Algorithms on Pixelized Images of Air Cherenkov Telescopes
62
0
0
Volltext
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(32)
(33)
(34)
(35)
(36)
(37)
(38)
(39)
(40)
(41)
(42)
Abbildung
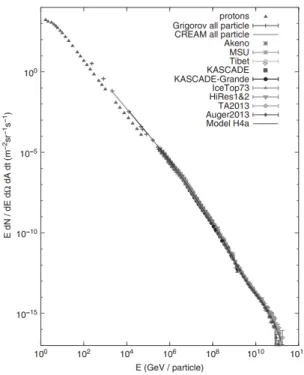
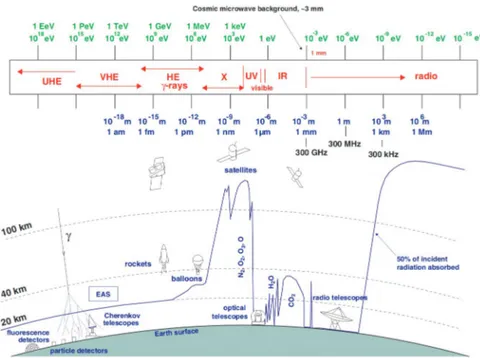
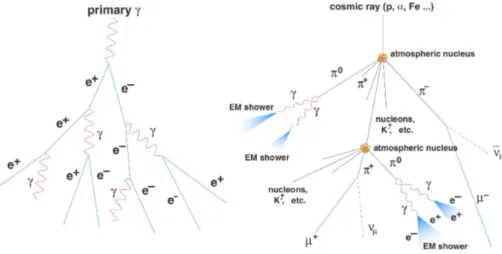

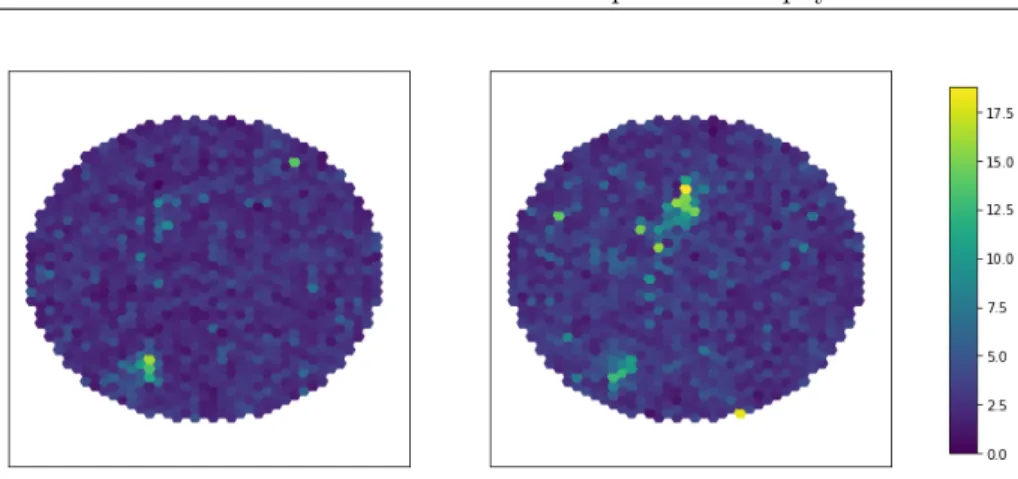
+7

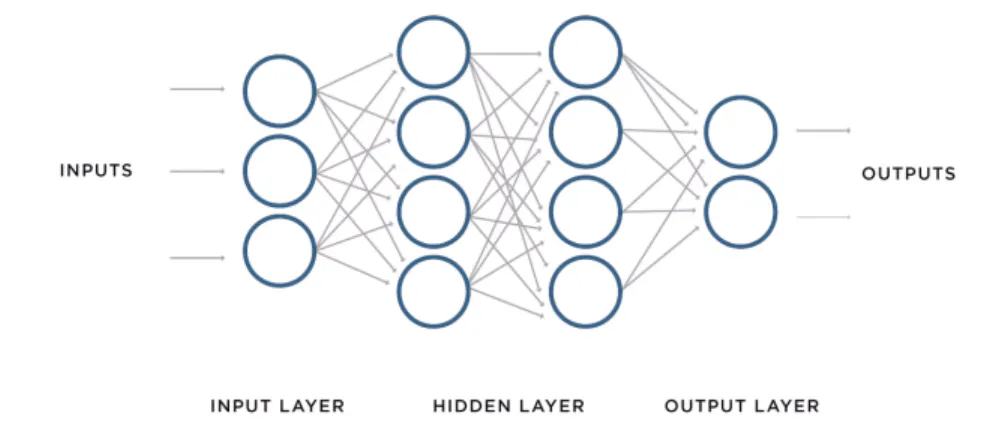
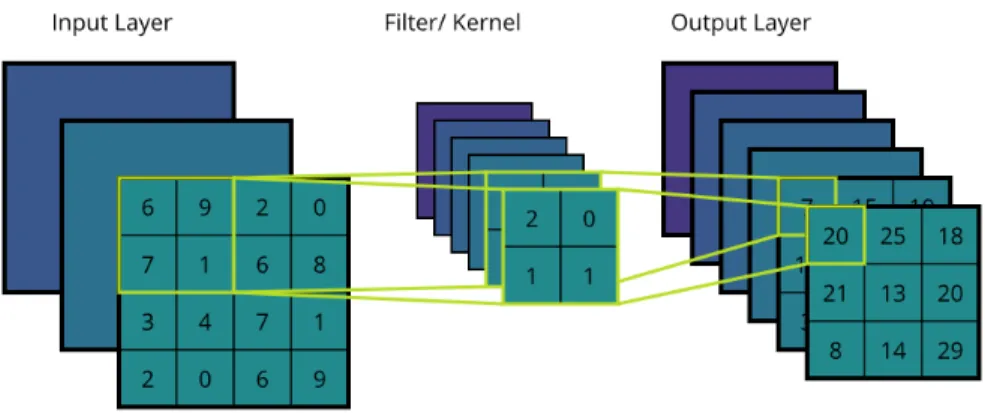
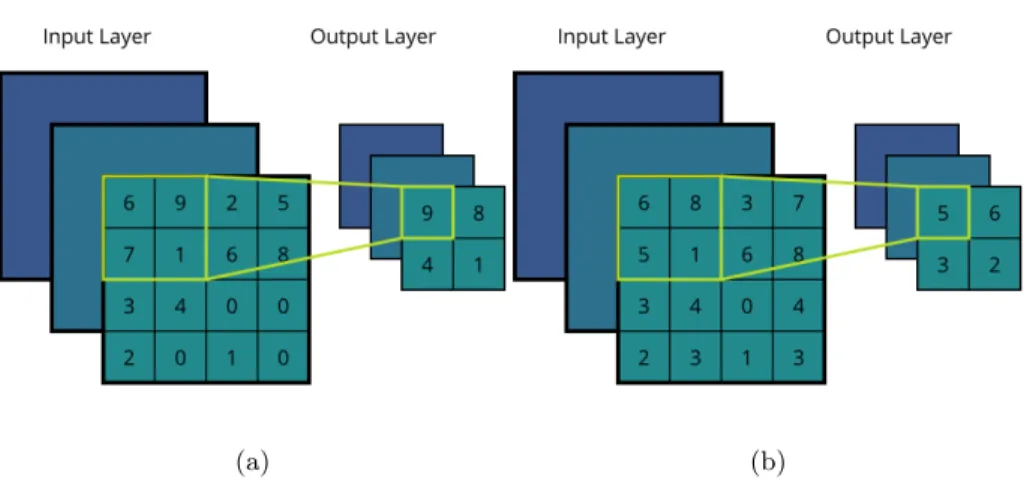
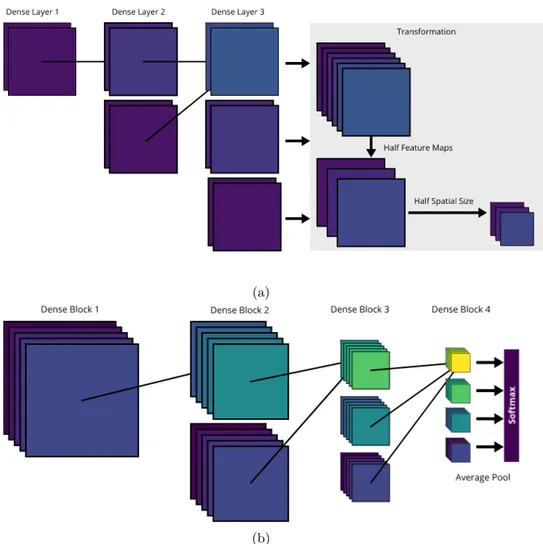
ÄHNLICHE DOKUMENTE
Общие конструкции применяются к задаче моделирования процесса загрязнения грунтовых вод, для которой исследуется проблема
where 7 > 0 is some number which depends on the known parameters of the problem, but not on number k.. The theorem is prooved.. When dealing with concrete problems
It becomes clear that for a sufficiently wide class of inverse problems, a control law for the model can be chosen in such a way that a control realization approximates
Transfer these + hits in 4 th layer to GPU Positive tracks Negative tracks Select combinations of 2 positive, 1 negative track from one vertex, based on
From Switching board: get 50 ns time slices of data containing full detector information..
From Switching board: get 50 ns time slices of data containing full detector information. 2844
If all cuts passed: Count triplets and save hits in global memory using atomic function. Copy back global
It proceeds by (i) comparing the performance of all considered tempo- ral regularization types in a phantom compliant with the optical flow model and without noise, (ii) considering
