Fachbereich
Automatisierung und Informatik
Wernigerode
Grundlagen der Informatik
„Einführung in XML und XSLT“
Dipl. Inf., Dipl.-Ing. (FH) Michael Wilhelm Friedrichstraße 57 - 59
38855 Wernigerode
Raum: 2.202 Tel.: 03943/659-338 Fax: 03943/659-399
Email: mwilhelm@hs-harz.de
Inhaltsverzeichnis
1 Einleitung 5
1.1 Eigenschaften von XML: 5
1.2 Tags 5
1.3 Vorteile bei der Verwendung von XML 6
1.4 Weitere Eingenschaften von XML 6
1.4.1 XML steht für strukturierte Daten 6
1.4.2 XML sieht ein wenig wie HTML aus 7
1.4.3 XML ist Text, aber für Anwender schlecht zu lesen 7
1.4.4 XML ist eine Familie von Techniken 7
1.4.5 XML ist modular 7
1.4.6 XML ist lizenzfrei, plattformunabhängig und gut unterstützt 8
2 Aufbau von XML-Dateien 9
2.1 Dateierweiterungen von XML: 9
2.2 XML Elemente 9
2.3 CDATA und PCDATA 9
2.4 XML tags 9
2.5 Entities 10
Beispiele Entities 10
2.6 XML Attribute 11
3 DTD: Document Type Definition 12
3.1 Wozu eine DTD ? 12
4 Beispiele 13
4.1 Beispiel einerXML-Datei EMail-Note 13
4.2 Beispiel 1 13
4.3 Beispiel 2 14
4.4 Beispiel 3 14
4.5 Beispiel 4 15
4.6 Beispiel 5 16
4.7 Beispiel 6 17
4.8 Beispiel 7a 17
4.9 Beispiel 7b 18
4.10 Beispiel bsp8.xml 18
4.11 Beispiel bsp8b.xml 19
4.12 Beispiel bsp8c.xml 19
5 Attributwerte 21
5.1 Mögliche Elemente für Attribute: 21
5.2 Beispiele mit Attributwerte 21
5.2.1 Einbau von Attributen im Entity „auto“: 22
5.2.2 Einbau einer Aufzählung 22
5.3 Zusammenfassung: 23
6 Weitere Verarbeitung 24
6.1 Programme für XLM und XSLT 24
6.2 XML-SPY 24
6.3 Die Abfragesprache XPath 25
6.3.1 Eigenschaften der XPATH-Ausdrücke 25
6.3.2 Beispielabfragen Matrikelnummer 26
6.3.3 Beispielabfragen Matrikelnummer>12400 26
6.3.4 Weitere PATH-Abfragen 27
6.4 Achsen unter XPATH 27
7 XML, XSLT und HTML 33
7.1 Beispiel1 33
7.1.1 Inhalt der Dateien 34
7.1.2 Transformation mit Kernow 34
8 Open-XML 39
8.1 Installation 39
8.2 Arbeitsablauf 39
9 Literatur und Links 40
9.1 Literatur 40
9.2 Links 40
10 Stichwortverzeichnis 41
Abbildungsverzeichnis
Abbildung 1 XML-Datei hat zwei Einträge im Root, keine valide XML-Datei 14
Abbildung 2 XML SPY: Anzeigen von XML-Dateien 24
Abbildung 3 XML Spy mit der Datei bsp5.xml 26
Abbildung 4 Bestimme alle Matrikelnummenr 26
Abbildung 5 Bestimme alle Matrikelnummenr größer 12400 27
Abbildung 6 Beispielknoten für XPATH 28
Abbildung 7 Parent-Achse (2) 28
Abbildung 8 Child-Achse (3) 29
Abbildung 9 Descendant-Achse (4) 29
Abbildung 10 Descendant-or-self-Achse (5) 29
Abbildung 11 Ancestor (6) 30
Abbildung 12 Ancestor-or-self-Achse (7) 30
Abbildung 13 Following-sibling-Achse (8) 30
Abbildung 14 Following-Achse (9) 31
Abbildung 15 Preceding-sibling-Achse (10) 31
Abbildung 16 Preceding-Achse (11) 32
Abbildung 17 http://www.w3.org/1999/XSL/Transform (Namensraum) 33
Abbildung 18 HTML-Datei des ersten Beispiels 35
Abbildung 19 XSLT-Transformation 35
Abbildung 20 Beispiel 1 in Firefox 38
Abbildung 1 Anzeige des Open-XML-Programms 39
1 Einleitung
Der Datenaustausch zwischen Programmen einer oder unterschiedlichen Plattformen verläuft nicht immer reibungslos:
• Das Datenformat ist binär und proprietär, einzigartig
• Man muss für jedes Programm die Ein- und Ausgabemethoden schreiben
• Problem Little- und Big-Endian (Vertauschung der Byte-Reihenfolge) o Big-Endian (Linux)
o Little Endian (Windows)
o Big-Endian (Java auch unter Windows)
• Plausibilitätsüberprüfung
• Die weitere Verarbeitung erfordert wiederum individuelle Programme o Export nach HTML
o Export nach PDF
o Schnitttstellen wie WML o SMIL
eXtensible Markup Language, XML bietet nun die Möglichkeit, diese Nachteile zu beheben. Es dient hauptsächlich dazu, ein einheitlich lesbares Datenformat zu erzeugen.
1.1 Eigenschaften von XML:
• Hat alle Fähigkeiten von HTML,
• XML ähnelt auf den ersten Blick HTML, ist aber wesentlich flexibler:
o darüber hinaus aber auch Definition eigener Tags
o Bessere Einbindung von Grafik und Programmen; man kann mit eigenen Programmen auf XML-Dokumente zugreifen
o Vollständige Beschreibungssprache für Datensätze im Internet o Zielsetzung: Inhalte (Semantik) von Dokumenten beschreiben
o Viele Programme erlauben die weitere Verarbeitung von XML-Dateien o XML ist plattformunabhängig, ein W3C-Standard
o XML erleichtert Informationsaustausch, da Konvertierungen nicht mehr nötig sind (XML kann von verschiedenen Applikationen, die auf unterschiedlichen Plattformen beruhen, gelesen werden)
o XML kann Daten in Dateien oder Datenbanken speichern; Speicherung und Zugriff auf XML-Daten über eigene Programme möglich
1.2 Tags
Während HTML lediglich wenige Tag vorhält, der die Strukturierung eines Dokumentes vorsieht (Paragraph, div), ermöglicht XML die Definition eigener Tags, die die Bedeutung von Elementen des Dokumentes beschreiben
1.3 Vorteile bei der Verwendung von XML
Bessere Strukturierung mit XML:
• XML kann Daten und ihre Beschreibung (z.B. Metadaten) in getrennten Dateien vorhalten
• HTML-Seiten enthalten oft beides, Daten und Beschreibung der Daten in einer Datei
• XML-Daten können aber auch als „data islands“ innerhalb von HTML-Dokumenten auftauchen (Saxon, XSLT)
Der Entwicklungsaufwand mit XML ist höher als bei HTML:
• Inhalte sind in XML logisch strukturiert und die Ausgabe der Inhalte muss mittels XSL programmiert werden (eXtensible Stylesheet Language)
• Für das Erzeugen einer Web-Seite (in HTML ggf. ein Dokument), sind in XML zwei Dateien notwendig (.xml und .xsl). Oft kommt eine dritte hinzu, in der eigene Tags definiert werden
• XML ist plattformunabhängig, ein W3C-Standard
• XML erleichtert Informationsaustausch, da Konvertierungen nicht mehr nötig sind (XML kann von verschiedenen Applikationen, die auf unterschiedlichen Plattformen beruhen, gelesen werden)
• XML kann Daten in Dateien oder Datenbanken speichern; Speicherung und Zugriff auf XML- Daten über eigene Programme möglich
• XML ist die Spezifikation einer Meta-Sprache. XML selbst stellt keine Sprache zur Definition von Inhalten dar, sondern lediglich die Grundlage für die Definition einer solchen Sprache.
