Sommersemester 2020
Prof. Dr. David Sabel
Lehr- und Forschungseinheit f¨ ur Theoretische Informatik Institut f¨ ur Informatik
Ludwig-Maximilians-Universit¨ at M¨ unchen Oettingenstr. 67
80538 M¨ unchen Email: david.sabel@ifi.lmu.de
Stand: 21. Juli 2020
Dank: Dieses Skript basiert unter anderem auf einem Skript von Manfred Schmidt-Schauß (Goethe-Universit¨ at Frankfurt) zur Funktionalen Programmierung und dem Material von Steffen Jost zur gleichnamigen Veranstaltung aus dem Wintersemester 2018/19 an der LMU M¨ unchen.
Beiden danke ich f¨ ur die ¨ Uberlassung des Materials und die Genehmigung dieses hier zu ver-
wenden.
1. Einleitung 1
1.1. Was sind funktionale Programmiersprachen? . . . . 1
1.2. Warum Funktionale Programmierung? . . . . 2
1.3. Klassifizierung funktionaler Programmiersprachen . . . . 4
1.4. Inhalte . . . . 6
1.5. Weiteres Material . . . . 6
1.5.1. Literatur . . . . 6
1.5.2. Webseiten, etc . . . . 8
2. Eine Einf¨ uhrung in wichtige Konstrukte von Haskell 9 2.1. Einf¨ uhrung und Werkzeuge . . . . 9
2.2. Einf¨ uhrendes zu Typen in Haskell . . . . 10
2.2.1. Syntax und Sprechweisen . . . . 10
2.2.2. Wichtige Basistypen und weitere Typen . . . . 11
2.2.2.1. Arithmetische Operatoren und Zahlen . . . . 11
2.2.2.2. Weitere wichtige Typen: Bool, Char, String . . . . 12
2.3. Algebraische Datentypen in Haskell . . . . 13
2.3.1. Aufz¨ ahlungstypen . . . . 13
2.3.2. Produkttypen . . . . 15
2.3.2.1. Record-Syntax . . . . 16
2.3.3. Parametrisierte Datentypen . . . . 18
2.3.3.1. Der Datentyp Maybe . . . . 18
2.3.3.2. Der Datentyp Either . . . . 18
2.3.4. Rekursive Datentypen . . . . 19
2.4. Listenverarbeitung in Haskell . . . . 20
2.4.1. Listen von Zahlen . . . . 20
2.4.2. Strings . . . . 22
2.4.3. Standard-Listenfunktionen . . . . 22
2.4.3.1. Append . . . . 22
2.4.3.2. Zugriff auf ein Element . . . . 23
2.4.3.3. Map . . . . 23
2.4.3.4. Filter . . . . 24
2.4.3.5. Length . . . . 24
2.4.3.6. Reverse . . . . 25
2.4.3.7. Repeat und Replicate . . . . 25
2.4.3.8. Take und Drop . . . . 26
2.4.3.9. Zip und Unzip . . . . 26
2.4.3.10. Die Fold-Funktionen . . . . 27
2.4.3.11. Scanl und Scanr . . . . 29
2.4.3.12. Partition und Quicksort . . . . 30
2.4.3.13. Listen als Str¨ ome . . . . 30
2.4.3.14. Lookup . . . . 32
2.4.3.15. Mengenoperationen . . . . 32
2.4.4. List Comprehensions . . . . 33
2.5. B¨ aume . . . . 36
2.5.1. Bin¨ are B¨ aume . . . . 36
2.5.2. B¨ aume mit h¨ oherem Grad . . . . 38
2.5.3. B¨ aume durchlaufen . . . . 38
2.5.4. Syntaxb¨ aume . . . . 41
2.6. Typdefinitionen mit data, type und newtype . . . . 42
2.7. Funktionen und Ausdr¨ ucke . . . . 43
2.7.1. Funktionen und Funktionstypen . . . . 43
2.7.2. Anonyme Funktionen . . . . 45
2.7.3. Ausdr¨ ucke . . . . 45
2.7.4. Programmieren mit Let-Ausdr¨ ucken in Haskell . . . . 47
2.7.4.1. Lokale Funktionsdefinitionen mit let . . . . 47
2.7.4.2. Pattern-Matching mit let . . . . 48
2.7.4.3. Memoization . . . . 48
2.7.4.4. where-Klauseln . . . . 49
2.8. Haskells hierarchisches Modulsystem . . . . 50
2.8.1. Moduldefinitionen in Haskell . . . . 50
2.8.2. Modulexport . . . . 51
2.8.3. Modulimport . . . . 52
2.8.4. Hierarchische Modulstruktur . . . . 54
2.9. Quellennachweise und weiterf¨ uhrende Literatur . . . . 54
3. Semantik funktionaler Programmiersprachen: Funktionale Kernsprachen 55 3.1. Der Lambda-Kalk¨ ul . . . . 56
3.1.1. Call-by-Name-Reduktion . . . . 59
3.1.2. Implementierung eines Interpreters f¨ ur den ungetypen Lambda-Kalk¨ ul . . 61
3.1.3. Call-by-Value-Reduktion . . . . 64
3.1.4. Call-by-Need-Auswertung . . . . 66
3.1.5. Gleichheit von Programmen . . . . 68
3.1.6. Kernsprachen von Haskell . . . . 70
3.2. Die Kernsprache KFPT . . . . 70
3.2.1. Syntax von KFPT . . . . 70
3.2.2. Freie und gebundene Variablen in KFPT . . . . 73
3.2.3. Operationale Semantik f¨ ur KFPT . . . . 74
3.2.4. Dynamische Typisierung . . . . 76
3.2.5. Suche nach dem Call-by-Name-Redex mit einem Markierungsalgorithmus 77 3.2.6. Darstellung von Termen als Termgraphen . . . . 79
3.2.7. Eigenschaften der Call-by-Name-Reduktion . . . . 81
3.3. Die Kernsprache KFPTS . . . . 82
3.3.1. Syntax . . . . 82
3.3.2. Auswertung von KFPTS-Ausdr¨ ucken . . . . 83
3.4. Erweiterung um seq . . . . 84
3.5. KFPTSP: Polymorphe Typen . . . . 85
3.6. KFPTSP+seq als Kernsprache f¨ ur Haskell . . . . 87
3.6.1. let-Ausdr¨ ucke und where-Klauseln . . . . 87
3.6.2. Darstellung von Zahlen in KFPTSP+seq . . . . 88
3.6.3. Datentypen . . . . 89
3.6.4. if-then-else-Ausdr¨ ucke . . . . 89
3.6.5. case-Ausdr¨ ucke . . . . 89
3.6.6. Funktionsdefinitionen . . . . 90
3.7. ¨ Ubersicht ¨ uber die Kernsprachen . . . . 91
3.8. Lazy Evaluation in Haskell . . . . 91
3.8.1. Potentiell unendliche Datenstrukturen . . . . 93
3.8.2. Thunks im GHCi . . . . 93
3.8.3. Strikte Datentypen . . . . 97
3.8.4. Laziness . . . . 97
3.9. Quellennachweis und weiterf¨ uhrende Literatur . . . . 99
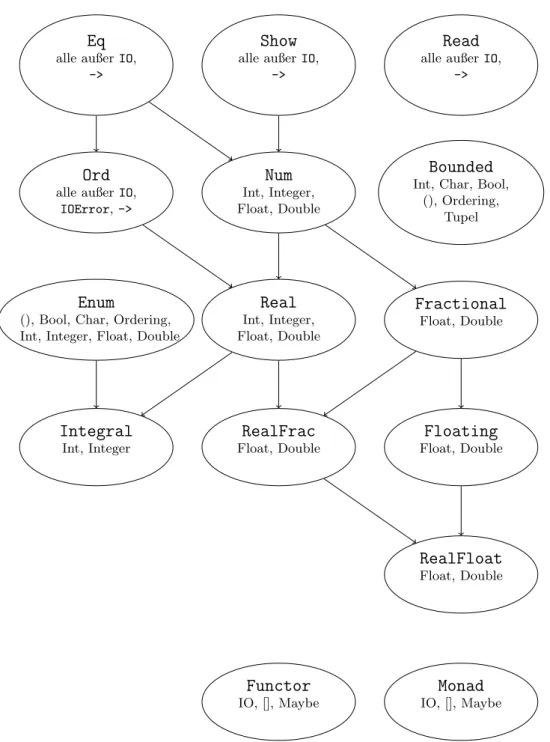
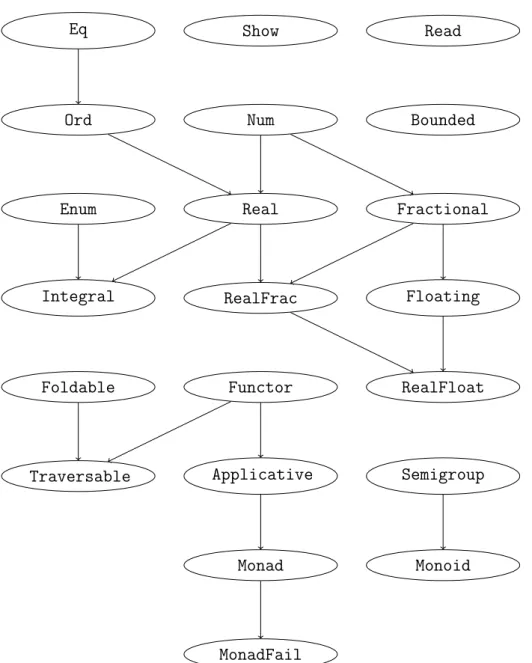
4. Haskells Typklassensystem 100 4.1. Ad hoc und parametrischer Polymorphismus . . . 100
4.2. Vererbung und Mehrfachvererbung . . . 102
4.3. Klassenbeschr¨ ankungen bei Instanzen . . . 104
4.4. Die Read- und Show-Klassen . . . 105
4.5. Die Klassen Num und Enum . . . 107
4.6. Kinds . . . 108
4.7. Konstruktorklassen . . . 110
4.7.1. Die Klasse Functor . . . 110
4.8. Auswahl weiterer vordefinierter Typklassen . . . 111
4.8.1. Monoide und Halbgruppen . . . 114
4.8.2. Die Klasse Foldable . . . 117
4.9. Aufl¨ osung der ¨ Uberladung . . . 117
4.10. Erweiterung von Typklassen . . . 123
4.11. Quellennachweise und weitere Literatur . . . 123
5. Applikative Funktoren, Monaden und Ein- und Ausgabe in Haskell 124 5.1. Applikative Funktoren . . . 124
5.1.1. Gesetze und die Maybe-Instanz f¨ ur Applicative . . . 126
5.1.2. Listen als Instanz der Klasse Applicative . . . 129
