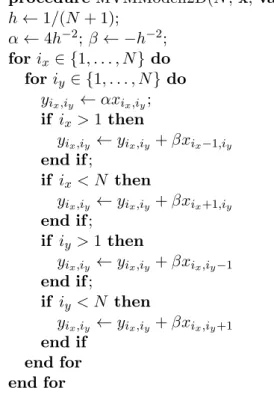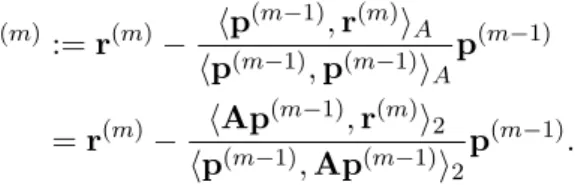f¨ ur
große lineare Gleichungssysteme
Steffen B¨ orm
Stand 25. September 2020
Alle Rechte beim Autor.
1 Einleitung 5
1.1 Direkte L¨ oser f¨ ur schwachbesetzte Matrizen . . . . 6
1.2 Iterationsverfahren . . . . 10
1.3 Semiiterative Verfahren . . . . 12
1.4 Eindimensionales Modellproblem . . . . 14
1.5 Zweidimensionales Modellproblem . . . . 20
2 Lineare Iterationsverfahren 27
2.1 Allgemeine lineare Iterationsverfahren . . . . 27
2.2 Hinreichendes Konvergenzkriterium . . . . 29
2.3 Konvergenz und Spektralradius . . . . 34
2.4 Richardson-Iteration . . . . 41
2.5 Jacobi-Iteration . . . . 45
2.6 Diagonaldominante Matrizen . . . . 55
2.7 Gauß-Seidel-Iteration . . . . 59
2.8 SOR-Iteration . . . . 64
2.9 Kaczmarz-Iteration . . . . 71
3 Semiiterative und Krylow-Raum-Verfahren 75
3.1 Allgemeine lineare semiiterative Verfahren . . . . 75
3.2 Tschebyscheff-Semiiteration . . . . 78
3.3 Gradientenverfahren . . . . 88
3.4 Verfahren der konjugierten Gradienten . . . . 96
3.5 Krylow-Verfahren f¨ ur nicht positiv definite Matrizen . . . . 109
3.6 Verfahren f¨ ur Sattelpunktprobleme . . . . 130
4 Mehrgitterverfahren 135
4.1 Motivation: Zweigitterverfahren . . . . 135
4.2 Mehrgitterverfahren . . . . 147
4.3 Konvergenzbeweis per Fourier-Analyse . . . . 152
4.4 Konvergenz des W-Zyklus-Mehrgitterverfahrens . . . . 156
4.5 Gl¨ attungs- und Approximationseigenschaft bei Finite-Elemente-Verfahren 163 4.6 Symmetrische Mehrgitterverfahren . . . . 172
4.7 Allgemeine Unterraumverfahren . . . . 179
Index 191
Im Mittelpunkt dieser Vorlesung stehen Verfahren zur effizienten Behandlung großer linearer Gleichungssysteme der Form
Ax = b f¨ ur A = (a
ij)
i,j∈I∈
RI×I, x = (x
i)
i∈I, b = (b
i)
i∈I∈
RI(1.1) mit einer n-elementigen allgemeinen Indexmenge I.
Wir haben bereits Algorithmen kennengelernt, mit denen sich derartige Probleme l¨ osen lassen, etwa die Gauß-Elimination (bzw. LR-Faktorisierung), die Cholesky-Faktorisie- rung (f¨ ur symmetrische positiv definite Matrizen) oder die Householder-Zerlegung (bzw.
QR-Faktorisierung). Im allgemeinen Fall w¨ achst der Rechenaufwand dieser Verfahren kubisch in n, also f¨ uhrt eine Verdopplung der Problemdimension zu einer Verachtfa- chung des Rechenaufwands. Der Speicherbedarf w¨ achst quadratisch, eine Verdopplung der Dimension bedeutet also eine Vervierfachung des Speicherbedarfs.
Deshalb lassen sich diese Verfahren nur dann auf große Probleme anwenden, wenn sehr schnelle Rechner (heutzutage in der Regel Parallelrechner, da sich die Leistung einzelner Prozessoren nicht beliebig steigern l¨ asst) mit sehr hoher Speicherkapazit¨ at zur Verf¨ ugung stehen.
Wenn wir ein großes lineares Gleichungssystem l¨ osen wollen, ohne den Gegenwert mehrerer Einfamilienh¨ auser in modernste Rechnertechnik zu investieren, m¨ ussen wir uns also nach alternativen Verfahren umsehen. Dieses Kapitel stellt eine Reihe erfolgreicher Verfahren kurz dar, die detaillierte Behandlung der Algorithmen und die Analyse ihrer Vor- und Nachteile ist sp¨ ateren Kapiteln vorbehalten.
Dieses Skript orientiert sich eng an dem Buch
” Iterative L¨ osung großer schwachbesetz- ter Gleichungssysteme“ von Wolfgang Hackbusch, erschienen 1993 im Teubner-Verlag.
Dieses Buch bietet wesentlich mehr als den hier gegebenen ¨ Uberblick und ist jedem an ite- rativen Verfahren Interessierten w¨ armstens zu empfehlen. Eine erweiterte Version dieses Buchs ist unter der Web-Adresse
http://www.mis.mpg.de/scicomp/Fulltext/ggl.pszu finden.
Danksagung.
Ich bedanke mich bei Knut Reimer, Christoph Gerken, Jonas Grams,
Jelle Kuiper und Franziska Schwarzenbach f¨ ur Verbesserungsvorschl¨ age und Korrektu-
ren.
1.1 Direkte L¨ oser f¨ ur schwachbesetzte Matrizen
Falls die meisten Eintr¨ age von A gleich Null sind, lassen sich die klassischen L¨ osungsver- fahren so modifizieren, dass sie effizienter arbeiten. In diesem Abschnitt sei I = [1 : n]
Definition 1.1 (Dreiecksmatrizen) Eine Matrix L ∈
Kn×nnennen wir eine linke untere Dreiecksmatrix, falls
`
ij= 0 f¨ ur alle i, j ∈ [1 : n] mit i < j gilt, falls also alle Eintr¨ age oberhalb der Diagonalen gleich null sind.
Eine Matrix R ∈
Kn×nnennen wir eine rechte obere Dreiecksmatrix, falls r
ij= 0 f¨ ur alle i, j ∈ [1 : n] mit i > j gilt, falls also alle Eintr¨ age unterhalb der Diagonalen gleich null sind.