• Daher ist bei XML auch kein einziger Element-Typ ("Tag") von der Bedeutung her definiert.
XML definiert lediglich den Aufbau derartiger Dokumente.
• XML soll HTML nicht ersetzen, sondern erweitern
• XML strukturiert konkrete Inhalte (Texte, Grafiken, Sounds, etc.). Die Ausgabe übernimmt XSL (eXtensible Stylesheet Language)
• XML achtet sehr genau auf die Syntax (ein Tag <Datensatz> wird beispielsweise von HTML einfach ignoriert – XML zeigt das Tag an, wenn es richtig definiert ist, ansonsten gibt es eine Fehlermeldung aus (siehe Vorlesung und Labor)
1.4 Weitere Eingenschaften von XML
1.4.1 XML steht für strukturierte Daten
• Strukturierte Daten findet man z.B. in so unterschiedlichen Dingen wie Kalkulationstabellen, Winword, Adressbücher, Konfigurationsparameter, finanzielle Transaktionen und technische Zeichnungen
• XML ist ein Satz an Regeln (man kann ebenso von Richtlinien oder Konventionen sprechen) für die Erstellung von Textformaten zur Strukturierung solcher Daten
• XML ist keine Programmiersprache, also leicht zu lernen
• XML erleichtert es einem Computer, Daten zu generieren oder zu lesen und sorgt dafür, dass eine bestimmte Datenstruktur eindeutig bleibt
• XML ist erweiterbar, plattformunabhängig und unterstützt Internationalisierung /
1.4.2 XML sieht ein wenig wie HTML aus
• Wie HTML verwendet XML Tags (durch '<' und '>' geklammerte Wörter) und Attribute (der Form name="value").
• HTML legt fest, was jedes Tag und Attribut bedeutet, und oft wie der Text dazwischen in einem Browser dargestellt werden soll (<h1>, <u>, <b>)
• Benutzt man XML dienen die Tags nur zur Abgrenzung von Daten
• Man überlässt die Interpretation der Daten allein der Anwendung, die sie verarbeitet.
1.4.3 XML ist Text, aber für Anwender schlecht zu lesen
• Programme, die Kalkulationstabellen, Adressbücher und andere strukturierte Daten produzieren, speichern diese Daten meist auf der Festplatte, wobei sie entweder ein Binär- oder ein Textformat verwenden.
• Ein Vorteil des Textformats ist es, dass man sich auf diese Weise die Daten ansehen kann, ohne das produzierende Programm selbst zu verwenden. Man kann es auch ändern, Gefahr)
• Anders als bei HTML, sind die Regeln bei XML strikt. Ein weggelassenes Tag oder ein Attribut ohne Anführungszeichen, machen eine XML Datei unbenutzbar, während dies bei HTML toleriert und oftmals explizit erlaubt wird. Die offizielle XML Spezifikation zwingt Anwendungen, falls sie auf fehlerhafte XML Dateien laden; die Anwendung an dieser Stelle anzuhalten und eine Fehlermeldung auszugeben.
1.4.4 XML ist eine Familie von Techniken
• XML ist die Spezifikation, die definiert, was "Tags" und "Attribute" sind. Hinter XML steht die "XML Familie" als ein wachsender Satz an Modulen, der nützliche Serviceleistungen für die Verwirklichung wichtiger und häufig angefragter Aufgaben bereithält
• Xlink beschreibt eine Standardmethode, um Hyperlinks zu XML Dateien hinzuzufügen
• XPointer und XFragments sind Syntaxen, um auf Teile eines XML Dokuments zu verweisen.
Ein XPointer ähnelt ein wenig einem URL, aber anstatt auf Dokumente im Web zu zeigen, zeigt er auf Teildaten innerhalb einer XML Datei
• XSL ist die weiterentwickelte Sprache zum Erstellen von Style Sheets. Sie basiert auf XSLT, einer Transformationssprache, die für das Umstellen, Hinzufügen und Löschen von Tags und Attributen verwendet wird
1.4.5 XML ist modular
• Um bei der Kombination von Formaten Namenskollisionen zu vermeiden, stellt XML den Namensraummechanismus zur Verfügung.
1.4.6 XML ist lizenzfrei, plattformunabhängig und gut unterstützt
• Wenn man XML als Basis für ein Projekt wählen, dann findet man Zugang zu einer großen und wachsenden Ansammlung von Werkzeugen
• Sich für XML zu entscheiden, ist fast so wie SQL für Datenbanken zu wählen: Man muss nur noch seinen eigenen Datenbestand und die Programme/Prozeduren, die ihn bearbeiten, erstellen.
• XML ist als W3C-Entwicklung lizenzfrei. Man kann eine eigene Software drum herum bauen, ohne jemandem etwas zu bezahlen. Die große und wachsende Unterstützung bedeutet, dass Sie auch nicht an einen einzigen Anbieter gebunden sind. XML ist nicht immer die beste Lösung, aber es lohnt sich immer, XML in Erwägung zu ziehen.
2 Aufbau von XML-Dateien
2.1 Dateierweiterungen von XML:
• XML: XML-Datei (Strukturierung der Inhalte von XML-Daten)
• XSL: XSL- Datei (Transformation resp. Ausgabe von XML-Daten)
• CSS: Cascading Style Sheets (einfachere Version von XSL für die Ausgabe von XML-Daten)
• DTD: Document Type Definition (Definition der Tags)
• HTM oder HTML: HTML-Datei
• XHTML: HTML-Datei
2.2 XML Elemente
Folgende Blöcke existieren in einem XML-Dokumenten:
• Elements // Person, Buch
• Tags // <person> …. </person>
• Attributes // <person geschlecht="m">
• Entities // Ersetzungen z.B. Name durch Text
• PCDATA // Parsed Character Data (keine < und &)
• CDATA // Character Data, einfacher Text
2.3 CDATA und PCDATA
• PCDATA = Parsed Character Data
o Der enthaltende Text muss bestimmten Kriterien entsprechen o Die Zeichen < und & dürfen nicht im Text sein
• CDATA = Character Data
o Dieser Abschnitt kann beliebigen Text enthalten o Auch {, <, &
• Character data = Text zwischen dem Start - und dem End Tag eines XML-Dokumentes PCDATA erlaubt die Definition auch von Alternativen:
<!ELEMENT b (#PCDATA)>
<!ELEMENT p (#PCDATA|a|b)*>
Beispiele:
Ein body Element:
<body>body text in between</body>.