5.1.2.1. Die Standardinstanz f¨ ur Listen – Nichtdeterministische Berechnung129 5.1.2.2. Zip-Listen Instanz . . . 129
5.1.3. Applicative-Instanz f¨ ur Funktionen . . . 130
5.1.4. Die Traversable-Klasse . . . 131
5.1.5. Paare als Applikative Funktoren . . . 132
5.2. Monaden . . . 133
5.2.1. Monaden sind Applikative Funktoren . . . 136
5.2.2. Do-Notation . . . 136
5.2.3. Die Monadischen Gesetze . . . 139
5.2.4. Die Listen-Monade . . . 140
5.2.5. N¨ utzliche Monaden-Funktionen . . . 141
5.3. Die Zustandsmonade . . . 144
5.4. Ein- und Ausgabe: Monadisches IO . . . 148
5.4.1. Primitive I/O-Operationen . . . 150
5.4.2. Komposition von I/O-Aktionen . . . 150
5.4.3. Implementierung der IO-Monade . . . 152
5.4.4. Monadische Gesetze und die IO-Monade . . . 153
5.4.5. Verz¨ ogern innerhalb der IO-Monade . . . 153
5.4.6. Speicherzellen . . . 155
5.5. Monad-Transformer . . . 156
5.6. Weitere Anwendungen von und Bemerkungen zu Monaden . . . 159
5.6.1. ST-Monade . . . 160
5.6.2. Fehlermonade . . . 161
5.6.3. Beispiel: Werte mit Wahrscheinlichkeiten . . . 162
5.7. Quellennachweis . . . 163
6. Typisierung 164 6.1. Motivation . . . 164
6.2. Typen: Sprechweisen, Notationen und Unifikation . . . 166
6.3. Polymorphe Typisierung f¨ ur KFPTSP+seq-Ausdr¨ ucke . . . 170
6.4. Typisierung von nicht-rekursiven Superkombinatoren . . . 176
6.5. Typisierung rekursiver Superkombinatoren . . . 177
6.5.1. Das iterative Typisierungsverfahren . . . 177
6.5.2. Beispiele f¨ ur die iterative Typisierung und Eigenschaften des Verfahrens . 179 6.5.2.1. Das iterative Verfahren ist allgemeiner als Haskell . . . 181
6.5.2.2. Das iterative Verfahren ben¨ otigt mehrere Iterationen . . . 182
6.5.2.3. Das iterative Verfahren muss nicht terminieren . . . 183
6.5.2.4. Erzwingen der Terminierung: Milner Schritt . . . 186
6.5.3. Das Milner-Typisierungsverfahren . . . 187
6.6. Haskells Monomorphism Restriction . . . 194
6.7. Zusammenfassung und Quellennachweis . . . 195
7. Template Haskell 196 7.1. Einleitung . . . 196
7.2. Template Haskell als Code-Generator . . . 197
7.3. Reification . . . 206
7.4. Quasi-Quotes . . . 209
7.5. Zusammenfassung und Quellen . . . 211
8. Funktionale Referenzen (Linsen) 212 8.1. Einleitung . . . 212
8.1.1. Geschichte der Linsen . . . 215
8.2. Implementierung von Linsen . . . 215
8.2.1. Grunds¨ atzliche Idee von Linsen . . . 215
8.2.2. Van Laarhoven-Linsen . . . 216
8.2.3. Definition eigener Linsen . . . 219
8.2.4. Infix-Operatoren . . . 222
8.3. Polymorphe Linsen und weitere Optiken . . . 222
8.3.1. Polymorphe Linsen . . . 222
8.3.1.1. Linsen-Gesetze . . . 223
8.3.2. Traversal . . . 223
8.3.3. Linsen Hierarchy . . . 224
8.3.4. Prismen . . . 224
8.3.5. Iso . . . 226
8.3.6. N¨ utzliche vordefinierte Optiken . . . 226
8.4. Zusammenfassung und Quellen . . . 227
9. Parallelit¨ at, Ausnahmen und Nebenl¨ aufigkeit in Haskell 228 9.1. Einleitung . . . 228
9.2. Grundlegendes . . . 228
9.2.1. GHC-Multithreading . . . 229
9.2.2. Ressourcenverhalten messen . . . 230
9.2.2.1. Profiling . . . 230
9.2.2.2. Statistikausgabe des Runtime-Systems . . . 230
9.2.2.3. Threadscope . . . 231
9.3. Semi-explizite Parallelit¨ at: Glasgow parallel Haskell . . . 231
9.3.1. Eval-Monade . . . 233
9.3.2. Auswertungsstrategien . . . 236
9.3.3. NFData . . . 238
9.3.4. Zusammenfassung GpH . . . 239
9.4. Par-Monade . . . 240
9.4.1. Explizite Synchronisation . . . 240
9.4.2. Fork . . . 241
9.4.3. Zusammenfassung Par-Monade . . . 242
9.5. Ausnahmen . . . 243
9.5.1. Ausnahmen in GHC . . . 244
9.5.2. Eigene Ausnahmen definieren . . . 244
9.5.3. Zusammenfassung . . . 246
9.6. Nebenl¨ aufigkeit . . . 246
9.6.1. Concurrent Haskell . . . 246
9.6.2. Asynchrone Ausnahmen . . . 249
9.7. Software Transactional Memory . . . 252
9.7.1. Grundlagen . . . 252
9.7.2. TVar . . . 253
9.7.3. Ausnahmenbehandlung in STM . . . 255
9.8. Quellen . . . 255
10.Spracherweiterungen von Haskell 256 10.1. Multi-Parameter Typklassen . . . 256
10.2. Typfamilien . . . 258
10.2.1. Top-level Typfamilien . . . 259
10.2.2. Datentyp-Familien . . . 260
10.3. Generalised Algebraic Datatypes . . . 261
10.4. Typfamilien und GADTs . . . 264
10.5. DataKinds . . . 265
10.6. Existentielle Typen . . . 266
10.7. View Patterns . . . 268
10.7.1. View Patterns vs Pattern Guards . . . 269
10.8. ¨ Uberladene Strings . . . 269
10.8.1. Quellen . . . 271
11.Anwendungsprogrammierung 272 11.1. Webapplikationen mit Yesod . . . 272
11.1.1. Shakespearean Templates . . . 273
11.1.1.1. Hamlet . . . 275
11.1.1.2. Lucius . . . 276
11.1.1.3. Cassius . . . 277
11.1.1.4. Julius . . . 277
11.1.1.5. Widgets . . . 277
11.1.2. Foundation-Typ . . . 278
11.1.3. Handling . . . 281
11.1.4. Webformulare . . . 282
11.1.4.1. Applikative Formularfelder . . . 282
11.1.4.1.1. Auswahllisten . . . 283
11.1.4.1.2. Auswahlkn¨ opfe . . . 284
11.1.4.2. Input-Formulare ohne Layout . . . 284
11.1.4.3. Monadische Formulare . . . 285
11.1.5. Sessions . . . 285
11.1.5.1. Messages . . . 287
11.1.6. Persistenz – Anbindung an Datenbanken . . . 287
11.1.6.1. Spezifikation . . . 289
11.1.6.2. Migration . . . 290
11.1.6.3. Integration in Yesod . . . 292
11.2. GUI-Programmierung . . . 294
11.2.1. Gtk2Hs . . . 294
11.2.1.1. Grundger¨ ust eines Programms . . . 295
11.2.1.2. Widgets . . . 296
11.2.1.2.1. Buttons . . . 297
11.2.1.2.2. Entries . . . 298
11.2.1.2.3. Container . . . 298
11.2.1.3. Glade . . . 301
11.2.1.4. Eingefrorene GUI . . . 303
11.2.1.5. Men¨ us und Werkzeugleisten . . . 304
11.2.1.6. Beispiel: Taschenrechner . . . 305
11.2.2. Threepenny-GUI . . . 308
11.3. Quellen . . . 308
Literatur 309
A. Simulation von Turingmaschinen in Haskell 313
Einleitung 1
In diesem Kapitel erl¨ autern wir den Begriff der funktionalen Programmierung bzw. funktiona- len Programmiersprachen und motivieren, warum die tiefer gehende Besch¨ aftigung mit solchen Sprachen lohnenswert ist. Wir geben einen ¨ Uberblick ¨ uber verschiedene funktionale Program- miersprachen.
