Research Collection
Bachelor Thesis
Reading ROOT Files as Apache Arrow Tables
Author(s):
Enzler, Eric Publication Date:
2020-09
Permanent Link:
https://doi.org/10.3929/ethz-b-000457539
Rights / License:
Creative Commons Attribution-ShareAlike 4.0 International
Bachelor’s Thesis Nr. 309b
Systems Group, Department of Computer Science, ETH Zurich
Reading ROOT Files as Apache Arrow Tables
by Eric Enzler
Supervised by
Dr. Ingo Müller, Dr. Ghislain Fourny, Prof. Dr. Gustavo Alonso
April 2020 - September 2020
Contents
1 Introduction 2
2 ROOT 3
2.1 Criticism . . . 3
2.2 Alternatives . . . 3
3 Apache Arrow 4 4 Mapping 5 4.1 RDataFrame . . . 5
4.2 Table . . . 5
4.3 Conversion Plan . . . 5
4.4 Types . . . 6
5 Code Implementation 8 5.1 Starting method . . . 8
5.2 Type Matching and ArrayBulding . . . 9
5.3 Struct support . . . 10
6 Performance Analysis 12 6.1 Setup . . . 12
6.2 Timing . . . 12
6.3 Speed . . . 13
6.4 Correctness . . . 15
7 Showcase 16 7.1 Writing Parquet files . . . 16
8 Summary 17 8.1 Future Work . . . 17
8.2 Conclusion . . . 17
List of Figures
1 Common Arrow Data Layer [2] . . . 42 Conversion Plan . . . 6
3 Execution time analysis . . . 13
4 In-depth execution time analysis . . . 14
5 Percentual execution time . . . 15
1 Introduction
The ROOT data format is by far the most widespread tool for analysis of High Energy Physics data (HEP) today. Physicists in this field deal with massive amounts of data in the size of gigabytes to terabytes. The ROOT framework [1] has support for a lot of aspects of modern data analysis, including read- ing and writing ROOT files, plotting functions to create histograms, commonly used statistics functions and parallelization within and across multiple machines.
Despite the wide-spreadness of ROOT, people are increasingly looking for alter- natives for analysing ROOT files. The goal of these alternatives is clear: Read and write ROOT files outside of the ROOT framework. While some of these alternatives are already very successful, they repeat the implementation effort of reading and writing ROOT files and might thus only achieve partial support for the ROOT format, lag behind in version changes or create files that are incompatible.
The goal of this project is to find out whether the Apache Arrow format [2]
is able to deal with the data typically stored in ROOT files. Thus, the project consists of multiple parts. First, a typical access pattern to ROOT files needs to be found. Second, a mapping from ROOT to Apache Arrow needs to be created and coded. The data model of Apache Arrow seems expressive enough to cap- ture the (logical) types typically used in ROOT files, namely statically typed records of atoms and arrays thereof. The final mechanism should take a ROOT file as input and produce an Apache Arrow Table. This would allow any of the numerous tools that support Arrow to indirectly read from ROOT files. Finally, we want to analyse the performance and accuracy of our implementation.
2 ROOT
ROOT is a framework that was originally designed for particle physics data analysis. Not only does it serve in high-energy physics (HEP) but also in as- tronomy and data mining. The development of the framework started in 1994 by Ren´e Brun and Fons Rademakers and was programmed in C++, following an object oriented design. ROOT deals with massive amounts of data and is therefore designed for high computing efficiency. The data that is collected from the Large Hadron Collider [3], the famous particle collider of CERN in Geneva, is being analysed with ROOT. We are hereby talking about 15 petabytes of data per year.
2.1 Criticism
Criticism [4] about ROOT includes a variety of fields. First, ROOT is not beginner friendly. It takes a lot of time to understand how ROOT works, de- spite various code examples for C++ and a large documentation. This even applies to experienced programmers. Second, ROOT’s class system is very complex. ROOT implements a massive amount of classes with a literal jungle of inheritance relations. Third, the ROOT interpreter Cling introduces various problems. When executing a C++ file in the ROOT command prompt, the interpreter takes a lot of time compiling until the execution of the file starts.
Furthermore, a file may not compile if modern C++ features, such as std::future (used for multi-threading), are used. For this project, we had to work with dif- ferent libraries and therefore with problems handing these libraries to Cling . It took us multiple weeks to find a work-around because the interpreter had issues with said libraries.
