Entwicklung und Validierung logistischer Prognosemodelle anhand vordefinierter
SAS-Makros
Development and validation of logistic prognostic models by predefined SAS-macros
• Rainer Muche1• Christina Ring1• Christoph Ziegler2
Prognosen zum Krankheitsverlauf oder zum Schweregrad multipler Schädigungen bestimmen die medizinischen Therapie- und Diagnostikentscheidungen direkt oder indirekt. Neben der subjektiven Einschätzung des Arztes können mathematische Modelle für Prognosezwecke entwickelt und validiert werden. Prognosemodelle werden vielfach als verallgemeinerte lineare Regressionsmodelle formuliert. In der Praxis ist die betrachtete Zielgröße häufig dichotom, so dass multiple logistische Regressionsmodelle zum Einsatz kommen. Im folgenden wird das Vorgehen der Entwicklung und Validierung anhand vordefinierter SAS-Makros beschrieben, die für eine Modellierung basierend auf logistischen Regressionsmodellen entwickelt wurden.
Die Feststellung der Prognosemöglichkeiten anhand eines Regressionsmodells erfolgt in drei Schritten: Modellentwicklung, Bestimmung der Prognosegüte und Modellvali- dierung.
In diesem Beitrag kann das Rational für das Vorgehen und die entsprechenden Makros nur kurz beschrieben werden. Eine genaue und detaillierte Beschreibung findet sich in [16]. Mit den 14 beschriebenen SAS-Makros steht ein Werkzeug zur Verfügung, das die Durchführung einer vollständigen Modellierung eines logistischen Prognose- modells ermöglicht. Speziell die Möglichkeiten der Modellvalidierung, die in der bis- herigen Praxis selten genutzt werden, sollten so in Zukunft zu jeder Prognosemodel- lierung herangezogen werden.
Schlüsselwörter: Prognosemodell, Logistische Regression, Modellvalidierung, SAS- Makro
In medical decision making about therapies or diagnostic procedures in the treatment of patients the prognoses of the course or of the magnitude of diseases plays a rele- vant role. Beside of the subjective attitude of the clinician mathematical models can help in providing such prognoses. Such models are mostly multivariate regression models. In the case of a dichotomous outcome the logistic model will be applied as
1Abt. Biometrie und Med. Dokumentation, Universität Ulm, Ulm, Deutschland
Originalarbeit
the standard model. In this paper we will describe SAS-macros for the development of such a model, for examination of the prognostic performance, and for model vali- dation.
The rational for this developmental approach of a prognostic modelling and the des- cription of the macros can only given briefly in this paper. Much more details are given in [16]. These 14 SAS-macros are a tool for setting up the whole process of deriving a prognostic model. Especially the possibility of validating the model by a standardized software tool gives an opportunity, which is not used in general in published prognostic models. Therefore, this can help to develop new models with good prognostic perfor- mance for use in medical applications.
Keywords: prognostic model, logistic regression, model validation, SAS-Macro
1. Einleitung
"Prognose ist eine Vorhersage über den zukünfti- gen Verlauf einer Krankheit nach ihrem Be- ginn"[10]. Nach dieser Definition können Prognosen in der Medizin die Therapieentscheidungen direkt oder indirekt mitbestimmen und sollten daher so zuverlässig wie möglich erstellt werden. Neben der subjektiven ärztlichen Einschätzung zum zukünftigen Krankheits- verlauf können Prognosen auch auf Grundlage entwi- ckelter mathematischer Modelle gegeben werden.
Dabei handelt es sich oft um verallgemeinerte lineare Regressionsmodelle, wie z.B. das multiple logistische Regressionsmodell, das im Fall dichotomer Zielgrößen, wie sie häufig im klinischen Alltag beobachtet werden, zur Anwendung kommt.
Im Folgenden wirdeineVorgehensweise zur Progno- semodellierung auf Basis der logistischen Regression vorgestellt, deren Umsetzung in der Praxis durch neu entwickelte SAS-Makros bzw. den sinnvollen Einbau bereits vorhandener SAS-Makros unterstützt wird. Die Entwicklung eines Prognosemodells erfolgt dabei im Wesentlichen in drei Schritten: (1) Modellentwicklung, (2) Bestimmung der Prognosegüte und (3) Modellvali- dierung.