Außerdem geben wir einige Literaturempfehlungen.
1.1. Was sind funktionale Programmiersprachen?
Um den Begriff der funktionalen Programmiersprachen einzugrenzen, geben wir zun¨ achst eine Ubersicht ¨ ¨ uber die Klassifizierung von Programmiersprachen bzw. Programmierparadigmen. Im allgemeinen unterscheidet man zwischen imperativen und deklarativen Programmiersprachen.
Objektorientierte Sprachen kann man zu den imperativen Sprachen hinzuz¨ ahlen, wir f¨ uhren sie gesondert auf:
Imperative Programmiersprachen Der Programmcode ist eine Folge von Anweisungen (Be- fehlen), die sequentiell ausgef¨ uhrt werden und den Zustand des Rechners (Speicher) ver¨ andern. Eine Unterklasse sind sogenannte prozedurale Programmiersprachen, die es erlauben den Code durch Prozeduren zu strukturieren und zu gruppieren.
Objektorientierte Programmiersprachen In objektorientierten Programmiersprachen werden Programme (bzw. auch Problemstellungen) durch Klassen (mit Methoden und Attribu- ten) und durch Vererbung strukturiert. Objekte sind Instanzen von Klassen. Zur Laufzeit versenden Objekte Nachrichten untereinander durch Methodenaufrufe. Der Zustand der Objekte und daher auch des Systems wird bei Ausf¨ uhrung des Programms ver¨ andert.
Deklarative Programmiersprachen Der Programmcode beschreibt hierbei im Allgemeinen nicht, wie das Ergebnis eines Programms berechnet wird, sondern eher was berechnet werden soll. Hierbei manipulieren deklarative Programmiersprachen im Allgemeinen nicht den Zustand des Rechners, sondern dienen der Wertberechnung von Ausdr¨ ucken. Deklara- tive Sprachen lassen sich grob aufteilen in funktionale Programmiersprachen und logische Programmiersprachen.
Logische Programmiersprachen Ein Programm ist eine Menge logischer Formeln (in Prolog:
so genannte Hornklauseln der Pr¨ adikatenlogik), zur Laufzeit werden mithilfe logischer Schl¨ usse (der so genannten Resolution) neue Fakten hergeleitet.
Funktionale Programmiersprachen Ein Programm in einer funktionalen Programmiersprache
besteht aus einer Menge von Funktionsdefinitionen (im engeren mathematischen Sinn). Das
Ausf¨ uhren eines Programms entspricht dem Auswerten eines Ausdrucks, d.h. das Resultat
ist ein einziger Wert. In rein funktionalen Programmiersprachen gibt es keinen Zustand des
Rechners, der manipuliert wird, d.h. es treten bei der Ausf¨ uhrung keine Seiteneffekte (d.h.
sichtbare Speicher¨ anderungen) auf. Vielmehr gilt das Prinzip der referentiellen Transpa- renz : Das Ergebnis einer Anwendung einer Funktion auf Argumente, h¨ angt ausschließlich von den Argumenten ab, oder umgekehrt: Die Anwendung einer gleichen Funktion auf gleiche Argumente liefert stets das gleiche Resultat. Variablen in funktionalen Program- miersprachen bezeichnen keine Speicherpl¨ atze, sondern stehen f¨ ur (unver¨ anderliche) Werte.
1.2. Warum Funktionale Programmierung?
Es stellt sich die Frage, warum die Besch¨ aftigung mit funktionalen Programmiersprachen loh- nenswert ist. Wir f¨ uhren im Folgenden einige Gr¨ unde auf:
• Andere Sichtweise der Probleml¨ osung: W¨ ahrend beim Programmieren in imperativen Pro- grammiersprachen ein Großteil in der genauen Beschreibung besteht, wie auf dem Speicher operiert wird, wird in funktionalen Programmiersprachen eher das Problem bzw. die er- wartete Antwort beschrieben. Man muss dabei meist einen anderen Blick auf das Problem werfen und kann oft von speziellen Problemen abstrahieren und zun¨ achst allgemeine Me- thoden (bzw. Funktionen) implementieren. Diese andere Sichtweise hilft sp¨ ater auch beim Programmieren in imperativen Programmiersprachen, da man auch dort teilweise funktio- nal programmieren kann.
• Elegantere Probleml¨ osung: Im Allgemeinen sind Programme in funktionalen Program- miersprachen verst¨ andlicher als in imperativen Programmiersprachen, auch deshalb, da sie ” mathematischer“ sind.
• Funktionale Programme sind im Allgemeinen mathematisch einfacher handhabbar als im- perative Programme, da kein Zustand betrachtet werden muss. Aussagen wie
” mein Pro- gramm funktioniert korrekt“ oder
” Programm A und Programm B verhalten sich gleich“
lassen sich in funktionalen Programmiersprachen oft mit (relativ) einfachen Mitteln nach- weisen.
• Weniger Laufzeitfehler: Stark und statisch typisierte funktionale Programmiersprachen erlauben es dem Compiler viele Programmierfehler schon w¨ ahrend des Compilierens zu erkennen, d.h. viele falsche Programme werden erst gar nicht ausgef¨ uhrt, da die Fehler schon fr¨ uhzeitig w¨ ahrend des Implementierens entdeckt und beseitigt werden k¨ onnen.
• Testen und Debuggen ist einfacher in (reinen) funktionalen Programmiersprachen, da keine Seiteneffekte und Zust¨ ande ber¨ ucksichtigt werden m¨ ussen. Beim Debuggen kann so ein Fehler unabh¨ angig vom Speicherzustand o.¨ a. reproduziert, gefunden und beseitigt werden.
Beim Testen ist es sehr einfach m¨ oglich, einzelne Funktionen unabh¨ angig voneinander zu testen, sofern referentielle Transparenz gilt.
• Wiederverwendbarkeit und hohe Abstraktion: Funktionen h¨ oherer Ordnung (d.h. Funk- tionen, die Funktionen als Argumente verwenden und auch als Ergebnisse liefern k¨ onnen) erlauben eine hohe Abstraktion, d.h. man kann allgemeine Funktionen implementieren, und diese dann mit entsprechenden Argumenten als Instanz verwenden. Betrachte z.B. die Funktionen summe und produkt, die die Summe und das Produkt einer Liste von Zahlen berechnen (hier als Pseudo-Code):
summe liste =
if ” liste ist leer“ then 0 else
” erstes Element von liste“ + summe
” liste ohne erstes Element“
produkt liste =
if ” liste ist leer“ then 1 else
” erstes Element von liste“ * produkt
” liste ohne erstes Element“
Hier kann man abstrahieren und allgemein eine Funktion implementieren, welche die Ele- mente einer Liste mit einem Operator verkn¨ upft:
reduce e f liste =
if ” liste ist leer“ then e else
f ” erstes Element von liste“ (reduce e f
” liste ohne erstes Element“) Die Funktionen summe und produkt sind dann nur Spezialf¨ alle:
summe liste = reduce 0 (+) liste produkt liste = reduce 1 (*) liste
Die Funktion reduce ist eine Funktion h¨ oherer Ordnung, denn sie erwartet eine Funktion f¨ ur das Argument f.
