca. 1010 − 1011 Neuro- nen bei einem Menschen mit ca. 1014 − 1015 Verbindungen).
Abbildung aus Wikipedia: https:// de.wikipedia.org/wiki/Neuronales Netz
4
Einf¨ uhrung (4)
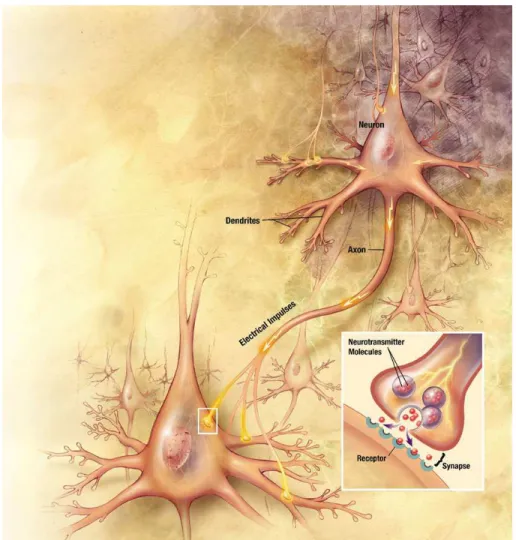
Ein Neuron hat
• Dendriten, die die Eingaben einsammeln
• Soma, der Zellk¨orper
• Axon, welches die Ausgabe der Zelle weiterleitet, sich verzweigt und mit den Dendriten nachfolgender Neuronen ¨uber Synapsen in Kontakt tritt.
• Synapsen sch¨utten Neurotransmitter aus, die anregend oder d¨amp- fend wirken.
Einf¨ uhrung (5)
Ein Modell eines Neurons:
X1 ω1j Übertragungs- funktion
Aktivierungs- funktion
Ausgabe- funktion Eingabe
Gewichte
Schwellwert
Ausgabe
Xi ωij
Xn ωnj
fprop net fact a fout o
j j j
Die Ausgabe f¨uhrt zur Aussch¨uttung von Neurotransmittern und damit zu einer Eingabe der nachfolgenden Zellen bzw. Neuronen.
In den Aktivit¨aten der Neuronen ist die Information codiert.
6
Einf¨ uhrung (6)
Vereinfacht: Ein Neuron i mit n Eing¨angen (Dendriten) bekommt einen Gesamtinput von neti und erh¨alt damit einem Aktivit¨atswert ai.
Daraus folgt ein Ausgangswert oi (Axon), der ¨uber eine synaptische Koppelung wi,j an das Neuron j koppelt.
ai aj
net net
o o
i
i
j w i,j j
Neuronale Netze waren f¨ur l¨angere Zeit auf Grund der “Lernprobleme”
aus der Mode gekommen. Seit ca. 2005 erleben neuronale Netzwer- ke eine Wiedergeburt, da sie bei herausfordernden Anwendungen oft bessere Ergebnisse als konkurrierende Verfahren liefern.
Einf¨ uhrung (7)
Eine andere Sichtweise auf Neuronale Netze besteht darin, dass es sich schlicht und einfach um eine Darstellung eines Rechengraphen handelt, bei dem sich auf bestimmte Operationen beschr¨ankt wurde, die anschließend nicht explizit notiert wurden.
Zwei Beispiele von Rechengraphen
x
o
y z
a b
σ
dot +
x y
z
x
8
Einf¨ uhrung (8)
1. “Klassische” k¨unstliche Neuronale Netze
• Grundlage sind biologische Neuronen, jedoch in einer starken Vereinfachung, so dass sie mathematisch einfach und schnell zu behandeln sind.
• Heute werden sogenannte tiefe Netze (deep neural networks) verwendet, bei denen Neuronen ¨uber viele Schichten verbunden sind (siehe z.B. www.deeplearning.net/).
• Sie werden z.B. von Google, Apple, Facebook, NSA, BND und vielen anderen verwendet z.B. zur Bild- und Spracherkennung, in der Robotik, f¨ur Optimierungsprobleme usw.
• Fast t¨aglich gibt es neue Meldungen ¨uber neue Anwendungen.
Einf¨ uhrung (9)
Anwendungsgebiete nach Wikipedia (Stand 2016):
• Regelung und Analyse von komplexen Prozessen
• Fr¨uhwarnsysteme
• Optimierung
• Zeitreihenanalyse (Wetter, Aktien etc.)
• Sprachgenerierung
• Bildverarbeitung und Mustererkennung
* Schrifterkennung (OCR), Spracherkennung, Data-Mining
• Informatik: Bei Robotik, virtuellen Agenten und KI-Modulen in Spielen und Simulationen.
• Medizinische Diagnostik, Epidemiologie und Biometrie
• Klangsynthese
• Strukturgleichungsmodell zum Modellieren von sozialen oder be- triebswirtschaftlichen Zusammenh¨angen
10
Einf¨ uhrung (10)
Weitere aktuelle Anwendungsbeispiele (2016)
• Mit zwei tiefen Netzen, eins f¨ur die Vorhersage guter Z¨uge und eins f¨ur den Wert einer Stellung, ist es im M¨arz 2016 gelungen, einen Go-Meister zu schlagen. Hardware: 1202 CPUs mit 176 GPUs.