Wir nennen (L, R) eine LR-Zerlegung einer Matrix A ∈
Kn×n, falls L ∈
Kn×neine linke untere und R ∈
Kn×neine rechte obere Dreiecksmatrix ist und A = LR gilt.
Satz 1.2 (Skyline-Struktur) Sei A ∈
Kn×ninvertierbar, und sei (L, R) eine LR- Zerlegung der Matrix A. Dann gelten
(∀k ∈ [1 : j] : a
ik= 0) ⇒ `
ij= 0 f¨ ur alle i, j ∈ [1 : n] mit i > j, (∀k ∈ [1 : i] : a
kj= 0) ⇒ r
ij= 0 f¨ ur alle i, j ∈ [1 : n] mit i < j.
Falls also am Anfang einer Zeile der Matrix A Nulleintr¨ age auftreten, bleiben sie auch in der Matrix L erhalten. Falls am Anfang einer Spalte der Matrix A Nulleintr¨ age auftreten, bleiben sie auch in der Matrix R erhalten.
Beweis. Wir f¨ uhren den Beweis per Induktion ¨ uber n ∈
N. Induktionsanfang: F¨ ur n = 1 ist nichts zu zeigen.
Induktionsvoraussetzung: Sei n ∈
Nso gegeben, dass die Behauptung f¨ ur alle Matrizen A ∈
Kn×ngilt.
Induktionsschritt: Sei A ∈
K(n+1)×(n+1)eine Matrix, und sei (L, R) eine LR-Zerlegung dieser Matrix.
Wir zerlegen die Matrizen in A =
A
∗∗A
∗,n+1A
n+1,∗a
n+1,n+1
, A
∗∗∈
Kn×n, A
∗,n+1∈
Kn×1, A
n+1,∗∈
K1×n, L =
L
∗∗L
n+1,∗`
n+1,n+1, L
∗∗∈
Kn×n, L
n+1,∗∈
K1×n, R =
R
∗∗R
∗,n+1r
n+1,n+1
, R
∗∗∈
Kn×n, R
∗,n+1∈
Kn×1, und stellen fest, dass
A
∗∗A
∗,n+1A
n+1,∗a
n+1,n+1= A = LR =
L
∗∗L
n+1,∗`
n+1,n+1R
∗∗R
∗,n+1r
n+1,n+1=
L
∗∗R
∗∗L
∗∗R
∗,n+1L
n+1,∗R
∗∗L
n+1,∗R
∗,n+1+ `
n+1,n+1r
n+1,n+1gilt, also insbesondere
A
∗∗= L
∗∗R
∗∗, A
∗,n+1= L
∗∗R
∗,n+1, A
n+1,∗= L
n+1,∗R
∗∗.
Da A invertierbar ist, m¨ ussen auch L und R invertierbar sein. Da die beiden letztge- nannten Dreiecksmatrizen sind, folgt, dass auch L
∗∗und R
∗∗invertierbar sind.
Seien nun i, j ∈ [1 : n + 1] mit i > j so gegeben, dass a
ik= 0 f¨ ur alle k ∈ [1 : j] gilt.
Falls i ≤ n gilt, folgt `
ij= 0 mit der Induktionsvoraussetzung, da (L
∗∗, R
∗∗) eine LR- Zerlegung der Matrix A
∗∗ist. Wir brauchen also nur den Fall i = n + 1 zu betrachten.
Aus unserer Voraussetzung folgt, dass A
n+1,∗dann die Form A
n+1,∗= 0 A
n+1,+mit A
n+1,+∈
K1×(n−j)aufweist. Mit der Zerlegung
R
∗∗=
R
00R
0+R
++
, R
00∈
Kj×j, R
0+∈
Kj×(n−j), R
++∈
K(n−j)×(n−j), L
n+1,∗= L
n+1,0L
n+1,+, L
n+1,0∈
K1×j, L
n+1,+∈
K1×(n−j)folgt aus
0 A
n+1,+= A
n+1,∗= L
n+1,∗R
∗∗= L
n+1,0L
n+1,+R
00R
0+R
++
unmittelbar 0 = L
n+1,0R
00. Da R
00als Diagonalblock einer invertierbaren Dreiecksma- trix selbst invertierbar ist, folgen L
n+1,0= 0 und damit insbesondere `
ij= 0.
F¨ ur den Nachweis zweite Aussage seien i, j ∈ [1 : n + 1] mit i < j so gegeben, dass a
kj= 0 f¨ ur alle k ∈ [1 : i] gilt. Falls j ≤ n gilt, folgt `
ij= 0 wie zuvor mit der Induktionsvoraussetzung. Wir betrachten den Fall j = n + 1. Es gilt
A
∗,n+1=
0
A
+,n+1
mit A
+,n+1∈
K(n−i)×1, und mit der Zerlegung
L
∗∗= L
00L
+0L
++
, L
00∈
Ki×i, L
+0∈
K(n−i)×i, L
++∈
K(n−i)×(n−i), R
∗,n+1=
R
0,n+1R
+,n+1
R
0,n+1∈
Ki×1, R
+,n+1∈
K(n−i)×1folgt aus
0 A
+,n+1
= A
∗,n+1= L
∗∗R
∗,n+1= L
00L
+0L
++R
0,n+1R
+,n+1
unmittelbar 0 = L
00R
0,n+1. Da L
00als Diagonalblock einer invertierbaren Dreiecksma-
trix selbst invertierbar ist, haben wir R
0,n+1= 0, also insbesondere r
ij= 0.
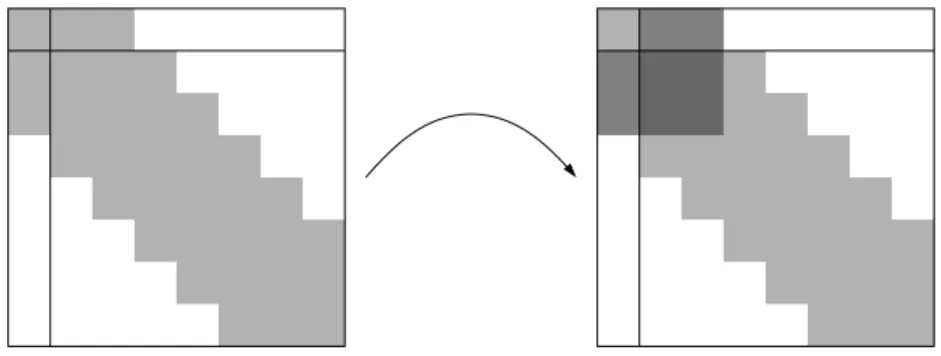
Abbildung 1.1: Konstruktion der Matrix S f¨ ur Bandmatrizen Definition 1.3 (Bandbreite) Sei p ∈
N0. Falls
|i − j| > p ⇒ a
ij= 0 f¨ ur alle i, j ∈ I
gilt, nennen wir p eine Bandbreitenschranke f¨ ur A. Die kleinste Bandbreitenschranke nennen wir die Bandbreite von A.
