All the Numbers are US: Large-scale Abuse of Contact Discovery in Mobile Messengers
Christoph Hagen†, Christian Weinert‡, Christoph Sendner†, Alexandra Dmitrienko†, Thomas Schneider‡
†University of W¨urzburg, Germany, {christoph.hagen,christoph.sendner,alexandra.dmitrienko}@uni-wuerzburg.de
‡Technical University of Darmstadt, Germany, {weinert,schneider}@encrypto.cs.tu-darmstadt.de
Abstract— Contact discovery allows users of mobile messen- gers to conveniently connect with people in their address book.
In this work, we demonstrate that severe privacy issues exist in currently deployed contact discovery methods.
Our study of three popular mobile messengers (WhatsApp, Signal, and Telegram) shows that, contrary to expectations, large- scale crawling attacks are (still) possible. Using an accurate database of mobile phone number prefixes and very few resources, we have queried 10 % of US mobile phone numbers for WhatsApp and 100 % for Signal. For Telegram we find that its API exposes a wide range of sensitive information, even about numbers not registered with the service. We present interesting (cross- messenger) usage statistics, which also reveal that very few users change the default privacy settings. Regarding mitigations, we propose novel techniques to significantly limit the feasibility of our crawling attacks, especially a new incremental contact discovery scheme that strictly improves over Signal’s current approach.
Furthermore, we show that currently deployed hashing-based contact discovery protocols are severely broken by comparing three methods for efficient hash reversal of mobile phone numbers.
For this, we also propose a significantly improved rainbow table construction for non-uniformly distributed inputs that is of independent interest.
I. INTRODUCTION
Contact discovery is a procedure run by mobile messaging applications to determine which of the contacts in the user’s address book are registered with the messaging service. Newly registered users can thus conveniently and instantly start messaging existing contacts based on their phone number without the need to exchange additional information like user names, email addresses, or other identifiers1.
Centralized messaging platforms can generally learn the social graphs of their users by observing messages exchanged between them. Current approaches to protect against this type of traffic analysis are inefficient [80], with Signal attempting to improve their service in that regard [46]. While only active users are exposed to such analyses, the contact discovery process potentially reveals allcontacts of users to the service provider, since they must in some way be matched with the server’s database. This is one of the reasons why messengers like Whats- App might not be compliant with the European GDPR in a business context [21], [77].
Cryptographic protocols for private set intersection (PSI) can perform this matching securely. Unfortunately, they are currently not efficient enough for mobile applications with billions of users [37]. Furthermore, even when deploying PSI protocols, this does not resolve all privacy issues related to contact discovery as they cannot prevent enumeration attacks, where an attacker attempts to discover which phone numbers are registered with the service.
Leaking Social Graphs.Worryingly, recent work [37] has shown that many mobile messengers (including WhatsApp) facilitate contact discovery by simply uploading all contacts from the user’s address book2 to the service provider and even store them on the server if no match is found [2]. The server can then notify the user about newly registered users, but can also construct the full social graph of each user. These graphs can be enriched with additional information linked to the phone numbers from other sources [12], [29], [30]. The main privacy issue here is that sensitive contact relationships can become known and could be used to scam, discriminate, or blackmail users, harm their reputation, or make them the target of an investigation. The server could also be compromised, resulting in the exposure of such sensitive information even if the provider is honest.
To alleviate these concerns, some mobile messaging appli- cations (including Signal) implement a hashing-based contact discovery protocol, where phone numbers are transmitted to the server in hashed form [37]. Unfortunately, the low entropy of phone numbers indicates that it is most likely feasible for service providers to reverse the received hash values [50] and therefore, albeit all good intentions, there is no gain in privacy.
Crawling.Unfortunately, curious or compromised service providers are not the only threat. Malicious users or external parties might also be interested in extracting information about others. Since there are usually no noteworthy restrictions for signing up with such services, any third party can create a large number of user accounts to crawl this database for information by requesting data for (randomly) chosen phone numbers.
Such enumeration attacks cannot be fully prevented, since legitimate users must be able to query the database for contacts.
In practice, rate-limiting is a well-established measure to effectively mitigate such attacks at a large scale, and one would assume that service providers apply reasonable limits to protect their platforms. As we show in § IV, this is not the case.
The simple information whether a specific phone number is registered with a certain messaging service can be sensitive in
2Assuming that users give the app permission to access contacts, which is very likely since otherwise they must manually enter their messenger contacts.
1Some mobile applications of social networks perform contact discovery also using email addresses stored in the address book.
Network and Distributed Systems Security (NDSS) Symposium 2021 21-25 February2021,Virtual
ISBN 1-891562-66-5
https://dx.doi.org/10.14722/ndss.2021.23159 www.ndss-symposium.org
many ways, especially when it can be linked to a person. For example, in areas where some services are strictly forbidden, disobeying citizens can be identified and persecuted.
Comprehensive databases of phone numbers registered with a particular service can also allow attackers to perform exploitation at a larger scale. Since registering a phone number usually implies that the phone is active, such databases can be used as a reliable basis for automated sales or phishing calls.
Such “robocalls” are already a massive problem in the US [79]
and recent studies show that telephone scams are unexpectedly successful [78]. Two recent WhatsApp vulnerabilities, where spyware could be injected via voice calls [73] or where remote code execution was possible through specially crafted MP4 files [26], could have been used together with such a database to quickly compromise a significant number of mobile devices.
Which information can be collected with enumeration attacks depends on the service provider and the privacy settings (both in terms of which settings are chosen by the user and which are available). Examples for personal (meta) data that can commonly be extracted from a user’s account include profile picture(s), nickname, status message, and the last time the user was online. In order to obtain such information, one can simply discover specific numbers, or randomly search for users [71].
By tracking such data over time, it is possible to build accurate behavior models [8], [72], [87]. Matching such information with other social networks and publicly available data sources allows third parties to build even more detailed profiles [12], [29], [30].
From a commercial perspective, such knowledge can be utilized for targeted advertisement or scams; from a personal perspective for discrimination, blackmailing, or planning a crime; and from a nation state perspective to closely monitor or persecute citizens [14]. A feature of Telegram, the possibility to determine phone numbers associated with nicknames appearing in group chats, lead to the identification of “Comrade Major” [85] and potentially endangered many Hong Kong protesters [14].
Our Contributions. We illustrate severe privacy issues that exist in currently deployed contact discovery methods by performing practical attacks both from the perspective of a curious service provider as well as malicious users.
a) Hash Reversal Attacks: Curious service providers can exploit currently deployed hashing-based contact discovery methods, which are known to be vulnerable [20], [48], [50].