• Facebook sagt, das neue System Deep Text versteht Texte ge- nauso gut wie Menschen.
• Google Photo oder die Translater-App, auf Clustern trainiert, lau- fen jetzt auf dem Smartphone.
• Immer mehr Firmen entwickeln Empathiemodule.
• Google hat gerade f¨ur Neuronale Netze eine Tensor Processing Unit (TPU) entwickelt.
• In der MKL (Mathematical Kernel Library) von Intel gibt es jetzt ein Modul DNN (Deep Neural Network).
Einf¨ uhrung (11)
2. Neuronale Netze, nahe an der Biologie
Gr¨oßtes Beispiel in der EU: Das Human Brain Project https://www.humanbrainproject.eu/de
• Gestartet in 2013, F¨ordersumme 1,2 Milliarden Euro
• 6 Segmente: Neuroinformatik, Medizinische Informatik, Gehirn- simulation, Supercomputing, Neuronales Rechnen und Neuro- robotik.
• Beispiel BrainScaleS-System, Heidelberg. 20 Silizium-Wafer mit je knapp 200.000 Neuronen, ca. 58 Millionen Synapsen.
12
Einf¨ uhrung (12)
• Beispiel SpiNNaker-Projekt, Manchester. 1.036.800 Arm9-Kerne Jeder Kern simuliert Neuronen und 6 Synapsen.
http://apt.cs.manchester.ac.uk/projects/SpiNNaker/
In Betriebnahme 11.2018. Par- allele Kommunikationsarchitektur, dem Gehirns nachgebildet. Der Computer verteilt Millionen kleiner Informationspakete gleichzeitig.
Unabh¨angig von diesem Projekt gibt es jede Menge “kleine” Arbeiten, z.B. unsere hier.
Im folgenden werden diese Projekte nicht weiter betrachtet.
Mathematisches Modell (1)
Mathematisches Modell von neuronalen Netzen
Die klassischen k¨unstlichen Neuronalen Netze vereinfachen das biolo- gische Vorbild so stark, dass
• viele biologische Eigenschaften verloren gehen,
• aber die Grundidee erhalten bleibt und
• eine “schnelle” Berechnung m¨oglich ist.
Mathematisch heißt das, der Weg von der Eingabe eines Neurons zur Eingabe des damit verbundenen Neurons wird durch sehr einfache Funktionen beschrieben.
14
Mathematisches Modell (2)
Ein k¨unstliches neuronales Netz besteht aus folgenden Komponenten 1. Neuronen mit einem Aktivierungszustand ai(t) zum Zeitpunkt t. 2. Eine Aktivierungsfunktion fact, die angibt, wie sich die Aktivierung
in Abh¨angigkeit der alten Aktivierung ai(t), des Inputs neti und eines Schwellwerts Θi mit der Zeit ¨andert.
ai(t + 1) = fact(ai(t), neti(t),Θi).
3. Eine Ausgabefunktion fout, die aus der Aktivierung des Neurons den Output berechnet
oi = fout(ai).
Mathematisches Modell (3)
4. Ein Verbindungsnetzwerk mit den Koppelungen wi,j (Gewichtsma- trix).
5. Eine Propagierungsfunktion, die angibt, wie sich die Netzeingabe aus den Ausgaben der anderen Neuronen berechnet, meist einfach
netj(t) = X
i
oi(t)wi,j
6. Eine Lernregel, die angibt, wie aus einer vorgegebenen Eingabe eine gew¨unschte Ausgabe produziert wird. Dies erfolgt meist ¨uber eine Modifikation der St¨arke der Verbindungen als Ergebnis wie- derholter Pr¨asentation von Trainingsmustern.
Auf diese Weise werden die “Zust¨ande” ge¨andert, bis ein stabiler (und hoffentlich erw¨unschter) Endzustand eintritt, welcher in gewisser Wei- se das Ergebnis der Berechnungen eines neuronales Netzes darstellt.
16
Mathematisches Modell (4)
In vielen Anwendungen wird die Zeitabh¨angigkeit, z.B. bei der Ob- jekterkennung weggelassen und es werden ganz einfache Funktionen verwendet:
• Die Ausgabefunktion ist einfach
oj = fout(aj) = aj
• Propagierungsfunktion lautet
netj = X
i
oiwi,j
• Die Ausgabe berechnet sich dann ¨uber
oj = aj = fact(netj,Θj)
wobei f¨ur fact eine Stufenfunktion, der Tangens Hyperbolicus, die logistische Funktion oder zur Zeit besonders die ReLU-Funktion (rectified linear unit) popul¨ar sind.
Mathematisches Modell (5)
Stufenfunktion:
oj = fact(netj,Θj) ==
( 1 falls netj ≥ Θj 0 sonst
Tangens Hyperbolicus
oi = tanh(c(neti − Θi)). Logistische Funktion oder Sigmoidfunktion
oi = 1/(1 + exp(−c(neti − Θi)))
Die Konstante c beeinflusst die Steigung der Funktionen.