Ein message Element:
<message>some message in between</message>
2.5 Entities
Entities sind Paare von Abkürzungen und deren Bedeutungen.
Fest eingebaute Beispiele:
• ' referenziert ein Apstroph (')
• > referenziert ein Größer-als (>)
• < referenziert ein Kleiner-als (<)
• & referenziert ein Kaufmanns-und (&)
• " referenziert ein Anführungszeichen (") Ingesamt gibt es drei unterschiedliche Typen:
allgemeine vs Parameterentities:
• Allgemeine Entities bzw. deren Entityreferenzen können nur im XML-Dokument auftauchen.
Im Gegensatz dazu gibt es Parameterentities nur in der DTD. Beide Entities werden natürlich wie gewohnt in der DTD deklariert.
geparste vs ungeparste Entities:
• Referenzen auf geparste Entities werden vom Parser zuerst ersetzt, und danach analysiert, das heißt auf Markup durchsucht. Ungeparste Entities werden vom Parser nicht analysiert. Das macht ja bei Bildern oder ähnlichen auch nicht viel Sinn. Ungeparste Entities müssen an eine externe Anwendung weitergegeben werden, um verarbeitet zu werden.
externe vs interne Entities:
• Der Inhalt (Ersetzungstext) eines externes Entities ist nur durch Zugriff auf eine andere Datei zu bestimmen. Diese Datei kann zum Beispiel ein Bild, ein Sound oder auch eine XML-Datei sein. Bei einem internen Entity wird der Inhalt bei der Deklaration bestimmt.
Beispiele Entities
in DTD:
<!ENTITY hsharz "Fachhochschule Harz in Wernigerode">
<!ENTITY tub "Technische Universität Berlin">
in XML:
<student hochschuhle="&hsharz;">
<uni>&hsharz;</uni>
</student>
<student >
<uni>&tub;</uni>
</student>
<!ELEMENT student (uni)>
<!ELEMENT uni (#PCDATA)>
<!ENTITY hsharz "Hochschulke Harz in Wernigerode">
<!ENTITY uni "<uni>&tub;</uni>">
]>
<student>
&uni;
</student>
2.6 XML Attribute
„Attribute liefern zusätzliche Information bezüglich der Elemente“.
Attribute stehen innerhalb des Start Tags; sie weisen meistens die Form eines Name/Wert-Paares auf.
Nachfolgend ein Beispiel, das „img“ - Element, dass Information über eine Quelldatei beinhaltet
<img src="computer.gif" />
Name des Elementes: "img"
Name des Attributes: "src"
Wert des Attributes: "computer.gif"
Bemerkungen :
• Da das Element selbst „leer“ ist, wird es mit einem " /“ geschlossen
• Attribute können keine "Unterattribute haben"
• Elemente haben diese Eigenschaft, sie können beliebig viele Unterelemente haben
3 DTD: Document Type Definition
• Zweck einer DTD: Definition eines gültigen XML Dokumentes
• Die DTD definiert die Struktur eines Dokumentes mittels einer gültigen Liste von Elementen
• Eine DTD kann innerhalb eines XML-Dokumentes angelegt werden, sie kann aber auch außerhalb desselben als „externe Referenz“ angelegt sein
o Intern
o externe Referenz als DTD o externe Referenz als URL
3.1 Wozu eine DTD ?
• XML ist ein anwendungsunabhängiges Datenaustausch“format“
• Voneinander unabhängige Nutzergruppen können auf der Grundlage einer gemeinsam
„verabschiedeten“ DTD Daten austauschen
• XML-Anwendungen können Standard-DTDs verwenden und gewährleisten damit die Verwendung „gültiger“, „vailder“ Schemata
• DTDs können zur Verifikation eigener Daten Einsatz finden
• In den letzten Jahren sind für viele Bereiche, z. B. B2B, DTDs entwicklet wurden, die einen reibungslosen Austausch gewährleisten
B2B: Business 2 Business
4 Beispiele
4.1 Beispiel einerXML-Datei EMail-Note
<?xml version="1.0"?>
<!DOCTYPE note [
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<note>
<to>Andreas</to>
<from>Beate</from>
<heading>Erinnerung</heading>
<body>Vergiss nicht fuer GDI zu lernen!</body>
</note>
Erläuterung:
!ELEMENT note (in Zeile 3) definiert das element "note" mit vier Eigenschaften:
"to,from,heading,body".
!ELEMENT to (in Zeile 4) definiert das "to" element mit dem Typ "CDATA".
!ELEMENT from (in Zeile 5) definiert das "from" element mit dem Typ "CDATA“
usw...
4.2 Beispiel 1
<?xml version="1.0"?>
<!DOCTYPE Student [
<!ELEMENT Student (#PCDATA)>
]>
<Student>Frau Mueller!</Student>
Bemerkungen:
• Interne DTD für einen Studenten
• Verwendung des amerikanischen Zeichensatz
• Müller vs. Mueller
4.3 Beispiel 2
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- Beispiel mit Kommentaren -->
<!DOCTYPE Student [
<!ELEMENT Student (#PCDATA)>
]>
<Student>Frau Müller!</Student>
Bemerkungen:
• Interne DTD für einen Studenten
• Verwendung des europäischen Zeichensatz: encoding="ISO-8859-1
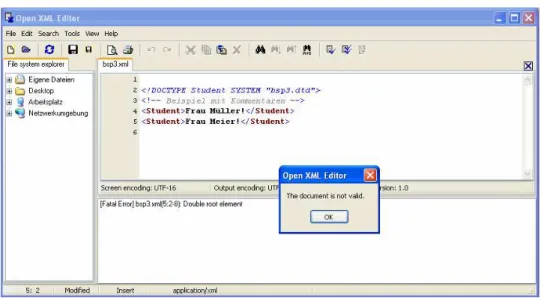
4.4 Beispiel 3
bsp3.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE Student SYSTEM "bsp3.dtd">
<!-- Beispiel mit Kommentaren -->
<Student>Frau Müller!</Student>
bsp3.dtd
<!ELEMENT Student (#PCDATA)>
Bemerkungen:
• Externe DTD für einen Studenten
• Aufruf des DTD mit
o <!DOCTYPE Student SYSTEM "bsp3.dtd">
• Verwendung des europäischen Zeichensatz: encoding="ISO-8859-1 Das dritte Beispiel nun mit zwei Studenten:
Abbildung 1 XML-Datei hat zwei Einträge im Root, keine valide XML-Datei
4.5 Beispiel 4
Im vierten Beispiel sollen in einer XML-Datei Adressen gespeichert werden. Jede „Adresse“ besteht aus einem Vorname, Nachnamen, Straße, PLZ, Ort und Matrikelnummer.