We quantify the practical efforts for service providers (or an attacker who gains access to the server) for efficiently reversing hash values received from users by evaluating three approaches: (i) generating large-scale key-value stores of phone numbers and corresponding hash values for instantaneous dictionary lookups, (ii) hybrid brute-force attacks based on hashcat [74], and (iii) a novel rainbow table construction.
In particular, we compile an accurate database of world- wide mobile phone prefixes (cf. § II) and demonstrate in § III that their hashes can be reversed in just 0.1 ms amortized time per hash using a lookup database or 57 ms when brute- forcing. Our rainbow table construction incorporates the non- uniform structure of all possible phone numbers and is of independent interest. We show that one can achieve a hit rate of over 99.99 % with an amortized lookup time of 52 ms while only requiring 24 GB storage space, which improves over classical rainbow tables by more than factor 9,400x in storage.
b) Crawling Attacks: For malicious registered users and outside attackers, we demonstrate that crawling the global databases of the major mobile messaging services WhatsApp, Signal, and Telegram is feasible. Within a few weeks time, we were able to query 10 % of all US mobile phone numbers for WhatsApp and 100 % for Signal. Our attack uses very few resources: the free Hushed [1] application for registering clients with new phone numbers, a VPN subscription for rotating IP addresses, and a single laptop running multiple Android emulators. We report the rate limits and countermeasures experienced during the process, as well as other interesting findings and statistics. We also find that Telegram’s API reveals sensitive personal (meta) data, most notably how many users include non-registered numbers in their contacts.
c) Mitigations: We propose a novel incremental contact discovery scheme that does not require server-side storage of client contacts (cf. § V). Our evaluation reveals that our approach enables deploying much stricter rate limits without de- grading usability or privacy. In particular, the currently deployed rate-limiting by Signal can be improved by a factor of 31.6x at the cost of negligible overhead (assuming the database of registered users changes 0.1 % per day). Furthermore, we provide a comprehensive discussion on potential mitigation techniques against both hash reversal and enumeration attacks in § VI, ranging from database partitioning and selective contact permissions to limiting contact discovery to mutual contacts.
Overall, our work provides a comprehensive study of privacy issues in mobile contact discovery and the methods deployed by three popular applications with billions of users. We investigate three attack strategies for hash reversal, explore enumeration attacks at a much larger scale than previous works [30], [71], and discuss a wide range of mitigation strategies, including our novel incremental contact discovery that has the potential of real-world impact through deployment by Signal.
Outline. We first describe our approach to compile an accurate database of mobile phone numbers (§ II), which we use to demonstrate efficient reversal of phone number hashes (§ III). We also use this information to crawl WhatsApp, Signal, and Telegram, and present insights and statistics (§ IV).
Regarding mitigations, we present our incremental contact dis- covery scheme (§ V) and discuss further techniques (§ VI). We then provide an overview of related work (§ VII) and conclude with a report on our responsible disclosure process (§ VIII).
II. MOBILEPHONENUMBERPREFIXDATABASE
In the following sections, we demonstrate privacy issues in currently deployed contact discovery methods by showing how alarmingly fast hashes of mobile phone numbers can be reversed (cf. § III) and that the database crawling of popular mobile messaging services is feasible (cf. § IV). Both attacks can be performed more efficiently with an accurate database of all possible mobile phone number prefixes3. Hence, we first show how such a database can be built.
A. Phone Number Structure
International phone numbers conform to a specific structure to be globally unique: Each number starts with a country
3Some messengers like WhatsApp and Signal also allow to register with landline phone numbers. We assume that very few users make use of this option, and also argue that gathering landline phone numbers is less attractive for attackers (e.g., when the goal is to infect smartphones with malware).
code (defined by the ITU-T standards E.123 and E.164, e.g.,+1 for the US), followed by a country-specific prefix and a subscriber number. Valid prefixes for a country are usually determined by a government body and assigned to one or more telecommunication companies. These prefixes have blocks of subscriber numbers assigned to them, from which numbers can be chosen by the provider to be handed out to customers. The length of the subscriber numbers is specific for each prefix and can be fixed or in a specified range.
In the following, we describe how an accurate list of (mo- bile) phone number prefixes can be compiled, including the possible length of the subscriber number. A numbering plan database is maintained by theInternational Telecommunication Union (ITU) [36] and further national numbering plans are linked therein. This database comprises more than 250 coun- tries (including autonomous cities, city states, oversea territories, and remote island groups) and more than 9,000 providers in total. In our experiments in § IV, we focus on the US, where there are 3,794 providers (including local branches).
Considering the specified minimum and maximum length of phone numbers, the prefix database allows for ≈52 trillion possible phone numbers (≈1.6 billion in the US). However, when limiting the selection to mobile numbers only, the search space is reduced to≈758 billion (≈0.5 billion in the US).
B. Database Preprocessing
As it turned out in our experiments, some of the numbers that are supposed to be valid according to the ITU still cannot be registered with the examined messaging applications. Therefore, we perform two additional preprocessing steps.
Google’s libphonenumber library [27] can validate phone numbers against a rule-based representation of inter- national numbering plans and is commonly used in Android applications to filter user inputs. By filtering out invalid numbers, the amount of possible mobile phone numbers can be reduced to ≈353 billion.
Furthermore, WhatsApp performs an online validation of the numbers before registration to check, for example, whether the respective number was banned before. This allows us to check all remaining prefixes against the WhatsApp registra- tion/login API by requesting the registration of one number for each prefix and each possible length of the subscriber number.
Several more prefixes are rejected by WhatsApp for reasons like “too long” or “too short”. Our final database for our further experiments thus contains up to ≈118 billion mobile phone numbers (≈0.5 billion in the US4). In § A we detail interesting relative differences in the amount of registrable mobile phone numbers between countries.
III. MOBILEPHONENUMBERHASHREVERSAL
Although the possibility of reversing phone number hashes has been acknowledged before [20], [48], [50], the severity of the problem has not been quantified. The amount of possible mobile phone numbers that we determined in § II indicates the feasibility of determining numbers based on their hash values. In the following, we show thatreal-time hash reversal is practical not only for service providers and adversaries with powerful resources, but even at a large scale using commodity hardware only.
4libphonenumberand WhatsApp reject no US mobile prefixes.
Threat Model.Here we consider the scenario where users provide hashed mobile phone numbers of their address book entries to the service provider of a mobile messaging application during contact discovery. The adversary’s goal is to learn the numbers from their hashed representation. For this, we assume the adversary has full access to the hashes received by the service provider. The adversary therefore might be the service provider itself (being “curious”), an insider (e.g., an administrator of the service provider), a third party who compromised the service provider’s infrastructure, or a law enforcement or intelligence agency who forces the service provider to hand out information. Importantly, we assume the adversary has no control over the users and does not tamper with the contact discovery protocol.
