d i s s . e t h n o . 2 7 3 6 8
D O M A I N A D A P TAT I O N I N N E U R A L Q U E S T I O N A N S W E R I N G
A dissertation submitted to attain the degree of d o c t o r o f s c i e n c e s of e t h z u r i c h
(Dr. sc. ETH Zurich)
presented by
b e r n h a r d k r at z wa l d MSc ETH CS, ETH Zurich
born on 22 . 02 . 1991 citizen of Austria
accepted on the recommendation of Prof. Stefan Feuerriegel, examiner
Prof. Huan Sun, co-examiner
2021
Bernhard Kratzwald: Domain Adaptation in Neural Question Answering, ©
2021
To my parents
For your advice, your support, your patience.
Because you always believed in me.
A B S T R A C T
Question Answering (QA) is the task of automatically deriving answers from natural language questions. It fundamentally redefines how humans interact with information systems by replacing keyword search or technical queries with interactions in natural language. The recent advancement of deep learning and neural networks has lead to significant performance gains in QA. Yet, the performance of QA systems often drops significantly when they are subject to a domain shift, i. e., questions used to train the system differ from user questions after deployment. This represents a severe problem in many practical setups, where certain guarantees on the performance are required. Furthermore, it limits the application of QA to areas for which we have access to large amounts of training data; which is primarily open-domain questions in English language.
In this thesis, we present several solutions to tackle the problem of do- main shift in QA. On the one hand, we present two methods designed for a usage before the deployment of a QA system. This includes a method for transfer learning when having only access to a small labeled amount of training data, as well as a method for a cost-effective annotation of new datasets. On the other hand, we present a method for domain customization after deployment. Here, the QA system continuously learns to adapt to the new domain directly from user interactions and is capable to overcome an initially low performance over time. In addition, we present robust architec- tures for QA systems that help in addressing domain shift as a foundation of this thesis. Finally, we show how our methods can be extended to the different but related task of knowledge base completion.
vii
Z U S A M M E N FA S S U N G
Question Answering (QA) ist das Fachgebiet der Computerlinguistik, wel- ches sich mit der automatischen Beantwortung von Fragen in natürlicher Sprache befasst. Durch automatisiertes QA wird die Art und Weise, wie Menschen mit Informationssystemen interagieren grundlegend neu de- finiert: klassische Stichwortsuchen oder technische Datenbankabfragen werden durch Interaktionen in natürlicher Sprache ersetzt. Die jüngsten Erfolge im Bereich “Deep Learning” haben zu erheblichen Performance- steigerungen von QA Systemen geführt. Allerdings sinkt die Leistung von QA Systemen oft erheblich, wenn sie einem so genannten “Domain Shift”
ausgesetzt sind. Zu einem “Domain Shift” kommt es, wenn sich die Fragen, die für den Lernprozess des Systems angedacht waren, erheblich von den Fragen der Systembenutzer_innen unterscheiden. Dies stellt ein schwerwie- gendes Problem in vielen praktischen Einsatzfeldern dar, insbesondere in solchen, in denen bestimmte Garantien für die Leistung eines QA Systems erforderlich sind. Außerdem beschränkt es die Anwendung von QA auf Felder, welche über große Mengen an Trainingsdaten verfügen. Also in erster Linie Fragen über Allgemeinwissen in englischer Sprache.
In dieser Arbeit stellen wir mehrere Lösungsansätze für “Domain Shifts”
in QA vor. Zum einen stellen wir zwei Methoden vor, die bereits während der Entwicklung eines QA-Systems zum Einsatz kommen: einen Ansatz basierend auf “Transfer learning”, der bereits mit einer kleinen Menge an Trainingsdaten arbeiten kann; und einen Ansatz zur kostengünstigen Annotieren neuer Datensätze. Zum anderen stellen wir eine Methode vor, die nach der Bereitstellung des QA Systems zur Anwendung kommt. Hier lernt das QA-System kontinuierlich und direkt von Interaktionen mit Be- nutzer_innen. Es ist dadurch in der Lage, eine anfänglich geringe Leistung im Laufe der Zeit zu verbessern. Darüber hinaus präsentieren wir in die- ser Doktorarbeit robuste Architekturen für QA-Systeme, welche sich bei einem “Domain Shift” als hilfreich erweisen. Schließlich zeigen wir eine Ausdehnung unserer Methoden auf andere Anwendungsbereiche.
ix
A C K N O W L E D G E M E N T S
This thesis would not have been possible without the support of many people.
First, I am thankful for my supervisor Prof. Stefan Feuerriegel who always gave great advice and guidance. For his support and encouragement to conduct research stays abroad, apply for summer schools and grants, and ultimately for his trust in my research.
My co-supervisor Prof. Huan Sun whom I always could approach when I needed feedback or advice. The four months I spend at The Ohio State University visiting her lab were extremely helpful. I have learned a lot.
My working colleagues both at the MIS Chair at ETH and the SunLab at The Ohio State University: Mathias, Tobias, Nicolas, Daniel, Christof, Eva, Malte, Svenja, Arne, Joel, Ziyu, Jie, Zhen, Xiang, Tommy (Xiang), Bernal, Yu Gu. All my co-authors and all the fascinating people that I have had an opportunity to collaborate with over the past years: Suzana, Anna, Nil-Jana, Dennis, and Guo. My friends from the machine learning summer school 2019 in Moscow. I will always be grateful for the things that you have taught me and the support I have received from you.
Prof. Torbjørn Netland, Julian Senoner, and the entire POM Chair. For great collaborations that are allowing me to apply my knowledge in fasci- nating practical applications.
To my Family: Mama, Papa, Barbara, Stefan, Leon, Jonas. Your belief in me is what kept me going – I will be forever grateful. Without your financial support, I would never have reached this point.
Toni, for your everyday support and enduring me at my best and at my worst, for giving me the energy I needed when I had none.
Last but definitely not least: to my friends, you are my constant source of inspiration, my safety net, and my loyal companion. I have nothing but gratitude for you.