Falls die Matrix A eine durch p beschr¨ ankte Bandbreite besitzt, gilt dasselbe auch f¨ ur die Faktoren L, R ∈
RI×Ider LR-Zerlegung:
Satz 1.4 (Bandbreitenschranke f¨ ur die LR-Zerlegung) Sei A ∈
Kn×ninvertier- bar, und sei (L, R) eine LR-Zerlegung dieser Matrix.
Sei p ∈
Neine Bandbreitenschranke f¨ ur A. Dann ist p auch eine Bandbreitenschranke f¨ ur die Matrizen L und R.
Beweis. Seien i, j ∈ [1 : n] mit |i − j| > p gegeben.
Falls i < j gilt, folgt `
ij= 0 per Definition. Anderenfalls haben wir i − j > p, also f¨ ur alle k ∈ [1 : j] auch i − k ≥ i − j > p und damit a
ik= 0. Mit Satz 1.2 folgt `
ij= 0.
Falls i > j gilt, folgt r
ij= 0 per Definition. Anderenfalls haben wir j − i > p, also f¨ ur alle k ∈ [1 : i] auch j − k ≥ j − i > p und damit a
kj= 0. Mit Satz 1.2 folgt r
ij= 0.
F¨ ur die praktische Konstruktion der LR-Zerlegung empfiehlt sich eine ¨ ahnliche Vor- gehensweise wie im Beweis des Satzes 1.2: Statt die letzte Zeile und Spalte separat zu behandeln, nehmen wir die erste, wir betrachten also
A =
a
11A
1∗A
∗1A
∗∗
, A
∗∗∈
K(n−1)×(n−1), A
1∗∈
K1×(n−1), A
∗1∈
K(n−1)×1und erhalten bei entsprechender Zerlegung der Faktoren L und R die Gleichung
a
11A
1∗A
∗1A
∗∗
= A = LR = `
11L
∗1L
∗∗r
11R
1∗R
∗∗
=
`
11r
11`
11R
1∗L
∗1r
11L
∗1R
1∗+ L
∗∗R
∗∗
, aus der sich die Gleichungen
a
11= `
11r
11, A
1∗= `
11R
1∗, A
∗1= L
∗1r
11, A
∗∗− L
∗1R
1∗= L
∗∗R
∗∗procedure LRZerlegung(n, p, var A, L, R);
for m := 1 to n do l
mm← 1;
r
mm← a
mm;
for i ∈ [m + 1 : min{m + p, n}] do l
im← a
im/r
mm;
r
mi← a
miend for;
for i, j ∈ [m + 1 : min{m + p, n}] do a
ij← a
ij− l
imr
mjend for end for
Abbildung 1.2: Berechnung der LR-Zerlegung
ergeben. Mit den ersten drei Gleichungen k¨ onnen wir `
11, r
11, R
1∗und L
∗1bestimmen.
Die vierte erlaubt es uns dann, L
∗∗und R
∗∗mit einer LR-Zerlegung der Dimension n −1 zu berechnen. Indem wir die Bandstruktur ausnutzen, sind f¨ ur die Berechnung der linken Seite S := A
∗∗− L
∗1R
1∗der vierten Gleichung h¨ ochstens p
2Operationen erforderlich, wenn wir A
∗∗mit S uberschreiben. Der resultierende Algorithmus ist in Abbildung 1.2 ¨ gegeben. Da wir nur an dem Fall n p interessiert sind, k¨ onnen wir uns die Analyse seiner algorithmischen Komplexit¨ at leicht machen:
Satz 1.5 (Komplexit¨ at der LR-Zerlegung) Der in Abbildung 1.2 gegebene Algo- rithmus ben¨ otigt nicht mehr als np Divisionen, np
2Multiplikationen und np
2Subtrak- tionen.
Beweis. F¨ ur ein m f¨ uhrt die erste innere Schleife des Algorithmus h¨ ochstens p Divisionen durch, da i nur Werte zwischen m + 1 und m + p annehmen kann.
In der zweiten inneren Schleife k¨ onnen i und j jeweils nur Werte zwischen m + 1 und m +p annehmen, also wird diese Schleife h¨ ochstens p
2-mal durchlaufen, so dass h¨ ochstens p
2Multiplikationen und Subtraktionen durchzuf¨ uhren sind.
Da die ¨ außere Schleife genau n-mal durchlaufen wird, erhalten wir direkt das gew¨ unschte Ergebnis.
Wir k¨ onnen sehen, dass diese Komplexit¨ atsabsch¨ atzung wesentlich g¨ unstiger als im allgemeinen Fall ist: Falls die Bandbreite von A unabh¨ angig von n beschr¨ ankt ist, k¨ onnen wir die LR-Zerlegung mit einem Aufwand berechnen, der lediglich linear in n w¨ achst.
Sobald die LR-Zerlegung zur Verf¨ ugung steht, k¨ onnen wir das Gleichungssystem b = Ax = LRx durch R¨ uckw¨ artseinsetzen in R und Vorw¨ artseinsetzen in L l¨ osen. Da die Bandbreiten von L und R durch p beschr¨ ankt sind, k¨ onnen diese Berechnungen in O(np) Operationen durchgef¨ uhrt werden, wir erhalten also wieder eine lineare Komplexit¨ at in der Problemdimension n.
Indem wir die besonderen Eigenschaften der Matrix A ausnutzen, k¨ onnen wir so eine
wesentlich h¨ ohere Effizienz erreichen.
Abbildung 1.3: Auff¨ ullen der Matrix A
Leider ist die Bandbreite vieler in der Praxis auftretender Matrizen nicht beschr¨ ankt.
Es tritt zwar h¨ aufig der Fall auf, dass nur wenige Eintr¨ age der Matrix von Null ver- schieden sind, aber diese Eigenschaft alleine gen¨ ugt nicht, um ¨ ahnliche Aussagen wie in Satz 1.5 zu zeigen.
Ein Beispiel ist in Abbildung 1.3 zu sehen: Obwohl in der Ausgangsmatrix nur jeweils h¨ ochstens vier Eintr¨ age pro Zeile von Null verschieden sind, f¨ ullen die einzelnen Berech- nungsschritte die Matrix A immer weiter auf, bis schließlich die volle Bandbreite von 4 erreicht ist, wir erhalten die von Satz 1.2 vorhergesagte Struktur. In der Praxis treten h¨ aufig Matrizen mit einer Bandbreite von n
1/2auf, hier w¨ urde unser Algorithmus also O(n
2) Operationen und O(n
3/2) Speicherpl¨ atze ben¨ otigen, selbst wenn die Ausgangs- matrizen fast nur aus Nulleintr¨ agen bestehen.