We compare three different approaches to reverse hashes of mobile phone numbers, each suitable for different purposes and available resources. In order to ensure comparability and uniqueness, phone numbers are processed as strings without spaces or dashes, and including their country code. Some applications add the “+”-sign as a prefix to conform to the E.164 format. In our experiments, numbers only consist of digits, but all approaches work similarly for other formats. We choose SHA-1 as our exemplary hash function, which is also used by Signal for contact discovery5.
A. Hash Database
The limited amount of possible mobile phone numbers combined with the rapid increase in affordable storage capacity makes it feasible to create key-value databases of phone numbers indexed by their hashes and then to perform constant- time lookups for each given hash value. We demonstrate this by using a high-performance cluster to create an in- memory database of all 118 billion possible mobile phone numbers from § II-B (i.e., mobile phone numbers allowed by Google’slibphonenumberand the WhatsApp registra- tion API) paired with their SHA-1 hashes.
Benchmarks. We use one node in our cluster, consisting of 48 Intel Skylake cores at 2.3 GHz, 630 GB of RAM, and 1 TB of disk storage. We choose a Redis database due to its robustness, in-memory design, and near constant lookup- time [70]. Since one Redis instance cannot handle the required number of keys, we construct a cluster of 120 instances on our node. Populating the table requires ≈13 hin our experiments due to several bottlenecks, e.g., the interface to the Redis cluster can only be accessed through a network interface. Unfortunately, only 8 billion hashes (roughly 6.8 % of the considered number space) can fit into the RAM with our test setup. We perform batched lookups of 10,000 items, which on average take 1.0 s, resulting in an amortized lookup time of 0.1 ms.
To cover the entire mobile phone number space, a system with several Terabytes of RAM would be necessary, which makes this type of hash reversal feasible for attackers with moderate financial resources, such as large companies or nation state actors. For attackers with consumer hardware, it would also be feasible to store a full database on disk, which requires roughly 3.3 TB of storage space6, but results in significantly higher lookup times due to disk access latencies.
5Signal truncates the SHA-1 output to 10 B to reduce communication overhead while still producing unique hashes for all possible phone numbers.
6Assuming SHA-1 hashes of 20 bytes and 64-bit encoded phone numbers.
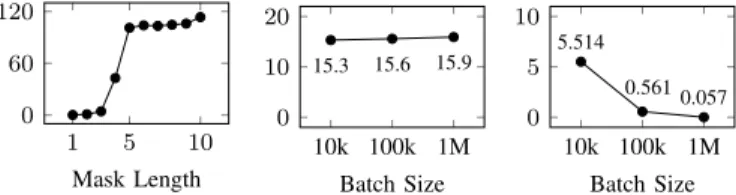
1 5 10 0
60 120
Mask Length (a) Hash rates in MH/s.
10k 100k 1M 0
10 20
15.3 15.6 15.9
Batch Size (b) Total times in h.
10k 100k 1M 0
5 10
5.514
0.5610.057
Batch Size (c) Amort. times in s.
Figure 1: Brute-force benchmark results.
B. Brute-Force
Another possibility to reverse phone number hashes is to iteratively hash every element of the input domain until a matching hash is found. A popular choice for this task is the open-source tool hashcat [74], which is often used to brute- force password hashes. Hashcat can efficiently parallelize the brute-force process and additionally utilize GPUs to maximize performance. With its hybrid brute-forcing mode it is possible to specify masks that constrain the inputs according to a given structure. We use this mode to model our input space of 118 billion mobile phone numbers (cf. § II-B).
Benchmarks.We perform lookups of phone number hashes on one node of our high-performance cluster with two In- tel Xeon Gold 6134 (8 physical cores at 3.2 GHz), 384 GB of RAM, and two NVIDIA Tesla P100 GPUs (16 GB of RAM each). Our setup has a theoretical rate of 9.5 GHashes/s accord- ing to the hashcat benchmark. This would allow us to search the full mobile phone number space in less than 13 seconds.
However, the true hash rate is significantly lower due to the overhead introduced by hashcat when distributing loads for processing. Since many of the prefixes have short subscriber numbers (e.g., 158,903 prefixes with length 4 digits), the overhead of distributing the masks is the bottleneck for the calculations, dropping the true hash rate to 4.3 MHashes/s for 3-digit masks (less than 0.05 % efficiency). The hash rate reaches its plateau at around 105 MHashes/s for masks larger than 4 digits (cf. Fig. 1a), which is still only 1.1 % of the theoretical hash rate.
A full search over the number space can be completed in 15.3 hours for batches of 10,000 hashes. While the total time only slightly increases with larger batch sizes (cf. Fig. 1b), the amortized lookup rate drops significantly, to only 57 ms per hash for batches of 1 million hashes (cf. Fig. 1c). Consequently, the practical results show that theoretical hash rates cannot be reached by simply deploying hashcat and that additional engineering effort would be required to optimize brute-force software for efficient phone number hash reversal.
C. Optimized Rainbow Tables
Rainbow tables are an interesting time-memory trade-off to reverse hashes (or any one-way function) from a limited input domain. Based on work from Hellman [32] and Oechslin [55], they consist of precomputed chains of plaintexts from the input domain and their corresponding hashes. These are chained together by a set of reduction functions, which map each hash back to a plaintext. By using this mapping in a deterministic chain, only the start and end of the chain must be stored to be able to search for all plaintexts in the chain. A large number of
chains with random start points form a rainbow table, which can be searched by computing the chain for the given hash, and checking if the end point matches one of the entries in the table. If a match is found, then the chain can be computed from the corresponding start index to reveal the original plaintext.
The length of the chains determines the time-memory trade- off: shorter chain lengths require more chains to store the same number of plaintexts, while longer chains increase the computation time for lookups. The success rate of lookups is determined by the number of chains, where special care has to be taken to limit the number of duplicate entries in the table by carefully choosing the reduction functions.
Each rainbow table is specific to the hash algorithm being used, as well as the specifications of the input domain, which determines the reduction functions. Conventional rainbow tables work by using a specific alphabet as well as a maximum input length, e.g., 8-digit ASCII numbers7. While they can be used to work on phone numbers as well, they are extremely inefficient for this purpose: to cover numbers conforming to the E.164 standard (up to 15 digits), the size of the input domain would be 1015, requiring either huge storage capacity or extremely long chains to achieve acceptable hit rates.
By designing new reduction functions that always map a hash back into a valid phone number, we improve performance significantly. While we use our approach to optimize rainbow tables for phone numbers, our construction can also find application in other areas, e.g., advanced password cracking.
Specialized Reduction Functions.Our optimization relies on the specific structure of mobile phone numbers, which consist of a country code, a mobile prefix, and a subscriber number of a specific length (cf. § II). Conventional reduction functions simply perform a modulo operation to map each hash back to the input domain, with additional arithmetic to reduce the number of collisions in the table.