xi
C O N T E N T S
1 i n t r o d u c t i o n 1
1 . 1 Motivation . . . . 1
1 . 2 Objectives . . . . 3
1 . 3 Outline . . . . 3
1 . 4 Abstracts of scientific papers . . . . 4
2 a d a p t i v e d o c u m e n t r e t r i e va l f o r d e e p q u e s t i o n a n - s w e r i n g 11 2 . 1 Introduction . . . . 12
2 . 2 Related Work . . . . 12
2 . 3 Noise-Information Trade-Off in Document Retrieval . . . . 14
2 . 4 Adaptive Document Retrieval . . . . 15
2 . 4 . 1 Threshold-Based Retrieval . . . . 16
2 . 4 . 2 Ordinal Regression . . . . 16
2 . 5 Experiments . . . . 17
2 . 5 . 1 Overall Performance . . . . 18
2 . 5 . 2 Sensitivity: Adaptive QA to Corpus Size . . . . 18
2 . 5 . 3 Robustness Check . . . . 20
2 . 6 Conclusion . . . . 20
3 r a n k q a : n e u r a l q u e s t i o n a n s w e r i n g w i t h a n s w e r r e - r a n k i n g 21 3 . 1 Introduction . . . . 22
3 . 2 RankQA . . . . 24
3 . 2 . 1 Module 1 : Information Retrieval . . . . 25
3 . 2 . 2 Module 2 : Machine Comprehension . . . . 25
3 . 2 . 3 Module 3 : Answer Re-Ranking . . . . 25
3 . 2 . 4 Estimation: Custom Loss/Sub-Sampling . . . . 29
3 . 3 Experimental Design . . . . 30
3 . 3 . 1 Content Base and Datasets . . . . 30
3 . 3 . 2 Training Details . . . . 32
3 . 4 Results . . . . 32
3 . 4 . 1 Performance Improvement from Answer Re-Ranking . 33 3 . 4 . 2 Robustness Check: BERT-QA . . . . 35
3 . 4 . 3 Performance Sensitivity to Corpus Size . . . . 36
3 . 4 . 4 Error Analysis and Feature Importance . . . . 39
3 . 5 Related Work . . . . 39
xiii
3 . 5 . 1 Neural Question Answering . . . . 40
3 . 5 . 2 Answer Re-Ranking . . . . 40
3 . 6 Conclusion . . . . 41
4 t r a n s f e r l e a r n i n g f o r e f f i c i e n t d o m a i n c u s t o m i z at i o n 43 4 . 1 Introduction . . . . 44
4 . 2 Background . . . . 46
4 . 2 . 1 Ontology-Based Q&A Systems . . . . 47
4 . 2 . 2 Content-Based Q&A Systems . . . . 47
4 . 2 . 3 Transfer Learning . . . . 49
4 . 3 Methods and Materials . . . . 50
4 . 3 . 1 Metadata Filter: Domain Customization for Informa- tion Retrieval . . . . 51
4 . 3 . 2 Domain Customization through Transfer Learning . . 52
4 . 4 Dataset . . . . 53
4 . 5 Results . . . . 55
4 . 5 . 1 Metadata Filtering . . . . 55
4 . 5 . 2 Answer Extraction Module . . . . 56
4 . 5 . 3 Domain Customization . . . . 58
4 . 5 . 4 Robustness Check: Transfer Learning with Additional Domain Customization . . . . 62
4 . 6 Discussion . . . . 62
4 . 6 . 1 Domain Customization . . . . 62
4 . 6 . 2 Design Challenges . . . . 63
4 . 6 . 3 Implications for Research . . . . 64
4 . 6 . 4 Conclusion . . . . 65
4 . 7 Supplements . . . . 65
4 . 7 . 1 Information Retrieval Module . . . . 65
4 . 7 . 2 Answer Extraction Module . . . . 67
5 l e a r n i n g a c o s t - e f f e c t i v e a n n o tat i o n p o l i c y f o r q a 71 5 . 1 Introduction . . . . 72
5 . 2 Related Work . . . . 74
5 . 3 Proposed Annotation Framework . . . . 75
5 . 3 . 1 Framework Overview . . . . 76
5 . 3 . 2 Annotation Schemes . . . . 76
5 . 3 . 3 Annotation Costs . . . . 77
5 . 4 Learning a Cost-Effective Policy . . . . 78
5 . 4 . 1 Objective . . . . 78
5 . 4 . 2 Annotation Procedure and Learning . . . . 79
5 . 4 . 3 Policy Updates . . . . 79
c o n t e n t s xv
5 . 4 . 4 Model Updates . . . . 82
5 . 5 Experimental Setup . . . . 82
5 . 5 . 1 Datasets . . . . 82
5 . 5 . 2 Baselines . . . . 83
5 . 5 . 3 Implementation Details . . . . 83
5 . 6 Experimental Results . . . . 84
5 . 6 . 1 Performance on Answer Span Annotations . . . . 84
5 . 6 . 2 Cost-Performance Sensitivity Analysis . . . . 86
5 . 6 . 3 Performance on Full Dataset Annotation . . . . 86
5 . 7 Discussion and Future Work . . . . 87
5 . 8 Conclusion . . . . 88
5 . 9 Supplements . . . . 88
5 . 9 . 1 Source Code . . . . 88
5 . 9 . 2 Details on the QA Model . . . . 88
5 . 9 . 3 Details on the Policy Model . . . . 88
5 . 9 . 4 Estimation of Real Annotation Costs . . . . 89
5 . 9 . 5 System . . . . 90
6 l e a r n i n g f r o m o n - l i n e u s e r f e e d b a c k i n q u e s t i o n a n - s w e r i n g 91 6 . 1 Introduction . . . . 92
6 . 2 Related Work . . . . 95
6 . 3 QApedia: Continuous Improvement from User Feedback . . . 97
6 . 3 . 1 Feedback Mechanism through User Interactions . . . . 98
6 . 3 . 2 Content Base . . . . 99
6 . 3 . 3 Continuous Improvement Module . . . . 100
6 . 4 The Question-Answering Module . . . . 103
6 . 4 . 1 P 1 : Document Retrieval . . . . 104
6 . 4 . 2 P 2 : Document Selection . . . . 104
6 . 4 . 3 P 3 : Answer Ranking . . . . 105
6 . 4 . 4 P 4 : Answer Selection . . . . 107
6 . 5 Experimental Setup . . . . 107
6 . 5 . 1 Content Repository . . . . 107
6 . 5 . 2 Question-Answer Corpora . . . . 108
6 . 5 . 3 Simulation of User Interactions . . . . 109
6 . 5 . 4 Clairvoyant, Noisy, and Adversarial Feedback . . . . . 109
6 . 5 . 5 Implementation Details . . . . 110
6 . 6 Results . . . . 111
6 . 6 . 1 Performance Improvements from Shallow User Feed-
back . . . . 111
6 . 6 . 2 Robustness Against Forgetting in Neural QA . . . . . 113
6 . 6 . 3 Performance Under Noisy User Feedback . . . . 114
6 . 6 . 4 Robustness to Adversarial User Feedback . . . . 115
6 . 7 Discussion . . . . 116
7 v e r i f i a b l e i n t e r a c t i v e k n o w l e d g e b a s e c o m p l e t i o n 119 7 . 1 Introduction . . . . 120
7 . 2 Related Work . . . . 122
7 . 3 Preliminaries . . . . 123
7 . 4 IntKB: A Verifiable Framework for Interactive KB Completion 124 7 . 4 . 1 Task Definition . . . . 124
7 . 4 . 2 QA Pipeline for KB Completion . . . . 125
7 . 4 . 3 Answer Triggering . . . . 126
7 . 4 . 4 Entity Linking . . . . 127
7 . 5 Continuous Learning for KB Completion . . . . 127
7 . 5 . 1 Cold-Start: Learning KB Completion from Text . . . . 128
7 . 5 . 2 Continuous Improvement from User Interactions . . . 129
7 . 6 Dataset . . . . 129
7 . 7 Computational Experiments . . . . 130
7 . 7 . 1 Performance on “Known” Subset . . . . 131
7 . 7 . 2 Performance on “Zero-Shot” Subset . . . . 134
7 . 7 . 3 Continuous Learning from User Interactions . . . . 136
7 . 7 . 4 Performance on Answer Back-Linking . . . . 136
7 . 8 Discussion . . . . 137
7 . 9 Supplements . . . . 138
8 d i s c u s s i o n 141
b i b l i o g r a p h y 143
1
I N T R O D U C T I O N
c o n t e n t s
1 . 1 Motivation . . . . 1
1 . 2 Objectives . . . . 3
1 . 3 Outline . . . . 3
1 . 4 Abstracts of scientific papers . . . . 4
1 . 1 m o t i vat i o n
The amount of digitally processed and stored information has been in- creasing drastically over the past decade. In 2012 alone, there were about 2 . 5 exabytes of data created every single day [ 1 ]. This availability of “big data” comes with big opportunities for scientists and practitioners, but also imposes big technical challenges. For humans it is getting increasingly difficult to visualize, access, or extract targeted information from growing data sources [cf., 2 ]. This is especially prevalent for non-expert users who are unfamiliar with programming languages or database management sys- tems [cf., 3 ]. Therefore, researchers in natural language processing have been looking for new and more natural ways to interact with information systems. Question Answering (QA) is a prominent example of such a natu- ral language interface that promises to replace traditional search by directly responding to natural language questions from users.