1.2 Iterationsverfahren
Wir haben gesehen, dass bei Matrizen, die zwar nur wenige von Null verschiedene Ein- tr¨ age, aber trotzdem eine hohe Bandbreite aufweisen, Algorithmen wie die LR-Zerlegung ineffizient werden, weil sich die Matrix nach und nach auff¨ ullt, also Nulleintr¨ age durch die einzelnen Berechnungsschritte ¨ uberschrieben werden.
Es w¨ are also sehr w¨ unschenswert, ein Verfahren zu kennen, das die Matrix ¨ uberhaupt nicht ver¨ andert und insbesondere auch keine Nulleintr¨ age ¨ uberschreibt.
Dieses Ziel erreichen die meisten iterativen L¨ osungsverfahren. Diese Algorithmen be- rechnen eine Folge x
(0), x
(1), . . . von Vektoren, ausgehend von einem beliebigen Startvek- tor x
(0)∈
RI, die gegen die gew¨ unschte L¨ osung x konvergieren. Im Gegensatz zu LR-, QR- oder Cholesky-Zerlegungen erhalten wir von diesen Verfahren also keine
” exakte“
L¨ osung, sondern lediglich eine approximative L¨ osung, die allerdings beliebig genau ist.
Dieser scheinbare Nachteil wird durch zwei Beobachtungen relativiert: Erstens ist man
bei den meisten Anwendungen ohnehin nicht an einer exakten L¨ osung interessiert, weil
die Ausgangsdaten in der Regel schon gest¨ ort sind, etwa durch Rundungsfehler. Zwei-
tens ist es leichter, bei iterativen Verfahren die Fehlerfortpflanzung zu kontrollieren, weil
in jedem Schritt lediglich die Ausgangsdaten und die aktuelle Approximation eingehen,
aber nicht die vorangehenden Approximationen. Aus diesem Grund werden in der Pra-
xis gelegentlich iterative Verfahren eingesetzt, um die Rundungsfehler zu kompensieren,
die bei einer LR- oder QR-Zerlegung auftreten k¨ onnen (dann spricht man von einer
” Nachiteration“).
Ein sehr einfaches Iterationsverfahren ist die Richardson-Iteration, bei der die Folge der Vektoren durch die Vorschrift
x
(m+1):= x
(m)− θ(Ax
(m)− b) f¨ ur alle m ∈
N0gegeben ist. Hierbei ist θ ∈
Cein geeignet zu w¨ ahlender Parameter, der offensichtlich entscheidenden Einfluss auf das Verhalten des Verfahrens hat, beispielsweise bewirkt das Verfahren in komplizierter Weise nichts, wenn wir θ = 0 setzen.
Bereits bei diesem sehr einfachen Beispiel k¨ onnen wir die Vorteile eines iterativen Ver- fahrens erkennen: Neben der Matrix A, dem Vektor b und dem L¨ osungsvektor x (in dem wir die einzelnen Iterierten x
(m)unterbringen) ist lediglich ein Hilfsvektor erforderlich, in dem wir den sogenannten
” Defekt“ d
(m):= Ax
(m)−b speichern, wir kommen also mit relativ wenig Speicher aus. Die Matrix A tritt ausschließlich in Form der Matrix-Vektor- Multiplikation Ax
(m)auf, insbesondere m¨ ussen wir ihre Eintr¨ age nicht ver¨ andern und vor allem keine Nulleintr¨ age ¨ uberschreiben.
Die Durchf¨ uhrung eines Iterationsschritts, also die Berechnung von x
(m+1)aus x
(m), kann in den meisten Anwendungsf¨ allen sehr effizient gestaltet werden, sehr h¨ aufig sogar mit der optimalen Komplexit¨ at O(n).
Leider ist es mit der bloßen Durchf¨ uhrung des Verfahrens nicht getan, wir m¨ ussen auch wissen, wieviele Schritte erforderlich sind, um eine gewisse Genauigkeit zu erzielen, und ob das Verfahren f¨ ur ein bestimmtes Problem ¨ uberhaupt konvergiert. Die Untersuchung der Konvergenz iterativer Verfahren kann sich beliebig kompliziert gestalten, und der Entwurf eines geeigneten Verfahrens f¨ ur eine bestimmte Problemklasse kann auch auf dem heutigen Stand der Forschung noch eine große wissenschaftliche Herausforderung darstellen.
Im Falle des Richardson-Verfahrens l¨ asst sich die Frage nach der Konvergenz relativ einfach beantworten: Das Verfahren konvergiert (f¨ ur ein geeignetes θ), falls alle Eigen- werte der Matrix A in derselben H¨ alfte der komplexen Ebene liegen, falls es also ein z ∈
Cgibt, das Re(zλ) > 0 f¨ ur alle Eigenwerte λ von A erf¨ ullt.
Wir werden diese Aussage sp¨ ater beweisen, im Augenblick gen¨ ugt es, zwei Beispiele zu untersuchen. Das erste Beispiel ist das durch
A :=
1 0 0 2
, b :=
0 0
gegebene Gleichungssystem Ax = b. Offensichtlich besitzt es die eindeutige L¨ osung x = 0. Falls wir das Richardson-Verfahren auf einen beliebigen Startvektor x
(0)∈
R2anwenden, erhalten wir
x
(1)= (1 − θ)x
(0)1(1 − 2θ)x
(0)2!
, x
(2)= (1 − θ)
2x
(0)1(1 − 2θ)
2x
(0)2!
, x
(m)= (1 − θ)
mx
(0)1(1 − 2θ)
mx
(0)2!
, es folgt somit
kx
(m)k
2≤ max{|1 − θ|
m, |1 − 2θ|
m}kx
(0)k
2f¨ ur alle m ∈
N0,
wir erhalten also Konvergenz f¨ ur alle θ ∈ (0, 1), und die optimale Wahl θ = 2/3 f¨ uhrt zu kx
(m)k
2≤
1 3
m
kx
(0)k
2f¨ ur alle m ∈
N0,
also reduziert jeder Schritt des Verfahrens den Fehler um den Faktor % := 1/3. Diese Konvergenzrate h¨ angt nicht von der Gr¨ oße des Gleichungssystems ab, sondern lediglich von dessen Eigenwerten.
Das zweite Beispiel ist das durch A :=
1 0 0 −1
, b :=
0 0
(1.2) gegebene Gleichungssystem Ax = b. Offensichtlich besitzt es ebenfalls die eindeutige L¨ osung x = 0. Falls wir das Richardson-Verfahren auf einen Startvektor x
(0)anwenden, erhalten wir diesmal
x
(1)= (1 − θ)x
(0)1(1 + θ)x
(0)2!