Mathematisches Modell (6)
-1 -0.5 0 0.5 1 1.5
-1 -0.5 0 0.5 1 1.5 2 2.5 3
output
input
Aktivierungsfunktionen Stufenfunktion Tangens Hyperbolicus Logistische Funktion
Hier wurde c = 5 und Θ = 1 verwendet. Meist wird aber c = 1 gesetzt.
19
Mathematisches Modell (7)
Die ReLU-Funktion, oder ‘leaky ReLU-Funktion ist einfach
f(x) =
x if x > 0 a otherwise
-0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4
-1.5 -1 -0.5 0 0.5 1 1.5
output
input
Aktivierungsfunktion Leaky ReLU
Hier wurde a = 0.02 und Θ = 0 verwendet. Die Funktion ist absolut
“unbiologisch”, aber sie funktioniert h¨aufig sehr gut, z.B. bei Netzen zur Objekterkennung, und ist extrem schnell zu berechnen!
Mathematisches Modell (8)
Beispiel: Ein nettes kleines bekanntes Netz mit wenigen Verbindungen und welches im Kopf nachzurechnen ist, ist das XOR-Netzwerk mit 4 Neuronen.
1.5 0.5
1
-2
1
1 1
n1 n2
n3 n4
Die Neuronen beinhalten die Schwellwerte, die Verbindun- gen sind mit den Gewichten beschriftet.
Als Aktivit¨atsfunktion bzw. f¨ur die Ausgabe wird eine Stufenfunktion gew¨ahlt
21
Mathematisches Modell (9)
Weiterhin wird die standardm¨aßige Propagierungsfunktion verwendet netj = X
i
oiwi,j
also gilt
oj =
( 1 falls Pi oiwi,j ≥ Θj
0 sonst .
Aus der folgenden Tabelle ist die Funktionsweise des Netzes ersicht- lich:
o1 o2 net3 Θ3 o3 net4 Θ4 o4
0 0 0 1.5 0 0 0.5 0
0 1 1 1.5 0 1 0.5 1
1 0 1 1.5 0 1 0.5 1
1 1 2 1.5 1 0 0.5 0
Mathematisches Modell (10)
Beschr¨ankt man sich auf ebenenweise verbundene feedforward-Netze, so wird f¨ur die XOR-Funktion ein weiterer verdeckter Knoten ben¨otigt.
0.5
0.5
1 1
-1 -1
n1 n2
n3
n5
n4 0.5
1 1
Eine kleine ¨Ubungsaufgabe: Wie sieht die zugeh¨orige Tabelle von Eingabe zur Ausgabe aus?
23
Mathematisches Modell (11)
Eingabeschicht: o1,o2
Aktivierungsfunktion: tanh(x) net1 = o1w11 + o2w21 + Θ1 net2 = o1w12 + o2w22 + Θ2 o′1 = tanh(net1)
o′2 = tanh(net2)
neto = o′1w1o + o′2w2o + Θo
oo = tanh(neto) n_1 n_2
n_1
n_o
n_2 w_11
θ_1 θ_2
θ_ο
w_12 w_21 w_22 w_2o
w_1o
’ ’
Insgesamt ergibt sich die Funktion
oo = tanh( ( tanh(o1w11 + o2w21 + Θ1 ) w1o +
( tanh(o1w12 + o2w22 + Θ2 ) w2o + Θo
Aufgabe des “Lernens”: Bestimmung der 9 Parameter w11, w12, w21, w22, w1o, w2o,Θ1,Θ2,Θo, so dass sich f¨ur alle m¨oglichen Werten o1, o2 die gew¨unschten oo ergeben.
Darstellung von neuronalen Netzen (1)
Ein neuronales Netz ist ein Graph mit Kanten und Knoten. Neuronen bzw. Zellen sind aktive Knoten oder Berechnungseinheiten, die lokal auf Eingaben reagieren und Ausgaben produzieren, die ¨uber die Kanten weiter gegeben werden.
Eine andere Darstellung besteht aus Matrizen oder allgemeiner aus Feldern mit mehreren Indices oder Tensoren:
• Verbindungsmatrix w[Ebene][Ausgangsneuron][Eingangsneuron]
• Schwellwertmatrix Θ[Ebene][N euron]
• Eingangsmatrix net[[Ebene][N euron]
Rechnungen erfolgen durch Neuberechnung der Ausgabematrix o[Ebene][N euron].
Oft kommt bei ein weiterer Index f¨ur das Eingabemuster hinzu.
25
Darstellung von neuronalen Netzen (2)
Tensoren: Tensoren sind Gr¨oßen aus der linearen Algebra, um Objekte aus der linearen Algebra in ein einheitliches Schema einzuordnen.
Tensoren haben Indizes. Die Anzahl der Indizes gibt den Rang oder die Stufe des Tensors an.
• Tensoren nullter Stufe sind Skalare
• Tensoren erster Stufe sind Vektoren
• Tensoren zweiter Stufe sind Matrizen
Neuronale Netze werden durch Tensoren beschrieben, deshalb nennt Google seine Softwarebibliothek Tensorflow und seinen Spezialpro- zessor Tensorprozessor.