• 1.1 Logistische Regression
Die logistische Regression ist seit langem ein Stan- dardverfahren für die Analyse binärer Zielgrößen [7], [14]. Die Modellgleichung zur Schätzung, ob ein Ereig- nis eintrifft (Y=1), gegeben einige Einflussgrößen X1, X2, ... , Xk, wird wie in Abbildung 1 angegeben model- liert.
Abbildung 1: Formel des logistischen Regressionsmodells
Dabei werden die Regressionskoeffizienten ßjmit der Maximum-Likelihood Methode geschätzt. In SAS kann die logistische Regression mit mehreren Prozeduren umgesetzt werden: PROC LOGISTIC, PROC CAT- MOD, PROC GENMOD, PROC PROBIT, wobei hier für die Umsetzung in den SAS-Makros die Prozedur PROC LOGISTIC eingesetzt wird.
2. Umsetzung der
Prognosemodellierung und Makro-Aufruf
Den Vorschlag für eine Vorgehensweise [11], [16] und sukzessive Abarbeitung der Prognosemodellierung in den drei Schritten (1) Modellentwicklung, (2) Progno- següte und (3) Modellvalidierung zeigt Abbildung 2.
Im Abschnitt 3 werden nach einer kurzen Beschreibung des prinzipiellen Aufrufs der Makros und der techni- schen Voraussetzungen jeweils einige kurze Hinweise zu den einzelnen Auswertungsschritten gegeben.
• 2.1 Allgemeiner Makro-Aufruf und technische Voraussetzungen
Der Aufruf aller Makros ist ähnlich gestaltet. In Abbil- dung 3 wird der prinzipielle Aufruf der wichtigsten Pa- rameter dargestellt. Mit den Parametern wird der auszuwertende Datensatz (data=), die Zielgröße mit interessierendem Event (resp_var=, event=) sowie die Einflussgrößen (diskret: cvar=, stetig: xvar=) angege- ben. Mit dem Parameter miss= können für Complete- Case-Analysen Beobachtungen mit fehlenden Werten aus der Analyse ausgeschlossen werden.
Originalarbeit
Abbildung 2: Schematischer Ablauf der Prognosemodellierung auf Basis der SAS-Makros [16]
Originalarbeit
Abbildung 3: Prinzipieller Aufruf der SAS-Makros Zur Nutzung sind einige Hard- und Softwarevorausset- zungen einzuhalten. Folgende Mindestanforderungen werden an das Computersystem gestellt:
• SAS-Installation ab SAS 8.2 (auch SAS 9 - Makros vorhanden)
• SAS-Module BASE, STAT, GRAPH, IML
• Hardwarevoraussetzungen zur Nutzung von SAS 8.2 bzw. 9 (Empfehlung: RAM 512 Mb, Prozessor >1 Ghz)
Die SAS-Makros nutzen viele externe Programme, u.a. umfangreiche Prüfprogramme. Das gesamte Ma- kropaket besteht aus etwa 100 Programmen und Da- teien. Deshalb sind zur Nutzung der Makros einige Voraussetzungen vorgegeben:
• das gesamte Makropaket steht in einem Ordner (Aufruf über macro_path=),
• die auszuwertenden Variablen müssen numerisch sein,
• die Variablen sollten möglichst numerisch formatiert sein,
• es wird eine Variable verlangt, die die Beobachtun- gen eindeutig identifiziert.
3. Kurzbeschreibung des Vorgehens anhand der SAS-Makros
In diesem Beitrag kann das Rational für das Vorgehen und das entsprechende Makro nur kurz beschrieben werden. Eine genaue und detaillierte Beschreibung findet sich in [16] bzw. [22]. Die folgende Kurzbeschrei- bung ist in die drei Oberbereiche der Prognosemodel- lierung: Modellentwicklung, Prognosegüte und Modell- validierung aufgeteilt.
• 3.1 Makros zur Modellentwicklung
Bei der Modellentwicklung sind verschiedene Untersu- chungen des Datensatzes vor der eigentlichen Model- lierung notwendig. Dazu gehört die Untersuchung der Variablen (Deskription) und deren Beziehungen unter- einander (Multikollinearität) genauso wie die Analyse des Einflusses der einzelnen Beobachtungen. Ein spezielles Problem sind fehlende Werte, die einen starken Einfluss auf das Ergebnis haben können. Die in der Tabelle 1 aufgeführten Makros helfen, diese Untersuchungen durchzuführen, bevor das logistische Regressionsmodell angepasst wird.
