Time-Optimal Nonlinear Model Predictive Control
Direct Transcription Methods with Variable Discretization and Structural Sparsity Exploitation
DISSERTATION
submitted in partial fulfillment of the requirements for the degree
Doktor-Ingenieur (Doctor of Engineering)
in the
Faculty of Electrical Engineering and Information Technology at Technische Universität Dortmund
by
Christoph Rösmann, M.Sc.
Münster, Germany
Date of submission: April 29, 2019
Place of submission: Dortmund, Germany
First examiner: Univ.-Prof. Dr.-Ing. Prof. h.c. Dr. h.c. Torsten Bertram Second examiner: Univ.-Prof. Dr.-Ing. Martin Mönnigmann
Date of approval: October 14, 2019
Preface
This thesis was written during my work at the Institute of Control Theory and Systems Engineering of the Faculty of Electrical Engineering and Information Technology at the Technical University of Dortmund.
I would like to thank Univ.-Prof. Dr.-Ing. Prof. h.c. Dr. h.c. Torsten Bertram that he made my scientific work possible and generously supported it. I am very grateful for his valuable feedback, confidence and inspiring suggestions. He has always given me the freedom to develop my own scientific knowledge and present it to a broad audience at numerous local and international conferences. I would also like to thank Univ.-Prof. Dr.-Ing. Martin Mönnigmann, who agreed to review my thesis as second examiner. I greatly appreciate his valuable feedback and expertise.
Additionally, I would like to thank all staff members and former staff members of the Institute of Control Theory and Systems Engineering for the pleasant working atmosphere, the cooperativeness and camaraderie. In particular, I am grateful for the assistance given by apl. Prof. Dr. rer. nat. Frank Hoffmann. His excellent experience in many different engineering and scientific fields, his insightful comments and the intensive discussions have helped me a lot to advance my ideas and research projects.
Dr.-Ing. Daniel Schauten deserves my special thanks for the many valuable conver- sations, advices and support during my time at the department, especially regarding best practices in teaching and research. I am very thankful to Artemi Makarow for all the time we spent discussing and questioning many control theoretical topics, for the conference trips we have experienced together and for the extraordinary support and encouragement especially in the final stages of completing my thesis. Special thanks also go to Maximilian Krämer and Christian Wissing for the intensive ex- change in many topics, especially in robotics and software development in C++. For the always kind assistance with administrative and technical questions I would like to thank Nicole Czerwinski, Gabriele Rebbe, Sascha Kersting, Jürgen Limhoff and Rainer Müller-Burtscheid.
I would also like to express my gratitude for the financial support provided by the German Research Foundation (DFG).
Words of gratitude are dedicated to my friends who helped me to find distraction and relaxation. Finally, I am very grateful to my family for their continuous unconditional support and encouragement throughout my life.
Dortmund, October 2019 Christoph Rösmann
Abstract
This thesis deals with the development and analysis of novel time-optimal model pre- dictive control concepts for nonlinear systems. Common realizations of model predic- tive controllers apply direct transcription methods to first discretize and then optimize the subordinate optimal control problems. The key idea of the proposed concepts is to introduce discretization grids in which the underlying discretization is explicitly treated as temporally variable during optimization. A single optimization parameter for all grid intervals leads to the global uniform grid, while the definition of an indi- vidual parameter for each interval results in the local uniform and quasi-uniform grid representations. The proposed grids are well-suited for established direct transcription methods such as multiple shooting and collocation. In addition, a proposed non-uni- form grid with extended multiple shooting is highly beneficial for bang-singular-bang control systems with simple constraint sets. The minimization of the local time in- formation of a grid leads to an overall time-optimal transition. Integration with state feedback does not immediately guarantee asymptotic stability and recursive feasibility.
To this end, the thesis provides a grid adaptation scheme capable of ensuring practi- cal stability and, under more restricted conditions, also nominal asymptotic stability while maintaining feasibility. The practical stability results facilitate the systematic dual-mode control design that restores asymptotic stability and establishes smooth stabilization.
The secondary objective of this thesis is the computationally efficient realization of time-optimal model predictive control by exploiting the inherent sparse structures in the optimal control problems. In particular, the efficient computation of first- and second-order derivatives required for iterative optimization is facilitated by a so-called hypergraph. The hypergraph captures the structure of the transcribed optimal con- trol problems and enables an almost linear relation between computation time and grid size. In addition, the hypergraph shows negligible computation times for each reconfiguration that is essential for grid adaptation.