Arten von Verbindungsnetzwerken: Je nach Netztopologie und der Art der Verarbeitung der Aktivit¨atswerte werden verschiedene neuro- nale Netze unterschieden.
Darstellung von neuronalen Netzen (3)
Eine Einteilung nach R¨uckkopplung:
1. Netze ohne R¨uckkopplung (feedforward-Netze),
• Ebenenweise verbundene feedforward-Netze
• Allgemeine feedforward-Netze 2. Netze mit R¨uckkopplung,
• Netze mit direkter R¨uckkopplung (direct feedback, zur¨uck zu Eingabeknoten),
• Netze mit indirekter R¨uckkopplung (indirect feedback, zur¨uck zu Zwischenknoten),
• Netze mit R¨uckkopplung innerhalb einer Schicht (lateral feed- back),
• Vollst¨andig verbundene Netze (lateral feedback).
27
Darstellung von neuronalen Netzen (4)
2 Beispiel-Topologien und ihre Verbindungsmatrizen:
1 2
3 4 5
6 7
1 2
3 4 5
6 7
feedforward, ebenenweise verbunden
vollständig verbunden, ohne direkte
Rückkopplung
Darstellung von neuronalen Netzen (5)
Zwei zur Zeit h¨aufig angewendete Architekturen
• Feedforward Networks (FFN), meist in der Form sogenannter Mul- tilayer Perceptrons (MLP) oder in der Form von Convolution Neural Networks (CNN) (Faltungsnetze, ¨uberlappende Teilbereiche), z.B.
in der Bildverarbeitung.
• Rekurrent Neuronal Networks (RNN), also solche mit R¨uckw¨arts- verbindungen, z.B. in der Form von Long Short Term Memory Networks (LSTM) f¨ur handgeschriebene Texte oder in der Spra- cherkennung.
Diese Architekturen und deren Anwendung werden in den letzten Jah- ren fast ¨uberall diskutiert, z.B. seit ein paar Jahren auch in Zeitschrif- ten wie C’t
29
Darstellung von neuronalen Netzen (6)
Beispiel eines feedforward Netzes, ein multiplayer Perceptron f¨ur eine Klassifizierung:
o1
Eingabe
Ausgabe
om
ω11
ω1i
ω1n
x1 xi
xn
Eingabe z.B. Pixel eines Bildes (Ge- sicht, Zahl, Tier ...
Ausgabe ein Neuron pro Name, pro Zahl, Art des Tiers ...
Darstellung von neuronalen Netzen (7)
Das Sch¨one an einem solchen Netz ist folgendes:
Wenn die Parameter, also die Gewichte wi,j und die Schwellwerte Θi gut bestimmt wurden, gilt:
• kleine ¨Anderungen des Netzes (Verbindungen defekt)
• oder kleine Eingabe¨anderungen (Bild verrauscht)
→ kleine ¨Anderung der Ausgabewerte
→ Bild wird h¨ochst wahrscheinlich trotzdem erkannt, da das gleiche Neuron den gr¨oßten Wert haben wird.
31
Lernen (1)
Wie werden gute Parameter bestimmt oder woher “weiß” ein Netz, welches Neuron bei welchem Bild aktiv sein soll?
M¨ogliche Arten des Lernens
1. Entwicklung neuer Verbindungen 2. L¨oschen existierender Verbindungen
3. Modifikation der St¨arke von Verbindungen 4. Modifikation der Schwellwerte der Neuronen
5. Modifikation der Aktivierungs-, Propagierungs- oder Ausgabefunk- tion
6. Entwicklung neuer Neuronen 7. L¨oschen von Neuronen
Lernen (2)
Lernverfahren
Meist wird die Modifikation der St¨arke von Verbindungen wi,j verwen- det, da diese Verfahren am einfachsten sind und die Entwicklung bzw.
das L¨oschen von Verbindungen mit eingeschlossen werden kann.
Prinzipiell werden 3 Arten von Lernverfahren unterschieden:
1. ¨Uberwachtes Lernen, bei dem einem Netzwerk zu einem Input ein gew¨unschter Output gegeben wird, nach dem es sich einstellt.
2. Best¨arkendes Lernen, bei dem zu einem Input die Information, ob der Output richtig oder falsch ist, in das Netz zur¨uckgegeben wird.
3. Un¨uberwachtes Lernen, bei dem sich das Netz selbst organisiert.
Am h¨aufigsten ist das ¨uberwachte Lernen. Von den verschiedenen Lernmethoden wird hier nur das klassische Backpropagation-Verfahren vorgestellt.
33
Lernen (3)
Hebbsche Lernregel
Die einfachste Lernregel, die heute noch Grundlage der meisten Lern- regeln ist, wurde 1949 von Donald O.Hebb entwickelt.
Wenn Neuron j eine Eingabe von Neuron i erh¨alt und beide gleichzei- tig stark aktiviert sind, dann erh¨ohe das Gewicht wij, die St¨arke der Verbindung von i nach j.