Hierarchie:
Adressen Adresse
Vorname Nachnamen Straße PLZ Ort
Matrikelnummer.
bsp4.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- interne DTD -->
<!DOCTYPE ADRESSEN [
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT ADRESSEN (DATENSATZ)*>
<!-- Ein Datensatz enthaelt (VORNAME, NACHNAME usw.) -->
<!ELEMENT DATENSATZ (VORNAME, NACHNAME, STRASSE, PLZ, ORT, MATRNR)>
<!-- Inhalt der Elemente wird festgelegt (hier beliebiger Text) -->
<!ELEMENT NACHNAME (#PCDATA)>
<!ELEMENT ORT (#PCDATA)>
<!ELEMENT PLZ (#PCDATA)>
<!ELEMENT STRASSE (#PCDATA)>
<!ELEMENT VORNAME (#PCDATA)>
<!ELEMENT MATRNR (#PCDATA)>
]>
<!-- DATEN -->
<!-- ROOT-ELEMENT -->
<ADRESSEN>
<!-- Der 1. Datensatz -->
<DATENSATZ>
<!-- Elemente eines Datensatzes: VORNAME, NACHNAME usw. -->
<VORNAME>Hans</VORNAME>
<NACHNAME>Mustermann</NACHNAME>
<STRASSE>Musterweg 1</STRASSE>
<PLZ>12345</PLZ>
<ORT>Musterstadt</ORT>
<MATRNR>12345</MATRNR>
</DATENSATZ>
<!-- Der 2. Datensatz -->
<DATENSATZ>
<VORNAME>Franz</VORNAME>
Man beachte den Stern nach der Definition des Datensatz Platzhalter:
• ? für keinmal oder genau einmal (0,1)
• + mindestens einmal, für einmal oder mehrmals (1,n)
• * für beliebig oft (0,1,n)
4.6 Beispiel 5
Diese Beispiel benutz als Basis das vierte Beispiel, verwendet aber eine externe Referenz:
bsp5.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- externe DTD -->
<!DOCTYPE ADRESSEN SYSTEM "bsp5.dtd">
<!-- ROOT-ELEMENT -->
<ADRESSEN>
<!-- Der 1. Datensatz -->
<DATENSATZ>
<!-- Elemente eines Datensatzes VORNAME, NACHNAME usw. -->
<VORNAME>Hans</VORNAME>
<NACHNAME>Mustermann</NACHNAME>
<STRASSE>Musterweg 1</STRASSE>
<PLZ>12345</PLZ>
<ORT>Musterstadt</ORT>
<MATRNR>12345</MATRNR>
</DATENSATZ>
<!-- Der 2. Datensatz -->
<DATENSATZ>
<VORNAME>Franz</VORNAME>
<NACHNAME>Meier</NACHNAME>
<STRASSE>Hauptstrasse 5</STRASSE>
<PLZ>54321</PLZ>
<ORT>Neustadt</ORT>
<MATRNR>12741</MATRNR>
</DATENSATZ>
</ADRESSEN>
bsp5.dtd:
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT ADRESSEN (DATENSATZ)*>
<!-- Ein Datensatz enthaelt mehrere Elemente (VORNAME, NACHNAME usw.) -->
<!ELEMENT DATENSATZ (VORNAME, NACHNAME, STRASSE, PLZ, ORT, MATRNR)>
<!-- Inhalt der Elemente wird festgelegt (hier beliebiger Text) -->
<!ELEMENT NACHNAME (#PCDATA)>
<!ELEMENT ORT (#PCDATA)>
<!ELEMENT PLZ (#PCDATA)>
<!ELEMENT STRASSE (#PCDATA)>
<!ELEMENT VORNAME (#PCDATA)>
<!ELEMENT MATRNR (#PCDATA)>
Die Anweisung „<!DOCTYPE ADRESSEN [„ wird in einer separaten DTD-Datei nicht verwendet.
Platzhalter:
• ? für keinmal oder genau einmal (0,1)
• + mindestens einmal, für einmal oder mehrmals (1,n)
• * für beliebig oft (0,1,n)
4.7 Beispiel 6
Im Beispiel sechs sollen zwei Vornamen gespeichert werden:
Mit der vorherigen Definition der DTD ist das nicht möglich.
bsp6.dtd:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- externe DTD -->
<!DOCTYPE ADRESSEN SYSTEM "bsp5.dtd">
<ADRESSEN>
<!-- Der 1. Datensatz -->
<DATENSATZ>
<VORNAME>Hans</VORNAME>
<VORNAME>Hugo</VORNAME>
<NACHNAME>Mustermann</NACHNAME>
<STRASSE>Musterweg 1</STRASSE>
<PLZ>12345</PLZ>
<ORT>Musterstadt</ORT>
<MATRNR>12345</MATRNR>
</DATENSATZ>
</ADRESSEN>
Hinweis:
• Das Beispiel sechs verwendet „noch“ die bsp05.dtd Ergebnis der Validierung:
Element contains another element which does not match the content model: [DATENSATZ]
Schlussfolgerung:
Es fehlt die Definition, dass der Vorname mehrfach vorkommen darf.
4.8 Beispiel 7a
Das Beispiel „bsp7b.dtd“ definiert die Vornamen, so dass mehrere möglich sind.
bsp7a.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE ADRESSEN SYSTEM "bsp7a.dtd">
<ADRESSEN>
<DATENSATZ>
</DATENSATZ>
</ADRESSEN>
Ergebnis der Validierung: Alles okay
bsp7a.dtd:
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT ADRESSEN (DATENSATZ)*>
<!ELEMENT DATENSATZ ( (VORNAME)*, NACHNAME, STRASSE, PLZ, ORT, MATRNR)>
<!ELEMENT VORNAME (#PCDATA)>
<!ELEMENT NACHNAME (#PCDATA)>
<!ELEMENT ORT (#PCDATA)>
<!ELEMENT PLZ (#PCDATA)>
<!ELEMENT STRASSE (#PCDATA)>
<!ELEMENT MATRNR (#PCDATA)>
4.9 Beispiel 7b
Das Beispiel „bsp7b.dtd“ definiert den Vornamen neu, so dass dieser beliebige VNamen haben kann.
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT ADRESSEN (DATENSATZ)*>
<!-- Ein Datensatz enthaelt mehrere Elemente (VORNAME, NACHNAME usw.) -->
<!ELEMENT DATENSATZ ( VORNAME, NACHNAME, STRASSE, PLZ, ORT, MATRNR)>
<!ELEMENT VORNAME (VNAME)*>
<!ELEMENT VNAME (#PCDATA)>
<!ELEMENT NACHNAME (#PCDATA)>
<!ELEMENT ORT (#PCDATA)>
<!ELEMENT PLZ (#PCDATA)>
<!ELEMENT STRASSE (#PCDATA)>
<!ELEMENT MATRNR (#PCDATA)>
Die nächsten Kapitel beschreiben ein Autohaus mit mehreren Autos
4.10 Beispiel bsp8.xml
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT AUTOHAUS (AUTO)+>
<!ELEMENT AUTO ( KFZ)>
<!ELEMENT KFZ (#PCDATA)>
<!-- externe DTD -->
<!DOCTYPE AUTOHAUS SYSTEM "bsp8.dtd">
<!-- ROOT-ELEMENT -->
<AUTOHAUS>
<!-- Der 1. Datensatz -->
<AUTO>
<KFZ>HZ AI 007</KFZ>
</AUTO>
</AUTOHAUS>
Das Autohaus muss kein Auto besitzen !