Research on question answering goes back to 1965 [ 4 ] where it was
based on manually written rules and patterns for answer extraction. Later
breakthroughs in QA often stemmed from the field of semantic parsing [e. g.,
5 – 7 ]: Semantic parsing has the goal to translate a textual utterance (i. e.,
question) into a logical form (i. e., SQL-query) that can be executed by a
computer against a structured knowledge source (i. e., database) in order
to derive the answer. The biggest disadvantage of this approach is that
structured knowledge sources are largely incomplete. Consequently, it is
impossible to derive the correct answer for any question that is not covered
by the underlying knowledge source. This problem is much less prevalent
in unstructured textual knowledge sources, as Wikipedia or the World
1
Wide Web. QA over unstructured knowledge sources is very powerful, as it does not suffer from the problem of coverage, but the step of answer extraction is much harder due to the missing semantic information about entities and their relations. As a consequence, such QA systems often depend on syntactic rules and patterns [cf., 8 ]. This makes predictions for unseen question types very hard and leads to an inferior performance in practice. The recent advancement of deep learning in natural language processing replaced rule- and pattern-based answer extraction with deep neural networks. This led to a significant boost in the performance of QA systems over unstructured knowledge sources [e. g., 9 , 10 ].
Deep neural networks were applied to QA after showing huge success in Machine Reading Comprehension (MRC) tasks [e. g., 11 – 13 ]. MRC has the goal of answering a question with the help of a given text passage (as opposed to QA where the text passage containing the answer is not known a priori). Neural networks for MRC have the substantial advantage that they do not relay on explicit syntactic rules or patterns, but learn to extract answers in an end-to-end fashion. Therefore, they are able to generalize to new and unseen types of input questions. Subsequently, neural networks for MRC were extended to the more complex setting of question answering where the text passage containing the answer has to be retrieved from a large text corpus. This new paradigm of “neural QA” systems operating on top unstructured knowledge sources has shown great success [ 9 , 10 , 14 ]. Nonetheless, neural QA systems have been developed mostly for open- domain questions in English; and their usage in other domains has been limited.
The performance of neural QA systems drops significantly when they are evaluated on a different dataset than they have been trained on [ 15 , 16 ].
This phenomenon, when the assumption of independent and identically
distributed (i.i.d.) samples between training and testing is violated, is often
referred to as domain shift. Domain shift is not prevalent in most academic
QA benchmark settings where training and evaluation are done on the
same data distribution. Although recently some efforts have been made for
a more fair and robust evaluation of QA [i. e., 16 ], solutions to the problem
of domain shift in QA remain scarce for the following reasons: (i) It is in
general not clear how one can customize an existing QA system to a specific
domain; (ii) The creation of new QA datasets for specific domains is costly,
time consuming, and often requires expert knowledge; (iii) QA systems in
academia are mostly viewed as static systems which are not able to adjust
over time to the domain they have been deployed to. These factors limit
1 . 2 o b j e c t i v e s 3 the usage of QA in many practical applications. This thesis is dedicated to tackle the problem of domain shift in neural QA systems and proposes several techniques to efficiently address domain shift in neural QA.
1 . 2 o b j e c t i v e s
Motivated by the problem statement above, this thesis develops several techniques to address the problem of domain shift in neural QA. Our work can be categorized in methods to be used before deployment, e. g., transfer-learning or low cost annotation of data; and methods to be used after deployment, e. g., continuous improvement from user interactions over time. Our objectives directly address the three limiting factors that we laid out above,
1 . We aim at finding efficient techniques to customize QA systems to new domains for which only a fraction of labeled data points are available.
That is we aim at developing techniques for transfer-learning from existing datasets.
2 . The annotation of QA datasets is expensive and time consuming. We aim at finding techniques to annotate new QA datasets with as little cost as possible.
3 . Questions seen during deployment will always differ from questions used during training. Therefore, we aim to re-think question answer- ing systems as dynamic frameworks that are capable to improve over time from user interactions.
1 . 3 o u t l i n e
The outline of this thesis is structured as follows (see Figure 1 . 1 ). Chapter 2 and Chapter 3 build the foundation of the thesis, here we develop robust architectures for QA systems that are used in the subsequent chapters. In Chapter 2 we develop a method for adaptive and robust document retrieval that is capable to adjust to fluctuations in the underlying knowledge source.
The answer re-ranking module presented in Chapter 3 yields a stable performance increase across various datasets.
In Chapters 4 and 5 we present our methods for addressing domain shifts that are suitable for a usage before the deployment of a QA system.
In Chapter 4 we develop transfer learning techniques for customizing an
Domain Adaptation in QA
Foundation
Chapter 1 Adaptive Retrieval [EMNLP'18] Chapter 2 Answer Re-Ranking [ACL'19]
Before Deployment
Chapter 3 Transfer Learning [TMIS'19] Chapter 4 Cost-Effective Annotation [EMNLP'20]
After Deployment
Chapter 5 Learning from On-line User Feedback on the Web [WWW'19] Chapter 6 Interactive knowledge base completion with QA [COLING'20]
Extensions to other tasks
F igure 1 . 1 : Illustrative outline of this thesis.
open-domain QA system to the domain of finance. In Chapter 5 we present a framework to annotate new question answering datasets with as little cost as possible.
In Chapter 6 we present a framework for the dynamic domain customiza- tion of a QA system after it is deployed. That is, we design a framework that continues to learn over time from user interactions. The original per- formance drop caused by a domain shift then vanishes with an increasing number of user interactions.
In Chapter 7 we extend our method to a different but related task:
Knowledge base completion. Here we design an interactive approach that is able to improve in performance over time on so-called zero-shot relations (i.e., relations that have not been seen during training). Our framework for knowledge base completion is based on an interactive question answering system.