Our algorithm concatenates ranges of valid mobile phone numbers into a virtual table, which we can index with a given hash. For each prefix, we store the amount of possible subscriber numbers and the offset of the range within the table. To select a valid number, we calculate the index from the 64-bit prefix of the given hash modulo the table size and perform a binary search for the closest smaller offset to determine the corre- sponding mobile prefix. Subtracting the offset from the index yields the subscriber number. For example, given Tab. I and index 3,849,382, we select the prefix+491511and calculate the subscriber number as 3,849,382−110,000 = 3,739,382, yielding the valid mobile phone number+491511 3739382.
In practice, our algorithm includes additional inputs (e.g., the current chain position) to limit the number of collisions and duplicate chains. The full specification is given in § B.
Implementation. We implement our optimized rainbow table construction based on the open-source version 1.28 of RainbowCrack [35]. To improve table generation and lookup performance, we add multi-threading to parts of the program via OpenMP [57]. SHA-1 hash calculations are performed using OpenSSL [58]. The table generation is modified to receive
7There are implementations that allow per-character alphabets [7], which is not applicable to phone numbers, since the allowed digits for each position strongly depend on the previous characters. More details are given in § C.
8Newer versions of RainbowCrack that support multi-threading and GPU ac- celeration exist, but are not open-source [68].
Country Code + Prefix # Subscriber Numbers Offset
+1982738 10,000 0
+172193 100,000 10,000
+491511 10,000,000 110,000 +49176 10,000,000 10,110,000
Table I: Example for selecting the next phone number from a hash value for our improved rainbow table construction.
the number specification as an additional parameter (a file with a list of phone number prefixes and the length of their subscriber numbers). Our open-source implementation is available at https://contact-discovery.github.io/.
Benchmarks. We generate a table of SHA-1 hashes for all registrable mobile phone numbers (118 billion numbers, cf. § II) and determine its creation time and size depending on the desired success rate for lookups, as well as lookup rates.
Our test system has an Intel Core i7-9800X with 16 physical cores and 64 GB RAM (only 2 GB are used), and can perform over 17 million hash-reduce operations per second.
We store 100 million chains of length 1,000 in each file, which results in files of 1.6 GB with a creation time of≈98 minutes each. For a single file, we already achieve a success rate of over 50 % and an amortized lookup time of less than 26 ms for each hash when testing batches of 10,000 items.
With 15 files (24 GB, created within 24.5 hours) the success rate is more than 99.99 % with an amortized lookup time of 52 ms.
In comparison, a conventional rainbow table of all 7 to 15- digit numbers has an input domain more than 9,400x larger than ours, and (with similar success rates and the same chain length) would require approximately 230 TB of storage and a creation time of more than 26 years on our test system (which is a one-time expense). The table size can be reduced by increasing the chain length, but this would result in much slower lookups.
These measurements show that our improved rainbow table construction makes large-scale hash reversal of phone numbers practical even with commodity hardware and limited financial investments. Since the created tables have a size of only a few gigabytes, they can also be easily distributed.
D. Comparison of Hash Reversal Methods
Our results for the three different approaches are sum- marized in Tab. II. Each approach is suitable for different application scenarios, as we discuss in the following. In § D, we discuss further optimizations for the presented methods.
A full in-memory hash database (cf. § III-A) is an option only for well-funded adversaries that require real-time reversal of hashes. It is superior to the brute-force method and rainbow tables when considering lookup latencies and total runtimes.
Brute-force cracking (cf. § III-B) is an option for a range of adversaries, from nation state actors to attackers with consumer- grade hardware, but requires non-trivial effort to perform efficiently, because publicly available tools do not perform well for phone numbers. Batching allows to significantly improve the amortized lookup rate, making brute-force cracking more suitable when a large number of hashes is to be reversed, e.g., when an attacker compromised a database.
Our optimized rainbow tables (cf. § III-C) are the approach most suited for adversaries with commodity hardware, since
Evaluation Criteria Hash Database Brute-Force Rainbow Tables
§ III-A § III-B § III-C
Generation Time 13 h – 24.5 h
RAM / Storage Requirements ≥3.3 TB – / – 2 GB / 24 GB
Lookup Time per 10k Batch 1 s 15.3 h 520 s
Best Amortized Time per Hash 0.1 ms 57 ms 52 ms
GPU Acceleration 7 3 (3)
Table II: Comparison of phone number hash reversal methods.
these tables can be calculated in reasonable time, require only a few gigabytes of storage, can be easily customized to specific countries or number ranges and types, and can reverse dozens of phone number hashes per second. It is also possible to easily share and use precomputed rainbow tables, which is done for conventional rainbow tables as well [67], despite their significantly larger size.
For other hash functions than SHA-1, we expect reversal and generation times to vary by a constant factor, depending on the computation time of the hash function [31] (except for hash databases where look-up times remain constant).
Our results show that hashing phone numbers for privacy reasons does not provide any protection, as it is easily possible to recover the original number from the hash. Thus, we strictly advise against the use of hashing-based protocols in their current form for contact discovery when users are identified by low- entropy identifiers such as phone numbers, short user names, or email addresses. In § VI-A, we discuss multiple ideas how to at least strengthen hashing-based protocols against the presented hash reversal methods.
IV. USERDATABASECRAWLING
We study three popular mobile messengers to quantify the threat of enumeration attacks based on our accurate phone number database from § II-B: WhatsApp, Signal, and Telegram.
All three messengers discover contacts based on phone numbers, yet differ in their implementation of the discovery service and the information exposed about registered users.
Threat Model. Here we consider an adversary who is a registered user and can query the contact discovery API of the service provider of a mobile messaging application. For each query containing a list of mobile phone numbers (e.g., in hashed form) an adversary can learn which of the provided numbers are registered with the service along with further information about the associated accounts (e.g., profile pictures). The concrete contact discovery implementation is irrelevant and it might be even based on PSI (cf. § VI-A). The adversary’s goal is to check as many numbers as possible and also collect all additional information and meta data provided for the associated accounts.
The adversary may control one user account or even multiple accounts, and is restricted to (ab)use the contact discovery API with well-formed queries. This implies that we assume no invasive attacks, e.g., compromising other users or the service provider’s infrastructure.
A. Investigated Messengers
WhatsApp.WhatsApp is currently one of the most popular messengers in the world, with 2.0 billion users [25]. Launched in 2009, it was acquired by Facebook in 2014 for approxi- mately 19.3 billion USD.
Signal.The Signal Messenger is an increasingly popular messenger focused on privacy. Their end-to-end-encryption protocol is also being used by other applications, such as WhatsApp, Facebook, and Skype. There are no recent statistics available regarding Signal’s growth and active user base.
Telegram. Telegram is a cloud-based messenger that re- ported 400 million users in April 2020 [23].