2.2 Alternatives
Users want to analyse ROOT files outside of the ROOT framework. The prob- lem is that ROOT has been around for so long that is has become a very complex framework with thousands of features that cannot just be recreated without tons of effort. Therefore, most alternatives [5] only support a subset of the whole ROOT framework. Since all alternatives share the same goal, namely reading and writing ROOT files, they repeat the same effort over and over again.
It is important to note that none of these alternatives provide a function to convert a ROOT file directly to an Apache Arrow table. However, one could convert a ROOT file to a Pandas data frame using one of the ROOT alterna- tives. Since Pandas is integrated into the Arrow family, a conversion could be done in a few lines of code. However, this introduces all the drawbacks from Pandas as well as drawbacks from the ROOT file reader.
3 Apache Arrow
Apache Arrow is a cross-language development platform for in-memory data.
Arrow specifies a standardized columnar memory format that is organized for efficient analysis on modern hardware. Furthermore, it provides computational libraries, zero-copy streaming messaging and inter-process communication. The languages that Arrow currently supports include C, C++, C#, Java, Python and many more. Apache Arrow is backed by key developers of major open source projects, including Drill, Hadoop, Pandas and Parquet. This fact makes it the de facto standard for columnar in-memory analysis.
Example: Imagine you are working on a Microsoft Excel sheet. You have a table with information about your schoolmates in front of you. Every person on this list has a name, address and phone number. Every row denotes a new person. Usually, a computer would store this table row by row, meaning that all information about a person is next to each other in the memory buffer. First we store person 1, next person 2 and so on. In the case of Apache Arrow, the computer would first store all names, all addresses and then all phone numbers.
Now the computer can exploit this storage format and perform computations on all the phone numbers in parallel, which is very fast.
A columnar memory layout avoids unnecessary IO and therefore accelerates analytical performance on modern GPUs and CPUs. Arrow exploits the SIMD (Single Instruction Multiple Data) instruction sets of modern processing units to accelerate analysis speed. In a bigger picture, Apache Arrow creates a common data layer that can be used by different systems and therefore removes overhead for cross-system communication. Applications that use Arrow can trade data directly in Arrow’s format. Figure 1 shows an abstraction of this common Data Layer.
Figure 1: Common Arrow Data Layer [2]
4 Mapping
4.1 RDataFrame
RDataFrame [6] is a ROOT class that offers a high level interface for analyses of data stored in TTrees. A TTree is a typical data container that holds a collection of Branches and each Branch holds data in the form of an array. The TTree is the most commonly used data container for experimental data. The RDataFrame itself holds columns of data and stores information about their types and names. It is the ROOT equivalent of the two-dimensional Apache Arrow datasets.
4.2 Table
Apache Arrow has two different containers for storing two-dimensional datasets;
Table and RecordBatch. The difference between the two is that the RecordBatch consists of equal-length columns. For this project, we convert explicitly to Arrow Tables because we cannot be sure if the data in a ROOT file consists of equal-length arrays and furthermore, a user can simply convert from Table to RecordBatch but not vice versa.
4.3 Conversion Plan
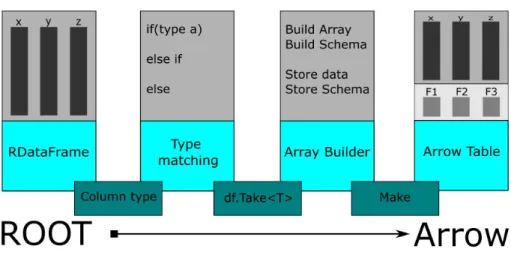
The conversion takes several steps to go from ROOT to Arrow. First, it takes an RDataFrame as input. An RDataFrame can be created by specifying a ROOT file and a TTree:
RDataFrame df("TTree", "ROOT-file.root");
The built-in ROOT function needs to know the name of the TTree in order to create an RDataFrame. Files that do not contain a TTree cannot be fed directly to the conversion algorithm. Since TTrees are commonly used for analysis of ex- perimental data, we assume that all files relevant to this project contain a TTree.
