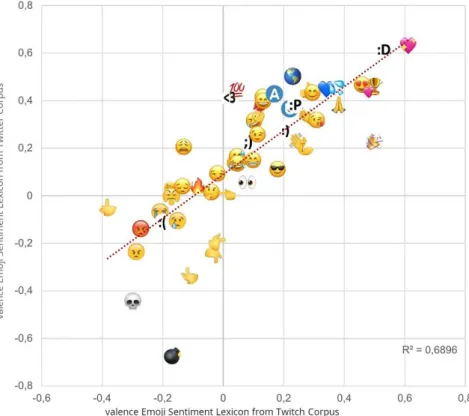
Design and Development of an Emoji Sentiment Lexicon
7
0
0
Volltext
(2)
(3)
(4)
(5)
(6)
(7)
Abbildung
ÄHNLICHE DOKUMENTE
Using Twitter API we collected a corpus of text posts and formed a dataset of three classes: positive sentiments, nega- tive sentiments, and a set of objective texts (no
Wird ein Knoten mit einer nicht-neutralen Polarit¨at (also negative oder positive) gefunden, wird diese als Polarit¨at f¨ur den entsprechenden Aspekt angenommen.. Nur wenn
Authors in (Araque et al., 2017) proposed a classifier ensemble model that combines surface- level features and generic word vectors for the sentiment classification. However, our
Our system is placed first in sentiment polarity classification for the English laptop domain, Spanish and Turkish restaurant reviews, and opinion target expres- sion for Dutch
Using a comprehensive sample of the Chinese A-share index ranged from 2006-01 to 2015-12, we formed a market-wide investor sentiment index in the monthly frequency
The analysis of the role of investor sentiment on REIT returns and volatility during the REIT liquidity crisis begins by examining whether investor sentiment is a significant factor
This paper describes an approach to uti- lizing term weights for sentiment analysis tasks and shows how various term weight- ing schemes improve the performance of sentiment
205.. Motivated by the latter approach, this paper presents a method for automati- cally creating a sentiment lexicon in a new language using a sentiment lexicon in a