B. Differences in Contact Discovery
Both WhatsApp and Telegram transmit the contacts of users in clear text to their servers (but encrypted during transit), where they are stored to allow the services to push updates (such as newly registered contacts) to the clients. WhatsApp stores phone numbers of its users in clear text on the server, while phone numbers not registered with WhatsApp are MD5-hashed with the country prefix prepended (according to court documents from 2014 [2]).
Signal does not store contacts on the server. Instead, each client periodically sends hashes of the phone numbers stored in the address book to the service, which matches them against the list of registered users and responds with the intersection.
The different procedures illustrate a trade-off between usability and privacy: the approach of WhatsApp and Telegram can provide faster updates to the user with less communication overhead, but needs to store sensitive data on the servers.
C. Test Setups
We evaluate the resistance of these three messengers against large-scale enumeration attacks with different setups.
WhatsApp. Because WhatsApp is closed source, we run the official Android application in an emulator, and use the Android UI Automator framework to control the user interface. First, we insert 60,000 new phone numbers into the address book of the device, then start the client to initiate the contact discovery. After synchronization, we can automatically extract profile information about the registered users by stepping through the contact list. New accounts are registered manually following the standard sign-up procedure with phone numbers obtained from the free Hushed [1] application.
Interestingly, if the number provided by Hushed was previously registered by another user, the WhatsApp account is “inherited”, including group memberships. A non-negligible percentage of the accounts we registered had been in active use, with personal and/or group messages arriving after account takeover. This in itself presents a significant privacy risk for these users, comparable to (and possibly worse than) privacy issues associated with disposable email addresses [33]. We did not use such accounts for our crawling attempts.
Signal.The Android client of Signal is open-source, which allows us to extract the requests for registration and contact discovery, and perform them efficiently through a Python script.
We register new clients manually and use the authentication tokens created upon registration to perform subsequent calls to the contact discovery API. Signal uses truncated SHA-1 hashes of the phone numbers in the contact discovery request9. The response from the Signal server is either an error message if the rate limit has been reached, or the hashes of the phone numbers registered with Signal.
9We use the legacy API; the new Intel SGX service does not use hashes.
Telegram.Interactions with the Telegram service can be made through the official library TDLib [76], which is available for many systems and programming languages. In order to create a functioning client, each project using TDLib has to be registered with Telegram to receive an authentication token, which can be done with minimal effort. We use the C++ version to perform registration and contact discovery, and to potentially download additional information about Telegram users. The registration of phone numbers is done manually by requesting a phone call to authenticate the number.
D. Ethical and Legal Considerations
We excessively query the contact discovery services of major mobile messengers, which we think is the only way to reliably estimate the success of our attacks in the real world. Similar considerations were made in previous works that evaluate attacks by crawling user data from production systems (e.g., [82]). We do not interfere with the smooth operation of the services or negatively affect other users.
In coordination with the legal department of our institution, we design the data collection process as a pipeline creating only aggregate statistics to preserve user privacy and to comply with all requirements under the European General Data Protection Regulation (GDPR) [56], especially the data minimization principle (Article 5c) and regulations of the collection of data for scientific use (Article 89). Privacy sensitive information such as profile pictures are never stored, and all data processing is performed on a dedicated local machine.
E. Rate Limits and Abuse Protection
Each messenger applies different types of protection mech- anisms to prevent abuse of the contact discovery service10.
WhatsApp. WhatsApp does not disclose how it protects against data scraping. Our experiments in September 2019 show that accounts get banned when excessively using the contact discovery service. We observe that the rate limits have a leaky bucket structure, where new requests fill a virtual bucket of a certain size, which slowly empties over time according to a specified leak rate. Once a request exceeds the currently remaining bucket size, the rate limit is reached, and the request will be denied. We estimate the bucket size to be close to 120,000 contacts, while our crawling was stable when checking 60,000 new numbers per day. There seems to be no total limit of contacts per account: some of our test accounts were able to check over 2.8 million different numbers.
Signal. According to the source code [47], the Signal servers use a leaky bucket structure. However, the parameters are not publicly available. Our measurements show that the bucket size is 50,000 contacts, while the leak rate is approximately 200,000 new numbers per day. There are no bans for clients that exceed these limits: The requests simply fail, and can be tried again later. There is no global limit for an account, as the server does not store the contacts or hashes, and thus cannot determine how many different numbers each account has already checked.
While we only use Signal’s hashing-based legacy API, current Android clients also sync with the new API based on Intel SGX and compare the results. We found that the
10There might be additional protections not triggered by our experiments.
new API has the same rate limits as the legacy API, allowing an attacker to use both with different inputs, and thus double the effective crawling rate.
Signal clients use an additional API to download encrypted profile pictures of discovered contacts. Separate rate limits exist to protect this data, with a leaky bucket size of 4,000 and a leak rate of around 180 profiles per hour.
Telegram.The mechanism used by Telegram to limit the contact discovery process differs from WhatsApp and Signal.
Telegram allows each account to add a maximum of 5,000 con- tacts, irrespective of the rate. Once this limit is exceeded, each account is limited to 100 new numbers per day. More requests result in a rate limit error, with multiple violations resulting in the ban of the phone number from the contact discovery service.
The batch size for contact requests is 100 and performing consecutive requests with a delay of less than≈8.3 s results in an immediate ban from the service.
In a response to the privacy issue discovered in Au- gust 2019 [14], where group members with hidden phone numbers can be identified through enumeration attacks, Tele- gram stated that once phone numbers are banned from contact discovery, they can only sync 5 contacts per day. We were not able to reproduce this behavior. Following our responsible disclosure, Telegram detailed additional defenses not triggered by our experiments (cf. § VIII).
F. Exposed User Data
All three messengers differ significantly regarding the amount of user data that is exposed.
WhatsApp. Users registered with WhatsApp can always be discovered by anyone through their phone number, yet the app has customizable settings for the profile picture,Abouttext, and Last Seen information. The default for all these settings is Everybody, with the other options being My Contacts orNobody. In recent Android versions it is no longer possible to save the profile picture of users through the UI, but it is possible to create screenshots through the Android Debug Bridge (ADB).
The status text can be read out through the UI Automator framework by accessing the text fields in the contact list view.
Signal.The Signal messenger is primarily focused on user privacy, and thus exposes almost no information about users through the contact discovery service. The only information available about registered users is their ability to receive voice and video calls. It is also possible to retrieve the encrypted profile picture of registered users through a separate API call, if they have set any [84]. However, user name and avatar can only be decrypted if the user has consented to this explicitly for the user requesting the information and has exchanged at least one message with them [45].