Second, it infers the type of a specific column and passes it to a pattern match- ing algorithm. If the algorithm finds the type, the conversion can start phase three. If not, the column cannot be converted and will be ignored. A warning will be printed to the console and the algorithm continues the conversion.
For the third phase, the column is taken from the RDataFrame and passed into an Apache Arrow ArrayBuilder of specified type. The phase also updates the schema that holds information about each column’s name and datatype. This is later needed to build the Arrow Table. Once every single column is built, the conversion goes to phase four.
In this final phase, the Apache Arrow Table is built with the information of the schema that we initialized in phase three and the data columns that we built with the ArrayBuilders.
Figure 2: Conversion Plan
4.4 Types
ROOT implements basic types that every programmer knows, such as floats, integers and booleans. In addition, ROOT implements a massive number of classes [7] and each class can be interpreted as a data type in C++. Since C++ is a type safe language, it needs to know the data type of each column of the RDataFrame to get data out of it. Therefore, pattern matching of the type is needed. We show this approach only on a subset of all possible types to illustrate how it works. We believe that the same can be done for every type in ROOT, but implementing support for all of them is outside of the scope of this thesis.
Our approach supports basic C++ data types, RVectors, which are the most common occurring implementation of vectors in ROOT and additionally three physics classes, namely TVector2, TVector3 and TLorentzVector, to get an un- derstanding of how to add support for ROOT classes. The full table of supported types is listed below.
Null does not exist in ROOT and therefore it is not included in the type match- ing table. Apache Arrow has null values and type NA.
Type Matching Table
ROOT C++ Arrow Size
Bool t bool BOOL 1b
Char t char INT8 1B
UChar t unsigned char UINT8 1B
Short t short INT16 2B
UShort t ushort UINT16 2B
Int t int INT32 4B
UInt t uint UINT32 4B
Long t long INT64 8B
ULong t unsigned long UINT64 8B
Long64 t long long INT64 8B
ULong64 t unsigned long long UINT64 8B
Float t float FLOAT 4B
Double t double DOUBLE 8B
TVector2 struct Struct 16B
TVector3 struct Struct 24B
TLorentzVector struct Struct 32B
RVec<T> vector<T> List variable
5 Code Implementation
5.1 Starting method
To start the conversion, the method R2A needs to be called. It takes an RDataFrame and a list of column names as inputs. In the end, it returns an Apache Arrow Table that holds the data of every column specified in the input vector.
using namespace arrow;
using namespace std;
using namespace ROOT;
shared_ptr<Table> R2A(RDataFrame df, vector<string> cNames){
//fields holds the Apache Arrow Schema
//data_columns holds the Apache Arrow data arrays vector<shared_ptr<Field>> fields = {};
vector<shared_ptr<Array>> data_columns = {};
//loops over all columns and performs //type matching and array building for(auto colName : cNames){
TypeMatching(df, fields, data_columns, colName);
}
//creates an arrow::schema from the fields vector auto schema = arrow::schema(fields);
//constructs the arrow::Table from the schema and data auto batch = Table::Make(schema,data_columns);
return batch;
}
5.2 Type Matching and ArrayBulding
The type matching and array building are being done in the same method, since a lot of elements need to be hard-coded. The matching is done column by col- umn via if-else cases that compare the type of a given column with a set of predefined types that the conversion supports. If the type is known, the algo- rithm takes the column out of the RDataFrame and builds an Apache Arrow Array. If the type is not known, the column is ignored and its name and type are displayed in the console.
The following code example demonstrates how the algorithm works for columns of unnested floating point values:
//string typ = df.GetColumnType(colName);
//typ is the type of a specified column if (typ.find("float") != std::string::npos) {
//df.Take returns a std::vector of type float //wrapped in a ROOT::ResultPtr
//GetValue() is called to unwrap the ResultPtr auto vc = df.Take<float>(colName).GetValue();
//Specify an Apache Arrow ArrayBuilder for //float values
FloatBuilder builder;
//The builder takes the whole std::vector as //input but doesn't build yet
check_status(builder.AppendValues(vc));
//A shared_ptr that will hold the data is constructed shared_ptr<Array> data_array;
//The builder builds the Apache Arrow Array check_status(builder.Finish(&data_array));
//data is saved and a new field (name, type) is added //to the fields vector (the Arrow schema)
data_columns.push_back(data_array);
fields.push_back(arrow::field(colName,float32()));
}
5.3 Struct support
Since ROOT supports a massive number of different classes, a goal of the im- plementation was to make adding support for a new class as easy as possible.