• Einfache Syntax: Funktionale Programmiersprachen haben im Allgemeinen eine einfache Syntax mit wenigen syntaktischen Konstrukten und wenigen Schl¨ usselw¨ ortern.
• K¨ urzerer Code: Implementierungen in funktionalen Programmiersprachen sind meist we- sentlich k¨ urzer als in imperativen Sprachen.
• Modularit¨ at: Die meisten funktionalen Programmiersprachen bieten Modulsysteme, um den Programmcode zu strukturieren und zu kapseln, aber auch die Zerlegung des Problems in einzelne Funktionen alleine f¨ uhrt meist zu einer guten Strukturierung des Codes. Durch Funktionskomposition k¨ onnen dann aus mehreren (kleinen) Funktionen neue Funktionen erstellt werden.
• Parallelisierbarkeit: Da die Reihenfolge innerhalb der Auswertung oft nicht komplett festge- legt ist, kann man funktionale Programme durch relativ einfache Analysen parallelisieren, indem unabh¨ angige (Unter-) Ausdr¨ ucke parallel ausgewertet werden.
• Multi-Core Architekturen: Funktionale Programmiersprachen bzw. auch Teile davon lie- gen momentan im Trend, da sie sich sehr gut f¨ ur die parallele bzw. nebenl¨ aufige Pro- grammierung eignen, da es keine Seiteneffekte gibt. Deshalb k¨ onnen Race Conditions oder Deadlocks oft gar nicht auftreten, da diese direkt mit Speicherzugriffen zusammenh¨ angen.
• Unver¨ anderliche Datenstrukturen: Eine Konsequenz der referentiellen Transparenz ist, dass Datenstrukturen unver¨ anderlich sind (da Seiteneffekte nicht erlaubt sind.). Daher muss z.B. beim Einf¨ ugen eines Elements in einer Liste eine neue Liste erzeugt werden. Dies hat Vor- und Nachteile: Es gilt Persistenz, denn die alte Liste existiert auch noch. Das Erstellen der neuen Liste kann mittels Sharing so implementiert werden, dass gleiche Tei- le der alten und der neuen Liste nur einmal (gemeinsam) im Speciher gehalten werden.
Eine automatische Garbage Collection entfernt nicht mehr verwendete alte Versionen aus dem Speicher. Vorteile bei Verwendung von unver¨ anderlichen Datenstrukturen ist, dass typische Fallen von ver¨ anderlichen Strukturen nicht auftreten (wie z.B. eine Ver¨ anderung w¨ ahrend der Iteration in einer for-Iteration in Java), dass beim Rekursionsr¨ ucksprung die alten Zust¨ ande noch vorhanden sind und daher nicht wiederhergestellt werden m¨ ussen und bei Nebenl¨ aufigkeit ist kein explizites Kopieren von Datenstrukturen notwendig, wenn nebenl¨ aufige Threads diese Daten gleichzeitig ver¨ andern m¨ ochten.
• Starke Typisierung: Funktionale Sprachen haben fast immer ein starkes Typsystem. Das
Typsystem dient dabei der Aufdeckung von Fehlern durch den Compiler, der Aufl¨ osung
von ¨ Uberladung, der Dokumentation von Funktionen und der Suche passender Funktionen.
Typen k¨ onnen oft automatisch inferiert werden. Fortgeschrittene Typsysteme dienen der Verifikation (z.B. in Agda).
• Nicht zuletzt gibt es viele Forscher, die sich mit funktionalen Programmiersprachen besch¨ aftigen und dort neueste Entwicklungen einf¨ uhren. Diese finden oft Verwendung auch in anderen (nicht funktionalen) Programmiersprachen.
Zur weiteren Motivation f¨ ur funktionale Programmiersprachen sei der schon etwas ¨ altere Artikel
“Why Functional Programming Matters” von John Hughes empfohlen (Hughes, 1989). Aktuel- lere Berichte ¨ uber die Popularit¨ at von funktionalen Programmiersprachen sind beispielsweise:
• John Puopolo, Introduction to Functional Programming, Dr. Dobbs, 6. Januar 2010, http://www.drdobbs.com/windows/222200479
• Michael Swaine, It’s Time to Get Good at Functional Programming, Dr. Doobs, 3. Dezember 2008, http://www.drdobbs.com/tools/212201710
• Christian K¨ ucherer, Uwe Schirmer Renaissance des F, iX – Magazin f¨ ur Informationstech- nik, S. 54-57, 2009
• Neal Ford, Functional thinking: Why functional programming is on the rise, IBM devel- operWorks 2013, http://www.ibm.com/developerworks/library/j-ft20/
1.3. Klassifizierung funktionaler Programmiersprachen
In diesem Abschnitt geben wir einen ¨ Uberblick ¨ uber funktionale Programmiersprachen. Um diese zu klassifizieren, erl¨ autern wir zun¨ achst einige wesentliche Eigenschaften funktionaler Pro- grammiersprachen:
Pure/Impure: Pure (auch reine) funktionale Programmiersprachen erlauben keine Seiteneffekte, w¨ ahrend impure Sprachen Seiteneffekte erlauben. Meistens gilt, dass pure funktionale Pro- grammiersprachen die nicht-strikte Auswertung (siehe unten) verwenden, w¨ ahrend strikte funktionale Programmiersprachen oft impure Anteile haben.
Typsysteme: Es gibt verschiedene Aspekte von Typsystemen anhand derer sich funktionale Programmiersprachen unterscheiden lassen:
stark /schwach: In starken Typsystemen m¨ ussen alle Ausdr¨ ucke (d.h. alle Programme und Unterprogramme) getypt sein, d.h. der Compiler akzeptiert nur korrekt getypte Programme. Bei schwachen Typsystemen werden (manche) Typfehler vom Compiler akzeptiert und (manche) Ausdr¨ ucke d¨ urfen ungetypt sein.
dynamisch/statisch: Bei statischem Typsystem muss der Typ eines Ausdrucks (Pro- gramms) zur Compilezeit feststehen, bei dynamischen Typsystemen wird der Typ zur Laufzeit ermittelt. Bei statischen Typsystemen ist im Allgemeinen keine Typin- formation zur Laufzeit n¨ otig, da bereits w¨ ahrend des Compilierens erkannt wurde, dass das Programm korrekt getypt ist, bei dynamischen Typsystemen werden Typ- information im Allgemeinen zur Laufzeit ben¨ otigt. Entsprechend verh¨ alt es sich mit Typfehlern: Bei starken Typsystemen treten diese nicht zur Laufzeit auf, bei dyna- mischen Typsystemen ist dies m¨ oglich.
monomorph / polymorph: Bei monomorphen Typsystemen haben Funktionen einen fes-
ten Typ, bei polymorphen Typsystemen sind schematische Typen (mit Typvariablen)
erlaubt.
first-order / higher-order: Bei first-order Sprachen d¨ urfen Argumente von Funktionen nur Da- tenobjekte sein, bei higher-order Sprachen sind auch Funktionen als Argumente erlaubt.
Auswertung: strikt / nicht-strikt: Bei der strikten Auswertung (auch call-by-value oder ap- plikative Reihenfolge genannt), darf die Definitionseinsetzung einer Funktionsanwendung einer Funktion auf Argumente erst erfolgen, wenn s¨ amtliche Argumente ausgewertet wur- den. Bei nicht-strikter Auswertung (auch Normalordnung, lazy oder call-by-name bzw.
mit Optimierung call-by-need oder verz¨ ogerte Reihenfolge genannt) werden Argumente nicht vor der Definitionseinsetzung ausgewertet, d.h. Unterausdr¨ ucke werden nur dann ausgewertet, wenn ihr Wert f¨ ur den Wert des Gesamtausdrucks ben¨ otigt wird.
Speicherverwaltung: Die meisten funktionalen Programmiersprachen haben eine automatische Speicherbereinigung (Garbage Collector). Bei nichtpuren funktionalen Programmierspra- chen mit expliziten Speicherreferenzen kann es Unterschiede geben.