Numerous examples in simulation and with a real experimental system demonstrate the capabilities and potentials of the proposed concepts. Extensive benchmarks in C++ compare the proposed methods with each other and the current state of the art.
The methods based on variable discretization outperform the current time-optimal
model predictive control methods in the literature, especially with regard to computa-
tion time.
Contents
Nomenclature iii
1. Introduction 1
1.1. Motivation . . . . 1 1.2. Contribution and Outline . . . . 3
2. Related Work 6
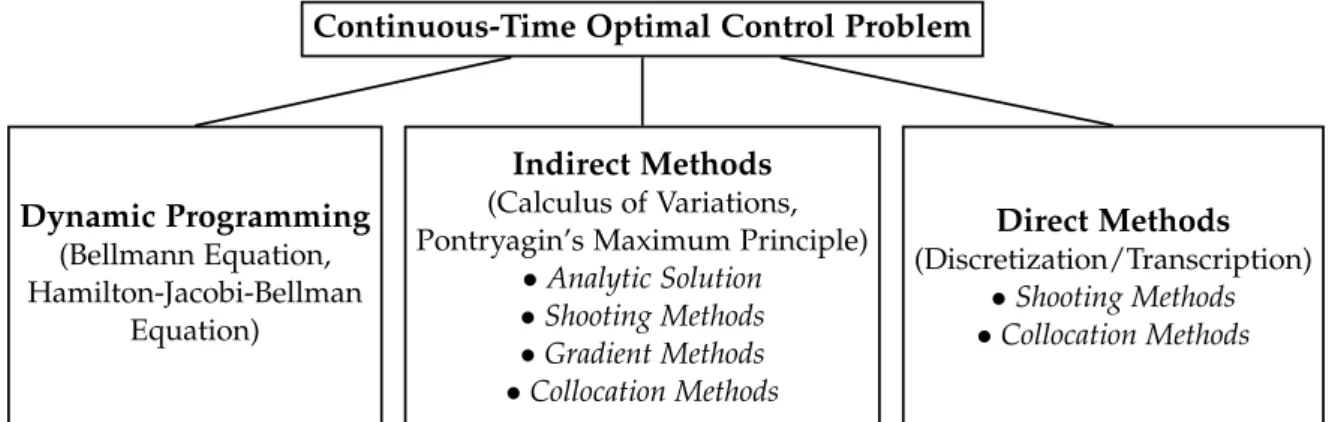
2.1. Optimal Control Methods . . . . 6 2.2. Model Predictive Control . . . 12 2.3. Time-Optimal Model Predictive Control . . . 14
3. Fundamentals 16
3.1. Dynamic System . . . 16 3.2. Feedback Control . . . 17 3.3. Benchmark Systems . . . 22
4. Global Uniform Grid for Time-Optimal Control 27
4.1. Direct Transcription Methods . . . 27 4.2. Solution to the Nonlinear Program . . . 33 4.3. Examples . . . 35
5. Time-Optimal Model Predictive Control 38
5.1. Shrinking-Horizon Closed-Loop Control . . . 38 5.2. Grid Size Adaptation . . . 44 5.3. Smooth Stabilizing Control . . . 47 6. Local Uniform and Quasi-Uniform Grid Representations 52 6.1. Uniformity Enforcement by Equality Constraints . . . 52 6.2. Approximation to the Uniform Grid . . . 53 6.3. Closed-Loop Control and Grid Adaptation . . . 56
7. Sparsity Structure Exploitation with Hypergraphs 59
7.1. Hypergraph Representation for Nonlinear Programs . . . 60 7.2. Sparse Derivative Computations . . . 62 7.3. Application to Time-Optimal Model Predictive Control . . . 66
8. Comparative Analysis and Benchmark Results 71
8.1. Time-Optimal Control with Variable Discretization Grids . . . 71
8.2. Comparison with Fixed Grid Methods . . . 78
8.3. Closed-Loop Control Performance . . . 81
9. Non-Uniform Grid for Bang-Singular-Bang Systems 84
9.1. Multiple Shooting Formulation . . . 84
9.2. Adaptation of Control Interventions . . . 90
9.3. Performance Comparison and Benchmark Results . . . 93
10. Conclusion and Outlook 97 A. Mathematical Definitions 101 A.1. Lipschitz Continuity . . . 101
A.2. Control Parameterization . . . 101
A.3. Numerical Solution to Initial Value Problems . . . 102
A.4. Fundamentals of Constrained Nonlinear Optimization . . . 103
B. Stability Definitions and Results 107 B.1. Lyapunov Functions for Stability . . . 107
B.2. Stability Results and Proofs . . . 108
C. Time-Optimal Control Methods – Extensions and Related Work 115 C.1. Related Methods from the Literature . . . 115
C.2. Types of Hermite-Simpson Collocation . . . 117
C.3. Minimum Number of Control Interventions . . . 120
C.4. Unconstrained Nonlinear Least-Squares Approximation . . . 121
D. Hypergraph for Nonlinear Model Predictive Control 129 D.1. Structural Sparsity Exploitation with Hypergraphs . . . 129
D.2. Comparative Analysis and Benchmark Results . . . 132
E. Implementation Details and Algorithms 136 E.1. Software Framework . . . 136
E.2. Optimization Algorithms . . . 137
F. Supplemental Results 142 F.1. ECP Industrial Plant Emulator Model 220 . . . 142
F.2. Benchmark Hardware and Results . . . 144
Bibliography 155
Nomenclature
General Symbols
ℓ 1 Absolute value norm
ℓ 2 Euclidean norm
T ¯ p Computation time required for solving the optimization problem T ¯ s Computation time required for preparing the optimization problem
∆t cpu Computation time for determining the control law
τ Auxiliary time parameter
θ Scalar weight for the ℓ 1 -norm cost function θ 0 Lower bound on θ to ensure time-optimality
ξ Auxiliary parameter in the Cauchy-Schwarz inequality Symbols and Functions for General Dynamic Systems and Control Tasks A System matrix of a linear system