, x
(2)= (1 − θ)
2x
(0)1(1 + θ)
2x
(0)2!
, x
(m)= (1 − θ)
mx
(0)1(1 + θ)
mx
(0)2!
. Falls x
(0)16= 0 6= x
(0)2gilt, erhalten wir, dass die Folge der Vektoren niemals gegen die korrekte L¨ osung konvergieren wird, weil
max{|1 − θ|, |1 + θ|} =
p1 + |θ|
2+ 2| Re θ| ≥ 1 gilt. Im schlimmsten Fall, f¨ ur θ 6= 0, wird die Folge sogar divergieren.
Wir k¨ onnen also feststellen, dass die Konvergenz eines iterativen Verfahrens entschei- dend von den Eigenschaften der Matrix A abh¨ angt. Wenn das Verfahren zur Matrix passt, k¨ onnen iterative Verfahren sehr effizient sein, beispielsweise gibt es f¨ ur einige wichtige Klassen von Gleichungssystemen iterative Verfahren, die auch mehrere Millio- nen Unbekannte in wenigen Sekunden berechnen.
1.3 Semiiterative Verfahren
Eine Kombination aus direkten und iterativen Verfahren stellen die sogenannten se- miiterativen Verfahren dar. Diese Algorithmen bestimmen die L¨ osung in einer festen Anzahl von Schritten (¨ ublicherweise n), berechnen dabei aber Zwischenergebnisse, die auch schon gute Approximationen darstellen.
Ein großer Vorteil der Richardson-Iteration besteht darin, dass sie durchgef¨ uhrt wer- den kann, sobald wir eine M¨ oglichkeit besitzen, Matrix-Vektor-Produkte y := Ax zu berechnen. Wir wollen nun ein Verfahren skizzieren, das ebenfalls ausschließlich mit derartigen Produkten auskommt.
Nach dem Satz von Cayley-Hamilton gibt es mindestens ein Polynom π mit einem Grad von h¨ ochstens n derart, dass
π(A) = 0
gilt. Wir w¨ ahlen ein Polynom minimalen Grades p, das diese Gleichung erf¨ ullt, und bezeichnen seine Koeffizienten mit π
0, . . . , π
p∈
R, so dass die Gleichung die Gestaltπ
pA
p+ π
p−1A
p−1+ . . . + π
1A + π
0I = 0
annimmt. Da π minimalen Grad besitzt, muss π
06= 0 gelten (sonst k¨ onnten wir ein Polynom niedrigeren Grades konstruieren, indem wir die obige Gleichung mit A
−1mul- tiplizieren), und wir erhalten
− π
pπ
0
A
p+
− π
p−1π
0
A
p−1+ . . . +
− π
1π
0
A = I.
Nun k¨ onnen wir A entweder nach links oder rechts aus der Summe herausziehen und gelangen zu der Gleichung
− π
pπ
0
A
p−1+
− π
p−1π
0
A
p−2+ . . . +
− π
1π
0
I
A = I, sowie ihrem Gegenst¨ uck
A
− π
pπ
0A
p−1+
− π
p−1π
0A
p−2+ . . . +
− π
1π
0I
= I.
Beide zusammen implizieren
− π
pπ
0
A
p−1+
− π
p−1π
0A
p−2+ . . . +
− π
1π
0
I = A
−1. Wir haben also die Inverse von A durch ein Polynom dargestellt.
F¨ ur unsere Aufgabe, also das L¨ osen des Gleichungssystems Ax = b, bedeutet diese Gleichung, dass wir x = A
−1b in der Form
x =
− π
pπ
0
A
p−1b +
− π
p−1π
0A
p−2b + . . . +
− π
1π
0
b darstellen k¨ onnen, wir brauchen also lediglich die Vektoren
y
(0):= b, y
(1):= Ay
(0)= Ab, y
(2):= Ay
(1)= A
2b, y
(m):= Ay
(m−1)= A
mb zu berechnen und wissen, dass
x = α
p−1y
(p−1)+ α
p−2y
(p−2)+ . . . + α
0y
(0)mit den Koeffizienten α
i:= −π
i+1/π
0gilt.
In der Praxis steht uns das Polynom π nicht zur Verf¨ ugung, wir m¨ ussen also das richtige p und die richtigen Koeffizienten α
ianders konstruieren. Krylow-Verfahren gehen dabei so vor, dass der Reihe nach die Vektoren y
(m)berechnet und dann die L¨ osung im zugeh¨ origen Krylow-Raum
K(b, m) := span{y
(0), . . . , y
(m)} = span{b, . . . , A
mb}
gesucht wird. Die Suche nach der L¨ osung l¨ asst sich als lineares Ausgleichsproblem for- mulieren: Wir suchen Koeffizienten α
0, . . . , α
m∈
Rderart, dass der Fehler
m:= kx − α
my
(m)− . . . − α
0y
(0)k
in einer geeigneten Norm (schließlich steht uns x nicht zur Verf¨ ugung) minimiert wird.
Dieses lineare Ausgleichsproblem kann effizient gel¨ ost werden, sofern m nicht zu groß ist.
Wir k¨ onnen diesen Prozess so lange wiederholen, wie die Vektoren y
(m)linear un- abh¨ angig sind. Wenn sie f¨ ur ein m nicht mehr linear unabh¨ angig sein sollten, kann man zeigen, dass
m= 0 gelten muss, dass wir also unsere L¨ osung bereits gefunden haben.
Da die Krylow-R¨ aume geschachtelt sind (es gilt offensichtlich K(b, m) ⊆ K(b, m + 1)), muss auch
m≥
m+1gelten, und aus dem Satz von Cayley-Hamilton folgt
n−1= 0.
Das Krylow-Verfahren berechnet also eine Folge von Vektoren, die monoton gegen die L¨ osung x konvergiert und nach sp¨ atestens n − 1 Schritten die exakte L¨ osung erreicht.
1.4 Eindimensionales Modellproblem
Wie wir gesehen haben, spielen f¨ ur die verschiedenen skizzierten Verfahren verschiede- ne Eigenschaften des Gleichungssystems eine Rolle: Bei Band-LR-Zerlegungen ist die Bandbreite der Matrix von entscheidender Bedeutung, bei der Richardson-Iteration sind es die Eigenwerte, und auch die Analyse von Krylow-Verfahren l¨ asst sich, zumindest in wichtigen Spezialf¨ allen, auf die Analyse der Eigenwerte zur¨ uckf¨ uhren.