Finally, in Chapter 8 we provide a summary of our findings as well as a discussion and an outlook on future work.
1 . 4 a b s t r a c t s o f s c i e n t i f i c pa p e r s
Adaptive Document Retrieval for Deep Question Answering This paper has appeared in the following conference article:
B. K ratzwald and S. F euerriegel Adaptive Document Retrieval
for Deep Question Answering. In: Empirical Methods in Natural Lan-
1 . 4 a b s t r a c t s o f s c i e n t i f i c pa p e r s 5 guage Processing (EMNLP, short papers), DOI: 10 . 18653 /v 1 /D 18 -
1055 .
State-of-the-art systems in deep question answering proceed as follows:
( 1 ) an initial document retrieval selects relevant documents, which ( 2 ) are then processed by a neural network in order to extract the final answer.
Yet the exact interplay between both components is poorly understood, especially concerning the number of candidate documents that should be retrieved. We show that choosing a static number of documents – as used in prior research – suffers from a noise-information trade-off and yields suboptimal results. As a remedy, we propose an adaptive document retrieval model. This learns the optimal candidate number for document retrieval, conditional on the size of the corpus and the query. We report extensive experimental results showing that our adaptive approach outperforms state- of-the-art methods on multiple benchmark datasets, as well as in the context of corpora with variable sizes.
Contribution: The author of this thesis developed the models and the computational framework, carried out the implementation, performed the analytical calculations, and performed the numerical experiments. The co-authors and the author contributed to the final version of the research paper.
Neural Question Answering with Answer Re-Ranking.
This paper has appeared in the following conference article:
B. K ratzwald , A. E igenmann and S. F euerriegel ( 2019 ). Putting
Question-Answering Systems into Practice: Transfer Learning for Effi-
cient Domain Customization. In: Annual Meeting of the Association
for Computational Linguistics (ACL) DOI: 10 . 18653 /v 1 /P 19 - 1611 .
The conventional paradigm in neural question answering (QA) for narra-
tive content is limited to a two-stage process: first, relevant text passages are
retrieved and, subsequently, a neural network for machine comprehension
extracts the likeliest answer. However, both stages are largely isolated in the
status quo and, hence, information from the two phases is never properly
fused. In contrast, this work proposes RankQA: RankQA extends the con-
ventional two-stage process in neural QA with a third stage that performs
an additional answer re-ranking. The re-ranking leverages different fea-
tures that are directly extracted from the QA pipeline, i. e., a combination
of retrieval and comprehension features. While our intentionally simple
design allows for an efficient, data-sparse estimation, it nevertheless outper- forms more complex QA systems by a significant margin: in fact, RankQA achieves state-of-the-art performance on 3 out of 4 benchmark datasets.
Furthermore, its performance is especially superior in settings where the size of the corpus is dynamic. Here the answer re-ranking provides an effective remedy against the underlying noise-information trade-off due to a variable corpus size. As a consequence, RankQA represents a novel, powerful, and thus challenging baseline for future research in content-based QA.
Contribution: The author of this thesis developed the models in collabo- ration with the second author of the research paper. The author of this thesis carried out the implementation of the framework, performed the analytical calculations, and designed and performed the numerical experiments. The co-authors and the author contributed to the final version of the research paper.
Putting Question-Answering Systems into Practice: Transfer Learning for Efficient Domain Customization
This paper has appeared in the following journal article:
B. K ratzwald and S. F euerriegel ( 2019 ). Putting Question- Answering Systems into Practice: Transfer Learning for Efficient Do- main Customization. In: ACM Transactions on Management Informa- tion Systems (TMIS), Vol. 9 ( 4 ) Paper No. 15 , DOI: 10 . 1145 / 3309706 . Traditional information retrieval (such as that offered by web search engines) impedes users with information overload from extensive result pages and the need to manually locate the desired information therein.
Conversely, question-answering systems change how humans interact with
information systems: users can now ask specific questions and obtain a
tailored answer – both conveniently in natural language. Despite obvious
benefits, their use is often limited to an academic context, largely because
of expensive domain customizations, which means that the performance
in domain-specific applications often fails to meet expectations. This paper
proposes cost-efficient remedies: (i) we leverage metadata through a filtering
mechanism, which increases the precision of document retrieval, and (ii)
we develop a novel fuse-and-oversample approach for transfer learning in
order to improve the performance of answer extraction. Here knowledge is
inductively transferred from a related, yet different, tasks to the domain-
specific application, while accounting for potential differences in the sample
sizes across both tasks. The resulting performance is demonstrated with
1 . 4 a b s t r a c t s o f s c i e n t i f i c pa p e r s 7 actual use cases from a finance company and the film industry, where fewer than 400 question-answer pairs had to be annotated in order to yield significant performance gains. As a direct implication to management, this presents a promising path to better leveraging of knowledge stored in information systems.
Contribution: The author of this thesis developed the models and the computational framework, carried out the implementations, performed the analytic calculations, and performed the numerical experiments. The co-author and the author of this work contributed to the final version of the research paper.
Learning a Cost-Effective Annotation Policy for Question Answering This paper has appeared in the following conference article:
B. K ratzwald , S. F euerriegel and H. S un ( 2020 ). Learning a Cost-Effective Annotation Policy for Question Answering. In: Empiri- cal Methods in Natural Language Processing (EMNLP), in press.
State-of-the-art question answering (QA) relies upon large amounts of training data for which labeling is time consuming and thus expensive.
For this reason, customizing QA systems is challenging. As a remedy, we propose a novel framework for annotating QA datasets that entails learning a cost-effective annotation policy and a semi-supervised annotation scheme.
The latter reduces the human effort: it leverages the underlying QA system to suggest potential candidate annotations. Human annotators then simply provide binary feedback on these candidates. Our system is designed such that past annotations continuously improve the future performance and thus overall annotation cost. To the best of our knowledge, this is the first paper to address the problem of annotating questions with minimal annotation cost. We compare our framework against traditional manual annotations in an extensive set of experiments. We find that our approach can reduce up to 21 . 1 % of the annotation cost.
Contribution: The author of this thesis developed the models and the
computational framework, carried out the implementations, performed the
analytic calculations, and performed the numerical experiments. The last
author and the author of this thesis contributed to developing the theoretical
framework. All co-authors and the author of this thesis contributed to the
final version of the research paper.
Learning from On-Line User Feedback in Neural Question Answering on the Web
This paper has appeared in the following conference article:
B. K ratzwald and S. F euerriegel ( 2019 ). Learning from On-Line User Feedback in Neural Question Answering on the Web. In: The World Wide Web Conference (WWW) DOI: 10 . 1145 / 3308558 . 3313661 . Question answering promises a means of efficiently searching web-based content repositories such as Wikipedia. However, the systems of this type most prevalent today merely conduct their learning once in an offline training phase while, afterwards, all parameters remain static. Thus, the possibility of improvement over time is precluded. As a consequence of this shortcoming, question answering is not currently taking advantage of the wealth of feedback mechanisms that have become prominent on the web (e. g., buttons for liking, voting, or sharing).