B Input matrix of a linear system f ( · ) System dynamics vector field
f d ( · ) Sampled-data system dynamics vector field K Linear feedback gain matrix
L ¯ Lipschitz constant
¯
r Scalar parameter in the definition of Lipschitz continuity
p State dimension
φ ( · ) Solution to the initial value problem of the system dynamics
q Control dimension
¯ t Transformed time parameter (time transformation approach)
t f Final time
t s Initial time
t Time
u 1 ( t ) First component of control trajectory u ( t ) u 2 ( t ) Second component of control trajectory u ( t ) u ( t ) Control trajectory
u f Final control respectively reference control u dist ( t µ ) Disturbance profile with closed-loop time t µ u lin ( t ) Control trajectory of the linear system u max Upper bound on the control
u min Lower bound on the control
x 1 ( t ) First component of state trajectory x ( t ) x 2 ( t ) Second component of state trajectory x ( t ) x ( t ) State trajectory
x f Final state respectively steady state
x f,1 First component of the final state
x f,2 Second component of the final state x ref ( t ) Reference trajectory
x s Initial state
x lin ( t ) State trajectory of the linear system x max Upper bound on the state
x min Lower bound on the state y ( t ) System output
y 1 ( t ) First component of y ( t ) y 2 ( t ) Second component of y ( t )
Symbols and Functions for Predictions, Open-Loop Control and Direct Transcription β 1 Coefficient for the linear term in the quadratic control polynomial β 2 Coefficient for the quadratic term in the quadratic control polynomial
∆t Global time interval t k + 1 − t k , ∀ k
∆t k Local time interval t k + 1 − t k
∆t ϵ Threshold for inserting or removing intervals (grid adaptation)
∆t max Upper bound on the time interval
∆t min Lower bound on the time interval
∆t ref Reference time interval for grid adaptation
∆t ∗ Optimal global time interval t k + 1 − t k , ∀ k
∆t ∗ k Optimal local time interval t k + 1 − t k
t min Lower bound on the final time t f (hybrid cost approach) ι Running index for enhanced integration (non-uniform grid)
∆t int Step size for the integration steps ∆t k /N int (non-uniform grid)
∆t rem,k Remaining step width for interval ∆t k (non-uniform grid)
∆u k Control error at time instance t k with respect to u f
∆x k State error at time instance t k with respect to x f e x ˆ ( t f ) Integral error at time t f
e x ˆ ( t ) Integral error with respect to ˆ x u ( t ) ( ℓ 2 -norm)
g ˜ ( · ) Integrand of the additional constraint equation (non-uniform grid) γ 1 Coefficient for the linear term in the cubic state polynomial
γ 2 Coefficient for the quadratic term in the cubic state polynomial γ 3 Coefficient for the cubic term in the cubic state polynomial h hs ( · ) State interpolant at t k + 0.5 in Hermite-Simpson collocation h fd ( · ) Equality constraint for collocation via finite differences h fe ( · ) Equality constraint for multiple shooting with forward Euler
I adapt Number of iterations for grid adaptation
i General running index (multiple shooting grid, grid adaptation, fun- damentals of nonlinear optimization)
k ¯ Running index for accumulating time intervals of the local grid κ Running index for Levenberg-Marquardt and SQP iterations k Index for time instances (prediction)
ℓ( · ) Running cost
˜
m Number of controls in each shooting interval, ˜ m i = m ˜ ∀ i
Nomenclature
˜
m i Number of controls in the i-th shooting interval M Number of shooting intervals
N init Initial grid size N for grid adaptation N max Upper bound on the grid size N N min Lower bound on the grid size N
N Discretization grid size or horizon length