Deshalb ist es sinnvoll, zum Vergleich verschiedener Verfahren einfache Modellproble- me heranzuziehen, bei denen sich die n¨ otigen Eigenschaften leicht nachweisen lassen. Wir beschr¨ anken uns hier auf lineare Gleichungssysteme, die aus der Diskretisierung einer partiellen Differentialgleichung entstehen, denn dieser Ansatz hat den Vorteil, dass wir Matrizen beliebiger Gr¨ oße mit geringem Aufwand aufstellen k¨ onnen und dass sie viele Eigenschaften aufweisen, die auch praktisch auftretende Probleme besitzen.
Zun¨ achst betrachten wir die eindimensionale partielle Differentialgleichung
−u
00(x) = f (x) f¨ ur alle x ∈ Ω := (0, 1), (1.3a)
u(0) = u(1) = 0, (1.3b)
f¨ ur eine Funktion u ∈ C[0, 1] mit u|
(0,1)∈ C
2(0, 1) und eine Funktion f ∈ C(0, 1).
Da das Intervall [0, 1] unendlich viele Punkte enth¨ alt, k¨ onnen wir die L¨ osung u in einem Computer mit endlichem Speicher nicht exakt darstellen, m¨ ussen sie also approximieren.
Zu diesem Zweck w¨ ahlen wir ein N ∈
Nund unterteilen das Intervall [0, 1] in N + 1 Teilintervalle der L¨ ange h := 1/(N + 1). Die Anfangs- und Endpunkte der Intervalle sind durch
ξ
i:= hi f¨ ur alle i ∈ {0, . . . , N + 1}
gegeben, und es gilt 0 = ξ
0< ξ
1< . . . < ξ
N< ξ
N+1= 1. Unser Ziel ist es nun, die Werte der Funktion in diesen Punkten zu bestimmen, also
u
i:= u(ξ
i) f¨ ur alle i ∈ {0, . . . , N + 1}
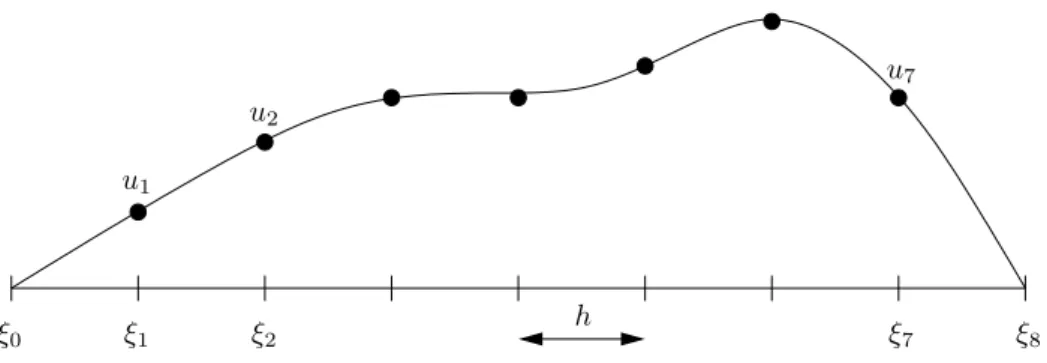
ξ0 ξ1 ξ2 ξ7 ξ8 u1
u2
u7
h
Abbildung 1.4: Eindimensionales Modellproblem
zu berechnen. Wegen u
0= u(0) = 0 und u
N+1= u(1) = 0 sind nur die Werte u
1, . . . , u
N∈
Rzu bestimmen, also der Vektor u = (u
i)
i∈If¨ ur I := {1, . . . , N}.
Da uns die wahre L¨ osung u nicht zur Verf¨ ugung steht, m¨ ussen wir versuchen, ihre Ableitung u
00zu approximieren, indem wir nur die Werte u
1, . . . , u
Nverwenden. Wir nehmen an, dass u ∈ C
4[0, 1] gilt und wenden die Taylor-Entwicklung an, um die Glei- chungen
u(x + h) = u(x) + hu
0(x) + h
22 u
00(x) + h
36 u
(3)(x) + h
424 u
(4)(η
+), u(x − h) = u(x) − hu
0(x) + h
22 u
00(x) − h
36 u
(3)(x) + h
424 u
(4)(η
−)
f¨ ur geeignete η
+∈ [x, x + h] und η
−∈ [x − h, x] zu erhalten. Wir addieren beide Glei- chungen und finden
u(x + h) + u(x − h) = 2u(x) + h
2u
00(x) + h
424 u
(4)(η
+) + h
424 u
(4)(η
−).
Wir sortieren die Terme um und stellen fest, dass
u
00(x) − 1
h
2(u(x − h) − 2u(x) + u(x + h))
≤ h
212 ku
(4)k
∞,[x−h,x+h](1.4) gilt, also k¨ onnen wir
1
h
2(u(x − h) − 2u(x) + u(x + h)) ≈ u
00(x) (1.5) als Endergebnis festhalten. Angewendet auf die Punkte ξ
1, . . . , ξ
Nbedeutet diese Glei- chung
1
h
2(u
i−1− 2u
i+ u
i+1) ≈ u
00(ξ
i).
Um die Verbindung zur Differentialgleichung (1.3) herzustellen, f¨ uhren wir den Vektor f = (f
i)
i∈Imit
f
i= f (ξ
i) f¨ ur alle i ∈ I
ein und erhalten wegen f
i= −u
00(ξ
i) die diskrete Approximation 1
h
2(−u
i−1+ 2u
i− u
i+1) = f
if¨ ur alle i ∈ I
der Differentialgleichung (1.3). Wie wir sehen, handelt es sich dabei um ein lineares Gleichungssystem
1 h
2
2 −1
−1 2 −1 . .. ... ...
−1 2 −1
−1 2
u
1u
2.. . u
N−1u
N
=
f
1f
2.. . f
N−1f
N
,
das mit Hilfe der durch
L
ij=
2h
−2falls i = j,
−h
−2falls |i − j| = 1,
0 sonst
f¨ ur alle i, j ∈ I
und L = (L
ij)
i,j∈Igegebenen Matrix in der kompakten Form Lu = f
dargestellt werden kann. An der Definition von L kann man leicht ablesen, dass diese Matrix eine Bandbreite von 1 besitzt, also l¨ asst sich das Gleichungssystem mit den in Abschnitt 1.1 eingef¨ uhrten Verfahren sehr effizient l¨ osen.
Die Fehlerabsch¨ atzung (1.4) legt uns nahe, dass wir nur dann auf eine gute Genauigkeit hoffen d¨ urfen, wenn h klein ist. Wegen h = 1/(N +1) k¨ onnen wir dieses Ziel nur erreichen, indem wir die Anzahl N der Unbekannten relativ groß w¨ ahlen.