Aufgaben:
• Speichern unter bsp8a.xml und bsp8a.dtd
• Ändern der DTD, so dass mindestens ein Auto vorhanden sein muss
• Einbau von zwei weiteren Autos
4.11 Beispiel bsp8b.xml
Einbau von Attributen im Entity „auto“:
• marke Bezeichnung des Herstellers
• kw Anzahl der Kilowatt des Motors
• kfzkz KFZ Kennzeichen
bsp8.xml:
<!DOCTYPE autohaus SYSTEM "bsp8b.dtd">
<autohaus>
<!-- Der 1. Datensatz -->
<auto marke="renault" kw="127">
<kfzkz> HZ MW 100 </kfzkz>
</auto>
<auto marke="vw" kw="89" farbe="rot">
<kfzkz> WR AI 200 </kfzkz>
</auto>
</autohaus>
bsp8.dtd:
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT autohaus (auto)+>
<!ELEMENT auto (kfzkz)>
<!ATTLIST auto marke CDATA #REQUIRED
kw CDATA #REQUIRED farbe CDATA #IMPLIED
>
<!ELEMENT kfzkz (#PCDATA)>
Datei bsp8c.xml:
<!-- externe DTD -->
<!DOCTYPE autohaus SYSTEM "bsp8c.dtd">
<!-- ROOT-ELEMENT -->
<autohaus>
<!-- Der 1. Datensatz -->
<auto marke="renault" kw="127" typ="Gelaende">
<kfzkz> HZ MW 100 </kfzkz>
</auto>
<auto marke="vw" kw="89" farbe="rot">
<kfzkz> WR AI 200 </kfzkz>
</auto>
</autohaus>
Frage:
bsp8c.xml
<!-- ROOT-ELEMENT enthaelt beliebige Anzahl von Datensaetzen -->
<!ELEMENT autohaus (auto)+>
<!ELEMENT auto (kfzkz)>
<!ATTLIST auto marke CDATA #REQUIRED
kw CDATA #REQUIRED farbe CDATA #IMPLIED
>
<!ELEMENT kfzkz (#PCDATA)>
Alternative:
<!ELEMENT autohaus (auto)*>
<!ELEMENT auto EMPTY>
<!ATTLIST auto
typ CDATA #REQUIRED bj CDATA #REQUIRED km CDATA #REQUIRED ps CDATA #REQUIRED preis CDATA #REQUIRED
>
5 Attributwerte
Mit Attributwerten kann man ein Elemnte genauer beschreiben. Ob man nun für eine Spezifikation Attribute oder Elemente nimmt, bleibt jedem selbst überlassen.
Hinweis:
• Attribute können keine „Unterattribute“ haben
• Elemente können Unterelemente besitzen
5.1 Mögliche Elemente für Attribute:
• EMPTY für keinen Inhalt
• ANY für beliebigen Inhalt
• , für Reihenfolgen
• | für Alternativen (im Sinne "entweder...oder")
• () zum Gruppieren, Enum
• für beliebig oft (0,1,n)
• + für mindestens einmal (1 bis n)
• ? für keinmal oder genau einmal (0,1) Hinweis:
Wird kein Stern, Pluszeichen oder Fragezeichen angegeben, so muss das Element genau einmal vorkommen
Weitere Typen:
• #REQUIRED Attributwert zwingend erforderlich
• #IMPLIED Attributwert optional
• #FIXED Zwingender Wert, kann aber weggelassen werden
5.2 Beispiele mit Attributwerte
<!ATTLIST termdef
id ID #REQUIRED name CDATA #IMPLIED>
Aufzählungselemente:
<!ATTLIST list
type (bestellt|verschickt|rechnung) "bestellt">
Fester Wert:
<!ATTLIST form method CDATA #FIXED "POST">
<!ATTLIST steuern comment CDATA #FIXED "zu hoch">
5.2.1 Einbau von Attributen im Entity „auto“:
Kfzkz KFZ Kennzeichen als Enitity
Attribute:
• marke Bezeichnung des Herstellers
• kw Anzahl der Kilowatt des Motors
• Farbe (optional)
Einbau von Attributen im Entity „auto“: bsp8.dtd
<!-- ROOT-ELEMENT enthaelt bel. Anzahl von Saetzen -->
<!ELEMENT autohaus (auto)+>
<!ELEMENT auto (kfzkz)>
<!ATTLIST auto
marke CDATA #REQUIRED
kw CDATA #REQUIRED farbe CDATA #IMPLIED
>
<!ELEMENT kfzkz (#PCDATA)>
bsp8.xml:
<!-- externe DTD -->
<!DOCTYPE autohaus SYSTEM "bsp8b.dtd">
<autohaus>
<auto marke="renault" kw="127">
<kfzkz> HZ MW 100 </kfzkz>
</auto>
<auto marke="vw" kw="89" farbe="rot">
<kfzkz> WR AI 200 </kfzkz>
</auto>
</autohaus>
5.2.2 Einbau einer Aufzählung
<!DOCTYPE autohaus SYSTEM "bsp8c.dtd">
<!-- ROOT-ELEMENT -->
<autohaus>
<auto marke="renault" kw="127" typ="Van">
<kfzkz> HZ MW 100 </kfzkz>
</auto>
<auto marke="vw" kw="89" farbe="rot">
<kfzkz> WR AI 200 </kfzkz>
</auto>
</autohaus>
typ: Typ des Autos: Van, Cabrio, SUV, Gelände
Alternative Lösung, die nur Attribute verwendet:
<!ELEMENT autohaus (auto)*>
<!ELEMENT auto EMPTY>
<!ATTLIST auto
typ CDATA #REQUIRED bj CDATA #REQUIRED km CDATA #REQUIRED ps CDATA #REQUIRED preis CDATA #REQUIRED
>
Hier muss nun als „Sub-Entity“ der Begriff „EMPTY“ eingetragen werden.
5.3 Zusammenfassung:
• XML kann alles, was HTML kann
• XML ist erweiterbar (HTML nicht)
• XML ist flexibler (Zusammenarbeit mit eigenen Programmen; mit kommerziellen Applikationen, z.B. DBMS, auch GIS)
• XML ist Basis vieler Dialekte, z. B. GML (Geographic Markup Language), RDF (Resource Description Framework), WeatherML, SportsML, EML, etc.
• XML ist ein internationaler Standard des W3C
• XML ist formal, aber dennoch lesbar
• für Computer und Menschen!