This is the first work that introduces a question-answering system for (web-based) content repositories with an on-line mechanism for user feed- back. Our efforts have resulted in QApedia – a framework for on-line improvement based on shallow user feedback. In detail, we develop a simple feedback mechanism that allows users to express whether a ques- tion was answered satisfactorily or whether a different answer is needed.
Even for this simple mechanism, the implementation represents a daunting undertaking due to the complex, multi-staged operations that underlie state-of-the-art systems for neural questions answering. Another challenge with regard to web-based use is that feedback is limited (and possibly even noisy), as the true labels remain unknown. We thus address these challenges through a novel combination of neural question answering and a dynamic process based on distant supervision, asynchronous updates, and an automatic validation of feedback credibility in order to mine high-quality training samples from the web for the purpose of achieving continuous improvement over time.
Our QApedia framework is the first question-answering system that
continuously refines its capabilities by improving its now dynamic content
repository and thus the underlying answer extraction. QApedia not only
achieves state-of-the-art results over several benchmarking datasets, but
we further show that it successfully manages to learn from shallow user
feedback, even when the feedback is noisy or adversarial. Altogether, our
extensive experimental evaluation, with more than 2 , 500 hours of computa-
tional experiments, demonstrates that a feedback mechanism as simple as a
1 . 4 a b s t r a c t s o f s c i e n t i f i c pa p e r s 9 binary vote (which is widespread on the web) can considerably improve performance when combined with an efficient framework for continuous learning.
Contribution: The author of this thesis developed the models and the computational framework, carried out the implementations, performed the analytic calculations, and performed the numerical experiments. The co-author and the author of this work contributed to the final version of the research paper.
IntKB: A Verifiable Interactive Framework for Knowledge Base Comple- tion
This paper has appeared in the following conference article:
B. K ratzwald ,G. Kunpeng S. F euerriegel and D. D iefenbach ( 2020 ). IntKB: A Verifiable Interactive Framework for Knowledge Base Completion. In: Conference on Computational Linguistics (COLING), in press.
Knowledge bases (KBs) are essential for many downstream NLP tasks, yet their prime shortcoming is that they are often incomplete. State-of-the- art frameworks for KB completion often lack sufficient accuracy to work fully automated without human supervision. As a remedy, we propose IntKB: a novel interactive framework for KB completion from text based on a question answering pipeline. Our framework is tailored to the specific needs of a human-in-the-loop paradigm: (i) We generate facts that are aligned with text snippets and are thus immediately verifiable by humans.
(ii) Our system is designed such that it continuously learns during the KB completion task and, therefore, significantly improves its performance upon initial zero- and few-shot relations over time. (iii) We only trigger human interactions when there is enough information for a correct prediction.
Therefore, we train our system with negative examples and a fold-option if there is no answer. Our framework yields a favorable performance: it achieves a hit@ 1 ratio of 29 . 7 % for initially unseen relations, upon which it gradually improves to 46 . 2 %.
Contribution: The author of this thesis developed the core of this frame- work including the training and update procedure, models, the analytic calculations, and design of the numerical experiments. The second author designed the answer-triggering module and continuous update module.
The last author of this paper designed the answer-linking module. All
co-authors and the author of this thesis contributed to the final version of
the research paper.
2
A D A P T I V E D O C U M E N T R E T R I E VA L F O R D E E P Q U E S T I O N A N S W E R I N G
c o n t e n t s
2 . 1 Introduction . . . . 12 2 . 2 Related Work . . . . 12 2 . 3 Noise-Information Trade-Off in Document Retrieval . . . . 14 2 . 4 Adaptive Document Retrieval . . . . 15 2 . 5 Experiments . . . . 17 2 . 6 Conclusion . . . . 20 This chapter has appeared in the following conference article:
B. K ratzwald and S. F euerriegel Adaptive Document Retrieval for Deep Question Answering. In: Empirical Methods in Natural Lan- guage Processing (EMNLP, short papers), DOI: 10 . 18653 /v 1 /D 18 - 1055 .
c o n t r i b u t i o n
The author of this thesis developed the models and the computational framework, carried out the implementation, performed the analytical calcu- lations, and performed the numerical experiments. The co-authors and the author contributed to the final version of the research paper.
a b s t r a c t
State-of-the-art systems in deep question answering proceed as follows:
( 1 ) an initial document retrieval selects relevant documents, which ( 2 ) are then processed by a neural network in order to extract the final answer.
Yet the exact interplay between both components is poorly understood,
especially concerning the number of candidate documents that should be
retrieved. We show that choosing a static number of documents – as used
in prior research – suffers from a noise-information trade-off and yields
suboptimal results. As a remedy, we propose an adaptive document retrieval
11
model. This learns the optimal candidate number for document retrieval, conditional on the size of the corpus and the query. We report extensive experimental results showing that our adaptive approach outperforms state- of-the-art methods on multiple benchmark datasets, as well as in the context of corpora with variable sizes.
2 . 1 i n t r o d u c t i o n
Question-answering (QA) systems proceed by following a two-staged pro- cess [ 17 ]: in a first step, a module for document retrieval selects n potentially relevant documents from a given corpus. Subsequently, a machine com- prehension module extracts the final answer from the previously-selected documents. The latter step often involves hand-written rules or machine learning classifiers [c. f. 8 , 18 ], and recently also deep neural networks [e. g.
9 , 10 ]
The number of candidate documents n affects the interplay between both document retrieval and machine comprehension component. A larger n improves the recall of document retrieval and thus the chance of including the relevant information. However, this also increases the noise and might adversely reduce the accuracy of answer extraction. It was recently shown that a top-1 system can potentially outperform a system selecting more than one document [ 19 ]. This finding suggests that a static choice of n can result a suboptimal performance.
Contributions. This work analyzes the interplay between document re- trieval and machine comprehension inside neural QA systems. We first reason numerically why a fixed choice of n in document retrieval can neg- atively affect the performance of question answering. We thus propose a novel machine learning model that adaptively selects the optimal n i for each document retrieval. The resulting system outperforms state-of-the-art neural question answering on multiple benchmark datasets. Notably, the overall size of the corpus affects the optimal n considerably and, as a result, our system evinces as especially superior over a fixed n in settings where the corpus size is unknown or grows dynamically.
2 . 2 r e l at e d w o r k
Taxonomy of QA systems. Question answering systems are frequently
categorized into two main paradigms. On the one hand, knowledge-based
systems draw upon manual rules, ontologies and large-scale knowledge
2 . 2 r e l at e d w o r k 13
(a) Exact matches with (b) Recall at top-n (c) Avg. number of
correct answer relevant documents
17.5 20.0 22.5 25.0 27.5 30.0
103 104 105 106
corpus size
% exact match
0.6 0.7 0.8 0.9 1.0
103 104 105 106
corpus size
recall
top−1 top−3 top−5 top−10 0 1 2 3 4 5
103 104 105 106
corpus size
number of relevant documents
F igure 2 . 1 : Comparison of how top-n document retrieval affects deep QA. Plot (a) shows the percentage of exact matches with the correct answering, thereby measuring the end-to-end performance of the complete sys- tem. Plot (b) gives the recall at top-n, i. e. the fraction of samples where at least once the correct answer is returned. Plot (c) depicts the average number of documents that contain the ground-truth answer.