∆wij = ηoiaj
Die Konstante η wird als Lernrate bezeichnet. Verallgemeinert lautet die Hebbsche Regel
∆wij = ηh(oi, wij)g(aj, tj)
tj ist die erwartete Aktivierung (teaching input), ein Parameter der Funktion g. Fast alle Lernregeln sind Spezialisierungen der Funktionen h und g.
Perzeptron (1)
Im folgenden werden wir uns aus Zeitgr¨unden nur eine Art von Netz mit einer Lernregel genauer ansehen, ein feedforward Netz in der Art des multiplayer Perzeptrons mit der Backpropagation-Lernregel.
Ursprung hat das Perzeptron aus der Analogie zum Auge, bei dem die Retina die Input-Neuronen beinhaltet, von der ¨uber eine Zwi- schenschicht eine Klassifikation der einzelnen Bilder in der Ausgabe- schicht erfolgt.
Dementsprechend werden solche Netze z.B. in der Steuerung auto- nomer Fahrzeuge eingesetzt.
Ausgabeneuron (Lenkung)
Eingabeneuronen (Straßenbild+entfernungen)
35
Perzeptron (2)
Aufbau:
• Es gibt eine Input-Schicht
• Es gibt keine, eine oder mehrere verborgene Schichten (hidden layer)
• Es gibt eine Ausgabe-Schicht
• Die Kanten verbinden die Schichten eine nach der anderen in der gleichen Richtung untereinander, d.h. die Informationen aller Kno- ten der Input-Schicht laufen in die selbe Richtung, nicht zur¨uck und nicht zwischen den Knoten einer Schicht.
In einigen F¨allen wird der Begriff Perzeptron enger als feedforward- Netz mit keiner oder einer verborgenen Schicht verwendet.
Backpropagation-Regel (1)
• Gegeben sind Eingabewerte, z.B. der MNIST-Datensatz∗ mit 60000 Bilder der Gr¨oße 28x28 Pixel, auf denen handgeschriebene Ziffern abgebildet sind, ein Standard-Benchmark f¨ur Neuronale Netze.
• Das ergeben 784 Eingabeknoten und 10 Ausgabeknoten, f¨ur jede Ziffer einer.
• Ziel ist es, f¨ur ein gegebenes Bild p die Funktionen, die die Ausga- be op des Netzes berechnen, so zu bestimmen, dass z.B. nur der Knoten, der der dem Bild entsprechenden Ziffer zugeordnet ist, einen Wert 1 hat und alle anderen Ausgabeknoten einen Wert 0 haben, was dann die gew¨unschten Ausgabewerte tp f¨ur dieses Bild w¨aren (es gibt auch andere Zuordnungen).
∗http://yann.lecun.com/exdb/mnist/
37
Backpropagation-Regel (2)
• Ein Maß f¨ur die Abweichung des berechneten von dem gew¨unsch- ten Ergebnis ist die Summe der quadratischen Abweichungen ¨uber alle Bilder p und alle Ausgabeneuronen j: das Fehlerfunktional
E =
P X p=1
Ep Ep = 1 2
nout X
j
op,j − tp,j2
• Die Funktionen, die die Ausgaben op,j berechnen, h¨angen von den Gewichten der Verbindungen zwischen den Knoten und den Schwellwerten der einzelnen Knoten ab.
• Backpropagation ist ein Gradientenabstiegsverfahren, bei dem die Gewichte und Schwellwerte so ge¨andert werden, dass das Fehlerfunktional (oder die Energiefunktion) minimiert wird.
Backpropagation-Regel (3)
Numerik bei mir: lineare Ausgleichsrechnung
Definition (Ausgleichsproblem)
Gegeben sind n Wertepaare (xi, yi), i = 1, . . . , n mit xi 6= xj f¨ur i 6=
j. Gesucht ist eine stetige Funktion f, die in einem gewissen Sinne bestm¨oglich die Wertepaare ann¨ahert, d.h. dass m¨oglichst genau gilt:
f(xi) ≈ yi f¨ur i = 1, . . . , n.
39
Backpropagation-Regel (4)
Numerik bei mir: lineare Ausgleichsrechnung
Statistik, 3. Semester: Methode der kleinsten Quadrate
Definition (Fehlerfunktional)
Gegeben sei eine Menge F von stetigen Funktionen sowie n Wertepaa- re (xi, yi), i = 1, . . . , n. Ein Element von f ∈ F heißt Ausgleichsfunktion von F zu den gegebenen Wertepaaren, falls das Fehlerfunktional
E(f) =
n X i=1
(f(xi) − yi)2
f¨ur f minimal wird, d.h. E(f) = min{E(g)|g ∈ F}. Die Menge F nennt man auch die Menge der Ansatzfunktionen.
Es werden also die Parameter der Funktion f(x) so bestimmt, so dass die Funktion m¨oglichst dicht an den Punkten liegt.
Backpropagation-Regel (4)
Ist die Funktion f(xi) linear in den Parametern, also f(x) = Ppk=1 akgk(x), so l¨asst sich das Minimum des Fehlerfunktionals ¨uber die Nullstelle der Ableitungen von E(f) durch L¨osen einer linearen Gleichung f¨ur die Pa- rameter ak bestimmen.