Wir geben eine ¨ Ubersicht ¨ uber einige funktionale Programmiersprachen bzw. -sprachklassen.
Die Auflistung ist in alphabetischer Reihenfolge:
Agda: Funktionale Programmiersprache, mit einem Typsystem mit sogenannten abh¨ angigen Ty- pen (dependent types). Kommt mit einem automatischen Beweissystem zur Verifikation von Programmen. Hat eine Haskell-¨ ahnliche Syntax aber eine andere Semantik. Die Spra- che ist total, d.h. Funktionen m¨ ussen terminieren https://wiki.portal.chalmers.se/agda/.
Alice ML: ML Variante, die sich als Erweiterung von SML versteht, mit Unterst¨ utzung f¨ ur Nebenl¨ aufigkeit durch sogenannte Futures, call-by-value Auswertung, stark und sta- tisch typisiert, polymorphes Typsystem, entwickelt an der Uni Saarbr¨ ucken 2000-2007, http://www.ps.uni-saarland.de/alice/
Clean: Nicht-strikte funktionale Programmiersprache, stark und statisch getypt, polymorphe Typen, higher-order, pure, http://wiki.clean.cs.ru.nl/Clean.
Clojure: Lisp-Dialekt, der direkt in Java-Bytecode compiliert wird, dynamisch getypt, spezielle Konstrukte f¨ ur multi-threaded Programmierung (software transactional memory system, reactive agent system) http://clojure.org/
Common Lisp: Lisp-Dialekt, erste Ausgabe 1984, endg¨ ultiger Standard 1994, dynamisch ty- pisiert, auch OO- und prozedurale Anteile, Seiteneffekte erlaubt, strikt, http://common- lisp.net/
Erlang: Strikte funktionale Programmiersprache, dynamisch typisiert, entwickelt von Erics- son f¨ ur Telefonnetze, sehr gute Unterst¨ utzung zur parallelen und verteilten Program- mierung, Ressourcen-schonende Prozesse, entwickelt ab 1986, open source 1998, hot swapping (Code-Austausch zur Laufzeit), Zuverl¨ assigkeit “nine nines”= 99,9999999 %, http://www.erlang.org/
F#: Funktionale Programmiersprache entwickelt von Microsoft ab 2002, sehr angelehnt an OCaml, streng typisiert, auch objektorientierte und imperative Konstrukte, call-by-value, Seiteneffekte m¨ oglich, im Visual Studio 2010 offiziell integriert, http://fsharp.net
Haskell: Pure funktionale Programmiersprache, keine Seiteneffekte, strenges und statisches Typsystem, call-by-need Auswertung, Polymorphismus, Komitee-Sprache, erster Standard 1990, Haskell 98: 1999 und nochmal 2003 leichte Revision, neuer Standard Haskell 2010 (ver¨ offentlicht Juli 2010), http://haskell.org
Lisp: (ende 1950er Jahre, von John McCarthy): steht f¨ ur (List Processing), Sprachfamilie, Spra-
che in Anlehnung an den Lambda-Kalk¨ ul, ungetypt, strikt, bekannte Dialekte Common
Lisp, Scheme
ML: (Metalanguage) Klasse von funktionalen Programmiersprachen: statische Typisierung, Po- lymorphismus, automatische Speicherbereinigung, im Allgemeinen call-by-value Auswer- tung, Seiteneffekte erlaubt, entwickelt von Robin Milner 1973, einige bekannte Varianten:
Standard ML (SML), Lazy ML, Caml, OCaml,
OCaml: (Objective Caml), Weiterentwicklung von Caml (Categorically Abstract Machine Lan- guage), ML-Dialekt, call-by-value, stark und statische Typisierung, polymorphes Typsys- tem, automatische Speicherbereinigung, nicht Seiteneffekt-frei, unterst¨ utzt auch Objekt- orientierung, entwickelt: 1996, http://caml.inria.fr/
Scala: Multiparadigmen Sprache: funktional, objektorientiert, imperativ, 2003 entwickelt, l¨ auft auf der Java VM, funktionaler Anteil: Funktionen h¨ oherer Ordnung, Anonyme Funktionen, Currying, call-by-value Auswertung, statische Typisierung, http://www.scala-lang.org/
Scheme: Lisp-Dialekt, streng und dynamisch getypt, call-by-value, Seiteneffekte er- laubt, eingef¨ uhrt im Zeitraum 1975-1980, letzter Standard aus dem Jahr 2007, http://www.schemers.org/
SML: Standard ML, ML-Variante: call-by-value, entwickelt 1990, letzte Standardisierung 1997, Sprache ist vollst¨ andig formal definiert, Referenz-Implementierung: Standard ML of New Jersey http://www.smlnj.org/.
Wir werden in dieser Vorlesung die nicht-strikte funktionale Programmiersprache Haskell ver- wenden und uns auch von der theoretischen Seite an Haskell orientieren.
1.4. Inhalte
Wir behandeln vertiefende Themen der Funktionalen Programmierung und Funktionaler Pro- grammiersprachen. Einerseits werden theoretische Grundlagen behandelt (z.B. Syntax, Seman- tik und Typisierung von (Kern-)sprachen funktionaler Programmiersprachen) und andererseits werden fortgeschrittene Techniken der funktionaler Programmierung behandelt (z.B. Behand- lung von I/O und Effekten, Nebenl¨ aufige und Parallele Programme, Testen und Verifikation, Entwicklung ereignisgesteuerter Anwendungen wie Webapplikationen und graphischer Benutze- roberfl¨ achen).
1.5. Weiteres Material
1.5.1. Literatur
Zu Haskell und auch zu einigen weiteren Themen zu Haskell und Funktionalen Programmier- sprachen gibt es einige B¨ ucher, die je nach Geschmack und Vorkenntnissen einen Blick wert sind:
Bird, R.
Thinking Functionally with Haskell, Cambridge University Press, 2014
Gutes Buch, deckt einige Themen der Vorlesung ab.
Bird, R.
Introduction to Functional Programming using Haskell.
Prentice Hall PTR, 2 edition, 1998.
Alteres Buch, deckt viele Themen der Vorlesung ab. ¨ Davie, A. J. T.
An introduction to functional programming systems using Haskell.
Cambridge University Press, New York, NY, USA, 1992.
Alteres aber gutes Buch zur Programmierung in Haskell. ¨ Thompson, S.
Haskell: The Craft of Functional Programming.
Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1999.
Guter ¨ Uberblick ¨ uber Haskell Hutton, G.
Programming in Haskell.
Cambridge University Press, 2007.
Knapp geschriebene Einf¨ uhrung in Haskell.
Chakravarty, M. & Keller, G.
Einf¨ uhrung in die Programmierung mit Haskell.
Pearson Studium, 2004
Einf¨ uhrung in die Informatik mit Haskell, eher ein Anf¨ angerbuch.
Bird, R. & Wadler, P.
Introduction to Functional Programming.
Prentice-Hall International Series in Computer Science. Prentice-Hall International, Upper Saddle River, NJ, USA, 1988.
Altere aber gute Einf¨ ¨ uhrung in die funktionale Programmierung, Programmiersprache:
Miranda.
Lipovaca, M.
Learn You a Haskell for Great Good! A Beginner’s Guide No Starch Press, 2011.
Online-Version:http://learnyouahaskell.com/.
umfassende Einf¨ uhrung in Haskell.
Marlow, S.
Parallel and Concurrent Programming in Haskell O’Reilly, ISBN 9781449335939, 2013.
Online-Version: www.oreilly.com/library/view/parallel-and-concurrent/9781449335939 . beschreibt paralleles und nebenl¨ aufiges Programmieren in Haskell.
O’Sullivan, B., Goerzen, J., & Stewart, D.
Real World Haskell.O’Reilly Media, Inc, 2008.
Online-Version: http://book.realworldhaskell.org/read/
Programmierung in Haskell f¨ ur Real-World Anwendungen Pepper, P..
Funktionale Programmierung in OPAL, ML, HASKELL und GOFER.
Springer-Lehrbuch, 1998. ISBN 3-540-64541-1.
Einf¨ uhrung in die funktionale Programmierung mit mehreren Programmiersprachen.
Pepper, P. & Hofstedt, P.
Funktionale Programmierung – Weiterf¨ uhrende Konzepte und Techniken.
Springer-Lehrbuch. ISBN 3-540-20959-X, 2006.
beschreibt einige tiefergehende Aspekte.
Peyton Jones, S. L.
The Implementation of Functional Programming Languages.
Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1987.
Sehr gutes Buch ¨ uber die Implementierung von Funktionalen Programmiersprachen.
Snoyman, M.
Developing Web Applications with Haskell and Yesod, O’Reilly, 2012. ISBN 1449316972.
Online-Version:https://www.yesodweb.com/book.
Programmieren mit dem Web-Framework Yesod.
Zum Lambda-Kalk¨ ul seien u.a. empfohlen:
Barendregt, H. P.
The Lambda Calculus. Its Syntax and Semantics.
North-Holland, Amsterdam, New York, 1984.
Standardwerk zum Lambda-Kalk¨ ul, eher Nachschlagewerk, teilweise schwer zu lesen.
Hankin, C.
An introduction to lambda calculi for computer scientists.
Number 2 in Texts in Computing. King’s College Publications, London, UK, 2004.
Sehr gute Einf¨ uhrung zum Lambda-Kalk¨ ul Lohnenswert ist auch ein Blick in das Buch:
Pierce, B. C.,
Types and programming languages.
MIT Press, Cambridge, MA, USA, 2002.
das sich allerdings an ML als Programmiersprache orientiert.
1.5.2. Webseiten, etc
Es gibt zahlreiche Webseiten zu Haskell. Ein zentrale ¨ Ubersicht bzw. Anlaufstelle ist das Haskell Wiki: http://www.haskell.org/haskellwiki. Es gibt aber auch spezialisierte Suchmaschinen, z.B. Hoogle http://haskell.org/hoogle. Diese durchsucht die Paket-Dokumentationen. Man kann z.B. auch nach Typen suchen, um Funktionen dieses Typs zu finden.
Bei speziellen Fragen sind die Haskell-Mailinglisten eine gute Anlaufstelle, um Fragen zu stellen:
• haskell-cafe@haskell.org
• beginners@haskell.org
• haskell@haskell.org
Auch auf Code-Probleme spezialisierte Webseiten k¨ onnen Haskell-Programmierer helfen:
http://stackoverflow.com/questions/tagged/haskell
Eine Einf¨ uhrung in wichtige Konstrukte von Haskell 2
In diesem Kapitel werden wir die verschiedenen Konstrukte der funktionalen Programmierspra- che Haskell er¨ ortern.
2.1. Einf¨ uhrung und Werkzeuge
Haskell (https://www.haskell.org/) ist eine Effekt-freie rein funktionale Sprache mit verz¨ ogerter Auswertung. Sie ist benannt nach dem US-amerikanischen Logiker Haskell B. Curry (1900- 1982). Die beiden neuesten Standards der Sprachen sind Haskell 98 und Haskell 2010. Es gibt verschiedene Implementierungen von Haskell, wobei der Glasgow Haskell Compiler (GHC) htt- ps://www.haskell.org/ghc/ der wichtigste ist. Die Dokumentation des Compilers ist online via https://downloads.haskell.org/ghc/latest/docs/html/users guide/ verf¨ ugbar, die Dokumentati- on der Standardbibliotheken ist unter http://www.haskell.org/ghc/docs/latest/html/libraries/
zu finden. Wir empfehlen eine Installation mittels stack (siehe http://haskellstack.org). Neben dem ¨ Ubersetzen in ausf¨ uhrbaren Code, kann der GHC auch als Interpreter verwendet werden (GHCi). Dort kann man direkt Ausdr¨ ucke eingeben und auswerten lassen:
> stack exec -- ghci
GHCi, version 8.6.5: http://www.haskell.org/ghc/ :? for help Prelude> 1+2
3
Prelude> 10 * (2 + 4) 60
Prelude> 14 `mod` 6 2
Mit den Pfeiltasten kann man die vorherigen Eingaben durchbl¨ attern Zur Steuerung des Inter- preters stehen Befehle zur Verf¨ ugung, welche alle mit einem Doppelpunkt beginnen, z.B. :? f¨ ur die Hilfe. Befehle kann man abk¨ urzen, z.B. kann man :quit also auch mit :q den Interpreter ver- lassen. ¨ Uberlicherweise macht man Programmdefinitionen mit einem gew¨ ohnlichen Texteditor in einer separate Datei und l¨ adt diese dann in den Interpreter:
:l datei.hs -- lade Definition aus Datei datei.hs :r -- erneut alle offenen Dateien einlesen
Haskell-Quellcodedateien enden mit .hs oder mit .lhs, wobei letztere Quellcode als Literate-
Haskell-Programm erwarten. In normalen Haskell-Quellcodedateien (deren Dateiendung .hs lau-
tet) werden Kommentare explizit gekennzeichnet: Mit -- wird ein Zeilenkommentar eingeleitet,
alles was danach kommt, bis zum Ende der Zeile wird ignoriert. Mit {- und -} wird ein mehr-
zeiliger Kommentar geklammert. Alles was zwischen dem ¨ offnenden {- und dem schließenden
-} steht, wird als Kommentar behandelt (und vom Compiler ignoriert).
Bei Literate-Haskell-Programm ist die Idee, dass s¨ amtliche Zeilen in der Datei als Kommentar angesehen werden, solange sie nicht als Code gekennzeichnet werden. Im sogenannten Bird-Stil (benannt nach Richard Bird) werden Zeilen, die mit > beginnen, als Codezeilen interpretiert.
Ein solcher Code-Block muss mit einer Leerzeile am Anfang und am Ende eingeleitet werden (ansonsten wird der Fehler
” unlit: Program line next to comment gemeldet“. Ein Beispiel f¨ ur ein Literate-Haskell-Programm im Bird-Style ist:
Hier steht beliebiger Kommentar, der sich auch ¨ uber mehrere Zeile erstrecken kann.
> meineFunktion [] = putStrLn "Hallo Welt"
> meineFunktion (_:rs) = do
> putStrLn "Hallo Welt"
> meineFunktion rs
Hier steht erneut ein Kommentar.
Im latex-Stil werden Code-Bl¨ ocke durch \begin{code} und \end{code} gekennzeichnet, obiges Programm wird dann als
Hier steht beliebiger Kommentar, der sich auch ¨ uber mehrere Zeile erstrecken kann.
\begin{code}
meineFunktion [] = putStrLn "Hallo Welt"
meineFunktion (_:rs) = do
putStrLn "Hallo Welt"
meineFunktion rs
\end{code}
Hier steht erneut ein Kommentar.
Haskell beachtet die Groß-/Kleinschreibung und es ist daher nicht egal, ob man etwas klein oder groß schreibt. Ebenso ist Haskell “whitespace”-sensitiv, d.h. insbeondere Ver¨ anderungen an Leerzeichen, Tabulatoren und Zeilenumbruch k¨ onnen Fehler verursachen. Statt Einr¨ uckung kann man auch geschweifte Klammern { } und Semikolons ; verwenden. Es empfiehlt sich Tabulatoren nicht zu verwenden, sondern (am besten durch den Text-Editor) durch Leerzeichen zu ersetzen. Hinweise zur Verwendung von Editoren und IDEs findet man unter https://wiki.
haskell.org/IDEs.
Zudem gilt in Haskell im Allgmeinen als Daumenregel: Beginnt die n¨ achste Zeile in einer Spalte weiter rechts als die vorherige, dann geht die vorherige Zeile weiter, beginnt die n¨ achste Zeile in der gleichen Spalte wie die vorherige, dann beginnt das n¨ achste Element eines Blocks, und beginnt die Zeile weiter links als die vorherig, dann ist der Block beendet.
2.2. Einf¨ uhrendes zu Typen in Haskell
2.2.1. Syntax und Sprechweisen
Ein Typ ist eine Menge von Werten, z.B. bezeichnet der Typ Int meistens die Menge der ganzen
Zahlen von −2 63 bis 2 63 − 1. In Haskell beginnen Typnamen stets mit einem Großbuchstaben
und Typvariablen beginnen stets mit einem Kleinbuchstaben.
Im GHCi kann mit :type Ausdruck der Typ eines Ausdrucks angezeigt werden Prelude> :type 'a'
'a' :: Char
Gilt e :: T, so sagt man
” Ausdruck e hat Typ T “ oder alternativ
” Ausdruck e ist vom Typ T“ Mit dem Befehl :set +t wird der Typ jedes ausgewerteten Ausdrucks angezeigt im GHCi angezeigt, mit :unset +t stellt man das wieder ab.