• XML strukturiert und beschreibt Daten und ihren Inhalt („semantisch angereichert“)
6 Weitere Verarbeitung
6.1 Programme für XLM und XSLT
• XML-Editor
o Open XML, XML Spy
• XPath mit Abfragen o XML SPY
• XSLT
o Prozessoren, Saxon, freie und kostenpflichtig o HTML Browser
• Erzeugen von PDF-Dateien
o Mit xslt-Formaten (XERCES, XALAN, FOP)
• Automatische Erzeugen von HTML-Formularen
o Mit xslt-Formaten (Java-Framework SCHEMOX)
• XML in Java und .net (C#, VB, C++) o Viele vorgefertigte Packages
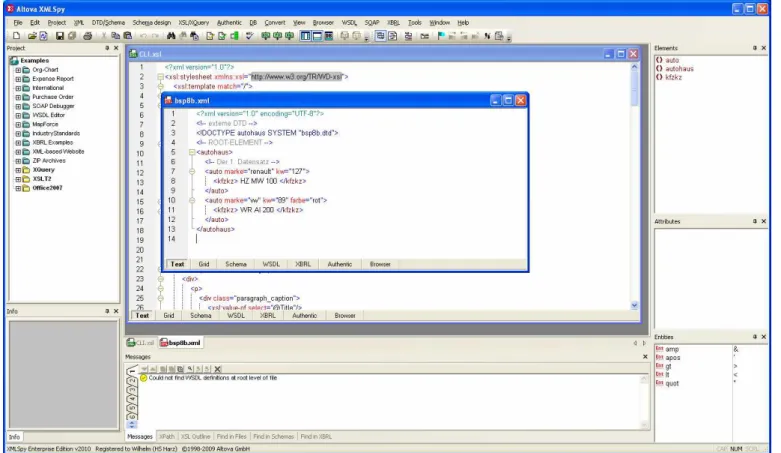
6.2 XML-SPY
Oberfläche von XML-SPY
Abbildung 2 XML SPY: Anzeigen von XML-Dateien
Wichtig ist das Abfragefenster im unteren Bereich
6.3 Die Abfragesprache XPath
• Ein Ausdruck in XPath ist eine Sequenz von Ortsangaben, die durch slash (/) voneinander getrennt werden
• XML-Daten werden als Baum à la Explorer dargestellt
• Ergebnis eines „XPath - Ausdruckes“ ist eine Wertemenge
Beispiel: suche alle Studenten des FB AI:
Abfrage: /fbai/student/name
Ergebnis: <name>Joe</name>
<name>Lisa</name>
<name>Mary</name>
Andere Ausgabeform:
• die Abfrage: /fbai/student/name/text()
• würde dieselbe Ergebnismenge liefern, jedoch ohne die einschließenden tags
6.3.1 Eigenschaften der XPATH-Ausdrücke
• der „/“ kennzeichnet die Wurzel eines Dokumentes
• XPath-Ausdrücke werden von links nach rechts ausgewertet
• wenn ein Path-Ausdruck ausgewertet ist, wird das Ergebnis als Menge der Knoten des (baumartig strukturierten) Dokumentes ausgegeben
• im vorherigen Beispiel ist „student “ ein Element
o da „student“ vor dem nächsten Pfadtrenner „/“ erscheint, bezieht sich dieses Element auf alle Elemente, die zu diesem Element „student“ gehören, d. h. alle Namen, die in der XML-Datenbank zu „student“ enthalten sind (s. Bsp.)
• Attribute und Attributwerte können ebenfalls über XPath abgerufen werden o hierzu wird das Symbol „@“ verwendet
o /fbai/student/@adresse liefert beispielsweise alle Werte von „adresse“-Attributen, die zu dem Element gehören
o PLZ, Ort, Straße, Hausnummer
Beispielabfragen zu vorhandenen Dateien:
Datei: Bsp8b.xml
Abfrage: /autohaus/auto/@kw
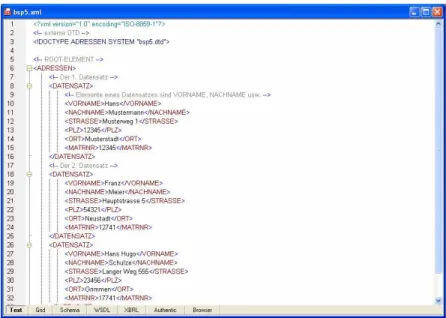
Datei: Bsp5.xml
Abfrage: /ADRESSEN/DATENSATZ[MATRNR>12400]
Abbildung 3 XML Spy mit der Datei bsp5.xml
6.3.2 Beispielabfragen Matrikelnummer
Gesucht: Anzeige aller Matrikelnummern
Pfad/Abfrage: /ADRESSEN/DATENSATZ/MATRNR
Aufruf mit:
Menü "XML", Eintrag "Evaluate XPath"
Abbildung 4 Bestimme alle Matrikelnummenr
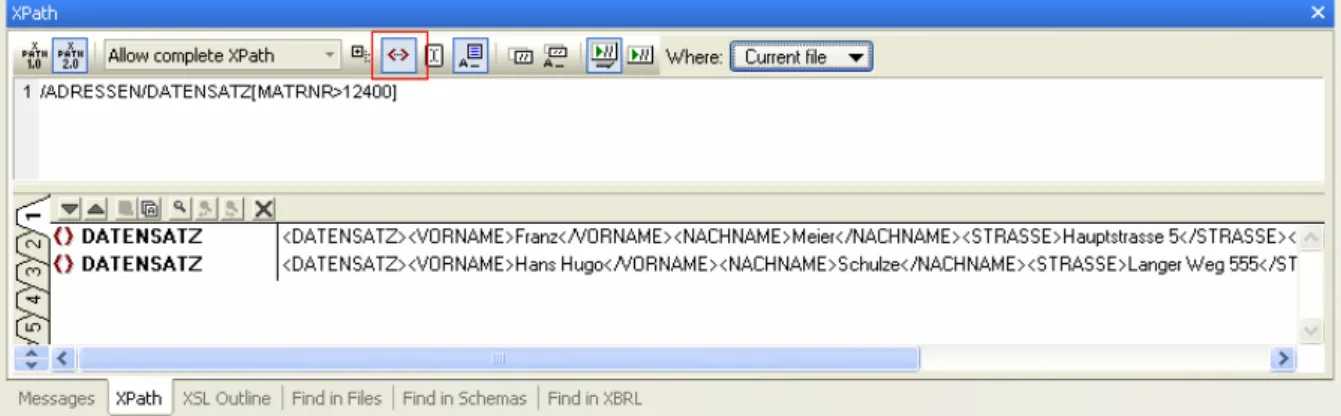
6.3.3 Beispielabfragen Matrikelnummer>12400
Gesucht: Anzeige aller Matrikelnummer mit M# > 12400 Pfad/Abfrage: /ADRESSEN/DATENSATZ[MATRNR>12400]
Abbildung 5 Bestimme alle Matrikelnummenr größer 12400
6.3.4 Weitere PATH-Abfragen
Abfrage:: / bank-1/konto[kontostand > 400]
liefert Elemente, die zu „konto“ gehören und die einen Wert für „kontostand“ aufweisen, der 400 übersteigt
Abfrage: /bank-1/konto/[kontostand > 400]/@nummer liefert die Kontonummern zur vorherigen Abfrage
Abfrage: /bank-1/konto/[kunde/count() > 2]
liefert Konten (Elemente von „konto“) mit mehr als zwei Kunden; es können auch logische Ausdrücke, z.B. „and“ oder „or“ bzw. „not“ verwendet werden
Abfrage: /bank-1/konto/id(@owner) | /bank-2/darlehen/id(@kreditnehmer) liefert Kunden mit „konto“ und mit „darlehen“
6.4 Achsen unter XPATH
Folgende Achsen sind unter XPATH definiert:
• 1) Self-Achse:
o aktueller Kontextknoten
• 2) Parent-Achse
o Die Eltern des aktuellen Knoten, maximal ein Knoten
• 3) Child-Achse
o alle Kinder, eine Generation
• 4) Descendant-Achse o alle Nachkommen
• 8) Following-sibling-Achse
o Alle folgenden Geschwister des aktuellen Knotens
• 9) Following-Achse