Jetzt:
• Jedem x-Wert entspricht einem Satz von Eingabewerten bzw. ein Eingabe-”Pattern” inp,i mit i ≤ 1 ≤ nin Werten.
• Jedem y-Wert entspricht einem Satz von Ausgabewerten bzw.
Ausgabe-”Pattern” tp,j mit j ≤ 1 ≤ nout Werten.
• Die Ausgleichsfunktion f(x) ist jetzt ein Satz von nicht-linearen Funktionen in einer Anzahl von Parameter, z.B. in den Gewichten des neuronalen Netzes: fi,j(inp,i, wi,j) = op,j.
41
Backpropagation-Regel (5)
• Dann lautet das Fehlerfunktional, die Summe der quadratischen Abweichungen anstatt
E =
n X i=1
Ei Ei = (f(xi) − yi)2 jetzt
E = X
p
Ep Ep = 1 2
nout X
j
op,j − tp,j2
• Gesucht in dem nicht-linearen Ausgleichsproblem: das Minimum von E als Funktion der nicht-linearen Parameter.
• Hinweis: H¨aufig werden auch andere Fehlerfunktion verwendet.
Das Minimum kann nicht exakt bestimmt werden, sondern es wird ge- sucht, in dem z.B. die Parameter entlang der negativen Steigung des Fehlerfunktionals ge¨andert wird ⇒ Backpropagation oder Gradienten- abstiegsverfahren.
Backpropagation-Regel (6)
0 1 2 3 4 5 6 7 8
0 2 4 6 8 10 12 14 16
error
wi,j
Fehlerfunktion fuer ein Gewicht wi,j
Die Aufgabe ist es ein m¨oglichst gutes Minimum zu finden.
Problem: Das funktioniert nur gut, wenn die Startwerte in der N¨ahe eines guten Minimums sind.
43
Backpropagation-Regel (7)
Vor der Ableitung des Algorithmus ist eine Vereinheitlichung der No- tation von Vorteil: Der Schwellwert-Wert eines Knotens wird interpre- tiert als eine Verbindung zu dem Knoten von einem Konten mit dem Ausgabewert 1 und einem Gewicht.
Mit wn+1,j = −Θj und on+1 = 1 gilt
n X i=1
oiwi,j − Θj =
n+1 X i=1
oiwi,j ≡ netj(t)
Backpropagation-Regel (8)
Der Backpropagation-Algorithmus ¨andert die Gewichte wi,j von einem Knoten i zu einem Knoten j entlang des negativen Gradienten der Fehlerfunktion, bis diese (hoffentlich) minimal ist.
∆wij = −η X
p
∂Ep
∂wij.
Zur Berechnung der Ableitungen nochmal die Formal f¨ur das XOR- Problem mit 2 versteckten Kno- ten (Schwellwerte werden Bias- Konten und die Aktivierungsfunkti- on fact(x) = tanh(x) wird allgemein geschrieben).
Eingabeschicht: o1,o2
net1 = o1w11 + o2w21 + w31 net2 = o1w12 + o2w22 + w23 o′1 = fact(net1)
o′2 = fact(net2)
neto = o′1w1o + o′2w2o + w3o oo = fact(neto)
45
Backpropagation-Regel (8)
Zerlege die Ableitung des Fehlerfunktionals nach den Gewichten in einzelne Schritte:
Ableitung nach den Gewichten zur Ausgabeschicht: Der Fehler h¨angt ab oo, das wiederum von neto, das wiederum von wio ab.
Ableitung nach den Gewichten zur verdeckten Schicht: Der Fehler h¨angt ab oo, das wiederum von neto, das wiederum von o1, o2, das wiederum von net1, net2 und das von wi1
Verwende die Kettenregel, zuerst f¨ur den letzten Schritt:
∂Ep
∂wij = ∂Ep
∂netpj
∂netpj
∂wij .
Backpropagation-Regel (8)
Der erste Faktor wird als Fehlersignal bezeichnet δpj = − ∂Ep
∂netpj und der zweite Faktor ist
∂netpj
∂wij = ∂
∂wij
X k
opkwkj = opi.
Die ¨Anderung der Gewichte berechnet sich dann durch
∆wij = η X
p
opiδpj
Bei der Berechnung von δpj geht die konkrete Aktivierungsfunktion ein, also wie das Neuron j den Input in einen Output verwandelt.
δpj = − ∂Ep
∂netpj = −∂Ep
∂opj
∂opj
∂netpj = −∂Ep
∂opj
∂fact(netpj)
∂netpj = −∂Ep
∂opjfact′ (netpj).
47
Backpropagation-Regel (9)
F¨ur den ersten Faktor muss zwischen den Ebenen, in denen sich die Knoten befinden, unterschieden werden.
1. j ist Index eines Ausgabeneurons. Dann gilt
−∂Ep
∂opj = −1 2
∂
∂opj
nout X
k
op,k − tp,k2 = (tpj − ooj). Der Gesamtfehler ist in diesem Fall
δpj = fact′ (netpj) · (tpj − ooj)
2. j ist Index eines Neurons der verdeckten Ebenen. Die Fehlerfunk- tion h¨angt von den Output oj indirekt ¨uber die Zwischenzellen k ab, denn der Output oj geht in den Input netpk von allen Knoten k eine Schicht “h¨oher” ein.