As a result, the recall lowers with increasing corpus size, yet this not necessarily compromises a top-n system, as it often contains the correct answer more than once.
graphs in order to deduce answers [e. g. 6 , 20 , 21 ]. On the other hand, QA system incorporate a document retrieval module which selects candidate documents based on a chosen similarity metric, while a subsequent module then processes these in order to extract the answer [e. g. 22 , 23 ].
Deep QA. Recently, Chen et al. [ 9 ] developed a state-of-the-art deep QA system, where the answer is extracted from the top n = 5 documents. This choice stems from computing the dot product between documents and a query vector; with tf-idf weighting of hashed bi-gram counts. Wang et al.
[ 10 ] extended this approach by implementing a neural re-ranking of the candidate document, yet keeping the fixed number of n selected documents unchanged. In particular, the interplay between both modules for docu- ment retrieval and machine comprehension has not yet been studied. This especially pertains to the number of candidate documents, n, that should be selected during document retrieval.
Component interactions. Extensive research has analyzed the interplay
of both document retrieval and machine comprehension in the context
of knowledge-based systems [c. f. 24 ] and even retrieval-based systems
with machine learning [c. f. 25 ]. However, these findings do not translate
to machine comprehension with deep learning. Deep neural networks
consist of a complex attention mechanism for selecting the context-specific answer [ 11 ] that has not been available to traditional machine learning and, moreover, deep learning is highly sensitive to settings involving multiple input paragraphs, often struggling with selecting the correct answer [ 26 ].
2 . 3 n o i s e - i n f o r m at i o n t r a d e - o f f i n d o c u m e n t r e t r i e va l In the following, we provide empirical evidence why a one-fits-all n can be suboptimal. For this purpose, we run a series of experiments in order to obtain a better understanding of the interplay between document retrieval and machine comprehension modules. That is, we specifically compare the recall of document retrieval to the end-to-end performance of the complete QA system; see Fig. 2 . 1 . Our experiments study the sensitivity along two dimensions: on the one hand, we change the number of top-n documents that are returned during document retrieval and, on the other hand, we vary the corpus size.
Our experiments utilize the TREC QA dataset as a well-established benchmark for open-domain question answering. It contains 694 question- answer pairs that are answered with the help of Wikipedia. We vary the corpus between a small case (where each question-answer pair contains only one Wikipedia article with the correct answer plus 50 % articles as noise) and the complete Wikipedia dump containing more than five million documents. Our experiments further draw upon the DrQA system [ 9 ] for question answering that currently stands as a baseline in deep question answering. We further modified it to return different numbers of candidate documents.
Fig. 2 . 1 (a) shows the end-to-end performance across different top-n document retrievals as measured by the exact matches with ground truth.
For a small corpus, we clearly register a superior performance for the top- 1 system. However, we observe a different pattern with increasing corpus size.
Fig. 2 . 1 (b) and (c) shed light into the underlying reason by reporting how frequently the correct answer is returned and, as the correct answer might appear multiple times, how often it is included in the top-n. Evidently, the recall in (b) drops quickly for a top- 1 system when augmenting the corpus.
Yet it remains fairly stable for a top-n system, due to the fact that it is
sufficient to have the correct answer in any of the n documents. According
to (c), the correct answer is often more than once returned by a top-n system,
increasing the chance of answer extraction.
2 . 4 a d a p t i v e d o c u m e n t r e t r i e va l 15
(a) Recall (b) Avg number of
relevant documents
0.2 0.4 0.6 0.8 1.0
2 4 6 8 10
top−n retrieved documents
recall
1 2 3 4 5
2 4 6 8 10
top−n retrieved documents
avg. number relevant documents
F igure 2 . 2 : Recall (a) and average number of relevant documents (b) for growing top-n configurations and a static corpus size (full Wikipedia dump).
While the recall is converging the number of relevant documents keeps growing resulting in a higher density of relevant information.
The above findings result in a noise-information trade-off. A top-1 system often identifies the correct answer for a small corpus, whereas a larger cor- pus introduces additional noise and thus impedes the overall performance.
Conversely, a top-n system accomplishes a higher density of relevant infor- mation for a large corpus as the answer is often contained multiple times.
This effect is visualized in an additional experiment shown in Fig. 2 . 2 . We keep the corpus size fixed and vary only n, i.e. the number of retrieved documents. We see the recall converging fast, while the average number of relevant documents keeps growing, leading to a higher density of relevant information. As a result, a top-n system might not be compromised by a declining recall, since it contains the correct answer over-proportionally often. This logic motivates us in the following to introduce an adaptive n i that optimizes the number of documents retrievals in a top-n system independently for every query q i .
2 . 4 a d a p t i v e d o c u m e n t r e t r i e va l
This section advances deep question answering by developing adaptive
methods for document retrieval. Our methods differ from conventional
document retrieval in which the number of returned documents is set to a
fixed n. Conversely, we actively optimize the choice of n i for each document retrieval i. Formally, we select n i between 1 and a maximum τ (e. g. τ = 20), given documents [ d (1) i , . . . , d (τ) i ] . These entail further scores denoting the relevance, i. e. s i = [ s (1) i , . . . , s i (τ) ] T with normalization s. t. ∑ j s i (j) = 1. The scoring function is treated as a black-box and thus can be based on simple tf-idf similarity but also complex probabilistic models.
2 . 4 . 1 Threshold-Based Retrieval
As a naïve baseline, we propose a simple threshold-based heuristic. That is, n i is determined such that the cumulative confidence score reaches a fixed threshold θ ∈ ( 0, 1 ] . Formally, the number n i of retrieved documents is given by
n i = max
k
∑ k j=1
s (j) i < θ. ( 2 . 1 ) In other words, the heuristic fills up documents until surpassing a certain confidence threshold. For instance, if the document retrieval is certain that the correct answer must be located within a specific document, it automatically selects fewer documents.
2 . 4 . 2 Ordinal Regression
We further implement a trainable classifier in the form of an ordinal ridge regression which is tailored to ranking tasks. We further expect the cumu- lative confidence likely to be linear. The classifier then approximates n i with a prediction y i that denotes the position of the first relevant document containing the desired answer. As such, we learn a function
y i = f ([ s i (1) , . . . , s (τ) i ]) = d s i T β e , ( 2 . 2 ) where d . . . e denotes the ceiling function.