N ∗ Minimum grid size respectively dead-beat horizon length N crit Smallest grid size for which the non-uniform grid is feasible
k ¯ 1 , ¯ k 2 , . . . , ¯ k 6 Auxiliary parameters in the explicit 5 th -order Runge-Kutta method N b Number of control interventions (non-uniform grid)
N ˜ b Surplus in the number of control interventions (non-uniform grid) u ϵ Similarity threshold for two consecutive controls (non-uniform grid) N int Number of integration steps for interval ∆t k , ∀ k (non-uniform grid) N int,k Number of integration steps for interval ∆t k (non-uniform grid) ϕ fd ( · ) Finite difference kernel function
ϕ hs ( · ) Simpson quadrature of f ( · ) in Hermite-Simpson collocation
ϖ Running index for interstitial grid points k in each shooting interval Q ˜ Weighting matrix for the state error (Riemann sum approximation) Q State error weighting matrix in quadratic form cost
R ˜ Weighting matrix for the control effort (Riemann sum approximation) R Control effort weighting matrix in quadratic form cost
ρ Weight for the regularization term (non-uniform grid) s ¯ k Slack variable with index k in the ℓ 1 -norm approach s i Shooting node at time instance ˜ t i , x u ( t ˜ i ) : = s i
˜ t i Time instance with index i (multiple shooting grid) t 0 Initial time (prediction)
t k Time instance with index k (prediction)
˜
u i ( t ) Control trajectory on shooting interval [ t ˜ i , ˜ t i + 1 ] , u ( t + t ˜ i ) : = u ˜ i ( t ) u ∗ ( t; t µ ) Optimal control trajectory at closed-loop time t µ
u ∗ ( t ) Optimal control trajectory
u ∗ k Optimal control at time instance t k (prediction) u k Control at time instance t k , u ( t k ) : = u k (prediction)
V dyn,N Cost for the non-uniform grid control problem with size N
V dyn,N ∗ Optimal cost for the non-uniform grid control problem with size N V f ( · ) Terminal cost
V k ( · ) Integral of the running cost on interval [ t k , t k + 1 ] x u,1 ( t ) First component of state trajectory x u ( t ) (prediction) x u,2 ( t ) Second component of state trajectory x u ( t ) (prediction)
ˆ
x u,1 ( t ) First component of state trajectory ˆ x u ( t ) ˆ
x u,2 ( t ) Second component of state trajectory ˆ x u ( t ) ˆ
x u ( t ) Open-loop state trajectory (for error calculation) x u ( t ) State trajectory (prediction)
x k State at time instance t k , x u ( t k ) : = x k (prediction) 1 p Vector of ones with dimension p × 1
I n Identity matrix with dimension n × n
Symbols and Functions for Closed-Loop Control
∆t µ,n Time interval between time instances t µ,n and t µ,n + 1
g f ( · ) Closed-loop system dynamics vector field µ ( · ) Control law
µ 1 ( · ) First component of the control-law µ ( · ) µ 2 ( · ) Second component of the control-law µ ( · ) µ dual ( · ) Dual-mode control-law
µ lin ( · ) Control law of the local controller (dual-mode) n Index for time instances (closed-loop)
φ µ ( · ) Solution to the initial value problem of g f ( · ) t µ Time variable (closed-loop)
t µ,n Time instance with index n (closed-loop) x µ,1 ( t µ ) First component of state trajectory x µ ( t ) x µ,2 ( t µ ) Second component of state trajectory x µ ( t ) x µ ( t µ ) State trajectory (closed-loop)
Symbols and Functions for the Stability Analysis α 1 ( · ) Comparison function, α 1 ∈ K ∞
α 2 ( · ) Comparison function, α 2 ∈ K ∞
α V ( · ) Comparison function, α V ∈ K β ( · ) Comparison function, β ∈ KL η Distance from x f (stability analysis)
Symbols and Functions for Nonlinear Programs and the Hypergraph
χ ( · ) Weighted quadratic penalty function for inequality constraints d ˜ Constant term in least-squares derivation
D (︁
Φ ( · ) , ∆z )︁
Directional derivative of Φ ( · ) with respect to ∆z.