o Alle Knoten, die in der Reihenfolge den akt. Knoten folgen ohne die Nachkommen des aktuellen Knoten
• 10) Preceding-sibling-Achse
o Alle vorhergehenden Geschwister des aktuellen Knotens
• 11) Preceding-Achse
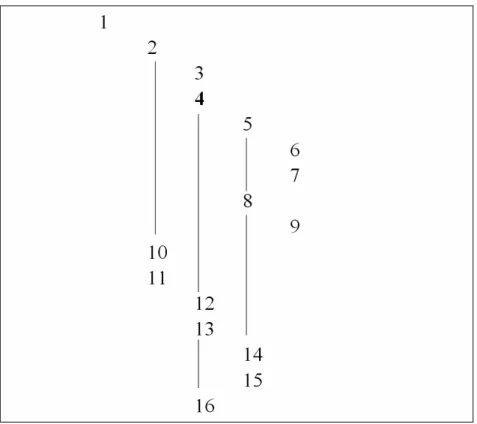
o Ergebnis sind alle Knoten vor dem aktuellen Knotens ohne der Vorfahren Die nächste Abbildung zeigt den Aufbau der Knoten in der Beispieldatei:
Abbildung 6 Beispielknoten für XPATH
Abbildung 7 Parent-Achse (2)
Abbildung 8 Child-Achse (3)
Die „Child“-Achse bezieht sich auf auf die direkten Subknoten.
Abbildung 9 Descendant-Achse (4)
Die Descendant-Achse bezieht sich auf alle Nachkommen des Kontextknoten, hier aber ohne den aktuellen Knoten.
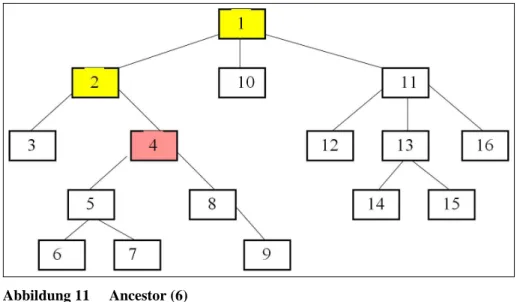
Abbildung 11 Ancestor (6)
Die „Ancestor“-Achse bezieht sich auf alle direkten Vorgänger (Alle Eltern)
Abbildung 12 Ancestor-or-self-Achse (7)
Die „Ancestor“-Achse bezieht sich auf alle direkten Vorgänger mit dem aktuellen Knoten
Abbildung 13 Following-sibling-Achse (8)
Die Following-sibling-Achse enthält alle Knoten, die auf der gleichen Stufe nach dem aktuellen Knoten liegen (gleicher Parent)
Abbildung 14 Following-Achse (9)
Die Following-Achse enthält alle "Nachfolger" des Kontextknotens, die keine Nachfahren sind (Platziert nach dem Knoten in der Datei)
Abbildung 15 Preceding-sibling-Achse (10)
Die Preceding-sibling-Achse enthält alle Knoten, die auf der gleichen Stufe vor dem aktuellen Knoten liegen (gleicher Parent)
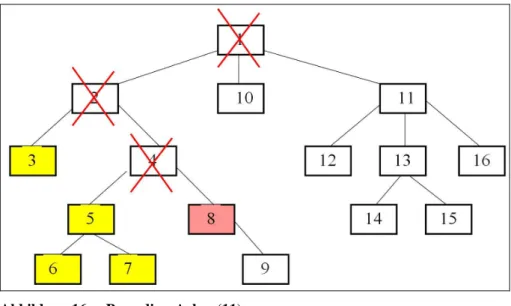
Abbildung 16 Preceding-Achse (11)
Die Preceding-Achse enthält alle Vorgänger des Kontextknotens, die keine Vorfahren sind (Platziert vor dem Knoten in der Datei)
7 XML, XSLT und HTML
Die Aufgabe von XSLT ist es, die XML-Daten lesbar in verschiedene Formate zu übertragen:
Eingangsdateien:
• In einer XML-Datei stehen die Daten
• In einer DTD-Datei steht die Struktur
Mit Hilfe einer XSLT-Datei kann die XML-Datei nun in andere Formate (HTML, SMIL, SVG, PDF) umgewandelt werden
Benötigt werden:
• xslt-Prozessor (Saxon, Kernow) für "Extensible Stylesheet Language Transformation"
• XML-Datei
• XSLT-Datei
• HTML-Datei ist Ergebnis
7.1 Beispiel1
Diese Kapitel zeigen an einigen Beispielen, wie man mittels XSLT-Prozessor aus einer XML- und aus einer XSL-Datei eine HTML-Datei erzeugt.
Man geht davon aus, dass alle XML-Dateien valid sind.
Aufbau einer XSLT-Datei:
• Es beginnt mit der normalen Definition <?xml…
• Der zweite Befehl bezieht sich auf die XSLT-Version, hier 2 und definiert den Namensraum, siehe untere Abbildung
7.1.1 Inhalt der Dateien
Inhalt der Datei guess.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet href="gruss.xsl" type="text/xsl"?>
<gruss>
<hallo>
Hallo Welt! Dies ist die Welt von XSLT.
</hallo>
</gruss>
Inhalt der Datei guess.xsl:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/"> // Templateregel und Vergleichsmuster <html>
<head>
<title>XSLT 2.0 und XPath 2.0 - Wertextraktion 1.11.1</title>
</head>
<body>
<h1 align="center">Dies ist ein Ergebnisdokument.</h1>
<p align="center">
<xsl:value-of select="gruss"/>
</p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Erläuterung der Farbbereiche:
• Schwarz: Allgemeiner XML-Start
• Grün: Start des Wurzelelements Definiert die Version und Aktion
xmnls: Namensraum definieren, eindeutige Namensräume
• Rot: XSLT-Elemente, Template,
Definiert die Grundstruktur des Abschnittes / (alles)
• Blau: Daten der XML-Datei
7.1.2 Transformation mit Kernow
Ergebnis:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>XSLT 2.0 und XPath 2.0 - Wertextraktion 1.11.1</title>
</head>
<body>
<h1 align="center">Dies ist ein Ergebnisdokument.</h1>
<p align="center">
Hallo Welt! Dies ist die Welt von XSLT.