Tabelle 1: SAS-Makros zur Modellentwicklung
Mit dem Makro PM_DESCRIPTION werden alle ange- gebenen Einfluss- sowie die Zielgröße univariat de- skriptiv ausgewertet. Je nachdem, ob als stetig oder diskret angegeben, werden PROC UNIVARIAT und PROC FREQ zur Analyse herangezogen. Dabei kann über den Parameter miss= entschieden werden, ob alle Beobachtungen in jeder Variablen oder ein Com- plete-Case-Datensatz ausgewertet wird. Zur Untersu- chung der Missing-Value Situation im Datensatz lässt sich neben der Auszählung der fehlenden Werte pro Variable auch die Anzahl fehlender Werte pro Beob- achtung ausgeben.
Die Untersuchung der Multikollinearität in PM_MULTI- COLLIN geschieht durch:
• paarweise Korrelationen (Spearman, PROC CORR)
• Varianzinflationsfaktoren (VIF, PROC REG)
• Eigenwertanalyse ([4], PROC REG/COLLINOINT)
Originalarbeit
Nach einem Vorschlag von Allison [2] wird die Eigen- wertanalyse zur Anpassung an die logistische Auswer- tungssituation anhand geschätzter Wahrscheinlichkei- ten aus PROC LOGISTIC gewichtet durchgeführt.
Mit Missing Values kann bei der Auswertung folgen- dermaßen umgegangen werden:
• Complete-Case-Analyse (miss=0)
• Single Imputation (stetig: PROC STDIZE, diskret:
zus. Kategorie MISSING)
• Multiple Imputation (Untersuchung des Missing pat- tern, PROC MI)
Das Makro PM_INFLUENCE identifiziert die für die Modellierung einflussreichsten Beobachtungen. Dabei wird hauptsächlich die Veränderung der Pearson- Statistik nach Entfernung einer Beobachtung unter- sucht. Große Veränderungen weisen auf einen großen Einfluss auf die Parameterschätzung hin. Schrittweise werden die einflussreichsten Beobachtungen bis zu einer vorgegebenen Schranke identifiziert, jedoch nicht automatisch aus dem Datensatz eliminiert.
In PM_UNI_LOGREG wird für jede Einflussgröße ein eigenes logistisches Regressionsmodell berechnet und der entsprechende p-Wert ausgegeben. Dabei kann auf den Complete-Case-Datensatz zurückgegrif- fen werden (miss=0). Kategorielle Variablen werden immer als Dummy-Variablen ins Modell aufgenommen und über das CLASS-Statement der gemeinsame Einfluss aller Dummies dieser Variable untersucht.
Stetige Variablen gehen linear ins Modell ein. Zusätz- lich wird für jede stetige Variable eine Überprüfung der besseren Modellierung über "Fractional Polynomi- als" bis zum Grad 2 [18] durchgeführt.
Die eigentliche multiple logistische Regressionsanalyse wird mit dem Hauptmakro PM_LOGREG durchgeführt.
Mit diesem Makro wird ein multiples logistisches Re- gressionsmodell, eventuell mit Stepwise-Variablense- lektion, angepasst. Dieses Makro liefert spezielle Ausgabedateien, die für weitere Analysen genutzt werden können (ROC, Modellvalidierung). Zur Prüfung des gemeinsamen Einflusses von Variablen kann das TEST-Statement eingesetzt werden. Wechselwirkun- gen werden nicht automatisiert erzeugt und berücksich- tigt, können aber durch Definition als eigene Variable in die Modellierung integriert werden. Bei den durch geringe Fallzahlen und oder viele untersuchte Einfluss- größen häufigen Problemen der Parameterschätzung durch eine complete- oder quasi-complete-Separation [1], [5] wird eine korrigierte Schätzmethode über das FL-Makro [12] automatisch durchgeführt. Dabei werden die Parameter mit der Firth-Prozedur durch ein
"penalized" Maximum Likelihood Verfahren geschätzt.
Eine alternative Vorgehensweise durch eine exakte Schätzung wird wegen Laufzeitproblemen in SAS nicht durchgeführt.