∆z Parameter update vector
∆z ∗ Optimal parameter update vector
e g r Edge in the hypergraph that is associated with g r ( · ) e h s Edge in the hypergraph that is associated with h s ( · ) e l J Edge in the hypergraph that is associated with J l ( · ) η LS Growth rate for the least-squares approximation λ LM Levenberg-Marquardt damping factor
η sqp Line-search parameter in sequential quadratic programming F ( z ) Least-squares cost vector with respect to parameter z
˜
g ( · ) Quadratic penalty function for inequality constraints g ( · ) General inequality constraint function
g r ( · ) Component with index r in g ( · )
H Hessian of the least-squares problem and Hessian in the SQP h ( · ) General equality constraint function
h s ( · ) Component with index s in h ( · )
I LM Number of Levenberg-Marquardt solver iterations I SQP Number of SQP solver iterations
J ( · ) General cost function
J l ( · ) Cost summand with index l in J ( · )
Nomenclature
δ D Pertubation of finite difference calculations (first-order) δ H Pertubation of finite difference calculations (second-order) L ( · ) Lagrangian of a nonlinear program
L Number of summands in J ( · )
l Running index for summands in J ( · )
λ Lagrange multiplier for the equality constraint
λ ∗ Optimal lagrange multiplier for the equality constraint λ ∗ i Optimal lagrange multiplier for the i-th equality constraint λ i Lagrange multiplier for the i-th equality constraint
µ Lagrange multiplier for the inequality constraint
µ ∗ Optimal lagrange multiplier for the inequality constraint µ ∗ i Optimal lagrange multiplier for the i-th inequality constraint µ m Penalty parameter in merit function Φ ( · )
µ i Lagrange multiplier for the i-th inequality constraint
Φ ( · ) Merit function for line-search in sequential quadratic programming
˜
p Linear term in least-squares derivation
ψ ( · ) Weighted quadratic penalty function for equality constraints R Dimension of inequality constraint function g ( · )
r Running index for components of g ( · )
S Dimension of equality constraint function g ( · ) s Running index for components of h ( · )
σ 1 Penalty weighting parameter for equality constraints
˜
σ 1 Square root of σ 1
σ 2 Penalty weighting parameter for inequality constraints
˜
σ 2 Square root of σ 2
τ sqp Line-search parameter in sequential quadratic programming Υ ˜ Number of unfixed vertices in the hypergraph
Υ Number of nominal optimization parameters
v υ Vertex in the hypergraph that correspond to parameter z υ