Backpropagation-Regel (10)
−∂Ep
∂opj = −X
k
∂Ep
∂netpk
∂netpk
∂opj
= X
k
δpk ∂
∂opj
X i
opiwik
= X
k
δpkwjk
Das bedeutet, dass man den Gesamtfehler des Neurons j f¨ur ein Muster p aus den gewichteten Fehlern δpk aller Nachfolgezellen k und der Gewichte der Verbindungen von j zu diesen k berechnen kann.
δpj = fact′ (netpj) · X
k
δpkwjk
Zusammengefasst
∆wi,j = η X
p
op,ifact′ (netpj) ·
(tpj − ooj) falls j Ausgabeneuron
Pk δpkwjk falls j verdecktes Neuron
49
Backpropagation-Regel (11)
Meist wird als Aktivierungsfunktion die logistische Funktion verwendet mit der Ableitung
d
dxflog(x) = d dx
1
1 + e−x = flog(x) · (1 − flog(x))
Damit ergibt sich eine vereinfachte Formel f¨ur den Backpropagation Algorithmus
∆pwij = ηopiδpj mit dem Fehlersignal
δpj =
( opj(1 − opj)(tpj − opj) falls j Ausgabeneuron opj(1 − opj) Pk δpkwjk falls j verdecktes Neuron
)
Backpropagation-Regel (12)
Beispiel: Netz mit 3 Ausgabeknoten n1, n2 und n3
n7 n4
n1 n2 n3
W
W74 42
∆w4j = ηo4δj = ηo4(tj − oj) ∗ f′(netj), j = 1,2,3
∆w74 = ηo7δ4 = ηo7(−
3 X j=1
δjw4j)f′(net4)
51
Backpropagation-Regel (13)
Das Verfahren zusammengefasst
1. Berechne bei einem gegebenem Input den Output oder “Propa- gierung” ein Signales ¨uber die Schichten:
• Die Ausgaben der Neuronen i (oder die Werte der Inputneu- ron i) einer Schicht werden an die Eingaben der Knoten j der n¨achsten Schicht weitergeleitet ¨uber
netj(t) =
n+1 X i=1
oiwi,j
• Die Knoten j berechnen die Ausgabe, die eventuell an die n¨achs- te Schicht weiter geleitet wird, ¨uber
oj = fact(netj)
• Ist man an der Ausgabeschicht angekommen, ¨uberpr¨ufe, ob das Eingabesignal erkannt wird, also berechne den Fehler bzw. das Fehlerfunktional.
Backpropagation-Regel (14)
2. Ist der Fehler zu groß, f¨uhre eine R¨uckpropagierung durch.
• Berechne das Fehlersignal, von der Ausgabeschicht beginnend r¨uckw¨arts bis zur Eingabeschicht.
• Berechne die Korrektur der Gewichte gem¨aß
∆pwij = ηopiδpj
3. Beginne mit der Prozedur von vorne, bis der Fehler (hoffentlich) klein geworden ist, also die Eingaben gelernt wurden.
53
Backpropagation-Regel (15)
Das Beispiel vom Anfang:
oo = tanh( ( tanh(o1w11 + o2w21 + Θ1 ) w1o + ( tanh(o1w12 + o2w22 + Θ2 ) w2o + Θo
• Ableitung der Aktivierungsfunktion: tanh′ = (1 − tanh2)
• “Fehler” bei der Ausgabe: to − oo
• Fehlersignal am Ausgabeknoten no: δo = (1 − o2o)(to − oo)
• Korrektur der Gewichte vom verdeckten Konten ni zum Ausgabe- knoten no: ∆wi,o = ηoiδo
• “Fehler” beim verdeckten Knoten nj: δowj,o
• Fehlersignal am verdeckten Knoten nj: δj = (1 − o2j)δowj,o
• Korrektur der Gewichte vom Eingangkonten ni zum verdeckten Knoten nj: ∆wi,j = ηoiδj
Backpropagation-Regel (16)
Probleme:
a) Bei zu kleinen Lernraten geht der Algorithmus nicht ¨uber das lokale Mi- nimum hinaus.
b) Kleine Gradienten wie bei Plateaus sorgen f¨ur eine erhebliche Mehrzahl an notwendigen Iterationsschritten.
c) Ungeeignete Wahl einer Lernrate bei zu großen Gradienten bewirkt Os- zillation des Lernprozesses
d) oder unter Umst¨anden ein ¨Uber- springen des globalen Minimums hin zu einem lokalen.
55
Backpropagation-Regel (17)
Noch zu beachten:
• Werden f¨ur jede Eingabe einzeln neue Gewichte berechnet, spricht man von online-learning.
• Werden erst die Fehler f¨ur alle Eingaben aufsummeriert (so wie in der Herleitung), heißt das batch-learning.
• Meist werden die Fehler f¨ur Bl¨ocke von Eingaben und damit Kor- rekturen f¨ur die Gewichte berechnet.