The ridge coefficients are learned through a custom loss function
L = kd Xβ e − y k 1 + λ k β k 2 , ( 2 . 3 )
where X is a matrix containing scores of our training samples. In contrast
to the classical ridge regression, we introduce a ceiling function and replace
the mean squared error by a mean absolute error in order to penalize the
2 . 5 e x p e r i m e n t s 17 difference from the optimal rank. The predicted cut-off ˆ n i for document retrieval is then computed for new observations s 0 i via ˆ n i = d s 0 T i β ˆ e + b. The linear offset b is added in order to ensures that n i ≤ n ˆ i holds, i. e. reducing the risk that the first relevant document is not included.
We additionally experimented with non-linear predictors, including ran- dom forests and feed-forward neural networks; however; we found no significant improvement that justified the additional model complexity over the linear relationship.
17.5 20.0 22.5 25.0 27.5 30.0
103 104 105 106
corpus size
ex act match [%]
top−1 top−3 top−5 top−10 adaptive
F igure 2 . 3 : End-to-end performance of adaptive information retrieval over static top-n configurations and a growing corpus.
2 . 5 e x p e r i m e n t s
We first compare our QA system with adaptive document retrieval against benchmarks from the literature. Second, we specifically study the sensi- tivity of our adaptive approach to variations in the corpus size. All our experiments draw upon the DrQA implementation [ 9 ], a state-of-the-art system for question answering in which we replaced the default module for document retrieval with our adaptive scheme (but leaving all remaining components unchanged, specifically without altering the document scoring or answer extraction).
For the threshold-based model, we set τ = 15 and the confidence thresh-
old to θ = 0.75. For the ordinal regression approach, we choose τ = 20 and
SQuAD TREC WebQuestions WikiMovies
DrQA [ 9 ]
†29 . 3 27 . 5 18 . 5 36 . 6
Threshold-based (θ = 0.75) 29.8 28 . 7 19 . 2 38 . 6
Ordinal regression (b = 1) 29 . 7 28 . 1 19 . 4 38 . 0
Ordinal regression (b = 3) 29 . 6 29.3 19.6 38 . 4
R
3[ 10 ] 29 . 1 28 . 4 17 . 1 38.8
†
: Numbers vary slightly from those reported in the original paper, as the public repository was optimized for runtime performance.
T able 2 . 1 : End-to-end performance of the plain DrQA system measured in exact matches. Performance of two threshold based and two regression based adaptive retreival improvements as well as other state-of-the art systems. Experiments are based on the full Wikipedia dump containing more than 5 million documents.
use the original SQuAD train-dev split from the full corpus also as the basis for training across all experiments.
2 . 5 . 1 Overall Performance
In a first series of experiments, we refer to an extensive set of prevalent benchmarks for evaluating QA systems, namely, SQuAD [ 27 ], Curated TREC [ 28 ], WikiMovies [ 29 ] and WebQuestions [ 6 ] in order to validate the robustness of our findings. Based on these, we then evaluate our adaptive QA systems against the naïve DrQA system in order to evaluate the relative performance. We included the deep QA system R 3 as an additional, top- scoring benchmark from recent literature [ 10 ] for better comparability.
Tbl. 2 . 1 reports the ratio of exact matches for the different QA systems.
The results demonstrate the effectiveness of our adaptive scheme: it yields the best-performing system for three out of four datasets. On top of that, it outperforms the naïve DrQA system consistently across all datasets.
2 . 5 . 2 Sensitivity: Adaptive QA to Corpus Size
We earlier observed that the corpus size affects the best choice of n and
we thus study the sensitivity with regard to the size. For this purpose, we
repeat the experiments from Section 2 . 3 in order to evaluate the performance
2 . 5 e x p e r i m e n t s 19
SQuAD TREC WebQuestions WikiMovies
Top-50 System 27 . 0 23 . 5 15 . 1 24 . 4
Top-80 System 27 . 2 25 . 9 14 . 9 26 . 0
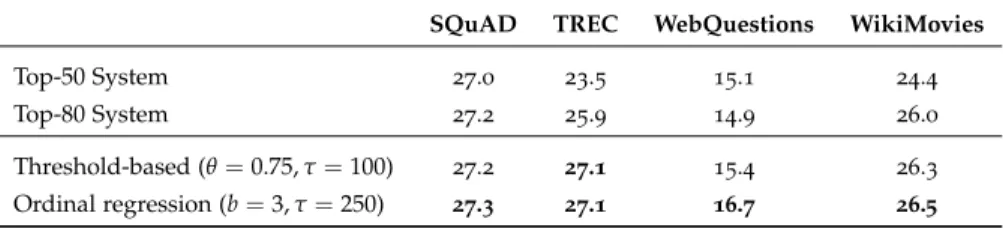
Threshold-based (θ = 0.75, τ = 100) 27 . 2 27.1 15 . 4 26 . 3
Ordinal regression (b = 3, τ = 250) 27.3 27.1 16.7 26.5
T able 2 . 2 : End-to-end performance measured in percentages of exact matching answers of a second QA system that operates on paragraph-level information retrieval. We compare two configurations of the system using the top-50 and top-80 ranked paragraphs to extract the answer against our threshold-based approach and regression approach that selects the cutoff within the first 250 paragraphs.
gain from our adaptive scheme. More precisely, we compare the ordinal regression (b = 1) against document retrieval with a fixed document count n.
Fig. 2 . 3 shows the end-to-end performance, confirming the overall supe- riority of our adaptive document retrieval. For instance, the top- 1 system reaches a slightly higher rate of exact matches for small corpus sizes, but is ranked last when considering the complete corpus. The high performance of the top-1 system partially originates from the design of the experiment itself, where we initially added one correct document per question, which is easy to dissect by adding little additional noise. On the other hand, the top- 10 system accomplishes the best performance on the complete corpus, whereas it fails to obtain an acceptable performance for smaller corpus sizes.
To quantify our observations, we use a notation of regret. Formally, let µ nm denote the performance of the top-n system on a corpus of size m.
Then the regret of choosing system n at evaluation point m is the dif-
ference between the best performing system µ ∗ m and the chosen system
r nm = µ ∗ m − µ nm . The total regret of system n is computed by averaging the
regret over all observations of system n, weighted with the span in-between
observations in order to account for the logarithmic intervals. The best top-n
system yields a regret of 0.83 and 1.12 respectively, whereas our adaptive
control improves it down to 0.70.
2 . 5 . 3 Robustness Check
Experiments so far have been conducted on the DrQA system. To show the robustness of our approach, we repeat all experiments on a different QA system. Different from DrQA, this system operates on paragraph-level information retrieval and uses cosine similarity to score tf-idf-weighted bag- of-word (unigram) vectors. The reader is a modified version of the DrQA document reader with an additional bi-directional attention layer [ 12 ]. We are testing two different configurations 1 of this system: one that selects the top-50 paragraphs and one that selects the top-80 paragraphs against our approach as shown in Tab. 2 . 2 . We see that, owed to the paragraph- level information retrieval, the number of top-n passages gains even more importance. Both variations of the system outperform a system without adaptive retrieval, which confirms our findings.