Das Makro PM_GOF dient zur Überprüfung der Model- lanpassung. Neben Parametern aus PROC LOGISTIC sind hier spezielle Tests für Sparseness (wenige Be- obachtungen pro Merkmalskombination) aus der Lite- ratur integriert (Makros aus [15], [17]), da in dieser Situation u.a. der Hosmer-Lemeshow-Test nicht mehr geeignet ist.
• 3.2 Makro zur Überprüfung der Prognosegüte
Bei der Überprüfung der Prognosegüte stellt sich die Frage:"Wie gut kann der Outcome des Patienten vorhergesagt werden?"Die Überprüfung der Progno- següte geschieht anhand einer Reklassifikation. Dabei werden die Daten der Patienten in die Modellgleichung eingesetzt und so für jeden Patienten die Wahrschein- lichkeit für das Eintreten des Outcome geschätzt.
Durch einen Vergleich mit den beobachteten Werten lässt sich die Übereinstimmung untersuchen.
Dabei können nach Wahl eines Grenzwertes (Cutpoint) zur Einteilung der Wahrscheinlichkeiten in "groß" bzw.
"klein" die Kenngrößen wie Sensitivität, Spezifität, prädiktive Werte, Youden-Index etc. bestimmt werden.
Zusätzlich lassen sich globale Maße der Prognosegüte (unabhängig von einem Cutpoint) angeben: AUC, Somer´s D, Emax, Brier Score etc. Diese Kenngrößen werden im Rahmen einer ROC-Analyse erzeugt (Ta- belle 2).
Tabelle 2: SAS-Makros zur Modellgüte
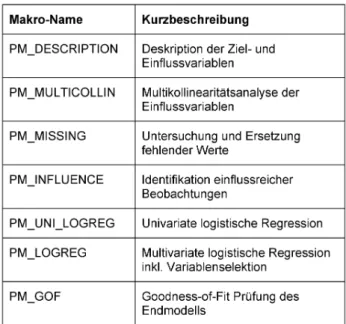
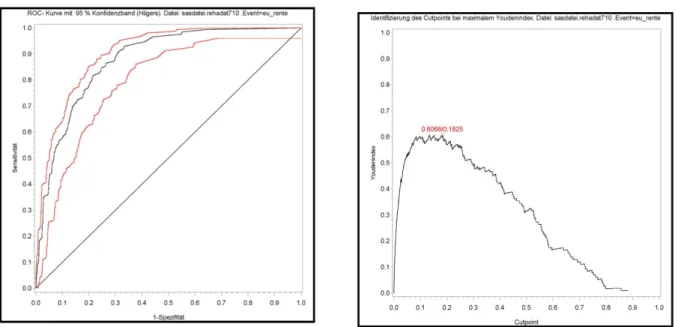
Die Prognosegüte wird anhand einer ROC-Analyse mit dem Makro PM_ROC durchgeführt. Alle oben an- gegeben Maßzahlen (zusätzlich Konfidenzintervalle für AUC) sowie einige wichtige Grafiken (u.a. ROC- Kurven (inkl. Konfidenzbänder nach Hilgers [13], Zu- sammenhang Youden-Index und Cutpoint) werden ausgegeben (Abbildung 4).
Zur Zusammenfassung der Prognosegüten (nach lo- gistischer Regression und ROC-Analyse) wird das Makro PM_MI_ANALYZE eingesetzt.
Originalarbeit
Abbildung 4: Beispielhafte Ausgabe von Grafiken aus PM_ROC.MAC.SAS
• 3.3 Makros zur Modellvalidierung
Nach der Untersuchung zur Prognosegüte könnte entschieden werden, ob das Prognosemodell für die Praxis ausreichende ist, d.h. möglichst wenig Fehlpro- gnosen erzeugt. Allerdings ist die Frage"Wie gut ist die Prognosegüte für spätere unabhängige Beob- achtungen?"bis hierhin noch nicht beantwortet. Das Problem besteht darin, dass die Prognosegüte nach der Reklassifikation anhand derselben Patientendaten ermittelt wird, die auch zur optimalen Schätzung der Regressionskoeffizienten zur Verfügung standen. So- mit ist von einem Bias im Sinne einer zu optimistischen Prognosegüte nach der ROC-Analyse auszugehen.