The implementation already supports different types of physics vectors. The code below shows how to support a simple fictional struct which could occur in the RDataFrame.
struct FPair { float x;
float y;
}
We need to make sure that the fields of the struct can be interpreted in Apache Arrow. In this example, the two fields are of type float and we can infer their Arrow type with the help of the type table in subsection 4.4. To support this struct in Apache Arrow, we need to set up the ArrayBuilders as follows:
//Use the default memory pool
arrow::MemoryPool* pool = arrow::default_memory_pool();
//Initialize the shared builders for each field of the struct auto x_b = std::make_shared<FloatBuilder>(pool);
auto y_b = std::make_shared<FloatBuilder>(pool);
//create an ArrayBuilder for all fields
std::vector<std::shared_ptr<ArrayBuilder>> fpb {x_b, y_b};
//Create an Arrow DataType that matches the struct //This is later needed to build the Arrow Schema std::vector<shared_ptr<Field>> fptype {
field("x",float32()), field("y",float32())};
std::shared_ptr<DataType> map_type = struct_(fptype) //Create the StructBuilder from the type and ArrayBuilders auto struct_b = std::make_shared<StructBuilder>(
map_type, pool, std::move(fpb));
//Create the ListBuilder to hold the struct from each row auto list_b = std::make_shared<ListBuilder>(pool,struct_b);
//vc returns a std::vector of FPairs
auto vc = df.Take<FPair>("FPair_column").GetValue();
//Loop over the data and append the values of the struct fields //to their corresponding ArrayBuilders.
for(auto i:vc){
list_b -> Append();
struct_b -> Append();
x_b -> Append(i.x);
y_b -> Append(i.y);
}
//Build the array and store it (data_columns vector) std::shared_ptr<arrow::Array> nested_arr;
list_b -> Finish(&nested_arr);
data_columns.push_back(nested_arr);
//Add the column to the Schema (fields vector)
fields.push_back(arrow::field("FPair_Column",map_type);
The provided example is not trivial to understand, despite being kept as simple as possible. Once this example is understood well, adding support for different ROOT classes becomes easy. Unfortunately, adding support for different classes cannot be made generic, because Apache Arrow demands the ArrayBuilders to be type specific.
6 Performance Analysis
6.1 Setup
All experiments were run on a Laptop with an IntelR CoreTMi7-7500U CPU
@2.70GHz. The code was executed inside the ROOT command prompt using ROOT version 6.20/02 and Apache Arrow version 0.17.1. Timing analysis was done using the std::chrono library for C++. The following ROOT files were used for analysis:
Name Rows Columns Size
Zmumu.root 2304 20 179.0 kB
HZZ-objects.root 2421 22 443.7 kB
Run2012B SingleMu small.root 100001 86 29.4 MB
For simplicity, we will use the names Zmumu[9], HZZ-objects[9] and Run2012B[10]
as abbreviations.
6.2 Timing
Normally, when measuring execution speed the same method is run many times and execution speed is measured and divided by the number of repeated runs.
As we did the same thing with our code, the execution time started to rise for every repeated run of the conversion algorithm. Small differences between subsequent runs are typical, but a continuous growth indicates that something might be wrong.
Example: Imagine an employee that drives to his workspace every day. He will always need about the same time for his drive. Sometimes he is a little faster, sometimes slower, but the values all lie in a certain area. In the present case, the employee would arrive later at work every day until he arrives so late that he cannot properly work anymore because he spends more time getting to work than actually working.
To better understand the behaviour, we put the timers deeper into the code.
We observed an increase in execution time for subsequent calls of the following method when the conversion was run multiple times on the same RDataFrame:
auto vc = df.Take<T>(string name).GetValue();
RDataFrame df("Events", "Run2012B_SingleMu_small.root");
for(int i = 0; i < 1000; i++){
//start measuring here
auto vc = df.Take<RVec<float>>("Tau_relIso_all").GetValue();
//stop measuring here and print time needed }
The behaviour of increasing runtime for subsequent conversions is not affecting the performance of the program since the conversion only needs to be done once and each column of the RDataFrame is only accessed once by the Take command.