• F¨ur die Initialisierung der Gewichte gibt es verschiedene Methoden, am einfachsten sind gleichverteilte oder Gauß-verteilte Zufallszah- len.
• Die Lernrate sollte kleiner werden mit kleiner werdendem Fehler.
• ... und vieles mehr.
CNN (1)
Neben den Multilayer Perceptrons sind heute die meist verwendeten Netze Faltungsnetze bzw. Convolution Neural Networks (CNN).
• Die meisten Daten liegen in “Gittern” vor (Bilder bei der Bilderken- nung, 2 Dimensionen, Pixel, oder T¨one bei der Spracherkennung, diskrete Zeitabst¨ande, Frequenzen, 1 Dimension)
• Die Daten sind “translationsinvariant”, d.h. eine Katze unten rechts im Bild muss genauso erkannt werden wie oben links im Bild.
• Ein Gesamtbild setzt sich aus lauter benachbarten Einzelteilen zu- sammen, mehrere “benachbarte” T¨one werden zu einem Wort, mehrere benachbarte Ausschnitte eines Bildes werden zu einem Objekt.
57
CNN (2)
Idee:
• Betrachte nicht von einem Punkt (Neuron) Verbindungen zu allen anderen (Neuronen der dar¨uber liegenden Schicht), sondern nur lokale Gruppen.
• Verwende die gleiche Gewichtsmatrix von allen Punkten aus (Fal- tung)
a b c a b c a b c a b c a b c
CNN (3)
Die Gewichtsmatrizen werden als Filter oder Kernel bezeichnet und es werden mehrere unterschiedliche Filter verwendet, die jeweils zu einer eigenen dar¨uber liegenden Schicht f¨uhren.
2 6 3 8
5 2 1
7 3
1 5 5
a b
d c
2*a+6*b+
1*c+5*d
6*a+3*b+
5*c+5*d
3*a+8*b+
5*c+5*d
1*a+5*b+
3*c+7*d
5*a+5*b+
7*c+1*d
5*a+5*b+
1*c+2*d
4 × 3 Eingangsbild, ein 2 × 2 CNN- Kernels mit den Parametern a,b,c,d, die gelernt werden.
3 × 2 Ausgaben.
59
CNN (4)
• Werden mehrere dieser Faltungsschichten hintereinander geh¨angt, vergr¨oßert sich der Bereich immer weiter, der Einfluss auf das Ergebnis hat.
• N¨utzlich ist es sogenannte Pooling-Schichten zu verwenden, die die Ergebnisse von benachbarten Neuronen zusammenfassen, z.B. den Mittelwert oder den maximalen Wert nehmen und weiter leiten.
2 0 1 7
8 6 1 5
5 2
4
0 6 3
3 1
6 8
6 5
4 × 4 Eingangs- bild, Max-Pooling Schicht, Filter-
maske 2 und
Schrittgr¨oße 2. 2×2 Ausgaben.
CNN (5)
Am Ende gibt es dann
• bei einem Klassifizierungsproblem f¨ur jedes Objekt ein Output- Neuron
• oder z.B. bei einem Segmentierungsproblem, also welches Pixel eines Bildes geh¨ort zu welchem Objekt f¨ur jedes Pixel so viele Output-Neuronen, wie es Klassen gibt.
Viele weitere Details sind f¨ur ein sinnvolles Netz notwendig, aber diese Netze machen auch nichts anderes als eine Kurve an Daten anzupassen.
61
Ausblick (1)
Verbesserungen:
“Intelligentere” Netze und Algorithmen + schnelle Hardware.
• weitere Formen von Faltungsnetzen / rekurrente Netze (mit Zeit- abh¨angingkeit)/ Deep Belief Netze und viele mehr
• Stochastische Modelle
• Verbesserte Gradientenverfahren
• Genetische Algorithmen und anderes zur Netzverbesserung
• ...
• Graphikkarten
Frage: Was lernt das Netz?
Ansatz: R¨uckverfolgung des Gelernten ¨uber die Schichten.
Bei diesen Versuchen hat Google direkt eine neue Kunstrichtung ins Leben gerufen: Inceptionism∗
∗Computer-Halluzinationen, Spektrum der Wissenschaft, 12/2015, Brian Hayes.
Ausblick (2)
Es fehlen viele “Kleinigkeiten”, die als n¨achstes wichtig f¨ur eine aktu- elle Anwendung, z.B. in der Objekterkennung w¨aren, z.B.:
• Wie sind Faltungsnetze (CNN) in Detail aufgebaut?
• Welche Aktivierungsfunktion ist die geeignetste (LeakyReLU)?
• Welche Fehlerfunktion sollte gew¨ahlt werden (cross entropy)?
• Welchen Lernalgorithmus sollte man nehmen (Adam Algorithmus)?
• Was ist eine gute Initialisierung der Gewichte (Gauß-Verteilung)?
• Wie wird overfitting vermieden (Dropout/L2-Regularisierung/Batch- Norm)?
• ...
Das Anpassen von Kurven an Daten ist nicht trivial, wenn nur wenige Informationen ¨uber die Daten vorliegen, aber meist sehr erfolgreich, wenn viele Daten zur Verf¨ugung stehen!
63