Using root cause analysis to handle intrusion detection alarms
148
0
0
Volltext
(2)
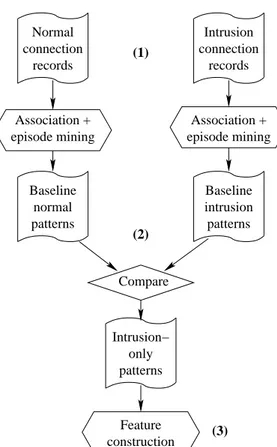
(3)
(4)
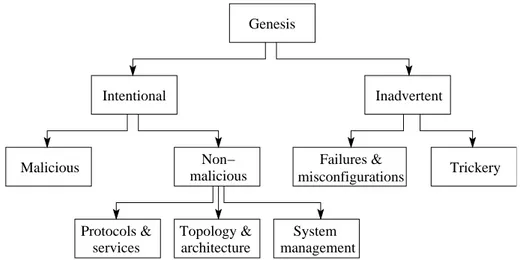
(5)
(6)(7)
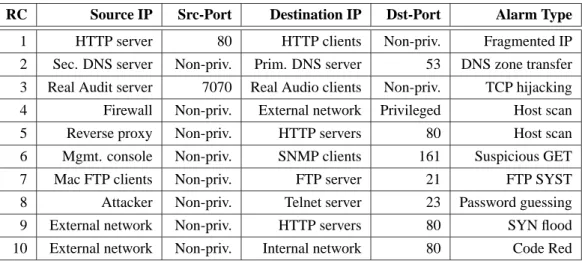
(8)
(9)
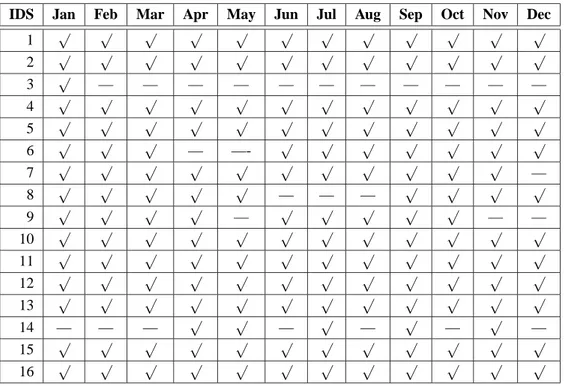
(10)
(11)
(12)(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(32)
(33)
(34)
(35)
(36)
Abbildung
+7


ÄHNLICHE DOKUMENTE
In this paper, I examine the root cause of sovereign default on the basis of a model of inflation that is built on a micro- foundation of government behavior and conclude that the
Turning to the temperature relaxation experiments shown in Figure 5 the relaxation time-scale of 10 h is comparable to τ θ so that it would be expected that the tropical
Safety related specification errors come into existence through accidents or incidents with undesired outcome: A root cause analysis may lead to corrections of the specifica- tion
a certain graph, is shown, and he wants to understand what it means — this corre- sponds to reception, though it involves the understanding of a non-linguistic sign;
The second part of the report turns to some less-examined aspects of R2P ‘root cause’ prevention: the intrusive nature of such prevention, the central role of states in the
To maintain the general nature of supported analysis tasks by the server and the models, there is no combination on the server side of the Fourier transform and the wavelet transform
Second, because paid apps are important to smartphone users, using paid apps for free is a main reason for jailbreaking, a reason more decisive among Android users than Apple
Fremdfirmenmanagement in Europa und wie man aus Fehlern klug wird Katrin Weißenborn, E.ON Kraftwerke GmbH. Im Rahmen des Einsatzes von internationalen Unternehmen bei