</body>
</html>
Ergebnis der HTML-Datei:
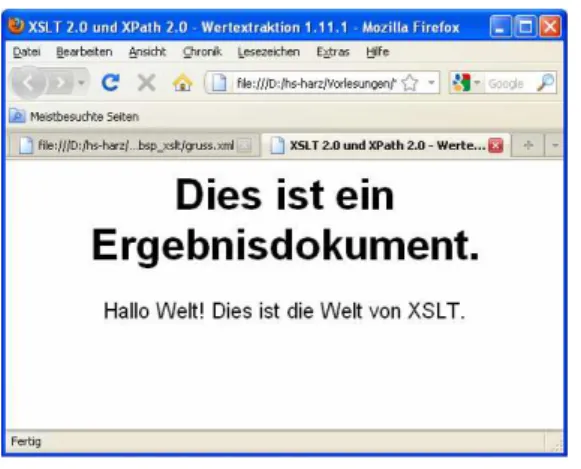
Abbildung 18 HTML-Datei des ersten Beispiels
Ablauf der Transformation:
• Installation, entzippen, des Programms Kernow, GUI mit Saxon
• Erstellen der XML-Datei
• Erstellen der DTD-Datei
• Erstellen der XSLT-Datei
• Starten des Programm Kernow
• Auswahl des Registers "Einzeldatei"
• XML-Datei eintragen
• Stylesheet eintragen
• Optional Ausgabedatei eintragen
• Schalter "Ausführen"
7.2 Beispiel 2
Im diesem Beispiel sollen alle Elemente in die HTML-Datei eingetragen werden. Aber die Darstellung soll pro Element unterschiedlich sein:
• Der Name soll fett dargestellt werden
• Nach dem Name ein Zeilenumbruch
• Der Ort soll durchgestrichen werden <s>
Die kann man realisieren, in dem man in der XSL-Datei für jedes gewünschte Attribut ein eigen- ständiges Template einträgt.
Inhalt der Datei a2/adressen.xml (Ausschnitt):
<?xml version="1.0" encoding="ISO-8859-1"?>
<adressen>
<adresse>
<name>
<vorname>Peter</vorname>
<nachname>Mustermann</nachname>
</name>
<anschrift>
<plz>12345</plz>
<ort>Beispielshausen</ort>
<strasse>Wagenstr.</strasse>
<nr>5a</nr>
</anschrift>
</adresse>
<adresse>
<name>
<vorname>Holger</vorname>
<nachname>Hurtig</nachname>
</name>
<anschrift>
<plz>22345</plz>
<ort>Randstetten</ort>
<strasse>Am Niemandsland</strasse>
<nr>2</nr>
</anschrift>
</adresse>
<adresse>
<name>
<vorname>Albert</vorname>
<nachname>Neumann</nachname>
</name>
<anschrift>
<plz>12345</plz>
<ort>Beispielshausen</ort>
<strasse>Nirgendwoweg</strasse>
<nr>7</nr>
</anschrift>
</adresse>
</adressen>
Inhalt der Datei a2/adressen.xsl (mit mehreren Namensräumen):
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0"
xmlns:fn="http://www.w3.org/2005/xpath-functions"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns="http://www.w3.org/1999/xhtml"
<xsl:output method="xhtml" // Ausgabeformat: xml, text, html, xhtml encoding="ISO-8859-1" // Zeichensatz
indent="yes" // einrücken
doctype-public="-//W3C//DTD XHTML 1.0 Strict//EN"
doctype-system="http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"
/>
<xsl:template match="/">
<html>
<head><title>XSLT 2.0 und XPath 2.0 - Adressenliste 1.15.4</title></head>
<body>
<h1>Adressenliste</h1>
<!-- hier sollen Adressen verarbeitet werden: -->
<xsl:apply-templates select="adressen/adresse"/>
</body>
</html>
</xsl:template>
<xsl:template match="adresse">
<p><xsl:apply-templates select="*"/></p>
</xsl:template>
<!-- Templateregel für <name>: -->
<xsl:template match="name">
<b><xsl:value-of select="."/></b><br/>
</xsl:template>
<!-- Templateregel für <ort>: -->
<xsl:template match="ort">
<s><xsl:value-of select="."/></s>
</xsl:template>
</xsl:stylesheet>
Ergebnis in Firefox
Abbildung 20 Beispiel 1 in Firefox
Nach dem Namen gibt ein Zeilenumbruch, der Ort wird durchgestrichen dargestellt (<s>)
8 Open-XML
Open-XML ist ein Programm, welches eine XML-Datei anzeigt und prüft.
Es gibt zwei Prüfungen:
• Wellform Zeigt an, dass der XML-Standard eingehalten wurde
• Validierung Zeigt an, das die Datei der DTD-Struktur entspricht
8.1 Installation
• Runterladen des Programm
• Speichern in einem Ordner
8.2 Arbeitsablauf
• Starten des Programms
• Öffnen einer XML-Datei mit Strg+O o Dann Auswahl
• Öffnen einer XML-Datei mit Strg+O
o Dann die Maske eingeben *.dtd und auswählen
• Bearbeiten der XML bzw. DTD-Datei
• Prüfen:
o Menü Tools, Eintrag „Check Validity“
o oder Shift+Strg+W o oder Schalter
9 Literatur und Links
9.1 Literatur
Helmut Vonhoegen Einstieg in XML
ISBN 978-3-8362-1367-7
Frank Bongers XSLT 2,0 & XPath 2.0 ISBN 97-3-89842-694-7
9.2 Links
• http://aktuell.de.selfhtml.org/links/xml.htm
• http://www.edition-w3c.de/TR/2000/REC-xml-20001006/
• http://www.uzi-web.de/
• http://www.w3schools.com/xmL/xml_cdata.asp
• http://www.syntext.com/downloads/serna-free/
• http://www.w3.org/Style/XSL/
• http://de.selfhtml.org/xml/darstellung/xsltbeispiele.htm
• http://www.w3.org/1999/XSL/Transform
10 Stichwortverzeichnis
A
Achsen · 27 Attributwerte · 21
Auto · 22 Beispiele · 21
Aufbau von XML-Dateien · 9 Aufzählung · 22
B
Beispiel 5 · 16 Beispiele · 13
Adressen, externe DTD · 16 Adressen, interne DTD · 15 Externe DTD · 14
note · 13 Student · 13 zwei Vornamen · 17
C
CDATA · 9
D
Dateierweiterungen · 9 DTD · 12
E
Eigene Tags · 5 Einleitung · 5 EMPTY · 23
H
HTML · 7
K
Kernow · 34
L