Die Syntax von Typen (ohne Typklassenbeschr¨ ankungen) in Haskell ist T ::= T V | T C T 1 . . . T n | T 1 -> T 2
wobei T V f¨ ur eine Typvariable steht (die mit einem Kleinbuchstaben beginnen muss) und T C ein Typkonstruktor mit Stelligkeit n ist (Typkonstruktoren beginnen mit einem Großbuchstaben, oder – wenn sie infix verwendet werden, mit einem Doppelpunkt). Das Konstrukt T 1 -> T 2
stellt einen Funktionstypen dar, d.h. es ist der Typ von Funktionen die als Eingabe Werte des Typs T 1 bekommt und als Ausgabe Werte des Typs T 2 liefert
Man unterscheidet noch die Sprechweisen f¨ ur verschiedene Typen. Eingebaute, vordefinierte Typen, nennt man Basistypen. Das entspricht in obiger Syntax den nullstelligen Typkonstrukto- ren. Diese haben keine Typvariablen und sind auch nicht aus anderen Typen zusammengesetzt.
Ein Beispiel ist der Typ Int f¨ ur Ganzzahlen beschr¨ ankter Gr¨ oße, oder auch der Typ Bool f¨ ur Wahrheitswerte. Grundtypen oder auch monomorphe Typen sind Typen, die keine Typvariablen enthalten. D.h. jedes Basistyp ist auch ein Grundtyp, aber z.B. sind die Typen Baum Int (ein Baum mit Zahlen als Blattmarkierungen), [(Int,Bool)] (eine Liste von Paaren bestehend aus Zahlen und Wahrheitswerten) oder Int -> Bool (eine Funktion von Int nach Bool) ebenfalls Grundtypen, da sie keine Typvariablen enthalten. Ein polymorpher Typ darf auch Typvariablen enthalten, z.B. ist [a] oder auch a -> a ein polymorpher Typ.
2.2.2. Wichtige Basistypen und weitere Typen 2.2.2.1. Arithmetische Operatoren und Zahlen
Haskell verf¨ ugt ¨ uber eingebaute Typen f¨ ur
• ganze Zahlen beschr¨ ankter Gr¨ oße Int, deren Bereich ist maschinenabh¨ angig, er reicht jedoch mindestens von −2 29 bis 2 29 − 1. Es wird nicht auf ¨ Uberl¨ aufe gepr¨ uft.
• ganze Zahlen beliebiger L¨ ange Integer,
• Gleitkommazahlen Float,
• Gleitkommazahlen mit doppelter Genauigkeit Double,
• rationale Zahlen Rational (bzw. verallgemeinert Ratio α, wobei α eine Typvariable ist.
Der Typ Rational ist nur ein Synonym f¨ ur Ratio Integer, die Darstellung ist x % y).
Zur Verwendung muss das Modul Data.Ratio immportiert werden, denn dort wird der Operator % definiert.
Die ¨ ublichen Rechenoperationen sind verf¨ ugbar f¨ ur alle diese Zahlen:
• + f¨ ur die Addition
• - f¨ ur die Subtraktion
• * f¨ ur die Multiplikation
• / f¨ ur die Division
• mod f¨ ur die Restberechnung
• div f¨ ur den ganzzahligen Anteil einer Division mit Rest
Die Operatoren k¨ onnen f¨ ur alle Zahl-Typen benutzt werden, d.h. sie sind ¨ uberladen. Diese ¨ Uber- ladung funktioniert durch Typklassen (genauer sehen wir das sp¨ ater in Abschnitt 4). Die Ope- rationen (+), (-), (*) sind f¨ ur alle Typen der Typklasse Num definiert, daher ist deren Typ Num a => a -> a -> a.
Eine kleine Anmerkung zum Minuszeichen: Da dieses sowohl f¨ ur die Subtraktion als auch f¨ ur negative Zahlen verwendet wird, muss man hier ¨ ofter Klammern setzen, damit ein Ausdruck geparst werden kann, z.B. ergibt 1 + -2 einen Parserfehler, richtig ist 1 + (-2).
2.2.2.2. Weitere wichtige Typen: Bool, Char, String
Neben Zahlen gibt es noch weitere wichtige grundlegende Typen:
Bool Boolesche (logische) Wahrheitswerte: True und False
Char Unicode Zeichen, z.B. 'q'. Diese werden immer in Apostrophen eingeschlossen.
String Zeichenketten, z.B. "Hallo!". Diese werden immmer in Anf¨ uhrungszeichen eingeschlos- sen.
Von diesen drei Typen ist lediglich Char wirklich speziell eingebaut, die beiden anderen kann man leicht selbst definieren:
type String = [Char] -- Typsynonym data Bool = True | False
Die Standardbibliothek (die sogenannte Prelude) definiert u.a. folgende Funktionen
• && Konjunktion, logisches Und
• || Disjunktion, logisches Oder
• not Negation, Verneinung
• == Test auf Gleichheit
• /= Test auf Ungleichheit
Prelude> (True || False) && (not True) False
Prelude> True == False False
Prelude> False /= True True
Die ¨ ublichen Vergleichsoperationen f¨ ur Zahlen sind auch eingebaut:
• == f¨ ur den Gleichheitstest (der Typ ist (==) :: (Eq a) => a -> a -> Bool, d.h. die zugeh¨ orige Typklasse ist Eq)
• /= f¨ ur den Ungleichheitstest
• <, <=, >, >=, f¨ ur kleiner, kleiner gleich, gr¨ oßer und gr¨ oßer gleich (der Typ ist
(Ord a) => a -> a -> Bool, d.h. die zugeh¨ orige Typklasse ist Ord).
In Haskell sind Priorit¨ aten und Assoziativit¨ aten f¨ ur die Operatoren vordefiniert und festgelegt (durch die Schl¨ usselw¨ orter infixl (links-assoziativ), infixr (rechts-assoziativ) und infix (nicht assoziativ, Klammern m¨ ussen immer angegeben werden). Die Priorit¨ at wird durch eine Zahl angegeben. Z.B. sind in der Prelude vordefiniert:
infixr 9 .
infixr 8 ^, ^^, **
infixl 7 *, /, `quot`, `rem`, `div`, `mod`
infixl 6 +, -
-- The (:) operator is built-in syntax, and cannot -- legally be given a fixity declaration; but its -- fixity is given by:
-- infixr 5 :
infix 4 ==, /=, <, <=, >=, >
infixr 3 &&
infixr 2 ||
infixl 1 >>, >>=
infixr 1 =<<
infixr 0 $, $!, `seq`
Diese k¨ onnen auch f¨ ur selbst definierte Operatoren verwendet werden: W¨ ahrend Funktions- namen mit einem Kleinbuchstaben oder _ beginnen m¨ ussen, bestehen Operatoren nur aus Symbolen, die keine alphanumerischen Zeichen sind. Operatoren werden standardm¨ aßig infix verwendet, w¨ ahrend Funktionen standardm¨ aßig pr¨ afix verwendet werden. Man kann in Haskell Pr¨ afix-Operatoren auch infix verwenden, indem man sie in Hochkommata setzt, z.B. ist mod 5 2
¨ aquivalent zu 5 ‘mod‘ 2. Umgekehrt kann man Infix-Operatoren auch pr¨ afix verwenden, indem man sie einklammert, z.B. ist 1 + 2 ¨ aquivalent zu (+) 1 2
2.3. Algebraische Datentypen in Haskell
Haskell stellt (eingebaute und benutzerdefinierte) Datentypen bzw. Datenstrukturen zur Verf¨ ugung.
2.3.1. Aufz¨ ahlungstypen
Ein Aufz¨ ahlungstyp ist ein Datentyp, der aus einer Aufz¨ ahlung von Werten besteht. Die Kon- struktoren sind dabei Konstanten (d.h. sie sind nullstellig). Ein vordefinierter Aufz¨ ahlungstyp ist der Typ Bool mit den Konstruktoren True und False. Allgemein l¨ asst sich ein Aufz¨ ahlungstyp mit der data-Anweisung wie folgt definieren:
data Typname = Konstante 1 | Konstante 2 | . . . | Konstante N
Ein Beispiel f¨ ur einen selbst-definierten Datentyp ist der Typ Wochentag:
data Wochentag = Montag
| Dienstag
| Mittwoch
| Donnerstag
| Freitag
| Samstag
| Sonntag deriving(Show)
Bemerkung 2.3.1. F¨ ugt man einer Data-Definition die Zeile deriving(...) hinzu, wobei ...
verschiedene Typklassen sind, so versucht der Compiler automatisch Instanzen f¨ ur den Typ zu generieren, damit man die Operationen wie == f¨ ur den Datentyp automatisch verwenden kann.