Telegram.Telegram exposes a variety of information about users through the contact discovery process. It is possible to access first, last, and user name, a short bio (similar to WhatsApp’sAbout), a hint when the user was last online, all profile pictures of the user (up to 100), and the number of common groups. Some of this information can be restricted to contacts only by changing the default privacy settings of the account. There is also additional management information (such as the Telegram ID), which we do not detail here.
Surprisingly, Telegram also discloses information about numbers not registered with the service through an integer
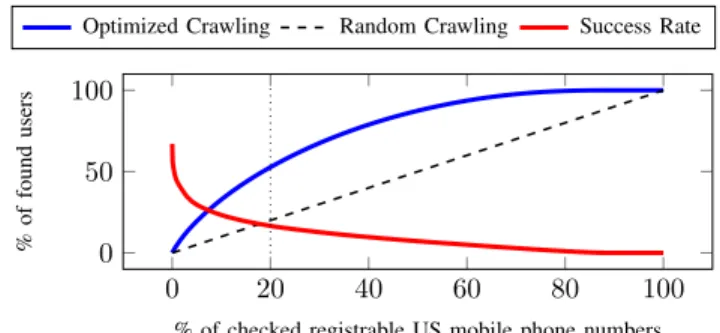
0 20 40 60 80 100
0 50 100
% of checked registrable US mobile phone numbers
%offoundusers
Optimized Crawling Random Crawling Success Rate
Figure 2: Optimized crawling compared to random crawling based on the non-uniform distribution of registered WhatsApp users across the US mobile phone number space.
labeled importer_count. According to the API documen- tation [75], it indicates how many registered users store a particular number in their address book, and is 0 for registered numbers11. Importantly, it represents the current state of a number, and thus decrements once users remove the number from their contacts. As such, the importer_count is a source of interesting meta data when keeping a specific target under surveillance. Also, when crawlers attempt to compile comprehensive databases of likely active numbers for conducting sales or phishing calls (as motivated in § I), having access to theimporter_countincreases the efficiency. And finally, numbers with non-zero values are good candidates to check on other messengers.
G. Our Evaluation Approach
We perform random lookups for mobile phone numbers in the US and collect statistics about the number of reg- istered users, as well as the information exposed by them.
The number space consists of 505.7 million mobile phone numbers (cf. § II-B). We assume that almost all users sign up for these messengers with mobile numbers, and thus exclude landline and VoIP numbers from our search space. The US numbering plan currently includes 301 3-digit area codes, which are split into 1,000 subranges of 10,000 numbers each. These subranges are handed out individually to phone companies, and only 50,573 of the 301,000 possible subranges are currently in use for mobile phone numbers. To reach our crawling targets, we select numbers evenly from all subranges. While the enumeration success rate could be increased by using telephone number lists or directories as used for telephone surveys [44], this would come at the expense of lower coverage.
H. Our Crawling Results
The messengers have different rate limits, amount of available user information, and setup complexity. This results in different crawling speeds and number space coverage, and affects the type of statistics that can be generated.
WhatsApp. For WhatsApp we use 25 accounts12 over 34 days, each testing 60,000 numbers daily, which allows us to check 10 % of all US mobile phone numbers. For a subset of discovered users, we also check if they have public profile pictures by comparing their thumbnails to the default icon.
11Telegram clients use this count to suggest contacts who would benefit the most from registering.
12Less than 100 for Signal due to the overhead of running Android emulators.
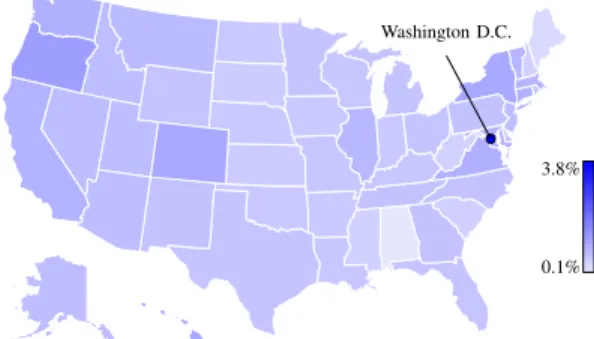
1.9%
47.4%
(a) WhatsApp; the popularity is estimated based on enumerat- ing 10 % of all possible US mobile phone numbers.
Washington D.C.
0.1%
3.8%
(b) Signal; Washington D.C. numbers are more than twice as likely to be registered with Signal than for any other area in the US.
Figure 3: Number of registered WhatsApp and Signal accounts of US states and Washington D.C. in relation to their population.
Messengers WhatsApp Signal Telegram
Contact Discovery Method Clear Hashing Clear
Rate Limits 60k / d 120k / d 5k + (100 / d)
Our Crawling Method UI Automator (Legacy) API API
# US Numbers Checked 46.2 M 505.7 M 0.1 M
Coverage of US Numbers 10 % 100 % <0.02 %
Success Rate for Random US Number 9.8 % 0.5 % 0.9 %
# US Users Found 5.0 M 2.5 M 908
# US Users (estimated) 49.6 M 2.5 M 4.6 M
Default Privacy Settings / Information Exposure
Profile Picture Public Explicit Share Public
Status Public – Public
Last Online Public – Public
Option to Hide Being Online 7 3 3
Option to Disable Contact Discovery 7 7 3
Table III: Comparison of surveyed messengers.
Users of
also use
WhatsApp Signal Telegram
WhatsApp – 2.2 % 5.1 %
Signal 42.3 % – 8.6 %
Telegram 46.5 % 5.3 % –
Table IV: Cross-messenger statistics for US users.
Our data shows that 5 million out of 50.5 million checked numbers are registered with WhatsApp, resulting in an average success rate of 9.8 % for enumerating random mobile phone numbers. The highest average for a single area code is 35.4 % for 718(New York) and 35 % for 305(Florida), while there are 209 subranges with a success rate higher than 50 % (the maximum is 67 % for a prefix in Florida). The non-uniform user distribution across the phone number space can be exploited to increase the initial success rate when enumerating entire countries, as shown in Fig. 2 for the US: with 20 % effort it is possible to discover more than 50 % of the registered users.
Extrapolating this data allows us to estimate the total number of WhatsApp accounts registered to US mobile phone numbers to be around 49.6 million. While there are no official numbers available, estimates from other sources place the number of monthly active WhatsApp users in the US at 25 million [16].
Our estimate deviates from this number, because our results include all registered numbers, not only active ones. Another statistic [17] estimates the number of US mobile phone numbers that accessed WhatsApp in 2019 at 68.1 million, which seems to be an overestimation based on our results.
For a random subset of 150,000 users we also analyzed the availability of profile pictures and About texts: 49.6 % have a publicly available profile picture and 89.7 % have a publicAbouttext. An analysis of the most popularAbouttexts shows that the predefined (language-dependent) text is the most popular (77.6 %), followed by “Available” (6.71 %), and the empty string (0.81 %, including “.” and “*** no status ***”), while very few users enter custom texts.