Zur Untersuchung dieses Bias sollte eine Modellvali- dierung erfolgen. Dafür stehen verschiedenen Verfah- ren zur Verfügung, die in den folgenden fünf Makros umgesetzt wurden. In der Literatur wird neben der externen Validierung die Bootstrap-Methode favorisiert [20]. Als Output werden jeweils die Cutpoint-abhängi- gen und -unabhängigen Prognosegütemaße der ROC- Analyse vor und nach der Validierung sowie die abso- lute und relative Veränderung ausgegeben (Tabelle 3).
Tabelle 3: SAS-Makros zur Modellvalidierung
Bei der externen Validierung wird die Prognosegüte des Modells anhand eines zweiten, unabhängigen Datensatzes bestimmt. Dies ist die Methode der Wahl, falls ein zweiter Datensatz zur Verfügung steht. Leider ist dies selten der Fall, so dass auf Methoden zurück- gegriffen werden muss, die auf dem vorhandenen Datensatz basieren (interne Validierungsmethoden).
Durch das Data-Splitting wird der Datensatz geteilt.
Ein Teil wird zur Modellentwicklung, der Zweite zur Validierung (s. externe Validierung) genutzt. Dabei beruht die Modellentwicklung und Modellvalidierung allerdings auf einer wesentlich geringeren Fallzahl, so dass dies Verfahren nur selten sinnvoll eingesetzt werden kann. Das Makro teilt den Datensatz nach vorgegebener Prozentangabe zufällig auf. Für die Validierung ist anschließend PM_EXTERNAL_VALI- DATION aufzurufen.
Die Kreuzvalidierung war lange Zeit das Standardver- fahren für die Modellvalidierung. Prinzipiell liegt dem Verfahren ein Stichprobenziehen ohne Zurücklegen zugrunde. Das Vorgehen kann folgendermaßen skiz-
Originalarbeit
ziert werden: Datensatz in K Teile teilen; anschließend an K-1 Teilen das Modell entwickeln und am K-ten Teil validieren. Das ganze wird für alle K Teile wieder- holt. Im Makro sind folgende Methoden programmiert:
K-fold Crossvalidation, adjusted Crossvalidation [8], Jackknife-Crossvalidation.
Die Methode der Bootstrap-Validierung [3] ist ebenfalls ein Resampling-Verfahren, basiert aber auf einem Ziehen mit Zurücklegen: Es werden Datensätze glei- cher Größe aus dem vorhandenen Datensatz erzeugt.
Anhand dieser so erzeugten Datensätze kann die Modellierung und/oder Validierung der Modelle erfol- gen. Durch geeignetes Zusammenführen der Einzeler- gebnisse kann der Bias der Prognosegüte abgeschätzt werden. Im Makro implementiert sind die Vorschläge von Efron [9]: simple-/enhanced Bootstrap sowie ein Ansatz über Mittelung der Regressionskoeffizienten (Mean Model).
Die Shrinkage-Methode korrigiert die geschätzten Regressionskoeffizienten [21], so dass die Prognose- güte anhand des korrigierten Modells bestimmt wird.
Drei Methoden sind im Makro implementiert: heuristi- scher Shrinkage, globaler Shrinkage [21] sowie ein parameterbezogener Shrinkage-Faktor [19].
4. Fazit
Die wichtigsten Probleme der Modellbildung werden in der Literatur folgendermaßen zusammengefasst:
nicht spezifizierte Definition der Variablen, Multikolli- nearität, Nichtberücksichtigung einflussreicher Beob- achtungen, nicht erfüllte Modellvoraussetzungen, Nichtlinearität des Zusammenhanges, Überanpassung, unspezifizierte Variablenselektion, keine Wechselwir- kungsprüfung sowie fehlende Modellvalidierung [9].
Die vorgestellte Strategie zur Modellentwicklung und -validierung anhand eines SAS-Makro-Paketes berück- sichtigt diese Auswertungsprobleme und schafft damit Voraussetzungen, in Zukunft geeignete Prognosemo- delle auf Basis der logistischen Regression erstellen und deren praktischen Nutzen genauer ermitteln zu können. Damit tragen die vorgestellten Makros zur Verbesserung der biometrischen Praxis zur Bestim- mung zuverlässigerer Prognosen bei. Die Umsetzung der Strategie in einzelne Auswertungsmodule schafft die Flexibilität, die Auswertungsschritte auch in einer anderen Reihenfolge als angegeben bzw. auch mehrfach anzuwenden, um jeweils zu einer sachge- rechten Modellierung zu gelangen. Dementsprechend können die Makros auch nicht automatisiert werden im Sinne eines durchgehend ablaufenden Makros von der Deskription der Daten bis zur Ausgabe der validier- ten Ergebnisse, da nach jedem Auswertungsschritt
benenfalls die Einstellung des nachfolgenden Makros anpassen muss.