Oft f¨ ugen wir deriving(Show) hinzu. Diese Typklasse erlaubt es, Werte des Typs in Strings zu verwandeln, d.h. man kann sie anzeigen. Im Interpreter wirkt sich das Fehlen einer Instanz so aus:
*Main> Montag
<interactive>:1:0: error:
• No instance for (Show Wochentag) arising from a use of ‘print’
• In a stmt of an interactive GHCi command: print it Mit Show-Instanz kann der Interpreter die Werte anzeigen:
*Main> Montag Montag
Die Werte eines Summentyps k¨ onnen mit mit einem case-Ausdruck abgefragt werden, und eine entsprechende Fallunterscheidung kann damit durchgef¨ uhrt werden. Z.B.
istMontag :: Wochentag -> Bool istMontag x = case x of
Montag -> True Dienstag -> False Mittwoch -> False Donnerstag -> False Freitag -> False Samstag -> False Sonntag -> False
Haskell erlaubt es auch, eine default-Alternative im case zu verwenden. Dabei wird anstelle des Patterns eine Variable verwendet, diese bindet den gesamten Ausdruck, d.h. in Haskell kann istMontag k¨ urzer definiert werden:
istMontag' :: Wochentag -> Bool istMontag' x = case x of
Montag -> True y -> False
Haskell bietet auch die M¨ oglichkeit (verschachtelte) Pattern links in einer Funktionsdefinition zu benutzen und die einzelnen F¨ alle durch mehrere Definitionsgleichungen abzuarbeiten z.B.
istMontag'' :: Wochentag -> Bool istMontag'' Montag = True
istMontag'' _ = False
Hierbei ist eine namenslose Variable (
” Wildcard“), die wie eine Variable wirkt aber rechts nicht
benutzt werden kann.
2.3.2. Produkttypen
Produkttypen fassen verschiedene Werte zu einem neuen Typ zusammen. Die bekanntesten Produkttypen sind Paare und mehrstellige Tupel.
Definition 2.3.2 (Kartesisches Produkt). Sind A 1 , . . . A n Mengen, so ist das kartesische Pro- dukt definiert als A 1 × · · · × A n =
(a 1 , . . . , a n ) | a i ∈ A i f¨ ur i = 1 . . . n
Die Elemente von A 1 × · · · × A n heißen allgemein n-Tupel, spezieller auch Paare, Tripel, Qua- drupel, . . .
In Haskell schreiben wir Tupelausdr¨ ucke und Tupeltypen mit runden Klammern und Kommas.
Z × Z wird zu (Int,Int).
Prelude> :t (True, 'a', 7)
(True, 'a', 7) :: (Bool, Char, Int) Prelude> :t (4.5,"Hi!")
(4.5,"Hi!") :: (Double, String)
Das 0-Tupel ist ebenfalls in Haskell erlaubt: () :: (). Der Typ () wird als Unit-Typ bezeichnet, und hat nur den einzigen Wert (). Aus dem Kontext wird fast immer klar, ob mit () der Typ oder der Wert gemeint ist.
Mit data k¨ onnen auch Produkttypen definiert werden (die keine Tupelsyntax verwenden). Die Syntax hierf¨ ur ist
data Typname = KonstruktorName Typ 1 Typ 2 . . . Typ N
Ein Beispiel ist der folgende Datentyp Student:
data Student = Student
String -- Name String -- Vorname
Int -- Matrikelnummer
In diesem Beispiel gibt es eine (in Haskell erlaubte) Namens¨ uberlappung: Sowohl der Typ als auch der Datenkonstruktor heißen Student. Mit Pattern-Matching und case-Ausdr¨ ucken kann man die Datenstruktur zerlegen und auf die einzelnen Komponenten zugreifen, z.B.
setzeName :: Student -> String -> Student setzeName x name' =
case x of
(Student name vorname mnr) -> Student name' vorname mnr Alternativ mit Pattern auf der linken Seite der Funktionsdefinition:
setzeName' :: Student -> String -> Student
setzeName' (Student name vorname mnr) name' = Student name' vorname mnr
F¨ ur Produkttypen bietet Haskell noch die so genannte Record-Syntax, die wir im n¨ achsten Abschnitt behandeln werden.
Zuvor sei noch erw¨ ahnt, dass man Aufz¨ ahlungstypen und Produkttypen verbinden kann, z.B.
kann man einen Datentyp f¨ ur 3D-Objekte definieren:
data DreiDObjekt = Wuerfel Int -- Kantenlaenge
| Quader Int Int Int -- Drei Kantenlaengen
| Kugel Int -- Radius
Als weiteres Beispiel definieren wir einen Datentyp f¨ ur Fr¨ uchte:
data Frucht = Apfel (Int,Double)
| Birne Int Double
| Banane Int Int Double
Allgemein kann man einen solchen Typ definieren als data Typ = Typ 1 | . . . | Typ n
wobei Typ 1 ,. . . ,Typ n selbst komplexe Typen sind, z.B. Produkttypen. Man nennt diese Klasse von Typen (aufgrund der mit | getrennten Alternativen) oft auch Summentypen.
2.3.2.1. Record-Syntax
Haskell bietet neben der normalen Definition von Datentypen auch die M¨ oglichkeit eine spezi- elle Syntax zu verwenden, die insbesondere dann sinnvoll ist, wenn ein Datenkonstruktor viele Argumente hat.
Wir betrachten zun¨ achst den normal definierten Datentypen Student als Beispiel:
data Student = Student
String -- Vorname String -- Name
Int -- Matrikelnummer
Ohne die Kommentare ist nicht ersichtlich, was die einzelnen Komponenten darstellen. Außerdem muss man zum Zugriff auf die Komponenten neue Funktionen definieren. Beispielsweise
vorname :: Student -> String
vorname (Student vorname name mnr) = vorname
Wenn nun ¨ Anderungen am Datentyp vorgenommen werden – zum Beispiel eine weitere Kom- ponente f¨ ur das Hochschulsemester wird hinzugef¨ ugt – dann m¨ ussen alle Funktionen angepasst werden, die den Datentypen verwenden:
data Student = Student
String -- Vorname String -- Name
Int -- Matrikelnummer Int -- Hochschulsemester
Um diese Nachteile zu vermeiden, bietet es sich an, die Record-Syntax zu verwenden. Diese erlaubt zum Einen die einzelnen Komponenten mit Namen zu versehen:
data Student = Student {
vorname :: String,
name :: String,
matrikelnummer :: Int
}
Eine konkrete Instanz w¨ urde mit der normalen Syntax initialisiert mittels Student "Hans" "Mueller" 1234567
F¨ ur den Record-Typen ist dies genauso m¨ oglich, aber es gibt auch die M¨ oglichkeit die Namen zu verwenden:
Student{vorname="Hans", name="Mueller",
matrikelnummer=1234567}
Hierbei spielt die Reihenfolge der Eintr¨ age keine Rolle, z.B. ist Student{vorname="Hans",
matrikelnummer=1234567, name="Mueller"
}
genau dieselbe Instanz.
Zugriffsfunktionen f¨ ur die Komponenten brauchen nicht zu definiert werden, diese sind sofort vorhanden und tragen den Namen der entsprechenden Komponente. Z.B. liefert die Funktion matrikelnummer angewendet auf eine Student-Instanz dessen Matrikelnummer. Wird der Daten- typ jetzt wie oben erweitert, so braucht man im Normalfall wesentlich weniger ¨ Anderungen am bestehenden Code.
Die Schreibweise mit Feldnamen darf auch f¨ ur das Pattern-Matching verwendet werden. Hierbei m¨ ussen nicht alle Felder spezifiziert werden. So ist z.B. eine Funktion, die testet, ob der Student einen Nachnamen beginnend mit 'A' hat, implementierbar als
nameMitA Student{name = 'A':xs} = True nameMitA _ = False
Diese Definition ist ¨ aquivalent zur Definition nameMitA (Student ('A':xs) _ _) = True
nameMitA _ = False
Die Record-Syntax kann auch benutzt werden, um
” Updates“ durch zu f¨ uhren 1 . Hierf¨ ur ver- wendet man die nachgestellte Notation {feldname = ...} . Die nicht ver¨ anderten Werte braucht man dabei nicht neu zu setzen. Wir betrachten ein konkretes Beispiel:
setzeName :: Student -> String -> Student
setzeName student neuername = student {name = neuername}
Die Funktion setzt den Namen eines Studenten neu. Sie ist ¨ aquivalent zu:
setzeName :: Student -> String -> Student setzeName student neuername =
Student {vorname = vorname student, name = neuername,
matrikelnummer = matrikelnummer student}
1