Signal.Our script for Signal uses 100 accounts over 25 days to check all 505 million mobile phone numbers in the US.
Our results show that Signal currently has 2.5 million users registered in the US, of which 82.3 % have set an encrypted user name, and 47.8 % use an encrypted profile picture. We also cross-checked with WhatsApp to see if Signal users differ in their use of public profile pictures, and found that 42.3 % of Signal users are also registered on WhatsApp (cf. Tab. IV), and 46.3 % of them have a public profile picture there.
While this is slightly lower than the average for WhatsApp users (49.6 %), it is not sufficient to indicate an increased privacy-awareness of Signal’s users, at least for profile pictures.
Telegram. For Telegram we use 20 accounts running for 20 days on random US mobile phone numbers. Since Tele- gram’s rate limits are very strict, only 100,000 numbers were checked during that time: 0.9 % of those are registered and 41.9 % have a non-zero importer_count. These num- bers have a higher probability than random ones to be present on other messengers, with 20.2 % of the numbers being registered with WhatsApp and 1.1 % registered with Signal, compared to the average success rates of 9.8 % and 0.9 %, respectively. Of the discovered Telegram users, 44 % of the crawled users have at least one public profile picture, with 2 % of users having more than 10 pictures available.
Summary and Comparison. An overview of the tested messengers, our crawling setup, and our most important results are given in Tab. III. Our crawling of WhatsApp, Signal, and Telegram provides insight into privacy aspects of these messengers with regard to their contact discovery service. The first notable difference is the storage of the users’ contact information, where both WhatsApp and Telegram retain this information on the server, while Signal chooses not to maintain a server-side state in order to better preserve the users’ privacy.
This practice unfortunately requires significantly higher rate- limits for the contact discovery process, since all of a user’s
contacts are compared on every sync, and the server has no possibility to compare them to previously synced numbers.
While Telegram uses the server-side storage of contacts to enforce strict rate limits, WhatsApp nevertheless lets individual clients check millions of numbers.
With its focus on privacy, Signal excels in exposing almost no information about registered users, apart from their phone number. In contrast, WhatsApp exposes profile pictures and the About text for registered numbers, and requires users to opt-out of sharing this data by changing the default settings.
Our results show that only half of all US users prevent such sharing by either not uploading an image or changing the settings. Telegram behaves even worse: it allows crawling multiple images and also additional information for each user.
The importer_count offered by its API even provides information about users not registered with the service. This can help attackers to acquire likely active numbers, which can be searched on other platforms.
Our results also show that many users are registered with multiple services (cf. Tab. IV), with 42.3 % of Signal users also being active on WhatsApp. We only found 2 out of 10,129 checked users on all three platforms (i.e., less than 0.02 %).
In Fig. 3, we visualize the popularity of WhatsApp and Signal for the individual US states and Washington D.C. On average, about 10 % of residents have mobile numbers from another state [22], which may obscure these results to some extent.
Interestingly, Washington D.C. numbers are more than twice as often registered on Signal than numbers from any other state, with Washington D.C. also being the region with the most non-local numbers (55 %) [22].
V. INCREMENTALCONTACTDISCOVERY
We propose a new rate-limiting scheme for contact discovery in messengers without server-side contact storage such as Signal.
Setting strict limits for services without server-side contact stor- age is difficult, since the server cannot determine if the user’s input in discovery requests changes significantly with each invocation. We named our new approach incremental contact discoveryand shared its details with the Signal developers who consider to implement a similar approach (cf. § VIII). Our approach provides strict improvements over existing solutions, as it enables the service to enforce stricter rate limits with negligible overhead and without degrading usability or privacy.
A. Approach
Incremental contact discovery is based on the observation that the database of registered users changes only gradually over time. Similarly, the contacts of legitimate users change only slowly. Given that clients are able to store the last state for each of their contacts, they only need to query the server for changes since the last synchronization. Hence, if the server tracks database changes (new and unsubscribed users), clients who connect regularly only need to synchronize with the set of recent database changes. This enables the server to enforce stricter rate limits on the full database, which is only needed for initial synchronization, for newly added client contacts, and whenever the client fails to regularly synchronize with the set of changes. Conversely, enumeration attacks require frequent changes to the client set, and thus will quickly exceed the rate limits when syncing with the full database.
Assumptions. Based on Signal’s current rate limits, we assume that each user has at mostm= 50,000contacts that are synced up to 4 times per day. This set changes slowly, i.e., only by several contacts per day. Another reasonable assumption is that the server database of registered users does not significantly change within short time periods, e.g., only 0.5 % of users join or leave the service per day (cf. § V-C).
Algorithm. The server of the service provider stores two sets of contacts: the full set SF and the delta set SD. SF contains all registered users, while SD contains only information about users that registered or unregistered within the last TF days. Both sets,SF and SD, are associated with their own leaky buckets of (the same) sizem, which are empty after TF and TD days, respectively. The server stores leaky bucket values tF and tD for each client, which represent the (future) points in time when the leaky buckets will be empty for requests to SF andSD, respectively.
A newly registered client syncs with the full set SF to receive the current state of the user’s contacts. For subsequent syncs, the client only syncs withSDto receive recently changed contacts, provided that it synchronizes at least everyTF days.
If the client is offline for a longer period of time, it can sync withSF again, since the leaky bucket associated with it will be empty. New contacts added by the user are initially synced withSF in order to learn their current state.
The synchronization withSF is given in Alg. 1. It takes as inputs the server’s setSF, the maximum number of contactsm, and the associated time TF after which the bucket will be empty. The client provides the set of contacts CF and the server provides the client’s corresponding bucket parametertF. The output is the setDwhich is the intersection ofCF withSF, or an error, if the rate limit is exceeded.
When a client initiates a sync with SF, the algorithm calculates tnew, the new (future) timestamp when the client’s leaky bucket would be empty (line 1). Here, |CF|/m×TF represents the additional time which the bucket needs to drain.
Iftnew is further into the future thanTF (line 2), this indicates that the maximum bucket size is reached, and the request will abort with an error (line 3). Otherwise, the leaky bucket is updated for the client (line 4), and the intersection between the client set CF and the server setSF is returned (line 5).
The synchronization with SD shown in Alg. 2 is quite similar. Here, the server supplies SF, SD, m, TD, and tD, and the client provides the previously synced contacts CD. The main difference to Alg. 1 is that it outputsRD, i.e., the requested contacts that changed (registered or unregistered) within the lastTF days together with their current state (line 5).