w Vector in constraint qualification conditions and second-order opti- mality conditions
˜
z υ ˜ Nominal optimization parameter with index ˜ υ z υ Nominal optimization parameter with index υ
n z Dimension of z
z Nominal (single) optimization parameter z ∗ Optimal (single) optimization parameter
z max Upper bound on nominal optimization parameter z min Lower bound on nominal optimization parameter z ref,ω Fixed vector asigned to z ω for some 0 ≤ ω ≤ Υ z ω Parameters with trivial assignments (see z ref,ω ) Symbols and Functions for Benchmark Systems
a vdp Damping coefficient of the Van der Pol oscillator c drag Drag coefficient of the rocket system
c roc Mass rate of change coefficient of the rocket system
˜
c 1 Friction coefficient (ECP Model 220)
˜
c 2 Friction coefficient (ECP Model 220)
c 1 Linear damping coefficient (ECP Model 220)
c 2 Coefficient for nonlinear damping (ECP Model 220) c 3 Slope in the nonlinear damping term (ECP Model 220) F inertial Inertial force of the rocket system
F drag Drag force of the rocket system F thrust Thrust force of the rocket system J ecp Moment of inertia (ECP Model 220) k ˜ 1 Motor specific constant (ECP Model 220) k ˜ 2 Motor specific constant (ECP Model 220) k 1 Gain of the first motor input (ECP Model 220) k 2 Gain of the second motor input (ECP Model 220) m r ( t ) Mass of the rocket system at time t
m r,f Final mass of the rocket system
s r ( t ) Position of the rocket system at time t s r,f Final position of the rocket system v r ( t ) Velocity of the rocket system at time t v r,f Final velocity of the rocket system Sets
B η ( x f ) Ball around x f with distance η C ( · ) Critical cone
∅ Empty set
E Set of edges in the hypergraph E e Set of indices of equality constraints F ( z ) Linearized feasible directions at z G ( V , E ) Hypergraph
A I ( z ) Set of indices of active inequality constraints with respect to z I Set of indices of inequality constraints
I Open time interval, I ⊂ R
K Set of indices that relate to redundant controls (non-uniform grid) N Neighborhood of an optimal parameter z ∗
N Positive natural numbers excluding zero N 0 Natural numbers including zero
Ω Feasible set for the nominal nonlinear program P global Set of optimization parameters for the global grid P local Set of optimization parameters for the local grid
P local,N Set of optimization parameters for the local grid with size N P Generic set for practical asymptotic stability
P c ( · ) Controllability region with respect to U N P ∆t min ( x f ) Controllability region to x f up to time ∆t min