6.3 Speed
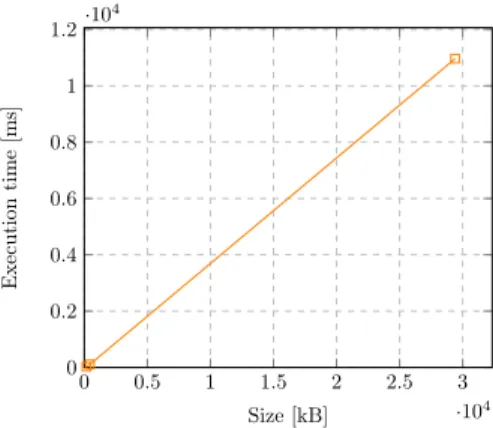
For execution time analysis, the time of a single conversion run was measured independently multiple times.The mean value of all runs was taken as a data point. Figure 3 shows that with increasing file size, the execution time increases as well. One can observe small deviations due to complex datasets that contain structures which are slower to convert than simple columns of numbers.
Despite the enjoyable near-linear increase of the execution time, the real values that were observed are very high. A 29.4 MB file needs approximately 11 sec- onds to go from ROOT to Arrow. This is very slow. ROOT usually deals with data that is 1000 times bigger than the example file used.
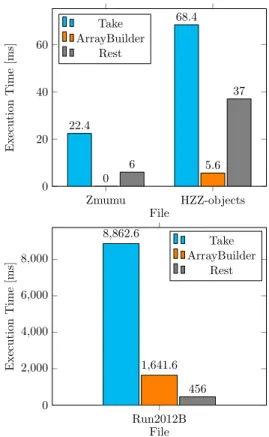
To better understand the execution time, timing was broken down into three parts: Take, ArrayBuilder and Rest. Take is the method mentioned in the pre- vious chapter. ArrayBuilder describes the whole process of building the Apache Arrow Array. Rest simply describes the time that is not spent in Take and ArrayBuilder.
Figure 4 shows the time spent in each category for the three different files. Fig-
0 0.5 1 1.5 2 2.5 3
·104 0
0.2 0.4 0.6 0.8 1 1.2·104
Size [kB]
Executiontime[ms]
Figure 3: Execution time analysis
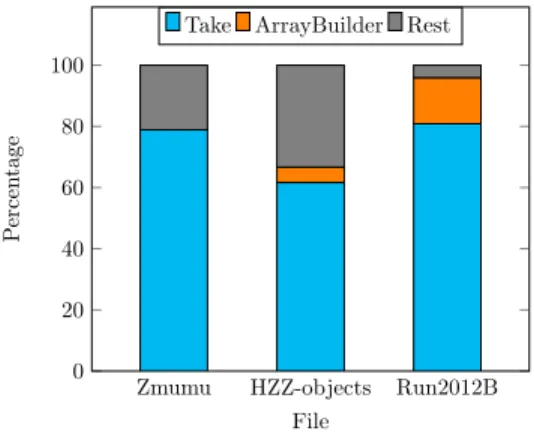
ure 5 shows the same data given in percentages. One can observe that most of the execution time is spent in the Take method. Unfortunately, this function is needed because it allows us access to the data of the RDataFrame. Furthermore, the function was implemented by ROOT itself, so there is nothing that can be done to speed it up. Unlike the other files, in Run2012B the time spent in the ArrayBuilders is larger than the Rest time. We assume that for the smaller files, noise has a bigger impact on the Rest runtime. Note that the time spent in the ArrayBuilder part in the Zmumu file is not zero, but less than 1ms and therefore not shown in the plot.
Zmumu HZZ-objects
0 20 40 60
22.4
68.4
0 6 5.6
37
File
ExecutionTime[ms]
Take ArrayBuilder
Rest
Run2012B 0
2,000 4,000 6,000 8,000
8,862.6
1,641.6 456
File
ExecutionTime[ms]
Take ArrayBuilder
Rest
Figure 4: In-depth execution time analysis
Zmumu HZZ-objects Run2012B 0
20 40 60 80 100
File
Percentage
Take ArrayBuilder Rest
Figure 5: Percentual execution time
6.4 Correctness
To verify correctness of the conversion, we have taken a ROOT file, read it into Spark and converted it to Parquet with Laurelin [8]. The resulting Parquet file was then read into an Apache Arrow table by using the built-in functions of Apache Arrow. The same ROOT file was then converted to an Apache Arrow table with our own conversion algorithm.