F¨ ur die Untersuchung des Richardson-Verfahrens ben¨ otigen wir die Eigenwerte der Matrix L, die sich mit Hilfe von etwas trigonometrischer Arithmetik bestimmen lassen.
Lemma 1.6 (Trigonometrische Orthogonalbasis) Sei N ∈
Nund h := 1/(N + 1).
Es gilt
N
X
j=1
sin(πjkh) sin(πj`h) =
(
(N + 1)/2 falls k = `,
0 ansonsten f¨ ur alle k, ` ∈ [1 : N ].
Beweis. Seien k, ` ∈ [1 : N ] gegeben. Mit der Eulerschen Gleichung gilt
N
X
j=1
sin(πjkh) sin(πj`h) =
N
X
j=1
e
iπjkh− e
−iπjkh2i
e
iπj`h− e
−iπj`h2i
= 1 4
N
X
j=1
e
iπj(k−`)h+ e
−iπj(k−`)h− e
iπj(k+`)h− e
−iπj(k+`)h,
und wegen k + ` ∈ [2 : 2N ] gilt (k + `)h ∈ (0, 2), also folgen q := e
iπ(k+`)h6= 1 und
N
X
j=1
e
iπj(k+`)h=
N
X
j=1
q
j= q
N+1− q
q − 1 = σ − q q − 1
f¨ ur σ := q
N+1= e
iπ(k+`)∈ {−1, 1}. In derselben Weise erhalten wir f¨ ur p := e
iπ(k−`)hdie Gleichung
N
X
j=1
e
iπj(k−`)h=
N
X
j=1
p
j=
(
N falls k = `,
σ−p
p−1
ansonsten,
da aus k + ` = (k − `) + 2` auch σ = e
iπ(k−`)= p
N+1folgt. F¨ ur k = ` haben wir σ = 1, also
N
X
j=1
sin(πjkh) sin(πj`h) = 1 4
2N − σ − q
q − 1 − σ − q q − 1
= N 2 − 1
2 Re (1 − q)(¯ q − 1)
|q − 1|
2= N 2 + 1
2 Re (q − 1)(¯ q − 1)
|q − 1|
2= N + 1 2 .
F¨ ur k 6= ` m¨ ussen wir die F¨ alle σ = 1 und σ = −1 unterscheiden. Im ersten Fall gilt
N
X
j=1
sin(πjkh) sin(πj`h) = 1 4
σ − p
p − 1 + σ − p
p − 1 − σ − q
q − 1 − σ − q q − 1
= 1 4 Re
1 − p
p − 1 − 1 − q q − 1
= 1
4 (−1 + 1) = 0, im zweiten Fall erhalten wir
N
X
j=1
sin(πjkh) sin(πj`h) = 1 4
σ − p
p − 1 + σ − p
p − 1 − σ − q
q − 1 − σ − q q − 1
= 1 4 Re
−1 − p
p − 1 − −1 − q q − 1
= 1 4 Re
(−1 − p)(¯ p − 1)
|p − 1|
2− (−1 − q)(¯ q − 1)
|q − 1|
2= 1 4 Re
1 − |p|
2− p ¯ + p
|p − 1|
2− 1 − |q|
2− q ¯ + q
|q − 1|
2= 1 4 Re
p − p ¯
|p − 1|
2− q − q ¯
|q − 1|
2= 0, und damit ist die gew¨ unschte Orthonormalit¨ atsbeziehung bewiesen.
Lemma 1.7 (Eigenwerte) F¨ ur alle k ∈ I definieren wir den Vektor e
k∈
RIdurch e
kj:= √
2h sin(πjkh) f¨ ur alle j ∈ I . Es gilt
Le
k= λ
ke
kmit λ
k:= 4h
−2sin
2(πkh/2) f¨ ur alle k ∈ I,
und die Vektoren erf¨ ullen he
k, e
`i
2=
(
1 falls k = `,
0 ansonsten f¨ ur k, ` ∈ I,
bilden also eine aus Eigenvektoren der Matrix L bestehende Orthonormalbasis von
RI. Beweis. Sei k ∈ I . Um nachzuweisen, dass e
kein Eigenvektor ist, betrachten wir f¨ ur einen Index j ∈ I die j-te Komponente von Le
k: Wegen sin(π0kh) = 0 = sin(π(N + 1)kh) erhalten wir
(Le
k)
j= h
−2(2e
kj− e
kj−1− e
kj+1)
= √
2hh
−2(2 sin(πjkh) − sin(π(j − 1)kh) − sin(π(j + 1)kh)).
Wir wenden das Additionstheorem sin(x + y) = sin(x) cos(y) + cos(x) sin(y) an:
(Le
k)
j=
√
2hh
−2(2 sin(πjkh) − sin(πjkh) cos(−πkh) − cos(πjkh) sin(−πkh)
− sin(πjkh) cos(πkh) − cos(πjkh) sin(πkh))
=
√
2hh
−2(2 − 2 cos(πkh)) sin(πjkh).
Nun benutzen wir das Additionstheorem cos(2x) = 2 cos
2(x) − 1:
(Le
k)
j=
√
2hh
−2(2 − 4 cos
2(πkh/2) + 2) sin(πjkh)
= 4 √
2hh
−2(1 − cos
2(πkh/2)) sin(πjkh)
= 4 √
2hh
−2sin
2(πkh/2) sin(πjkh)
= λ
ke
kj= (λ
ke
k)
j.
Da πkh/2 = πk/(2(N + 1)) ∈ (0, π/2) f¨ ur alle k ∈ I = {1, . . . , N} gilt und die Sinus- funktion auf diesem Intervall streng monoton w¨ achst, sind alle Eigenwerte verschieden, also m¨ ussen alle Eigenvektoren e
klinear unabh¨ angig sein.
Seien nun k, ` ∈ I. Mit Lemma 1.6 erhalten wir he
k, e
`i
2= 2h
N
X
j=1
sin(πjkh) sin(πj`h) = 2h
(
(N + 1)/2 falls k = `,
0 ansonsten
=
(
1 falls k = `, 0 ansonsten.
Untersuchen wir nun das Verhalten der Richardson-Iteration f¨ ur die Matrix L. Wir betrachten wieder das vereinfachte System Lu = 0, das die exakte L¨ osung u = 0 besitzt.