Die Makros stehen auf http://www.uni- ulm.de/uni/fak/medizin/biodok/v2004/prognosema- kros.htm zum Download zur Verfügung, die Nutzung und Hintergrundinformationen werden in [16] beschrie- ben.
Korrespondenzadresse:
• PD Dr. Rainer Muche, Abt. Biometrie und Med.
Dokumentation, Universität Ulm, Schwabstrasse 13, 89075 Ulm, Tel.: 0731/50-26903
rainer.muche@uni-ulm.de
Literatur:
[1] Albert A, Anderson JA. On the existence of maximum likelihood estimates in logistic regression models. Biometrika.
1984;71:1-10.
[2] Allison PD. Logistic Regression using the SAS System.
Cary NC: SAS Institute Books By Users; 1999.
[3] Assfalg I. Die Bootstrap-Methode zur internen Validierung von Prognosemodellen. Diplomarbeit FH Ulm; 2003.
[4] Belsley DA. Conditioning diagnostics - Collinearity and weak data in regression. New York: John Wiley & Sons;
1991.
[5] Christmann A, Rousseeuw PJ. Measuring overlap in logistic regression. Comp Statist Data Anal. 2001;37:65-75 [6] Concato J, Feinstein AR, Holford TR. The risk of determing risk with multivariable models. Ann Intern Med.
1993;118:210.
[7] Cox DR, Snell EJ. Analysis of binary data. London:
Chapman & Hall; 1989.
[8] Davison AC, Hinkley DV. Bootstrap methods and their application. Cambridge: Cambridge University Press; 1997.
[9] Efron B, Tibshirani RJ. An Introduction to the Bootstrap.
New York: Chapman & Hall; 1993.
[10] Fletcher RM, Fletcher SW, Wagner EH. Klinische Epidemiologie. Wiesbaden: Ullstein Medical Verlag; 1999.
[11] Harrell FE Jr. Regression Modeling Strategies. New York: Springer Verlag; 2001.
[12] Heinze G, Schemper M. A solution to the problem of separation in logistic regression. Stat Med. 2002;21:2409-19.
[13] Hilgers R. Distribution-free confidence bounds for ROC curves. Meth Inform Med. 1991;30:96-101.
[14] Hosmer DW, Lemeshow S. Applied Logistic Regression.
2nd ed. New York: John Wiley & Sons; 2000.
[15] Kuss O. Global goodness-of-fit-tests in logistic regression with sparse data. Stat Med. 2002;21:3789-801.
[16] Muche R, Ring Ch, Ziegler Ch. Entwicklung und Validierung von Prognosemodellen auf Basis der logistischen Regression. Aachen: Shaker Verlag; 2005.
Originalarbeit
[17] Pulkstenis E, Robinson TJ. Two goodness-of-fit tests for logistic regression with continuous covariates. Stat Med.
2002;21:79-93.
[18] Royston P, Altman DG. Regression using fractional polynomials of continuous covariates. Appl Statist.
1994;43:429-67.
[19] Sauerbrei W. The use of resampling methods to simplify regression models in medical statistics. Appl Statist.
1999;48:313-29
[20] Steyerberg EW, Harrell FEJr., Borsboom GJJM, et al.
Internal validation of predictive models: Efficiency of some procedures for logistic regression analysis. J Clin Epidemiol.
2001;54:774-81.
[21] van Houwelingen H, LeCessie S. Predictive value of statistical models. Stat Med. 1990;9:1303-25.
[22] Ziegler Ch. Ein SAS-Makro-Paket zur Entwicklung und Validierung von Prognosemodellen auf Basis der logistischen Regression. Diplomarbeit FH Ulm; 2004.
Originalarbeit
![Abbildung 2: Schematischer Ablauf der Prognosemodellierung auf Basis der SAS-Makros [16]](https://thumb-eu.123doks.com/thumbv2/1library_info/4883160.1633936/3.892.95.819.94.1014/abbildung-schematischer-ablauf-prognosemodellierung-basis-sas-makros.webp)