To compare the two tables, we loop over all columns and use either existing equality methods or compare values one by one. This is necessary because the Equal method of Apache Arrow reports some false negatives if different types are used or if NaN1values occur in the data. The test concluded that all values are equal.
1NaN = Not a Number, a datatype value that is undefined. Example: 0
7 Showcase
7.1 Writing Parquet files
To showcase a simple consumption of an Apache Arrow Table, we write an Apache Parquet file with the following lines of code:
using namespace arrow;
using namespace parquet;
void WriteParquetFile(std::shared_ptr<Table> table){
std::shared_ptr<io::FileOutputStream> outfile;
PARQUET_ASSIGN_OR_THROW(
outfile,
io::FileOutputStream::Open("TestOutFile.parquet") );
PARQUET_THROW_NOT_OK(
WriteTable(
*table.get(),
default_memory_pool(), outfile,
3 ) );
}
This example shows the simplicity of writing a Parquet file: It takes three lines of code. This code enables us to convert a ROOT file to an Apache Parquet file with the intermediate step of building an Apache Arrow Table. If we recall Figure 1, we could now add a box for ROOT to the data layer.
With our provided methods, a user can take a ROOT file and convert it to an Apache Arrow table without the need of learning and understanding ROOT and Arrow, which, as mentioned in subsection 2.1, is not easy and takes a lot of effort.
8 Summary
8.1 Future Work
We have planned to implement the other direction of the conversion, namely from Arrow to ROOT. However, this has already been implemented by the engineers at Cern. They have provided a function that takes an Apache Arrow table as input and produces and RDataFrame. A re-implementation would repeat the effort and will therefore not be considered.
8.2 Conclusion
In summary, we have implemented a conversion algorithm that takes a ROOT file as input, builds an RDataFrame using built-in ROOT functions and then converts this table-like structure to an Apache Arrow Table. The approach we provide supports a subset of all ROOT types and classes and provides a showcase of how to add support for any ROOT class. The correctness of our conversion algorithm has been verified by comparing it to an already converted Parquet file.
Generally speaking, a user of our program can now convert ROOT files to Apache Parquet files by only specifying an RDataFrame and a list of columns.
More knowledge of ROOT or Apache Arrow is not required.
Furthermore, we have analysed the performance of the algorithm and found out that most of the time is spent by taking data out of the RDataFrame. This action is being carried out by a ROOT function and therefore impossible to fix by us. One possible improvement we suggest could be to ignore the immediate step of going from ROOT file to RDataFrame. This means, one would access the data in the file directly, without RDataFrame’s high level interface.
References
[1] CERN.ROOT a Data analysis Framework. 2018.
URL: https://root. cern.ch/
(visited on 07/06/2020)
[2] The Apache Software Foundation.Apache Arrow.
URL: https://arrow. apache.org/
(visited on 07/06/2020)
[3] CERN.The Large Hadron Collider. 2020.
URL: https://home.cern/science/accelerators/large-hadron-collider/
(visited on 07/06/2020)
[4] Andy Buckley.The Problem with ROOT. 2003.
URL: http://insectnation.org/articles/problems-with-root.html (visited on 07/08/2020)
[5] Github.IRIS-HEP.
URL:https://github.com/iris-hep/adl-benchmarks-index (visited on 06/28/2020)
[6] ROOT Reference Guide.ROOT::RDataFrame Class Reference.
URL: https://root.cern/doc/master/classROOT11RDataF rame.html (visited on 07/20/2020)
[7] ROOT.Class Index. 2020.
URL: https://root.cern/doc/master/classes.html (visited on 07/08/2020)
[8] Github.spark-root/laurelin.
URL: https://github.com/spark-root/laurelin (visited on 07/08/2020)
[9] Github.scikit-hep/uproot.
URL: https://github.com/scikit-hep/uproot/tree/master/tests/samples (visited on 06/22/2020)
[10] CERN.EOS storage system.
URL: root://eospublic.cern.ch//eos/root-eos/benchmark/Run2012BSingleM usmall.root (visited on 04/19/2020)