R + Positive real numbers excluding zero R + 0 Positive real numbers including zero
S i Set of grid indices k in the shooting interval [ t ˜ i , ˜ t i + 1 ]
Nomenclature
S Lyapunov function state space, S ⊂ X T Ω ( z ) Tangent cone at z
U Restricted control space, U ⊂ U U Control space, X : = R q
V Set of vertices in the hypergraph X feas Feasible set in the TOMPC approach X Restricted state space, X ⊆ X
X lin Forward invariant region of the local controller (dual-mode) X f Terminal set, X f ⊆ X
X State space, X : = R p
Y Generic forward invariant set
Z ˜ Set of nominal optimization parameters whose vertex is not fixed Z Set of nominal optimization parameters z υ
Z r g Set of optimization parameters that directly affect g r Z s h Set of optimization parameters that directly affect h s Z l J Set of optimization parameters that directly affect J l Function Spaces
K Comparison functions (stability analysis) K ∞ Comparison functions (stability analysis) KL Comparison functions for (stability analysis) L Comparison functions (stability analysis)
L ∞ ([ t 0 , t f ] , U ) Lebesgue integrable control functions on interval [ t 0 , t f ] L ∞ ( R, U ) Lebesgue integrable control functions on R
U k Control space on grid interval [ t k , t k + 1 ]
U N ( t f ) Control space of N piecewise polynomials up to time t f Special Operators
⌈·⌉ Ceiling operator
| Z | Cardinality of set Z (only for sets)
| z | Absolute value of scalar z
⌊·⌋ Flooring operator
D z f ( z 0 , · ) Jacobian of vector field f ( z, · ) with respect to z and evaluated at ( z 0 , · ) D f ( z 0 ) Jacobian of vector field f ( z ) with respect to z and evaluated at z 0
∥·∥ Arbitrary norm
∥·∥ 1 ℓ 1 -norm (absolute value norm)
∥·∥ 2 ℓ 2 -norm (Euclidean norm)
∥·∥ Q Weighted ℓ 2 -norm, for example ∥ z ∥ Q = √ z ⊺ Qz max ( z 0 , z 1 ) Componentwise maximum of vectors z 0 and z 1
min ( z 0 , z 1 ) Componentwise minimum of vectors z 0 and z 1
∇ z J ( z 0 , · ) Gradient of scalar function J ( z, · ) with respect to z and evaluated at ( z 0 , · )
∇ J ( z ) Gradient of scalar function J ( z ) with respect to z and evaluated at z 0
∇ zz 2 J ( z 0 , · ) Hessian of scalar function J ( z, · ) with respect to z and evaluated at ( z 0 , · )
∇ 2 J ( z 0 ) Hessian of scalar function J ( z ) with respect to z and evaluated at z 0
Abbreviations and Acronyms
AD Automatic Differentiation
BFGS Broyden-Fletcher-Goldfarb-Shanno algorithm IPOPT Interior Point Optimizer