Note thatSF is only used to check the state for contacts inSD. Algorithm 1 Synchronization with full setSF
Input: SF,m,TF,CF,tF
Output: D
1: tnew←max(tF,current time) +|CF|/m×TF
2: iftnew>current time+TF then
3: raise RateLimitExceededError
4: tF ←tnew 5: returnCF∩SF
B. Implementation
We provide an open-source proof-of-concept imple- mentation of our incremental contact discovery scheme
Algorithm 2 Synchronization with delta setSD Input: SF,SD,m,TD,CD,tD
Output: RD
1: tnew←max(tD,current time) +|CD|/m×TD
2: iftnew>current time+TD then
3: raise RateLimitExceededError
4: tD←tnew
5: return{(x, x∈SF)forx∈CD∩SD}
written in Python at https://contact-discovery.github.io/. It uses Flask [54] to provide a REST API for performing contact discovery. While not yet optimized for performance, our implementation can be useful for service providers and their developers, and in particular can facilitate integration of our idea into real-world applications.
C. Evaluation
Overhead.Our incremental contact discovery introduces only minimal server-side storage overhead, since the only additional information is the set SD (which is small compared toSF), as well as the additional leaky bucket states for each user. The runtime is even improved, since subsequent contact discovery requests are only compared to the smaller setSD.
On the client side, the additional storage overhead is introduced by the need to store a timestamp of the last sync to select the appropriate set to sync with, as well as a set of previously unsynced contactsCD.
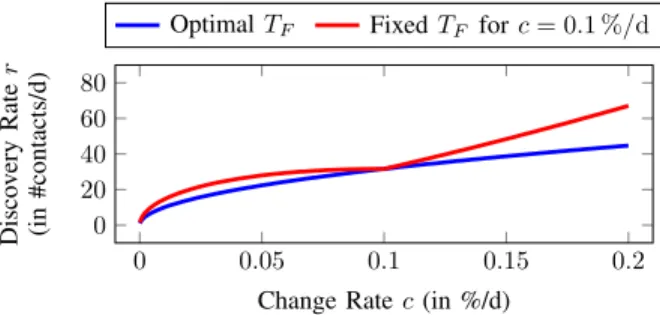
Improvement. To evaluate our construction, we compare it to the leaky bucket approach currently deployed by Signal.
Concretely, we compare thediscovery rateof the schemes, i.e., the number of users that can be found by a single client within one day with a random lookup strategy. Rate-limiting schemes should minimize this rate for attackers without impacting usability for legitimate users. For Signal, the discovery rate is r = s·4 ·50,000/day, where s is the success rate for a single lookup, i.e., the ratio between registered users and all possible (mobile) phone numbers. Based on our findings in § IV-H, we assume s= 0.5 %, which results in a discovery rate of r= 1,000/day for Signal’s leaky bucket approach.
For our construction, the discovery rate is the sum of the rates rF and rD for the buckets SF and SD, respectively.
WhilerF is calculated (similar to Signal) asrF =s·m/TF, rD is calculated as rD = s·m·c·TF/TD, where c is the change rate of the server database. To minimize r, we have to set TF = p
TD/c. With Signal’s parameters s = 0.5 %, m = 50,000, and TD = 0.25 days, the total discovery rate for our construction therefore is r= 1,000·√
c/day, and the improvement factor is exactly1/√
c.
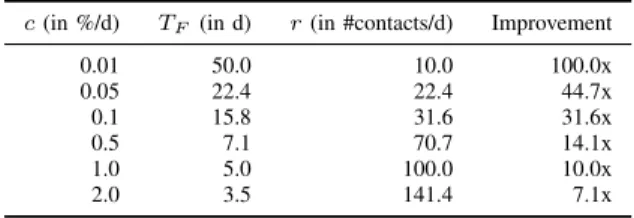
In reality, the expected change rate depends on the popular- ity of the platform: Telegram saw 1.5 M new registrations per day while growing from 300 M to 400 M users [23], corresponding to a daily change rate of ≈0.5 %. WhatsApp, reporting 2 billion users in February 2020 [25] (up from 1.5 bil- lion in January 2018 [18]), increases its userbase by an average of 0.05 % per day. Compared to Signal’s rate limiting scheme, incremental contact discovery results in an improvement of 14.1x and 44.7x for Telegram’s and WhatsApp’s change rate, respectively (cf. Tab. V). Even at a theoretical change rate of 25 % per day, incremental discovery is twice as effective as Signal’s current approach. Crawling entire countries would
c(in %/d) TF (in d) r(in #contacts/d) Improvement
0.01 50.0 10.0 100.0x
0.05 22.4 22.4 44.7x
0.1 15.8 31.6 31.6x
0.5 7.1 70.7 14.1x
1.0 5.0 100.0 10.0x
2.0 3.5 141.4 7.1x
Table V: Effect of change ratec on the optimal choice forTF, the discovery rater for our incremental contact discovery, and the improvement compared to Signal’s leaky bucket approach.
only be feasible for very powerful attackers, as it would require over 100k registered accounts (at c= 0.05 %) to crawl, e.g., the US in 24 hours. It should be noted that in practice the change rate cwill fluctuate over time. The resulting efficiency impact of non-optimal choices forTF is further analyzed in § E.
Privacy Considerations. If attackers can cover the whole number space every TF days, it is possible to find all newly registered users and to maintain an accurate database. This is not different from today, as attackers with this capacity can sweep the full number space as well. Using the result from Alg. 2, users learn if a contact in their set has (un)registered in the lastTF days, but this information can currently also be retrieved by simply storing past discovery results.
D. Generalization
Our construction can be generalized to further decrease an attacker’s efficiency. This can be achieved by using multiple sets containing the incremental changes of the server set over different time periods (e.g., one month, week, and day) such that the leak rate of SF can be further decreased. It is even possible to use sets dynamically chosen by the service without modifying the client: each client sends its timestamp of the last sync to the service, which can be used to perform contact discovery with the appropriate set.
VI. MITIGATIONTECHNIQUES
We now discuss countermeasures and (mostly known) mitigation techniques for both hash reversal and enumeration attacks. We discuss further supplemental techniques in § F.
A. Hash Reversal Mitigations
Private set intersection (PSI) protocols (cf. § VII-A) can compute the intersection between the registered user database and the users’ address books in a privacy-preserving manner.
Thus, utilizing provably secure PSI protocols in contact discov- ery entirely prevents attacks where curious service providers can learn the user’s social graph when receiving hashes of low-entropy contact identifiers such as phone numbers.
However, even with PSI, protocol participants can still perform enumeration attacks. Even with actively secure con- structions (where privacy is still guaranteed despite arbitrary deviations from the protocol), it is possible to choose different inputs for each execution. In fact, the privacy provided by PSI interferes with efforts to detect if the respective other party replaced the majority of inputs compared to the last execution.
Thus, these protocols must be combined with protections against enumeration attacks by restricting the number of protocol executions and inputs to the minimum (cf. § VI-B and § V).