Den Startvektor u
(0)∈
RIstellen wir in der Eigenvektorbasis dar und erhalten u
(0)=
Xk∈I
α
ke
k,
so dass sich der Iterationsschritt
u
(1)= u
(0)− θLu
(0)in der Form
u
(1)=
Xk∈I
α
k(1 − θλ
k)e
k(1.6)
darstellen l¨ asst. F¨ ur die weiteren Iterierten erhalten wir die Darstellung u
(m)=
Xk∈I
α
k(1 − θλ
k)
me
kin der Eigenvektorbasis, also konvergiert die Iteration gegen die korrekte L¨ osung u = 0, falls
max{|1 − θλ
k| : k ∈ I} < 1 (1.7) gilt. Gl¨ ucklicherweise gen¨ ugt es, nur den gr¨ oßten und den kleinsten Eigenwert zu unter- suchen, also
λ
1= 4h
−2sin
2(πh/2), λ
N= 4h
−2sin
2(πN h/2) = 4h
−2cos
2(πh/2).
Wenn wir max{|1 − θλ
1|, |1 − θλ
N|} < 1 bewiesen haben, gilt auch die Bedingung (1.7).
Wir w¨ ahlen θ so, dass diese Gr¨ oße minimiert wird, n¨ amlich als L¨ osung von 1 − θ
optλ
1= θ
optλ
N− 1.
Diese L¨ osung ist durch
θ
opt:= 2 λ
N+ λ
1= 2
4h
−2= h
22 gegeben und f¨ uhrt zu der Schranke
max{|1 − θ
optλ
k| : k ∈ I} = % := 1 − θ
optλ
1= 1 − 2λ
1λ
N+ λ
1= λ
N− λ
1λ
N+ λ
1< 1.
Mit dieser Schranke und der Dreiecksungleichung erhalten wir ku
(m)k ≤ %
mXk∈I
kα
ke
kk f¨ ur jede beliebige Norm. F¨ ur die euklidische Norm gilt sogar
ku
(m)k
2≤ %
mku
(0)k
2,
da wir bereits nachgewiesen haben, dass die Eigenvektoren senkrecht zueinander stehen.
Die Richardson-Iteration konvergiert also. Leider konvergiert sie nicht sehr schnell: Wir haben
% = λ
max− λ
minλ
max+ λ
min= 4h
−2cos
2(πh/2) − 4h
−2sin
2(πh/2)
4h
−2(1.8)
= cos
2(πh/2) − sin
2(πh/2) = 1 − 2 sin
2(πh/2),
und f¨ ur h → 0, also N → ∞, bedeutet diese Gleichung % ≈ 1 − π
2h
2/2, die Konvergenz-
rate wird also schlechter, wenn die Problemdimension w¨ achst.
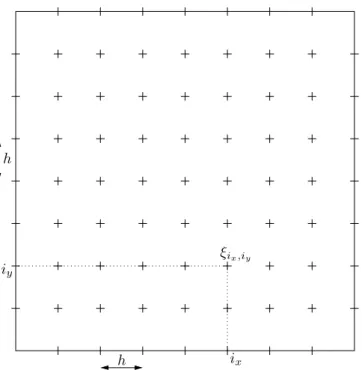
h h
iy
ix ξix,iy
Abbildung 1.5: Zweidimensionales Modellproblem f¨ ur N = 7
1.5 Zweidimensionales Modellproblem
W¨ ahrend das eindimensionale Modellproblem (und auch viele andere eindimensionale Probleme) zu Matrizen geringer Bandbreite f¨ uhrt und somit effizient mit der Band-LR- Zerlegung gehandhabt werden kann, wird die Situation wesentlich schwieriger, wenn wir zu einem zweidimensionalen Problem ¨ ubergehen: Wir untersuchen die partielle Differen- tialgleichung
−∆u(x) :=
− ∂
2∂x
21− ∂
2∂x
22u(x) = f(x) f¨ ur alle x ∈ Ω := (0, 1)
2, (1.9a) u(x) = 0 f¨ ur alle x ∈ ∂Ω = {0, 1} × [0, 1] (1.9b)
∪ [0, 1] × {0, 1}, f¨ ur eine Funktion u ∈ C(Ω) mit u|
Ω∈ C
2(Ω) und eine rechte Seite f ∈ C(Ω).
Diese Differentialgleichung ist das zweidimensionale Gegenst¨ uck zu der Gleichung (1.3). Wir diskretisieren sie, indem wir eine endliche Anzahl von Punkten in Ω fixieren und die zweite Ableitung mit Hilfe der Funktionswerte in diesen Punkten approximieren.
Die Punkte konstruieren wir ¨ ahnlich wie im eindimensionalen Fall: Wir fixieren N ∈
N, setzen h := 1/(N + 1) und w¨ ahlen
ξ
ix,iy:= (hi
x, hi
y) f¨ ur alle i
x, i
y∈ {0, . . . , N + 1}.
Infolge der Randbedingung sind nur die Werte
u
ix,iy:= u(ξ
ix,iy) f¨ ur alle i
x, i
y∈ {1, . . . , N}
zu bestimmen.
Zur Vereinfachung der Notation fassen wir i
xund i
yzu einem Multiindex i := (i
x, i
y) zusammen und bezeichnen die Menge aller dieser Multiindizes mit
I := {i = (i
x, i
y) : i
x, i
y∈ {1, . . . , N }}.
Die M¨ achtigkeit der neuen Indexmenge I betr¨ agt n := N
2, und mit ihrer Hilfe k¨ onnen wir die Notationen des eindimensionalen Problems weiterverwenden: ξ
i= (hi
x, hi
y), u
i= u(ξ
i) = u(hi
x, hi
y). Der Vektor der Werte von u schreibt sich als u = (u
i)
i∈I.
Um die Differentialgleichung (1.9) zu diskretisieren, ersetzen wir wieder die zweiten Ableitungen durch die Approximation (1.5) und erhalten
1 h
2
u
x
1− h x
2
− 2u x
1x
2+ u
x
1+ h x
2
≈ ∂
2∂x
21u x
1x
2, 1
h
2u
x
1x
2− h
− 2u x
1x
2+ u
x
1x
2+ h
≈ ∂
2∂x
22u x
1x
2f¨ ur alle x = x
1x
2∈ Ω.
Wie bereits im eindimensionalen Fall wenden wir diese Gleichungen auf die Punkte ξ
ian und erhalten
1
h
24u
i− u
i−(1,0)− u
i−(0,1)− u
i+(1,0)− u
i+(0,1)≈ −∆u(ξ
i) f¨ ur alle i ∈ I . Wir f¨ uhren wieder den Vektor f ∈
RImit
f
i= f(ξ
i) = f (hi
x, hi
y) f¨ ur alle i ∈ I ein und setzen −∆u(ξ
i) = f
i, um die diskrete Approximation
1
h
24u
i− u
i−(1,0)− u
i−(0,1)− u
i+(1,0)− u
i+(0,1)= f
if¨ ur alle i ∈ I der Differentialgleichung (1.9) zu erhalten.
Mit Hilfe der Matrix L = (L
ij)
i,j∈I, gegeben durch
L
ij=