KKT Karush-Kuhn-Tucker
LICQ Linear Independence Constraint Qualification LQR Linear Quadratic Regulator
MFCQ Mangasarian-Fromovitz Constraint Qualification MPC Model Predictive Control
NRMSE Normalized Root Mean Square Error
nz non-zeros
OSQP Operator Splitting Quadratic Program PID Proportional-Integral-Differential RTI Real-Time Iteration Scheme
SQP Sequential Quadratic Programming
w.r.t. with respect to
1
Introduction
1.1. Motivation
In a number of industries, minimizing time is essential to increasing the productivity of automation solutions. To give a few examples, gantry cranes lift and transport a large number of containers in ports to meet the increasing demand for import and export goods. In addition to sophisticated logistics, faster crane control is crucial to increase productivity. In the field of warehouse robotics, mobile robots are also ex- pected to navigate as fast as possible while avoiding obstacles. The productivity in the area of automated assembly at automobile manufacturers correlates strongly with the execution speed of their robotic manipulators. Racing is also dedicated to minimizing lap times as a central objective. In most of today’s industrial applications, however, linear control concepts such as PID or robust H ∞ -control [Zho+96] as well as linear quadratic regulators (LQR) [KS72] are used due to their simple realization and im- plementation. The minimization of time is only achieved by an aggressive tuning of the control parameters. These conventional controllers cannot explicitly incorporate constraints on control respectively state variables such as limited crane swing, obsta- cle avoidance or bounded robot respectively car velocities without conservatism and further restrictions [Sch+97]. Practical control systems are therefore not operated at
Time t µ
Current time t 0 t 1 Final time t f
Prediction (horizon)
Control bound u max
Final state x f
Past
input sequence u ∗ 0 Predicted
input sequence Past
trajectory
Predicted trajectory Current state x u ( t 0 )
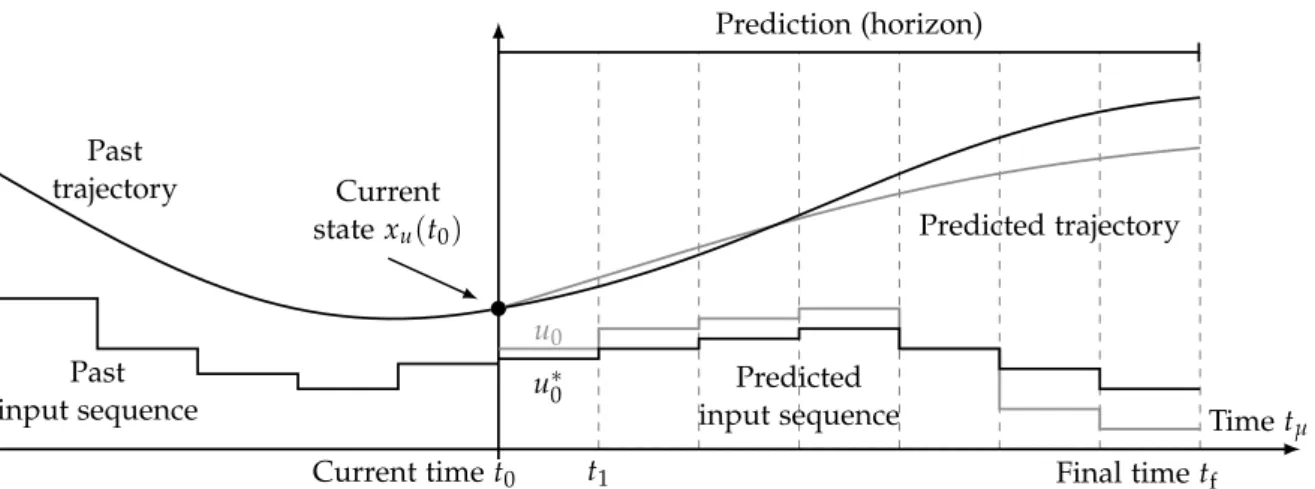
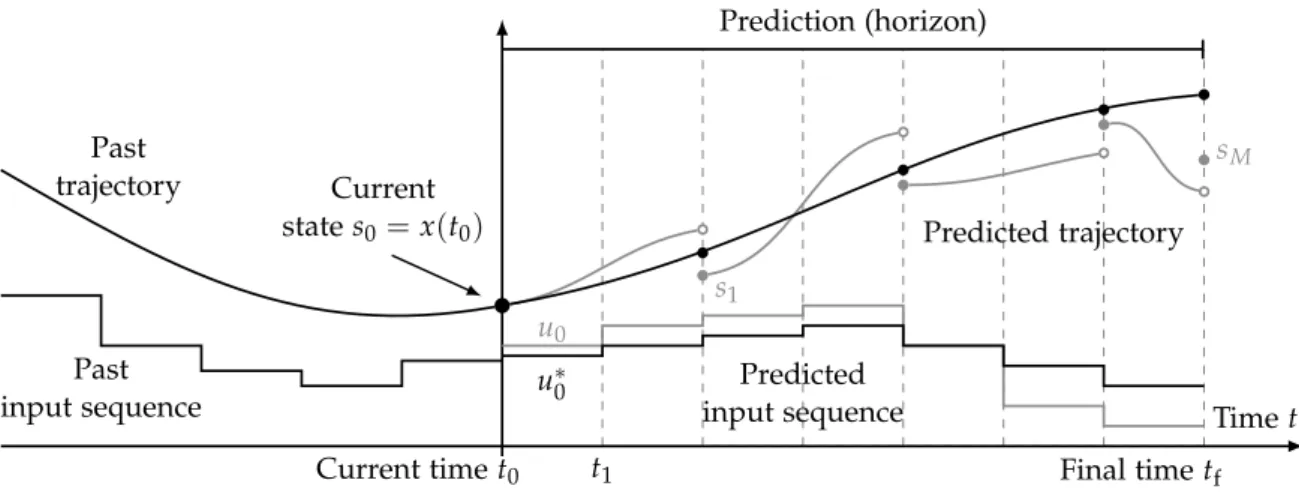
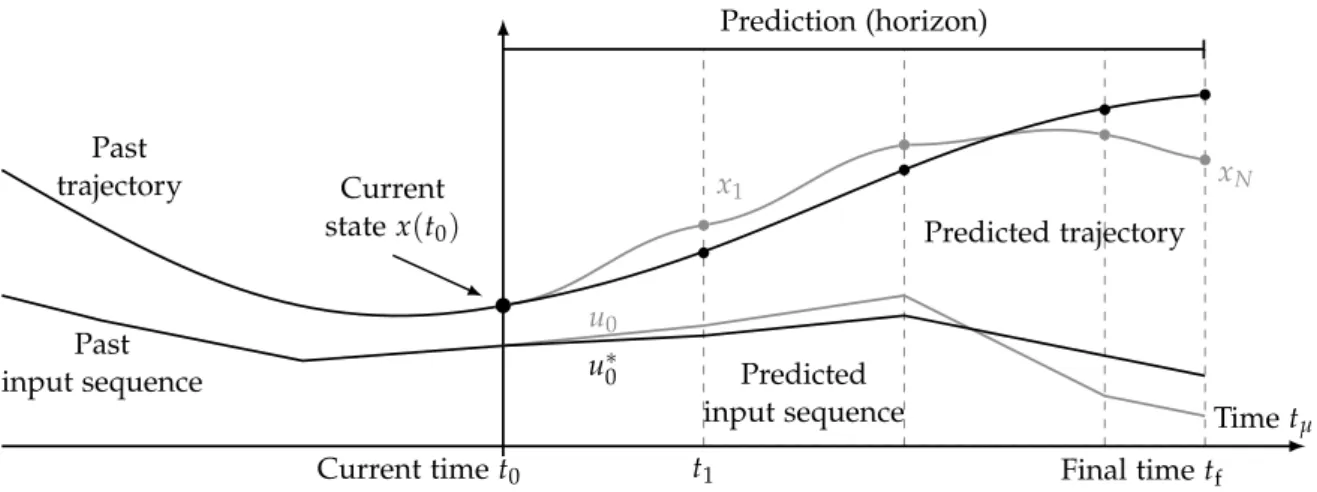
Figure 1.1.: Receding horizon principle in MPC.
Model Predictive Controller
Plant
Observer Control law
µ ( t µ ) : = u ∗ 0
Output y ( t µ )
Current state x u ( t 0 ) : = x µ ( t µ ) Final state
x f
x
ftf Prediction (horizon)
x
u( t
0)
tµ
t0 t1 tf
Prediction (horizon)
x
u( t
0) u
max
x
fu0
t
t0 t1 tf
Prediction (horizon)
x
u( t
0) u
max
x
fu∗0