2 . 6 c o n c l u s i o n
Our contribution is three-fold. First, we establish that deep question an- swering is subject to a noise-information trade-off. As a consequence, the number of selected documents in deep QA should not be treated as fixed, rather it must be carefully tailored to the QA task. Second, we propose adaptive schemes that determine the optimal document count. This can considerably bolster the performance of deep QA systems across multiple benchmarks. Third, we further demonstrate how crucial an adaptive docu- ment retrieval is in the context of different corpus sizes. Here our adaptive strategy presents a flexible strategy that can successfully adapt to it and, compared to a fixed document count, accomplishes the best performance in terms of regret.
r e p r o d u c i b i l i t y
Code to integrate adaptive document retrieval in custom QA system and future research is freely available at https://github.com/bernhard2202/
adaptive-ir-for-qa
1 Best configurations out of { 30, 40, 50, 60, 70, 80, 90, and 100 } on SQuAD train split.
3
R A N K Q A : N E U R A L Q U E S T I O N A N S W E R I N G W I T H A N S W E R R E - R A N K I N G
c o n t e n t s
3 . 1 Introduction . . . . 22 3 . 2 RankQA . . . . 24 3 . 3 Experimental Design . . . . 30 3 . 4 Results . . . . 32 3 . 5 Related Work . . . . 39 3 . 6 Conclusion . . . . 41 This chapter has appeared in the following conference article:
B. K ratzwald , A. E igenmann and S. F euerriegel ( 2019 ). Putting Question-Answering Systems into Practice: Transfer Learning for Effi- cient Domain Customization. In: Annual Meeting of the Association for Computational Linguistics (ACL) DOI: 10 . 18653 /v 1 /P 19 - 1611 . c o n t r i b u t i o n
The author of this thesis developed the models in collaboration with the second author of the research paper. The author of this thesis carried out the implementation of the framework, performed the analytical calculations, and designed and performed the numerical experiments. The co-authors and the author contributed to the final version of the research paper.
a b s ta c t
The conventional paradigm in neural question answering (QA) for narrative content is limited to a two-stage process: first, relevant text passages are retrieved and, subsequently, a neural network for machine comprehension extracts the likeliest answer. However, both stages are largely isolated in the status quo and, hence, information from the two phases is never properly fused. In contrast, this work proposes RankQA 1 : RankQA extends the con-
1 Code is available from https://github.com/bernhard2202/rankqa
21
ventional two-stage process in neural QA with a third stage that performs an additional answer re-ranking. The re-ranking leverages different fea- tures that are directly extracted from the QA pipeline, i. e., a combination of retrieval and comprehension features. While our intentionally simple design allows for an efficient, data-sparse estimation, it nevertheless outper- forms more complex QA systems by a significant margin: in fact, RankQA achieves state-of-the-art performance on 3 out of 4 benchmark datasets.
Furthermore, its performance is especially superior in settings where the size of the corpus is dynamic. Here the answer re-ranking provides an effective remedy against the underlying noise-information trade-off due to a variable corpus size. As a consequence, RankQA represents a novel, powerful, and thus challenging baseline for future research in content-based QA.
3 . 1 i n t r o d u c t i o n
Question answering (QA) has recently experienced considerable success in variety of benchmarks due to the development of neural QA [ 9 , 10 ]. These systems largely follow a two-stage process. First, a module for information retrieval selects text passages which appear relevant to the query from the corpus. Second, a module for machine comprehension extracts the final answer, which is then returned to the user. This two-stage process is necessary for condensing the original corpus to passages and eventually answers; however, the dependence limits the extent to which information is passed on from one stage to the other.
Extensive efforts have been made to facilitate better information flow between the two stages. These works primarily address the interface be- tween the stages [ 30 , 31 ], i. e., which passages and how many of them are forwarded from information retrieval to machine comprehension. For in- stance, tTraditional information retrieval (such as that offered by web search engines) impedes users with information overload from extensive result pages and the need to manually locate the desired information therein.
Conversely, question-answering systems change how humans interact with
information systems: users can now ask specific questions and obtain a
tailored answer – both conveniently in natural language. Despite obvious
benefits, their use is often limited to an academic context, largely because
of expensive domain customizations, which means that the performance
in domain-specific applications often fails to meet expectations. This pa-
per proposes cost-efficient remedies: (i) we leverage metadata through a
3 . 1 i n t r o d u c t i o n 23 filtering mechanism, which increases the precision of document retrieval, and (ii) we develop a novel fuse-and-oversample approach for transfer learning in order to improve the performance of answer extraction. Here knowledge is inductively transferred from a related, yet different, tasks to the domain-specific application, while accounting for potential differences in the sample sizes across both tasks. The resulting performance is demon- strated with actual use cases from a finance company and the film industry, where fewer than 400 question-answer pairs had to be annotated in order to yield significant performance gains. As a direct implication to management, this presents a promising path to better leveraging of knowledge stored in information systems. he QA performance is dependent on the corpus size and the number of top-n passages that are fed into the module for machine comprehension [ 32 ]. Nevertheless, machine comprehension in this approach makes use of only limited information (e. g., it ignores the confidence or similarity information computed during retrieval).
State-of-the-art approaches for selecting better answers engineer addi- tional features within the machine comprehension model with the implicit goal of considering information retrieval. For instance, the DrQA architec- ture of Chen et al. [ 9 ] includes features pertaining to the match between question words and words in the paragraph. Certain other works also in- corporate a linear combination of paragraph and answer score [ 30 ]. Despite that, the use is limited to simplistic features and the potential gains of re-ranking remain untapped.
Prior literature has recently hinted at potential benefits from answer re-ranking, albeit in a different setting [ 33 ]: the authors studied multi- paragraph machine comprehension at sentence level, instead of a complete QA pipeline involving an actual information retrieval module over a full corpus of documents. However, when adapting it from a multi-paragraph setting to a complete corpus, this type of approach is known to become computationally infeasible [cf. discussion in 30 ]. In contrast, answer re- ranking as part of an actual QA pipeline not been previously studied.
Proposed RankQA: This paper proposes a novel paradigm for neural QA. That is, we augment the conventional two-staged process with an additional third stage for efficient answer re-ranking. This approach, named
“RankQA”, overcomes the limitations of a two-stage process in the status quo whereby both stages operate largely in isolation and where information from the two is never properly fused. In contrast, our module for answer re-ranking fuses features that stem from both retrieval and comprehension.
Our approach is intentionally light-weight, which contributes to an efficient
estimation, even when directly integrated into the full QA pipeline. We show the robustness of our approach by demonstrating significant performance improvements over different QA pipelines.
Contributions: To the best of our knowledge, RankQA represents the first neural QA pipeline with an additional third stage for answer re-ranking.
Despite the light-weight architecture, RankQA achieves state-of-the-art per- formance across 3 established benchmark datasets. In fact, it even outper- forms more complex approaches by a considerable margin. This particularly holds true when the corpus size is variable and where the resulting noise- information trade-off requires an effective remedy. Altogether, RankQA yields a strong new baseline for content-based question answering.
3 . 2 r a n k q a
#1 Information
Retrieval
#2 Machine Comprehension Content
Base
#3 Answer Re-ranking
Question passagestext Answer
IR features answer candidates
MC features